
光学成像小目标检测技术综述
2020-11-26 07:39王志虎沈小青桂伟龙
现代防御技术 2020年5期
王志虎,沈小青,桂伟龙
(中国卫星海上测控部,江苏 江阴 214431)
0 引言
长期以来,小目标检测始终是计算机视觉领域的研究难点。对于小目标的定义,目前还没有统一的标准[1],一般情况下,将距离较远,在成像平面上只占数十个像素区域,显示为点状并且具有低对比度和信噪比的目标称为小目标。近年来,伴随光学系统成像距离的拓展,以及对目标监测鲁棒性、智能化、准确度要求的提高,在目标监视、智能控制、视觉导航等方面,小目标检测技术都将发挥巨大的作用,并且为目标跟踪、识别等提供技术基础。由于距离远,目标成像尺寸小,形状、纹理、颜色、轮廓等特征缺乏;同时,背景噪声,例如云层、波浪、房屋、树木等,很容易将目标掩盖,这些都将增加小目标检测的难度。本文将从红外小目标检测、可见光小目标检测、基于深度学习的小目标检测3个方面对国内外相关研究成果进行汇总和综述,旨在为本领域的研究人员提供参考。
1 红外小目标检测技术
典型的红外小目标检测结果如图1所示。通常情况下,场景中目标物体的红外辐射较强,从而在图像中形成局部显著区域,根据这一特征,许多研究人员通过搜索图像极值来检测目标[2]。Wang等[3]基于最小二乘向量机(least squares support vector machine,LS-SVM)模型,设计了一种新型的小目标检测方法,它利用LS-SVM函数拟合图像块,然后使用2个高通滤波器和图像卷积来表达拟合后的极值,方法具有很高的运算效率。Deng等[4]利用信息理论提出了一种基于自信息图的小目标检测方法。对应于前景目标的直接检测,间接检测方法首先预测图像背景,然后基于实际图像和预测背景之间的差异来突出目标区域。Bae[5]提出了一种基于双边滤波的背景预测方法,可以在预测背景的同时保护边缘细节。为了更加准确地预测场景背景,Gu等[6]提出了一种基于核的非参数回归模型(nonparametric regression model)。
一些研究人员通过提取对应于目标的频域信息来实现小目标的检测。Yang等[7]设计的自适应巴特沃斯(Butterworth)高通滤波器能够有效抑制图像低频成分,同时突出高频信息,以增强包含高频分量的目标。Sadjadi[8]首先对图像进行小波分解,然后估计分解后小波域子带的概率密度,最后依据矩信息聚类提取红外小目标。
此外,数学形态学在红外小目标检测中也被广泛应用。Tom等[9]提出了著名的数学形态学方法,即Top-hat算子,它通过开运算消除图像中的高频信息,然后利用其与原始图像的差异来检测目标。Jong-Ho Kim等[10]首先基于形态学方法检测候选区域,紧接着使用改进的高斯距离函数确定真实目标。为了减少背景场景中边缘信息对前景目标的干扰,算法首先利用中值滤波预处理输入图像。为了提高红外小目标的检测能力,Zhou等[11]提出了一种利用序列型Top-hat滤波器实现红外小目标增强的新算法。
