
A privacy-preserved indexing schema in DaaS model for range queries
2020-11-27 09:17HaoRenzhi郝任之LiJunWuGuangjun
High Technology Letters 2020年4期
Hao Renzhi (郝任之), Li Jun , Wu Guangjun
(*College of Control Science and Engineering, Zhejiang University, Hangzhou 310058, P.R.China)(**School of Cyber Security, University of Chinese Academy of Sciences, Beijing 100093, P.R.China)(***Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093, P.R.China)
Abstract
Key words: database-as-a-service (DaaS) model, data privacy and security, data verification, range query
0 Introduction
The database as a service (DaaS) model was proposed by Hacigumus et al.[1], and NetDB2, SQLVM[2], PMEL[3]are effective DaaS models. In a DaaS model, a data owner stores encrypted data in a database server of the service provider, and the data user obtains query results from the service provider. In the DaaS model, data owner can access the data freely and can reduce the cost of deploying corresponding software and hardware of database service. Typically, a DaaS model includes 3 parts: (1) The data owner, which is the owner of data, publishes and shares data with data users; (2) The service provider provides service for the data owner and user; (3) The data user accesses and uses data stored in the service provider. Owing to the fact that a service provider cannot be trusted by a data owner, the data owner encrypts data before publishing data. Considering a relation TRADE (tno, cost, date) as an example, a data owner encrypts the original data items into encrypted data, builds index for each item, and publishes and stores them in the database of service provider. However, in current DaaS model, the published data suffers from the risk of privacy leaking to an attacker. In other words, the data owner and the data user do not trust the service provider. To support the following queries over encrypted data, the service provider usually stores the index along with the encrypted data, and an attacker might obtain data distribution and statistical information from the correspond indexing. For example, a tuple in TRADE (tno, cost, date) is recorded as (key1, 5779520.12, 2018/12/3) and it might be represented as (Index onkey1,kVpZCNJqcG8=,lcXxF+LEl9TogO7ADeI/e,JHKIN+iZwiA==). An attacker can obtain the distribution of encrypted data from the index on tno.
A novel indexing schema is proposed for encrypted data stored in DaaS service provider. In this model, the data owner can use encryption technologies to store data at a service provider. Meanwhile, the model can avoid data privacy leaking and provide the capability of correctness verification to verify the following queries over the encrypted data. The main contributions of this paper are as follows:
A novel DaaS model using privacy-preserved Hash-based indexing schema is proposed, which is computed by summarization of Hash value from an interval of data items. The schema can support range query and avoid the false fit by a proposed marked data items technique.
A correctness verification method is described, which uses a verification matrix to check the answer of a range query. The verification matrix is computed by data items signature. The data users can check correctness of an answer for range query that is obtained via the proposed Hash-based indexing.
An extensive evaluation using 2 data sets to demonstrate the functionality and effectiveness of the proposed approach is conducted. The experimental results show that the approach can protect the statistical information and data distribution using the proposed schema over encrypted data.
1 The proposed approach
1.1 Approach overview
In this section, the overview of proposed approach for privacy-preserved data publishing and queries in a DaaS model is presented. In data owns’ perspective, data privacy of the data owner includes data statistical information, such as maximum data item, minimum data item, and data value distribution.
This work proposes a privacy-preserved indexing schema for data owner and provides query correctness verification for data users. The core idea of the approach is shown in Fig.1. The method mainly includes 3 stages: (1) The data owners encrypt their data and build a Hash-based indexing. Then, the data owners publish the encrypted data and built index to the service provider; (2) The service provider accepts the published wrapped data, including the encrypted data and the indexing, and stores them in an open database; (3) The data user conducts a range query in the service provider over the encrypted data, obtains the queried result, and verifies the correctness of the answer.

Fig.1 Overview of the approach in the DaaS model
1.2 Hash-based indexing
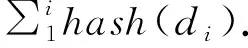
1.3 Publishing encrypted data and index

