
一种面向网络借贷反欺诈的自动化特征工程方法*
2020-11-20 03:13郑忠斌胡瑞鑫王朝栋黄淳霏舒睿琪
通信技术 2020年11期
郑忠斌,胡瑞鑫,王朝栋,黄淳霏,舒睿琪
(1.工业互联网创新中心(上海)有限公司,上海 201303;2.同济大学,上海 200092;3.华东政法大学,上海 201620)
0 引言
随着信息技术的进步和推广,机器学习逐渐被应用在信用卡、消费信贷以及抵押贷款等领域。其中,反欺诈是信贷业面临的一个巨大挑战。咨询公司Javelin Strategy & Research 发布的报告显示,仅在美国,2017 年遭遇欺诈的客户就达到创纪录的1 670 万人,比2016 年高出8%,欺诈者从银行偷走了约168 亿美元[1]。此外,领先的金融机构已经使用机器学习技术打击欺诈者。例如,万事达采用机器学习系统跟踪和处理诸如交易规模、位置、时间、设备和购买数据之类的变量,系统评估用户在每个交易中的行为,并实时判断交易是否是欺诈。
特征工程是机器学习中最重要和最耗时的步骤之一。由于许多机器学习算法的效果在很大程度上取决于特征质量[2],因此在机器学习模型算法和参数配置相同的情况下,特征的微小变化可能对预测结果产生巨大影响[3]。另外,特征工程也非常耗时,因为它往往需要特定领域的专家凭借直觉和领域知识来构建有用的特征。例如,在Kaggle 举办的Grupo Bimbo 烘焙公司的库存需求预测竞赛上,获胜的团队在采访中表示,他们在特征工程上花了95%的时间,而只有5%的时间用于建模[4]。IT 公司Tata Consultancy Services 调查[5]显示,在其内部物联网数据分析团队中,60%的员工都有5~10年的行业经历,30%的组员从业超过10 年,且拥有硕士或更高学历。
欺诈检测本质上是一个检测罕见事件的问题,通常涉及异常分析、异类挖掘以及分析不平衡数据等。欺诈交易十分罕见,往往只占总交易量的极小一部分。但是,如果没有合适的工具和系统进行检测,这一小部分活动将会造成巨额的经济损失。因此,以准确和有效的方式检测欺诈交易的任务是相当困难和具有挑战性的,金融机构往往需要40 天以上[1]才能发现欺诈行为。
识别欺诈性贷款申请的挑战更加严峻。当一个恶意借款人在短时间内申请多个贷款人的多笔贷款时,会产生大量的申请数量和极小的申请审核时间间隔,使得这种欺诈几乎无法察觉。网络交易的普及也大大提高了身份验证的难度,犯罪分子可以利用各种方法盗窃他人身份进行贷款,如购买被黑客入侵的账户资料,或使用恶意软件和其他诈骗来远程操作计算机并申请贷款。
因此,对自动特征工程在借贷反欺诈场景下进行研究具有重要的现实意义,主要表现在以下几个方面。