近年来,随着生物视觉研究的深入,越来越多的研究者开始关注仿生视觉红外目标检测算法。Li等[12]基于图像的显著性信息,首先利用尺度空间表达得到原始图像的显著图从而提取出感兴趣区域,然后再从这些感兴趣区域中进一步检测红外目标。Wang等[13]设计了一种高斯差分滤波器,首先根据视觉注意机制计算显著性图,然后结合回归抑制机制和赢者优先竞争机制,提取候选目标区域。Zhao等[14]结合形态学理论和显著性检测技术,设计了一种基于局部频率调谐的显著性提取技术,以突出潜在目标区域,然后通过阈值处理,得到潜在目标映射,最后采用形态学运算进行噪声抑制。受生物视觉的启发,Wei[15]提出了一种基于多尺度区域对比度算子(multiscale patch-based contrast measure,MPCM)的红外小目标检测方法。MPCM算法可以提高目标和背景的对比度,使得简单的自适应阈值即可实现小目标分割。

图1 典型红外小目标检测结果Fig.1 Typical infrared small target detection results
红外成像作用距离远、抗干扰能力强,并且可以全天候工作,但是分辨率低、目标与背景边界模糊,而且不包含颜色、纹理等细节信息,目标检测识别性差,因此可见光图像中的目标检测技术不可或缺。
2 可见光小目标检测技术
针对可见光图像小目标检测问题,早期的工作主要集中于通过对目标的状态估计来提高目标的检测结果,但是,在低信噪比情况下表现较差。为了提高检测准确度,研究者期望通过图像的预处理来达到抑制背景和增强目标的目的。针对应用场景的不同,国内外学者提出了多种图像预处理方法,包括有限或无限脉冲响应滤波器抑制算法、基于各向异性扩散的增强算法[16]、Top-hat变换[17]、自适应滤波技术等。然而,这些算法要求背景的统计特性是恒定的或缓慢变化的,因此它们对非平稳、非线性、快速变化的背景,抑制效果并不理想。为了抑制非平稳、非线性和快速变化的背景,研究人员提出了时频分析方法,如方向滤波器组、自适应频域巴特沃斯高通滤波器[18]、基于高阶累计量和小波变换的预处理算法[19]等。然而,这些算法是从傅里叶变换导出的,受海森堡不确定性原理的限制,存在时频分析不足的局限,限制了其在图像预处理中的应用。
近期,南京理工大学娄竞等[20]提出结合稳定图和显著性检测的海上舰船小目标检测方法,方法首先生成图像的稳定图,然后通过逐像素比较LAB颜色空间获取显著图,最后融合稳定图和显著图来移除虚警,实现飞机、车辆等小目标的检测,算法流程如图2所示。华中师范大学的邓鹤[21]发现小目标会导致图像局部反熵值发生较大变化,利用该特性提出基于改进的区域生长技术和局部反熵算子的小目标检测新方法。中国科学院大学的李大伟[22]在其博士论文中针对固定翼无人机地面车辆目标的自动检测问题,分别提出了基于目标特性、机器学习以及卷积神经网络的小目标检测算法,其中基于卷积神经网络的方法检测精度最高,达到80%以上,不过也存在计算过程复杂度高,不满足实时性的弊端。Nathan Mundhenk[23]提出一种基于逐像素提取区域特征的方法,将区域特征通过卷积神经网络进行分类检测,然而这种逐像素搜索的方法效率太低,而且对目标没有尺度适应能力。Sebastien Razakarivony[24]利用流形学习的方法分别建立目标与背景模型来检测复杂背景中的小目标(航空影像中的车辆),并且在OIRDS数据集取得48.9%的平均准确率。
可见光图像中小目标检测的传统方法主体部分通常是提取人为设计的图像特征,为了提高算法检测准确率,或者前端进行图像预处理,或者后端进行不同检测结果融合。这些方法往往针对某些特定应用领域或者数据集有效,适用范围窄,如果目标物体某些特征变化后性能便急剧下降。几十年来,尽管研究人员不断设计出新的提取特征,但在目标检测准确率上的提高并不明显,现实结果表明传统检测模型并不能很好解决目标检测问题。
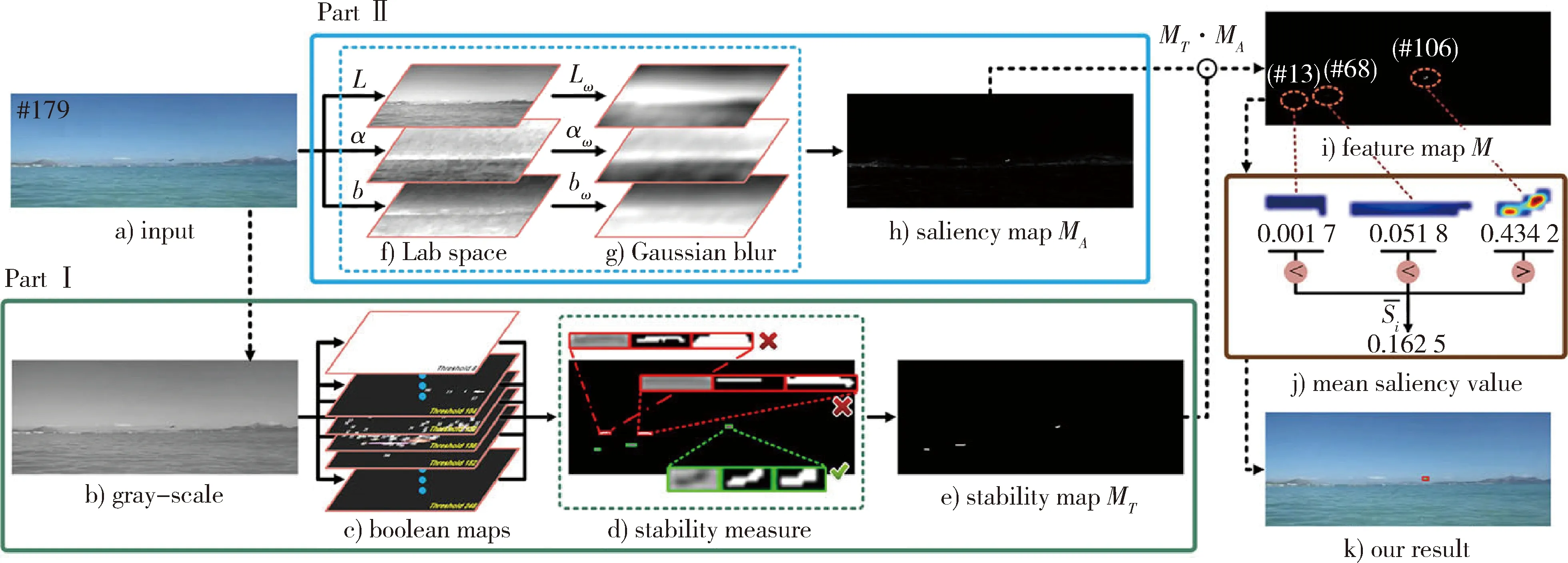