1.4 Query in a DaaS model
After representing the Hash-based indexing, the process of a range query can be described. The steps can be described as Fig.2. For a range queryQ(a,b), the range query condition is expressed as [a,b]. The query condition can be divided into 2 parts: (1) [a,a1) and (b1,b], which contains the boundary of the query; (2) [a1,b1], which covers the whole internals. To obtain the range query results, the data user firstly maps all the queried range into interval identifiers. For the range [a,a1), which is in one interval supposed as [c,d), the data user calculatesgthat satisfiesc+g×Φi≤aandc+(g+1)×Φi>ato locate the boundary by valuea, and the process of locating the query boundary can be described as Algorithm 1.
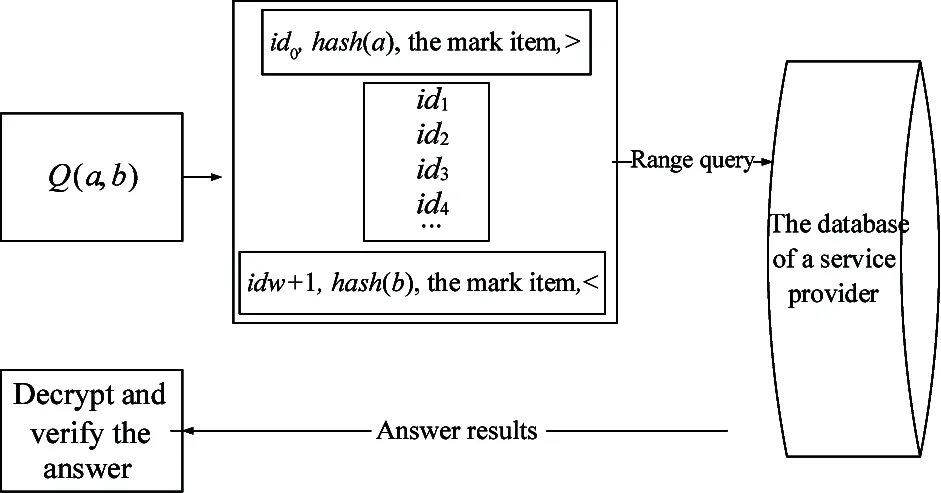
Fig.2 Range query via Hash-based indexing

Algorithm 1 Computing a range boundary for a range query Input: hash(a), marked item g, hash-based index in one interval, sum=0, boundary=0 While indexes! = NULL index = indexes.next hash = index - sum if index is of marked items if hash>g return boundary else if hash == hash(a) return index boundary = index sum = index return boundary
1.5 Correctness verification
To prevent data privacy leaked, the data owner encrypts the data before publishing it. In this section, the schema adopts a verification matrix to verify the query results. Along with each data item, the service provider stores a signature calculated by the data owner. The signature of a data item is determined by 2 adjacent data items as Fig.3.
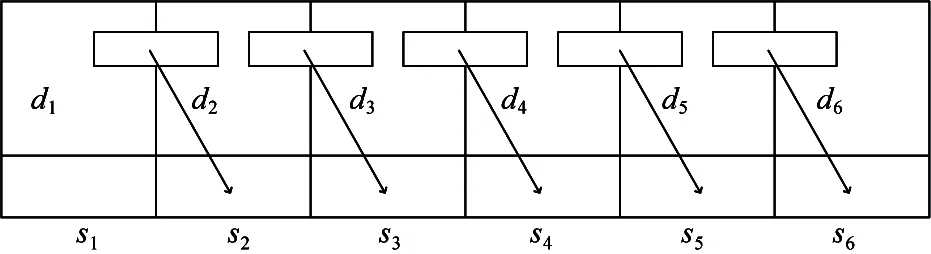
Fig.3 The signature chain
The signature is calculated via the signature function presented as Eq.(1). In Eq.(1),SHash(d) is a Hash function, and it calculates the data item’s Hash value, andMaxP(a,b) calculates the maximum multiple ofbless thana, andbmust be a rounded number. In the Eq.(1),ε1,ε2are error parameters that equal to 1/p1, 1/p2, wherep1andp2are decided by the data owner.
S(di)=MaxP(SHash(di),1/ε1)
+MaxP(SHash(d(i-1)),1/ε2)
(1)
The schema defines the verification matrixes by the signatures. As described in Fig.3, a data itemdiand its signaturesican be verified through 3 ways: (1) The neighbor verification, which means verification by the relationship betweendi-1andsi; (2) The self-verification, which means verification by the relationship betweendiandsi; (3) The mutual verification, which means verification by the Eq.(1). For the 3 ways, the verifications can be presented as the following equation:
(si-MaxP(SHash(d(i-1)), 1/ε2))mod(1/ε1)=0
(2)
(si-MaxP(SHash(d(i-1)), 1/ε1))mod(1/ε2)=0
(3)
si=(MaxP(SHash(di), 1/ε1))
+MaxP(SHash(d(i-1)), 1/ε2))
(4)
The errors of verification Eq.(1) and Eq.(2) areε2, andε2, respectively, andε1·ε2for verification Eq.(3). The schema defines the verification matrixAu:
The (sij∈{0, 1}) equals to 1 if the data item or the verification signature satisfies the Eqs(2), (3), and (4) respectively, otherwise,sijequals 0. Andβ1=1-ε1,β2=1-ε2,β3=1-ε1·ε2, and define the matrix operation ‘*’ appearing in Eq.(5).
Ma=Mb*Mc, whereMaij=max(Mbik·Mbkj)
(5)
In the verification matrix of the data itemdi,au11indicates the confidence of correctness of the data itemdi,au12for the neighbor data itemdi+1,au21forsi, andau22fordi-1. Based on the verification matrixAu, the data user can verify that the data itemdiis correct with the confidenceau11, and the data user can confirm with the confidenceau21·(1-au22) that the data itemdi-1is lost and with the confidenceau11·(1-au12) that the data itemdi+1is lost. Furthermore, the verification method can be extended to a two-dimensional zone query.
1.6 Experimental setup
This work uses 2 types of data sets to evaluate the approach. One data set is the generated relational data TRADE(tno, cost, date), which has 10 000 data items, and the attributes cost is from 0 to 10 000 000 with precision 0.01 and attributes tno is an integer attribute. Another data set is a real data set, which comes from the Labor Statistic Public Database. This work conducted the experiment in a computer with Intel (R) Core (TM) i5-4210M CPU @2.60 GHz, 8 G RAM. The software environment is Ubuntu 17.10, JDBC, and JAVA 1.8, and the DBMS is the PostgreSQL 9.5. Based on the experimental environment, this work conducted the following experimental tests: (1) Data publishing evaluation; (2) Range queries via Hash-based indexing; and (3) Data correctness verification.
1.7 Hash-based indexing schema evaluation
Next, this work verifies the functionality of the privacy-preserved indexing on the simulated data set TRADE, whose attribution tno data items are randomly generated from a linear distribution as shown in Fig.4, and Fig.4 shows that the distribution of the index obtained by order-preserving Hash-based function (OPHF)[4]is similar to the data value. Fig.5 shows the original data value distribution and the Hash-based index obtained by the approach, and the Hash-based index of the approach can protect the privacy and statistical information of the data value.