(1)任何分类预测模型都离不开特征。特征工程是数据科学中至关重要的一环,其结果将直接影响模型的有效性。
(2)特征工程的自动化可以为简化数据科学流程带来显著的改变,使数据科学家能够更多地关注数据科学中其他的步骤。自动特征工程能够针对当前数据集和模型提取信息量,从而帮助数据科学家消除许多不确定性,并且加快决策过程。
(3)自动特征工程能够降低数据科学的门槛。自动特征工程不依靠直觉和特定领域知识就能创建有用的特征,使得没有相关知识的一般用户也能够构建专业级性能的机器学习模型,从而有效解决行业中数据科学家短缺的问题。
本文旨在在网络借贷背景下,将机器学习和自动特征工程相结合,探索能够区分罕见欺诈活动与数百万合法交易的有效方法。既是对机器学习和特征工程概念的探索,也是相关算法理论在特定场景和实际工程问题中的应用,是对自动特征工程技术的深入探讨,为网络借贷反欺诈模型的建立奠定了基础。
1 相关工作
机器学习包括若干个流程,如数据收集、数据预处理、特征工程以及模型训练与验证。在实际应用中,这些步骤通常是由机器学习工具库和各类计算包临时拼接在一起,随着数据量和工具库复杂性的增加,机器学习应用越来越难以扩展。为了解决此问题,许多框架引入了可自动构建节点的、端到端的高效流水线,如由Google 开发的著名的TensorFlow[6]、专注分布式系统的MLbase[7]、面向大规模数据分析的KeystoneML[8]、擅长复杂模型构建的Theano[9]以及侧重于系统的灵活性和高效性的Apache MxNet[10]等。这些框架证明,通过优化机器学习的工作流程,能够简化机器学习代码编写,并借助分布式计算技术进一步提高机器学习程序运行效率,而不要求用户具有分布式系统和低级语言的强大背景。虽然这些框架能够帮助构建高效的机器学习应用,但是机器学习模型的预测性能仍然在很大程度上取决于开发者和研究人员的专业知识——如何灵活选择现有的技术来创建并选择特征,以及如何选择模型和调整参数使其达到最佳性能。本文侧重于在网络借贷数据集上自动生成和选择一组有用的特征,这个过程不需要使用者具备金融领域的专业知识,便能提高分类算法的性能。
近几年,深度神经网络被大量用于计算机视觉领域。自2010 年以来,ImageNet 每年都会举办视觉识别比赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)[11],许多物体识别领域顶尖成果也于此诞生。例如:夺得了2012 年ImageNet图像识别冠军并由此引发神经网络应用热潮的AlexNet[12];将网络层数由数十层大幅提高至上百层的2015年冠军ResNet[13]。