
在用摩托车样本分布和活动水平分析*
2020-11-26 02:36冷传刚秦敬哲
小型内燃机与车辆技术 2020年5期
冷传刚 秦敬哲 赵 颖
(1-天津内燃机研究所 天津 300072 2-天津市公安局交通警察总队车辆管理所)
引言
为了进行摩托车行业环境空气质量改善应对方案研究,开展了以全国摩托车样本分布和活动水平为基础的调查和研究工作。
摩托车调查以如实反映摩托车的实际情况为基本原则,研究对象为摩托车样本分布和活动水平,调研以问卷调查的形式进行。
调研方案既考虑调查数据的完整性,又注意实效,同时坚持节约性原则[1]。调研采用了分层随机抽样法[2],将调研市场总体按一定的标志划分成轻便摩托车、两轮摩托车、三轮摩托车3 个层次,从地域角度将样本总体划分为4 个层次,再从各层相同性质的分子中随机抽取样本,使样本具有充分的代表性和普遍性。共收集有效问卷340 份,完成了在用摩托车样本分布和活动水平各个预定内容的调研。
对获得的调研问卷进行汇总整理,完成了在用摩托车样本分布和活动水平的统计结果。结果充分反映了我国在用摩托车的现状。
1 抽样调查统计方法概述
数据整理是指对统计调查所搜集到的各种数据进行分组与汇总,亦称为统计汇总[3]。统计整理在统计工作过程起着承上启下的作用,它是统计调查的继续和深化,又是统计分析的基础和前提,其中心环节是对搜集的原始资料根据研究目的按一定的标志进行科学的分组和汇总,并用统计表和统计图将数据直观地显示出来,使数据资料条理化、系统化,为统计分析奠定基础。
统计数据描述性指标可以分为3 类:一是反映数据集中趋势的数量特征,包括数值平均数与位置平均数;二是反映数据分布的离散趋势的数量特征,包括极差、方差、标准差等;三是与数据分布的形状相关的数量特征,即偏度与峰度。
除了对样本数据的水平或其他特征进行描述以外,还经常需要根据样本的信息,对总体的分布以及分布的数字特征进行统计推断,即推断统计分析。推断统计分析的前提要求是,样本是随机抽样而来的,对总体有一定的代表性。分析方法主要包括2 部分:参数估计和假设检验。参数估计是在总体分布已知的情况下,用样本统计量估计总体参数的方法。假设检验是在总体分布未知,或已知总体分布但不知其参数的情况下,来推断总体的某些性质,提出有关总体的假设,再根据样本信息对假设进行判断的方法;常用多元统计分析方法有方差分析,多元线性回归分析,因子分析,聚类分析等[4]。
2 在用摩托车样本分布水平
综合应用各种统计方法,对获得的问卷结果进行统计整理,得到在用车样本分布结果,包括:在用车车辆类型分布;摩托车保有量、销量、新车占有率、报废率;骑行时间、燃油供给方式统计;污染控制装置比例。
实际场景中,信号源的位置是随机的,每个脉冲信号的到达时间不同,因此接收端很难采样到每个信号的峰值,这被称为非理想采样。理想采样能采样到信号的峰值,但是非理想采样情况下采样到的位置则是随机的。在多径信道情况下,信号相互交叠,更加难以实现信号的分辨估计。本节介绍基于泰勒级数展开的信号分辨算法,其原理参考文献[6]。

图1 在用车车辆类型分布
车辆类型分布的比例(见图1)为,两轮摩托车的比重最大,约占总体的92%,其中骑式车和踏板车的比重最大,约占总体的90%;从排量看,两轮摩托车100 mL 至125 mL 排量所占比例最大,100 mL 至125 mL 骑式车约占所有统计车型总体的33%,踏板车约为20%,而三轮摩托车以125 mL 以上排量为主,约占样本总体的3%。
摩托车新车占有率和报废费率统计。由2009 年至2016 年我国摩托车保有量和新车的销售量可以推算出该地区的新车占有率和老旧车辆报废率,结果如图2 所示。

图2 新车占有率和旧车报废率统计
2013 年是具有转折意义的一年,随着汽车及电动车保有量的逐年上升,摩托车保有量从2013 年开始逐年下降,而报废率却创近几年新高。由于用户收入不断提高及我国禁限摩的原因,用户更愿意选择汽车或电动车辆作为代步工具,摩托车市场越来越小。目前存在的摩托车主要是2008 年以后生产,2008 年以前各年份生产的摩托车总量小于15%。
骑行时间、燃油供给方式统计如表1 所示。可以看出,化油器车仍然占主导,这是由于目前国Ⅱ排放阶段的摩托车仍然没有完全报废,并且国Ⅲ排放阶段仍然存在一定比例的化油器车,而国四排放只接受电喷车的申报。可以预见,随着国四标准实施的不断深入和化油器车的逐年报废,市场上化油器车的比例将逐年下降,单辆摩托车对空气污染程度将呈下降趋势。