图2 RSS模型框架及小目标检测结果Fig.2 RSS model framework and small target detection results
3 基于深度学习的小目标检测技术
传统的目标检测方法主要面临2个问题:一是基于滑动窗口的区域选择策略冗余且时间复杂度高;二是手工设计的特征对于多样性的变化没有很好的鲁棒性[25]。而且,对于弱小目标,传统的处理方法难以获得诸如形状、大小、结构、纹理等的有用信息,这增加了目标检测的难度。得益于深度学习技术的快速发展,目标检测技术近年来取得了巨大的突破。深度学习方法相比于传统手工提取特征的方法在图像识别、区域分割、检测、分类等领域具有巨大优势,它通过多层非线性模型将输入数据转变为更高层次、更加抽象的表达,从而达到从整体上认识目标的目的[26],其中具有代表性的为Girshick提出了region CNN(R-CNN)[27]算法和Joseph Redmon[28]提出的Yolo(you only look once)网络。
由于深度学习的快速发展,陆续有研究者开始尝试使用深层网络模型检测弱小目标。李大伟对比了Faster R-CNN、Yolo等深度学习方法在小目标检测中的应用,并针对性地进行了系统的改进和优化,Yolo检测结果如图3所示[22]。针对PASCAL VOC数据集中的小目标检测,王昊然[29]设计并实现了基于多层卷积特征高阶融合的小目标检测系统。陈江昀[30]结合卷积神经网络CNN和超像素算法检测图像中的车辆年检标志,取得了不错的效果。唐聪等[31]分析了传统SSD(single shot multibox detector)方法在小目标检测上不足的原因,基于深度学习技术,提出了一种多视窗SSD目标检测方法。Akito Takeki等[32]提出一种基于深度卷积神经网络的方法,在视场的大范围区域检测鸟类小型目标:首先利用全卷积网络融合多尺度的神经网络输出特征,再使用SVM来获取更高的检测效果。Michael Kampffmeyer[33]等提出一种基于像素级、块区域以及两者相结合的深度卷积神经网络架构来实现航拍图像中单像素的分类,建立土地覆盖图以实现小目标检测。林两魁等[34]构建红外小目标深度学习检测框架,通过设计两个面向红外小目标检测的回归型和分类型DCNN(deep convolution neural network)网络,实现了基于深度学习的红外小目标检测。冯小雨等[35]改进了基于深度学习的目标检测框架Faster R-CNN,将其专用于空中目标检测,实验表明,改进后的Faster R-CNN在应对弱小目标、多目标、杂乱背景、光照变化、模糊、大面积遮挡等检测难度较大的情况时,均能获得很好的效果。Rui Zhu等[36]基于ResNet网络,通过加入BatchNorm层,同时去掉部分下采样层设计了一种不依赖预训练分类器的目标检测网络ScratchDet,改进后的网络模型在保持常规目标检测能力的同时,有效提高了小目标物体检测准确度。

图3 Yolov2的小目标检测实际效果Fig.3 Small target detection results in Yolov2
