
一种面向自动化标检的文本分类方法
2020-11-26 07:41:56郭泽焦倩倩
现代防御技术 2020年5期
郭泽,焦倩倩
(北京电子工程总体研究所,北京 100854)
0 引言
文档是用户与产品之间最直接的桥梁,它有助于软件人员设计程序,有助于管理人员监督和管理产品,有助于维护人员进行有效的修改和改进,更是用户对产品功能、使用方式等各方面进行了解的最主要方式,其质量十分重要。在军用领域,研试文件、设计文件、软件文件等等一系列文档贯穿整个产品周期,其质量的好坏对产品的研制、试验等过程有着极其重要甚至决定性作用[1]。同时,文档作为向用户展示成果的最直接窗口,其质量更是反映了一个企业的文化。一份完美的文档能够让人看出企业工作的严谨态度,而一份错漏百出的文档甚至会令用户失去对企业的信心。
文档的质量已经引起各军工企业的重视,对文档质量开展的各类评审、审查等工作使文档的质量大幅提高。然而目前对文档的格式、内容的审查均完全依靠人工进行审查,审查效率不高,且受审查人水平、劳累程度等主观因素影响较大。文档的质量即使经过审查,也往往出现质量参差不齐的情况。开展自动化标检技术研究,降低人力资源消耗,提高文档产品质量十分重要。对文档的自动化标检实际是一种大规模文本的处理技术,其过程可分解为文本识别、文本标检和文本处理,其中最为核心的技术在于对文本的识别,即文本分类技术[2]。
1 基于机器学习的文本分类方法
文本分类是处理和组织大规模文本数据的关键技术,目前正广泛的应用于搜索引擎、快速资料分检、自动文摘、信息资料推送等领域[3]。自20世纪90年代以来,随着信息存储技术和计算机网络的飞速发展,机器学习逐渐取代了传统的知识工程,成为文本分类的主流技术。基于机器学习的文本分类方法一般采用向量空间模型[4],该模型包含3个关键技术:特征选择、特征权重估算和文本分类器。特征选择是从原始特征集合中选择一部分特征组成分类集合,最终得到原始特征集合的一个真子集,从而达到降低原始特征空间维度的目的。特征的权重反映了该特征对于标识文本内容的贡献度和文本之间的区分度。分类器则用于依据特征的权重,采用一定的模型对文本实施分类。常用的分类器包括朴素贝叶斯[5]、最近邻分类算法(K-nearest neighbor,KNN)[6]和支持向量机(support vector machine,SVM)[7],这几类分类器在特定的领域均有较好的应用。
与传统的文本分类问题不同,自动化标检领域的文本分类的基本单位为段落,特征向量除了文本外,段落的格式同样是决定其分类的重要特征[8]。其各类格式特征和文本特征均是相互独立的,这使得其非常适合采用朴素贝叶斯算法作为分类器[9]。由于需要进行分类的样本往往具有极强的样本倾斜性,某一类的数量(如正文)十分多,因此KNN算法不适用。此外,文本的编写中容易出现较多低级问题,使得某些特征具有一票否决的特性,支持向量机的核函数构造较为困难。综合考虑,采用朴素贝叶斯算法作为自动化标检的段落分类器。
2 分类模型与特征选取
设计一种改进的朴素贝叶斯分类算法用于段落分类。定义事件Ai为段落为第i类,事件Bj表示段落有特征j,则段落可用特征向量X={B1,B2,…,Bj}表示。已知段落全部特征B1到Bj时,根据贝叶斯公式,段落具有B1到Bj特征的条件下为类型i的概率为
由于各个特征相互独立,根据全概率公式,得到
不失一般性,对于任意一个段落,在不添加任何前置条件的情况下,P(X)对于所有类为常数,公式进一步变为
可以看出,任意段落为某一类型的概率与以下2类概率直接相关。
(1) 段落为类型i的先验概率[10]P(Ai);
(2) 段落为类型i时具有特征Bj的概率P(Bj|Ai)。对于任意一个段落,在书写过程中均可能出现特征与预期不符的情况。将P(Bj|Ai)拆分为类型i的特征符合要求和不符合要求2种情况。