表1 骑行时间、燃油供给方式统计
在用车污染控制装置比例统计数据见表2。

表2 污染控制装置比例 %
可以看出二次补气、催化器、炭罐等污染控制装置已经广泛用于摩托车污染控制,随着国四排放标准的实施,摩托车污染控制水平不断提高。
3 在用摩托车活动水平
摩托车的活动水平现状主要包括行驶里程、使用时间、使用用途、使用车速、使用地点、故障、保养、维修现状等信息。对调研结果的各个数据汇总取平均值,可以得到活动水平数据,如表3 所示。

表3 在用摩托车活动水平
在用车常用行驶车速统计见图3。在用车的常用车速集中分布在40~80 km/h 的区间内(90.4%)。在制定新的油耗、排放标准时,行驶工况的确定可以参考这一数据。
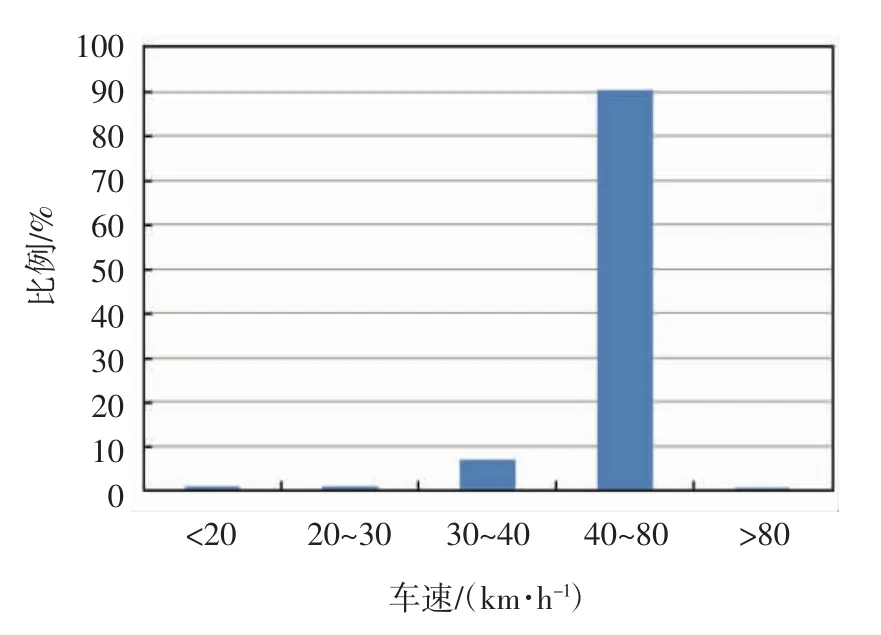
图3 在用车常用车速分布区间
故障统计情况见表4。可以看出,随着人们生活水平的提高,用户对噪声、振动即摩托车的骑行舒适性要求越来越高,此外燃油经济性也是用户较为关心的问题。

表4 在用摩托车故障统计情况 %
常用地点路况统计情况见表5。平坦路行驶占有的比例最高,这与我国优良的公路条件有关,城市、郊区、乡村各占有一定的比例。

表5 常用地点路况统计情况 %
4 调研结果的方差分析
本次调研采用了分层调研,从全国在用摩托车保有量大的几个区域抽取样车进行调研,用这几个区域的多个总体代表全国在用摩托车的样本分布和活动水平。为了验证这种方法的有效性,对调研结果采用了多元统计分析方法-方差分析[5]。
在假设检验中,我们可以检验2 个总体均值之差,而方差分析是该问题的推广,它是比较若干个总体均值之差的一种常用统计方法。传统的方差分析主要用于分析实验数据,实际上它同样适用于调查数据与观察数据[6]。
方差分析的基本思想是将所有测量值间的总变异按照其变异的来源分解为多个部分,然后进行比较,评价由某种因素所引起的变异是否具有统计学意义。得出统计量F 值;最后根据F 值的大小确定P值,做出统计推断。变异分解示意图如图4 所示。