随着神经网络的层数增加,网络架构越来越复杂,一定程度上推动了对自动发现模型结构的研究,该领域也被称为网络结构搜索。在过去几年中,研究人员使用强化学习设计了对网络结构进行快速和有效的搜索方法[14-15]。2018 年,Google Research 展示了一种基于进化算法的搜索方法,产生的深度神经网络比早期阶段的强化学习搜索表现更好[16]。通过多层感知器或卷积神经网络,深度学习能够自动生成合适的特征。但是,深度学习任务依赖于大量带有标签的数据来训练网络,对于借贷欺诈识别任务来说几乎是不可能的。本文旨在进行模型结构优化前就能从原始数据中提取更多有用的信息,同时将网络结构搜索与自动特征工程结合使用,可能会在机器学习问题上得到更好的效果。
将重复繁琐的任务交给计算机,使人类从这种劳动中解放,是计算机科学的一个重要目标。为了在机器学习领域实现这一目标,诞生了自动机器学习(Automated Machine Learning,AutoML)这一研究方向。自动机器学习旨在实现在给定数据集与学习任务上具有泛化能力的系统,使得机器学习流程自动化而无需人工干预[17]。近年来,自动机器学习引发了学术界的高度关注,相关技术得到了飞速发展,涌现出了许多成熟的自动机器学习工具,如Auto-WEKA[18-19]和Auto-sklearn[20]都实现了可扩展的、通用的机器学习框架。Auto-WEKA 将自动机器学习问题规约为算法选择和超参优化问题,并使用基于树的贝叶斯优化方法进行超参数设置。Auto-sklearn 在基于Auto-WEKA 的全局优化方式上,进一步构建了多达15 种的分类算法,并通过识别类似的数据集来使用过去训练获得的知识。现阶段的自动机器学习研究将重点主要放在模型的选择和调参过程的自动化上,在特征工程方面对特征进行不同形式的编码,使其统一转化为能被机器学习模型接受的数值为主。本文主要关注的是如何自动在给定数据集上生成大量有用的特征。这部分工作发生在训练和调参之前,能够降低后续模型构建的成本。
2 方法设计
深度特征合成(Deep Feature Synthesis,DFS)是一种自动为关系数据集生成特征的算法,在2014年由麻省理工学院计算机科学与人工智能实验室的Max Kanter 等人提出。该算法遵循数据中的字段和不同数据集之间的关系,沿一定的路径顺序叠加应用函数以创建最终特征集。因此,新特征可以看作具有一定的深度,这个算法也被称为深度特征合成算法。
2.1 基本要素
DFS 的输入是一组实体以及与之关联的表。表中实体的每个实例都有唯一的标识符,可以通过使用标识来引用相关实体的实例。实例的特征具有属于数值、分类、时间戳和自由文本等数据类型之一的属性。
假设有数据集E1…K,其中每个实体有J个特征,是第k个实体的第i个实例的特征j的值。