Fig.4 Original data distribution vs. index distribution in OPHF[4]
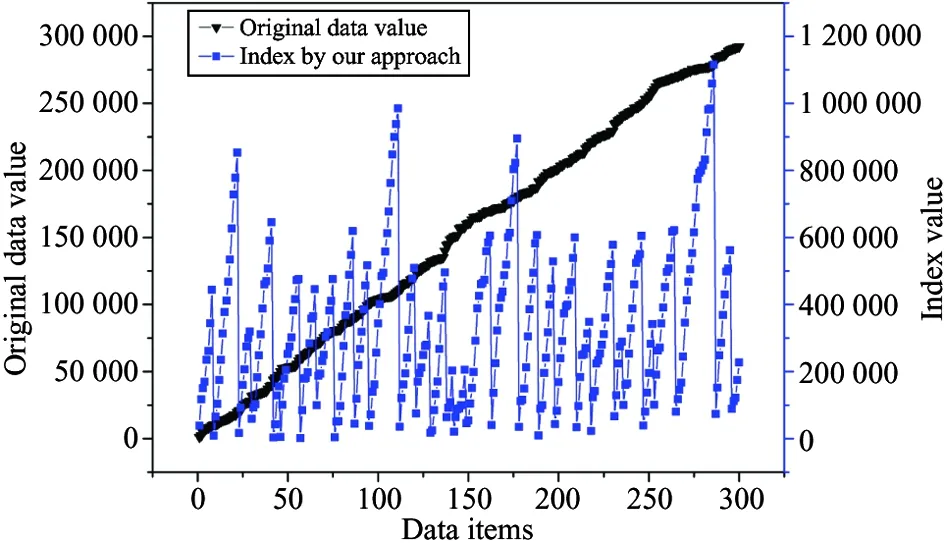
Fig.5 Original data distribution vs. the Hash-based index
The evaluations use public dataset from the Bureau of Labor Statistics to conduct the evaluation. Fig.6 and Fig.7 present the original data value and Hash-based index by the approach, and the figure demonstrates that the distribution of original data and the Hash-based index by the approach are uncorrelated. The attacker can’t defer the data information via the encrypted data or the Hash-based index accurately.
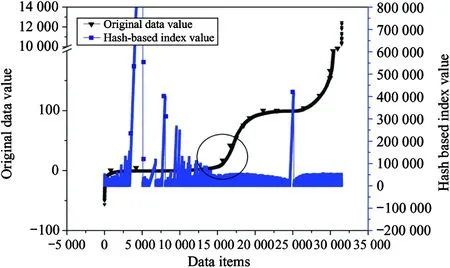
Fig.6 Overview of the original data value vs. Hash-based

Fig.7 Partial view of the original data value vs. Hash-based
1.8 Correctness verification evaluation
To test the efficiency of publishing the data items and conducting a range query, this work conducts the experiments on the simulated data set TRADE. Table 1 shows the efficiency of the publishing data items. The data set TRADE includes 100 000 items. This work inserts the data items one by one and calculates the average time for per item. When the number of intervalsNvaries, the time of the approach almost keeps the same as shown in Table 1. Table 1 demonstrates that the approach is more efficient than OPHF[4]whose parameter (xi-xi-1) is assigned 0.01. The evaluation demonstrates that the approach has better efficiency on data publishing and indexing. In the testing, the approach can achieve nearly 10 times and 35 times improvement on data encryption (decryption) and indexing respectively.