图4 方差分析变异分解示意图
总变异为所有测量值之间总的变异程度。组间变异为各组均数与总均数的离均差平方和。组内变异为在同一处理组内,虽然每个受试对象接受的处理相同,但测量值仍各不相同,这种变异称为组内变异。
选取摩托车排量数值进行计算。按照以上理论进行方差分析,计算结果见表6。
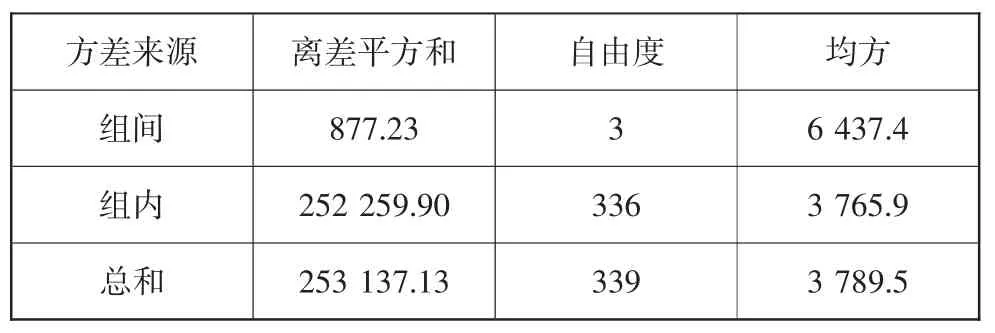
表6 方差分析计算结果
经计算,F=1.70,Fα=2.63。给定α=0.05 时,查F 分布表,临界值Fα(k-1,N-k)=2.63。由于F=1.70 <2.63,所以不同区域间的在用摩托车各水平间无差异:μ1=μ2=…=μk=μ。
结果表明,虽然从表面上看,区域不同对调研结果可能产生较大差异,故为了得到全国在用车的样本数据,需要对全国各地多个区域进行大量的调研。但从方差分析的结果看,对于选取的观测值,其组间离差平方和所占的比例很小,说明调研区域的不同对观测值的影响很小;组内离差平方和所占比例很大,说明观测值的变动主要是由随机变量因素引起的。即4 个不同区域调研结果的变异较小,对全国在用车这一样本总体的影响在可接受范围之内。由于4个不同区域的调研样本的观测值水平无明显差异,用这4 个区域的调研结果代表全国在用车这一总体的调研方法是可信的。从而证明了本次的调研方法和调研结果是有效的。可以看出,如果合理选择调研方法,可以大量减少调研的人力物力,而调研结果也能达到较高的置信水平。
5 结论
对获得的调研问卷进行汇总整理,完成了以下内容的统计分析:在用车车辆类型分布;摩托车保有量、销量、新车占有率、报废率;骑行时间、燃油供给方式统计;污染控制装置比例;骑行里程、时间、用途统计;常用车速分布区间统计;故障统计;常用地点路况比例统计。
对调研结果进行了方差分析,结果表明4 个不同区域的调研样本的观测值水平无明显差异,用这4个区域的调研结果代表全国在用车这一总体的调研方法是可信的。
对调研数据进行整理,可以得到以下结论:
1)我国摩托车保有量从2013 年开始逐年下降,而2013 年报废率却创近几年新高,随着我国机动车保有量的不断增加,摩托车市场却被不断压缩。
2)在用车用途以非运营和上下班骑行为主,而单人骑行比例高达95.8%,说明摩托车还是实用的单人代步工具。从在用摩托车的车辆类型分布看,两轮摩托车的比重最大,占摩托车总体的87.5%,两轮轻便摩托车和三轮摩托车比重较小。
3)从行驶路况看,平坦路占有的比例最高(占82.9%),在用车自测平均油耗为2~3.5 L/100 km。
4)从排放技术路线看,由于目前国Ⅱ排放阶段的摩托车仍然没有完全报废,而国Ⅲ排放阶段仍然存在一定比例的化油器车,化油器车比例仍然最大(占73.6%)。
5)从污染控制装置看,二次补气、催化器、炭罐等污染控制装置已经广泛用于摩托车污染控制,油箱盖防丢失措施应用也较广泛。
6)随着人们生活水平的提高,用户对噪声、振动即摩托车的骑行舒适性要求越来越高,此外燃油经济性也是用户较为关心的问题。
猜你喜欢
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
支部建设(2020年15期)2020-07-08
中国外汇(2019年6期)2019-07-13
四川党的建设(2019年5期)2019-03-19
中学生数理化·高一版(2017年2期)2017-04-25
车迷(2016年4期)2016-05-14
百科知识(2015年18期)2015-09-10
小星星·阅读100分(高年级)(2015年4期)2015-05-26
坦克装甲车辆(2000年12期)2000-06-13
雕塑(1996年4期)1996-07-12