给定实体、数据表和关系,DFS 定义了实体级别和关系级别两个不同级别的函数集。实体特征是对一个单独的实体对应表中的特征计算得出的;关系特征是通过分析两个相关的实体得出的。
2.1.1 实体特征
实体特征(Entity Feature,efeat)是通过将实体函数作用于得到的,包括将实体表中的现有特征转换为另一种类型的值,如将分类字符串数据类型转换为预定格式的数值。将时间戳转换为工作日(1~7)、月中的某一天(1~30)、一年中的一个月(1~12)以及一天中的小时(1~24)4 个不同的特征。还有将函数作用于实体的整个特征值集合,即:

计算累积分布函数时,需要在形成密度函数,然后计算的累计密度值。
2.1.2 关系特征
根据两个实体关联方式的不同,实体间的关系可分为前向关系(Forward)和后向关系(Backward)。前向关系是实体集El的实例和实体集Ek的i实例之间的、依赖于m的关系。例如,在电子商务中,订单实体与顾客实体之间具有前向关系,即每个订单只与一个客户有关。后向关系存在于实体集Ek的i实例与实体集El中所有1…m实例之间。例如,顾客实体与订单实体间具有后向关系,即可能有许多个订单指向同一个顾客。
直接特征(Direct Feature,dfeat)作用于前向关系,将i∈El中所有相关特征转换到m∈Ek。联系特征(Relational Feature,rfeat)作用于后向关系,通过在xk:,j|ek=i上应用数学函数来提取实体El中特征j的所有值并加以拼接,得到在Ek中标识符为的特征。使用最小值(min)、最大值(max)和计数(count),都会得到联系特征,可以表示为:

2.2 算 法
考虑有K个实体的数据集E1…K,DFS 的目标是为Ek提取出实体特征、直接特征和联系特征。所有与Ek有前向关系和后向关系的数据集表示为EF和EB。首先应该合成直接特征和联系特征,以便将实体函数应用于更多的结果。为了生成Ek的联系特征,需要使用EB,因此需要搜索EB中每个实体的所有特征。类似的,为了生成Ek的直接特征,需要搜索EF中每个实体的所有特征。最后,将所有联系特征和直接特征添加到Ek,生成实体特征。

图1 深度特征合成步骤
此外,考虑到实际应用中每个实体可能分别具有其他相关实体,算法递归地执行以上步骤生成特征。当达到某个深度或是没有相关实体时,递归可以终止。
2.3 可生成的特征数量分析
DFS 可以枚举的特征空间增长非常快。假设算法为给定实体生成的特征数量为z。由于特征合成的递归特性,为实体创建的特征数量取决于为其所有相关实体创建的特征数量。因此,如果算法递归i次,以zi代表每次递归中创建的特征数量,假设数据集中的所有实体原本具有O(j)个特征,且具有O(n)个前向关系和O(m)个后向关系。