Table 1 Time used for publishing and indexing data
This work conducts the range query evaluations, in which a data user requests the range queries that cover 20%, 40%, 60%, and 80% of dataset TRADE. The process of a range query includes 4 parts as labeled in Fig.8. Step 1 is the process that the data user maps the interval identifiers and calculates the mark data items, Step 2 is the process that works in the service provider, Step 3 is the process that the data user filters the mark items, and Step 4 is the process that the data user encrypts and decrypts data items. Fig.9 is the process that the data user calculates the signature matrix and verifies the query results. In the DaaS model, the most computation is calculated by the service provider and the process that is executed by the data user uses less proportion time, which reflects the advantage of the DaaS model, and Fig.9 also demonstrates that the process of correctness verification costs reasonable time consumption in the approach.

Fig.8 Time used for a range query
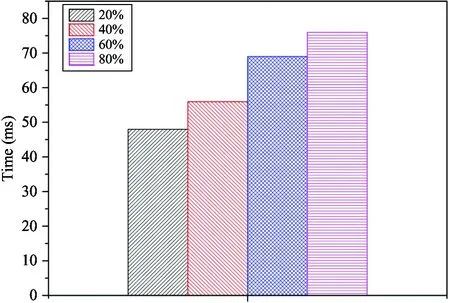
Fig.9 Time used for correction verification
2 Related work
The database as a service (DaaS) was proposed by Hacigumus et al[1], and they have developed a DaaS instantiation called NetDB2. Some researches demonstrate privacy issue in the DaaS model[1,5,6], and many researches focus on the solution of the problem[7,8]. To keep data security, the data owner set up a reasonable access control mechanism, such as role-based access control (RABC)[9], attribute-based access control (ABAC)[10], discretionary access control (DAC), and mandatory access control (MAC)[11]. Many encryption algorithms, such as DES[12], 3DES, Blowfish[13], RC5[14], IDEA[15], RSA, and Elgamal[16]will be used in DaaS model.
Order-preservingdataencryptionmethodsBy adopting an order-preserving encryption, the encrypted data would meetEncrypt(d1) IndexingmethodsThe bucket partitioning[23]is an effective approach to support the range query on encrypted data. The primary idea of bucket partitioning method is that the data owner divides data domainUintoNdiscrete buckets, and each bucket has an index value. However, the data user might get the false hit data. Order-preserving Hash-based function (OPHF)[4]can be adopted to support range query. This method has a risk of privacy leaking, such that data distribution of the data will be exposed by the Hash index. CorrectionverificationThe service providers wouldn’t be trusted absolutely, so it is important to verify the correctness of the query results[24,25]. On the verification of data correctness, the data owner and the data user share a matrix to verify query results[4]. However, the matrix can just show whether there are data items added or deleted. However, when a data item is corrupted, the matrix can’t show this situation. There are some researches using Merkle Hash tree[25]to verify query results. The DaaS model makes it easy to share and manage data between different data users. To keep data privacy and security for data owners, the DaaS model needs an efficient and secured strategy to ensure data privacy in the process of data publishing, storage, and sharing between users. This work proposes a novel indexing schema to satisfy privacy-preserved data management requirements. The proposed approach includes 2 parts: the Hash-based indexing for encrypted data and correctness verification for range queries between the DaaS service provider and the data users. The evaluation results demonstrate that the proposed approach can hide statistical information of encrypted data distribution while can also obtain correct answers for range-queries. The future plan is to promote query efficiency over publishing data items.3 Conclusion
 High Technology Letters2020年4期
High Technology Letters2020年4期
- High Technology Letters的其它文章
- Experimental study on vibration suppression in a rotor system under base excitation using an integral squeeze film damper
- Grouping pilot allocation scheme based on matching algorithm in massive MIMO system
- Fraudulent phone call recognition method based on convolutional neural network
- Behavior recognition based on the fusion of 3D-BN-VGG and LSTM network
- Dynamic A* path finding algorithm and 3D lidar based obstacle avoidance strategy for autonomous vehicles
- An effective indoor radio map construction scheme based on crowdsourced samples