定义P0表示先验概率,Pj表示特征j符合类型i的值。假设某段落的特征2不符合类型i,其余特征均符合,则段落为类型i的概率为

根据上述公式,段落的分类概率与P0到Pj直接相关,选取合理的特征将大幅提升识别的准确性。将特征分为格式特征和文本特征2类,其中格式特征表示段落的格式,文本特征表示段落文字中隐含的特征属性。段落为类型i的概率为

格式特征为通用特征,即每个段落都具备的特征,是进行分类的基础特征。文本特征为特有特征,当某些段落具备特殊的文本特征时,该段落属于某一类型的概率提升,属于其他类型的概率降低。任意段落具备类型k的文本特征时,属于不同类型的概率进一步分解为

根据上述推导,我们选取了19个特征的概率值作为训练参数,选取参数如表1所示。
3 基于遗传算法的参数训练模型
各个特征对于最终文本分类结果的贡献度由其权重直接决定,单纯的依赖经验难以获取较好的分类结果,直接影响最终的标检质量。本文采用一种基于遗传算法的参数训练模型对19个特征的权重(概率)进行训练,采用一种有监督[11]的机器学习的算法,使得机器的分类结果尽可能的接近人工分类结果,各个特征的权重由样本数据决定,随着样本量的增大,其分类的准确性将有效提升。
3.1 基因设计
由于19个特征相互独立,且均为概率值,本文采用一种一维线性基因,每个特征的权重作为其中的一个编码,可以较为便捷的进行交叉和变异操作。

表1 训练参数选择情况Table 1 The choice of training parameters
3.2 算子设计
选择算子采用锦标赛算子[12],交叉算子[13]采用单点交叉和两点交叉算子,变异算子采用单点变异和位置变异算子[14]。
3.3 适应度设计
考虑到文档的段落类型的倾斜度,适应度函数以文档为单位计算分类参数的准确度,机器分类的结果与人工分类的结果越接近,则适应度越高。设p表示单份文档中的段落个数,q表示机器分类与人工分类相同的段落个数,则适应度计算函数为
依据以上设计,本文采用传统遗传算法,在适应度计算阶段将交叉、变异后的基因解析为特征权重并带入到文本分类算法中,对样本进行分类计算,将分类结果与人工结果进行自动比对,计算适应度并执行选择操作,判断是否满足准确度要求或迭代次数要求,不满足则继续进行下一代遗传,满足则输出特征权重至文本分类模型中作为最终参数。基于遗传算法的分类模型如图1所示。