首先为O(m)个后向相关实体合成关联型特征。假设有O(r)个关系函数,则可以为每个实体合成O(r·zi-1)个特征。接着为O(n)个前向相关实体合成直接型特征,此处将增加O(zi-1·n)个特征。最后,使用j个原始特征以及前面所合成的共O((m+n)·r·zi-1)个新特征生成实体特征。假设有O(e)个关系函数,则会再增加O(e·j+e((m+n)·r·zi-1))个特征。
将所有联系特征、直接特征和实体特征合起来,有:
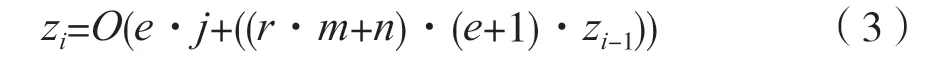
在第一次递归z0时,仅能合成实体特征,即z0=O(e·j)。记p=(r·m+n)·(e+1),q=e·j,有:

将递归式展开至z0,可以得到:

将z0=O(e·j)=q带入式(6),得:

将p和q展开,得到最终表达式:

3 实验验证
3.1 数据集简介
网络借贷数据集由某银行提供,表中包含37个字段,除标签外的所有信息均为脱敏加密的字符串。分类器无法直接输入非数值类数据类型,因而特征工程对于此类数据集是不可缺少的。目前,自动特征工程软件与工具包也都无法处理这些字符串,需要做进一步的处理。数据集共有40 077 条含有标签的记录,其中标签为正常的记录32 990 条,标签为欺诈的记录7 068 条。异常与正常记录的比例约为4.6:1。数据集的不均衡很容易导致分类器训练时发生过拟合,误认为这些规则也适用于训练集之外的其他集合,使得训练好的算法在训练数据上验证时效果非常好,但在新测试样本上的效果却剧烈下降。
3.2 数据集划分
在机器学习任务中,通常尽可能多地利用搜集到的样本进行训练以提高精度。考虑到算法在借贷数据集上容易发生过拟合问题,此处对数据集进行分割。分割的比例为训练集:验证集:测试集=6:2:2,且各子集的标签值分布应尽可能与原数据集一致,减少因数据划分过程引入额外的偏差而对最终结果产生影响。这可以通过分层抽样实现,按照总体标签的比例,从不同层中随机抽选样本。
3.3 模型评估指标
KS值是一个常用来衡量风控模型优劣的指标,非常适合用于评估借贷反欺诈分类的效果。计算KS值时涉及到的指标、含义和计算方法如表1 所述。

表1 指标、含义和计算方法
3.4 实验性能
实验组分为1 个基准组和2 个对比组,每组的设置如表2 所示。

表2 实验分组
基准组的K-S曲线如图2 所示,人工特征组的K-S曲线如图3 所示,自动特征组的K-S曲线如图4 所示。
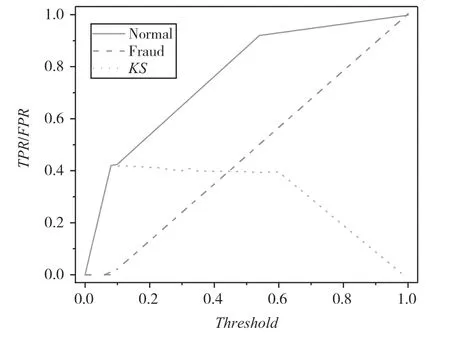
图2 基准组的K-S 曲线