2012年,得益于ImageNet数据集的出现,深度学习技术井喷式发展,在计算机视觉领域带来了一场革命。由此,除了设计及优化网络模型外,不少研究者开始着眼于从基础数据集的角度提高小目标检测的准确度,主要包括2类:一类是在现有的目标检测数据集上做数据增强,Mate Kisantal等[37]针对小目标检测问题提出2种数据增量方法,即过采样和复制粘贴,过采样简单来说是将数据重复使用,复制粘贴即将输入图像中的小目标在多个位置复制,如图4所示。另一类为收集制作专门针对小目标的数据集,如航空影像中的车辆检测(vehicle detection in aerial imager,VEDAI)[38]数据、OIRDS(overhead imagery research data set)[39]数据集、RSS(regional stability and saliency)[20]数据集等。

图4 复制粘贴小对象的数据增强Fig.4 Data enhancements for small objects by copying and pasting
深度学习算法通过逐层运算提取物体更高层次的特征,近几年在目标检测领域取得了突破性进展,然而,伴随网络模型层数的增加,对目标物体的特征表达愈加抽象,当目标物体本身较小时,抽象后的特征将无法有效表征目标物体。针对该问题,目前主要通过保留浅层特征和融合上下文交互信息2种方法来提高小目标检测准确率[40],实验效果证明其有效性,改进模型在小目标图像数据集上的检测结果无论较传统目标检测算法还是通用的目标检测深度模型都有一定程度的提高,但是准确率依然不能令人满意,与生物视觉之间仍然存在很大的差距。虽然现有的研究表明生物视觉系统采用层次模型处理视觉信息,然而对其高层次的处理机制依然知之甚少。笔者认为,想要解决小目标检测难题,必将需要先验知识的支持,虽然现在的数据集数据量已经相当大,但相比较现实世界,尤其是生物视觉系统所接收的三维视觉信息而言仍然是远远不足的,因此有些研究者在目标检测模型中加入独立的空间变换模块[41],以期达到拓展先验信息的有效手段,这也许是一个可以有所作为的研究方向。
4 结束语
光学系统小目标检测技术研究不仅在目标监视、远程预警、精确制导等军事领域具有重大意义,而且在智能控制、人机交互、视觉导航等民用领域也有很大的发展空间。然而,传统检测方法在小目标检测问题中局限性大、准确率低,性能提升已到瓶颈,深度学习算法为解决该问题提供了新的技术手段,然而,一方面小目标检测数据集规模有限;另一方面目前研究者还没有设计出专门针对小目标的性能优异的检测模型。想要解决小目标检测难题,必将需要先验知识的支持,因此如何设计能够自主学习的智能算法将是关键。本文首先依据图像类别分别对红外图像小目标检测和可见光图像小目标检测的相关研究及国内外发展现状进行了梳理。接着,针对传统方法进行小目标检测时遭遇的瓶颈以及机器学习在目标检测领域的出色表现,详细叙述了基于深度学习的小目检测技术研究现状,期望本文综述内容能为相关领域科研人员研究小目标检测技术时提供一定的参考。
猜你喜欢
环球时报(2022-05-23)2022-05-23
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
航天返回与遥感(2022年1期)2022-03-09
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
金桥(2021年4期)2021-05-21
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
福建基础教育研究(2019年6期)2019-05-28
科技与创新(2018年7期)2018-11-30