图1 基于遗传算法的分类模型Fig.1 Classification model based on genetic algorithm
4 基于识别结果的自动化标检模型
自动化标检的目的是找出用户编写的文档中格式错误或文本错误的文本,其关注的重点是用户编写错误的情况。因此在文本分类时需要考虑到错误较为严重的例子,例如用户将图题、表题的格式完全写错的时候,由于段落紧跟图或表,仍应当识别为图题或表题,否则将直接影响后续标检结果。为了解决该类问题,在上面的训练和分类模型的基础上补充一种基于图表位置的图题表题识别算法优化文本分类结果。本文采用的标检流程如下。
(1) 检查文件载入:将参数配置文件载入模型中;
(2) 特征提取与筛选:提取段落的主要格式特征,剔除空段落、无效段落等干扰数据;
(3) 段落分类:为了进一步提高识别准确率,本方法加入了基于经验的先验识别算法;
图题表题识别算法(算法1)。首先利用文字处理程序提供的api函数获取其中所有的图和表位置,初步识别出为表题和图题的段落;
通用识别算法(算法2)。然后采用基于改进贝叶斯算法的分类算法计算所有段落的分类结果,记录概率最高的3个类型;
最后将2种识别算法结果进行融合。由于图题和表题通常紧跟图或表,因此通过api函数获取的图题表题结果可信度较高。因此,算法1识别为图题或表题时,直接采用算法1结果。算法1识别为非图题或非表题时,从算法2的结果中选取与不违背算法1结果的概率最高的结果。
(4) 错误检查:基于识别结果对各段落进行错误比对,记录所有的错误位置,并生成错误提示字串;
(5) 错误输出:自动统计错误情况,将所有错误在对应的位置直接以批注的形式输出错误提示字串[15]。
标检完成后将自动打开文档便于标检人员查看错误情况,同时还将在文档中标注出错误统计情况,用于直观判断文档的编写质量。
5 实验
定义文档的识别准确率如下:
识别准确率=识别正确的段落数/总段落数×100%.
为了验证本文算法的效果,分别采用传统KNN算法、朴素贝叶斯算法和本文的改进朴素贝叶斯算法进行实验。选取质量技术处提供的实际文档作为样本,共计5 150个段落,样本主要选取了最常见的需要标检的4类文档,包括
(1) 设计文件:正确样本率100%;
(2) 研试文件:正确样本率80%;
(3) 软件文档:正确样本率:60%;
(4) 三大规范:正确样本率:40%。
除了模板,针对这4类文档,各随机选取了一份真实文件进行检查。
1) 模板文件识别准确率分析
各算法的模板文件的识别比较情况如图2~5所示。
可以看出,传统的KNN和朴素贝叶斯算法在处理正确率较低的样本效果较差,而本文提出的算法在各个不同正确率的样本集中均取得了95%以上的识别准确率。
2) 随机选取文件识别准确率分析
对4类文档随机选取的样本进行识别准确率分析,结果如表2所示。
可以看出,随机选取的文档识别准确率均能达到95%左右的水平。
为了验证错误提示的正确性,设计《测试文档.doc》,植入不同的错误格式。植入的错误包括:段前行距错误、字号错误、首行缩进错误、段后行距错误、字体错误、对齐方式错误、右侧缩进错误、左侧缩进错误。将部分缩进进行组合放在同一自然段,且最后2个自然段为正确格式,用于检查是否误报。
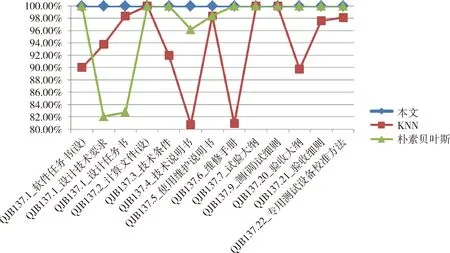
图2 设计文件识别准确率Fig.2 Identification accuracy result of design documents
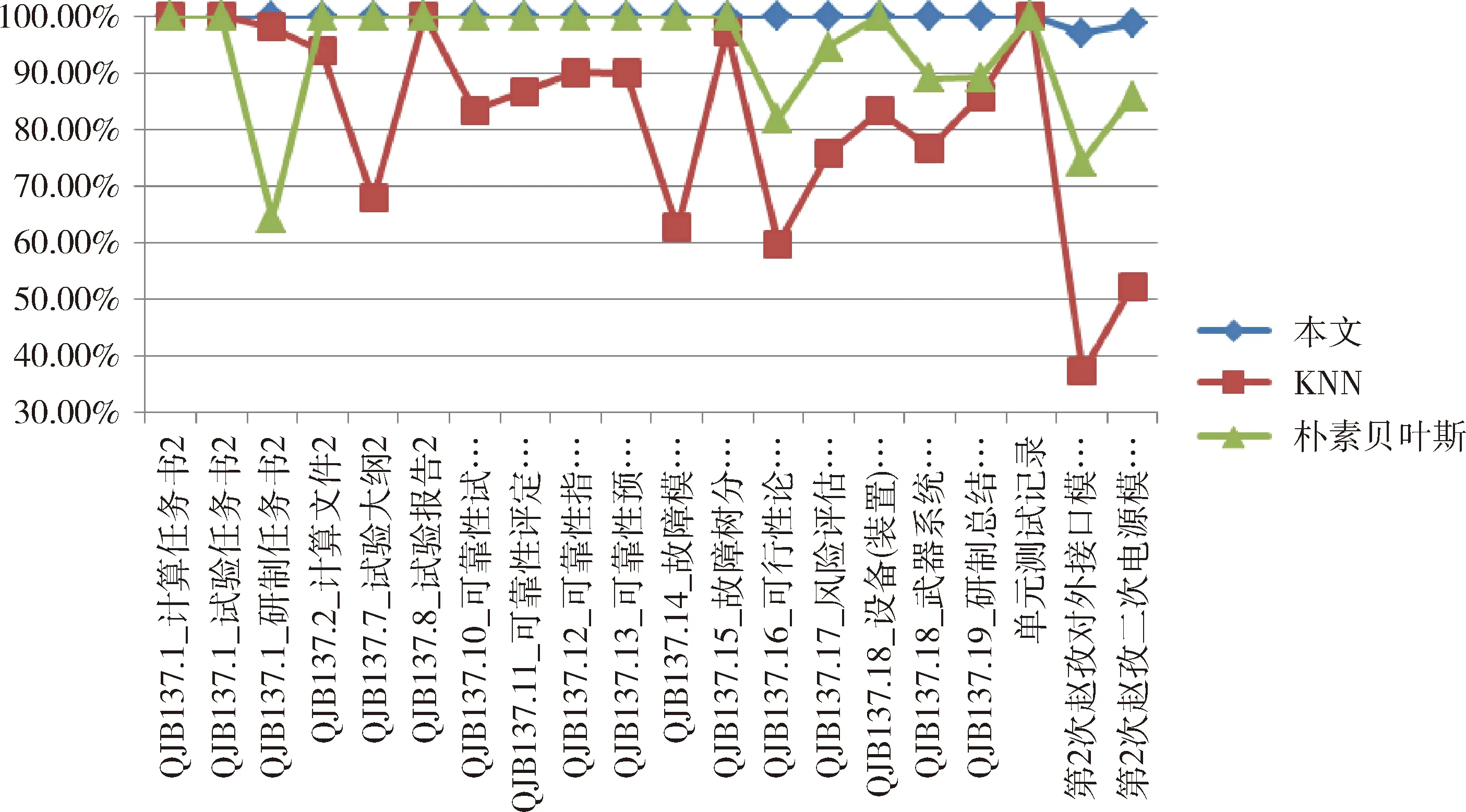
图3 研试文件识别准确率Fig.3 Identification accuracy result of research & experiment documents