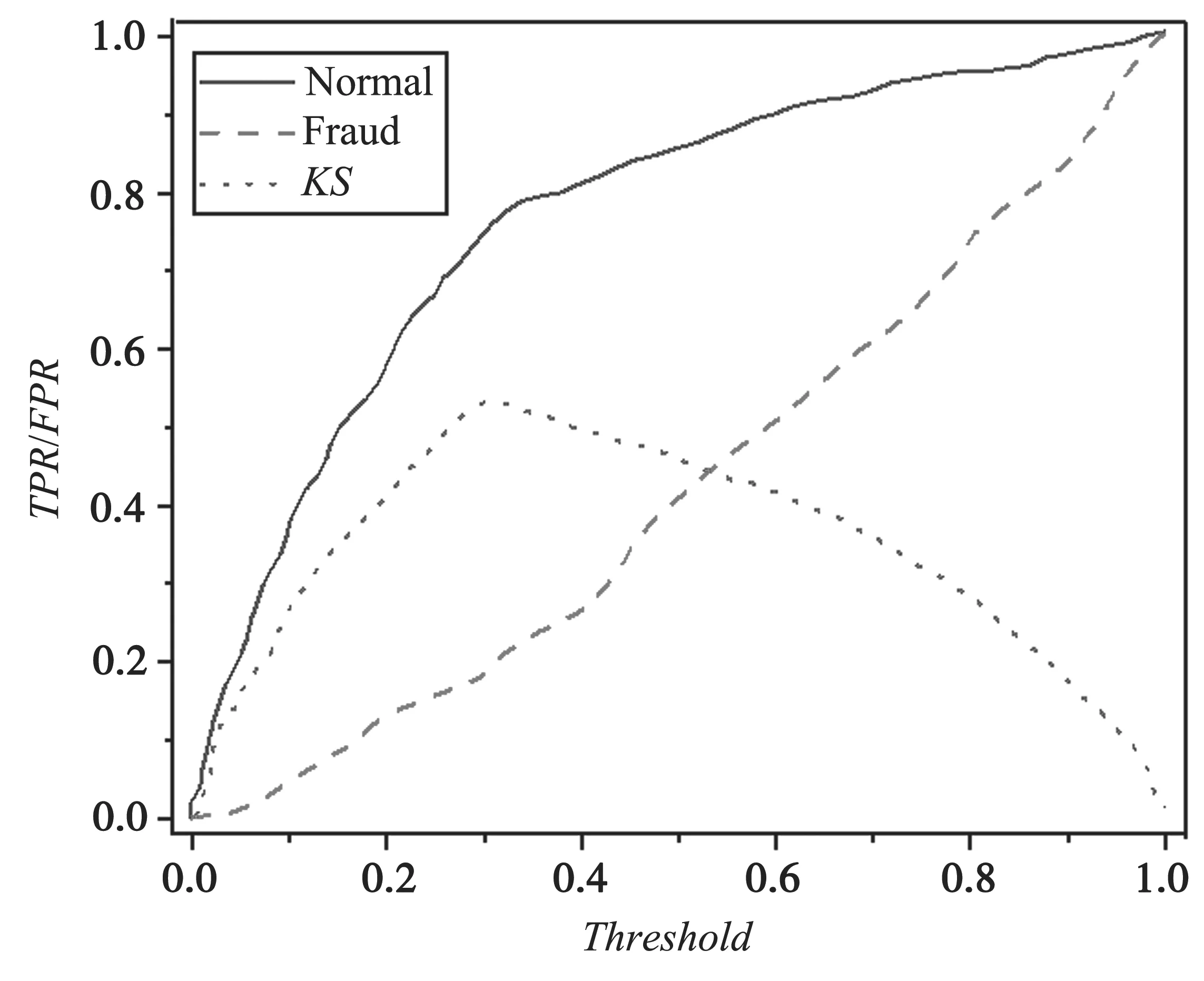
图3 人工特征组的K-S 曲线
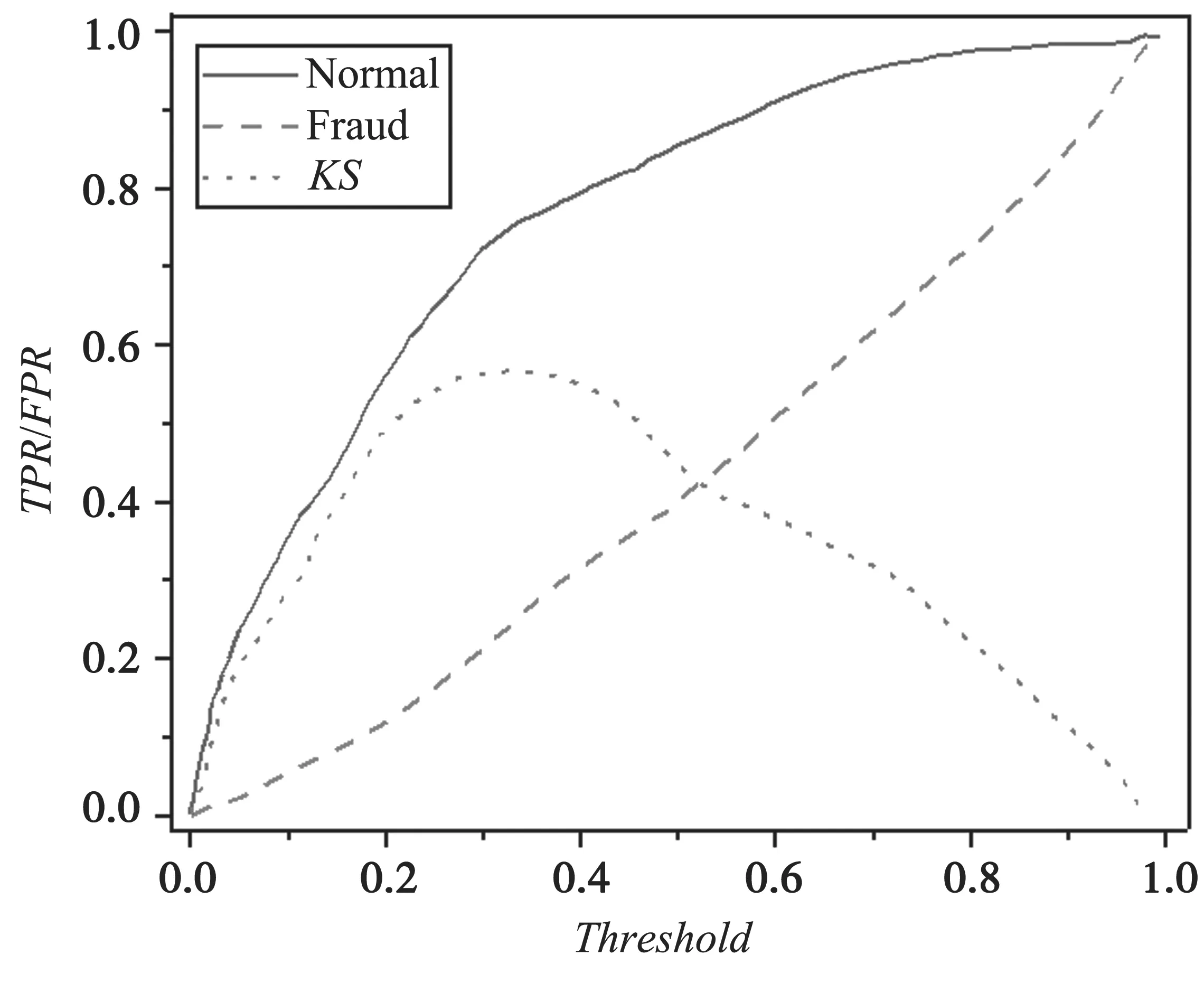
图4 自动特征组的K-S 曲线
3 个实验组的特征数量、特征构造时间和预测结果的K-S值如表3 所示。

表3 实验结果
分析实验结果,可以得到以下结论。
(1)使用原始特征的基准组的召回率在0.55左右,KS值为0.446 7,说明仅将数据集的原始特征编码转换为数值类时,这些信息几乎可以看作是随机的,难以作为分类算法分类和预测的评判标准。
(2)通过人工构造一些特征,KS值得到了提高(0.550 5),且召回率大幅提升到了0.8 左右,说明参考特征组构造的特征是十分有效的。但是,手动构造特征需要对数据集进行仔细分析,找出字段间的联系,这一过程十分耗时。
(3)相较于基准组,自动特征组的KS值提高了约36%,达到了0.607 4,且在特征数量方面提高了近18 倍。相较于人工特征组,自动特征组的KS值得到了约10%的提升,在特征数量方面也提高了近11 倍,同时构造特征的时间大幅缩短(约节约了90%的时间)。值得注意的是,自动组相比于人工组,在召回率基本不变的情况下,进一步降低了误判率,这在实际应用中十分重要。误判率越低,代表正常用户被判断为欺诈用户的几率越低,因此对正常用户的打扰也就更小。
4 结语
本文基于现有的特征工程相关研究,探索如何自动地为网络借贷数据集构造有助于机器学习分类效果提升的特征,使不具有金融和机器学习领域知识的普通用户也能参与反欺诈模型构建的工作。这个过程中,本文设计并实现了适用于网络借贷数据集的自动特征工程方案。通过对比实验,比较了分别在使用原始特征、手动构造的特征和自动构造的特征几种情况下,机器学习模型分类和预测的效果,验证了方案的有效性。自动特征工程是一个庞大的、多领域交叉的学科,本文只对其在网络借贷欺诈背景下的应用进行了探讨,在优化特征选择方法、整个机器学习流程的自动化以及增加特征工程适用的分类器范围等方面还有待进一步的研究。
猜你喜欢
眼科新进展(2022年12期)2022-12-29
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
汽车维修与保养(2019年7期)2020-01-06
中国外汇(2019年18期)2019-11-25
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
当代陕西(2019年5期)2019-03-21
电影(2018年8期)2018-09-21
领导决策信息(2017年9期)2017-05-04