图4 软件文档识别准确率Fig.4 Identification accuracy result of software documents

图5 三大规范识别准确率Fig.5 Identification accuracy result of standards

表2 随机文件识别准确率Table 2 Identification accuracy result of random documents
植入的错误在各段落末尾标注出设计测试文档,植入错误的分布情况如图6所示。使用工具进行格式检查后,自动生成错误批注,检查结果如图7所示。

图6 测试文档设计情况Fig.6 Design of test document

图7 格式检查结果Fig.7 Result of format check
所有植入的错误均被工具自动识别且标注出,标注的段落位置正确。正确的段落未出现误报,预埋错误的识别率达到100%,工具的基本格式检查功能满足设计要求。
6 结束语
本文首先对基于机器学习的文本分类算法进行了介绍,在此基础上选取了面向自动化标检的特征向量,进而提出改进的朴素贝叶斯分类算法和基于遗传算法的分类模型。然后,在实际的数据集中分别采用KNN算法、传统朴素贝叶斯算法和本文的算法进行了分类。实验结果表明,本文提出的分类模型能够有效处理段落数多、错误多的情况,正确的将段落进行分类。能够有效地提高自动化标检的正确率,从而提高标检质量。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
小学阅读指南·低年级版(2020年9期)2020-10-12 02:43:08
阅读(快乐英语高年级)(2020年9期)2020-01-08 02:20:52
散文诗(2017年17期)2018-01-31 02:34:11
数理化解题研究(2017年4期)2017-05-04 04:07:54
信息安全研究(2016年4期)2016-12-01 06:06:54
铁道通信信号(2016年6期)2016-06-01 12:10:20
读写算(下)(2016年11期)2016-05-04 03:44:07
电子器件(2015年5期)2015-12-29 08:43:15
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
