
一种关系型数据非结构化的转换方法
2020-11-19 03:12林徐
榆林学院学报 2020年6期
林 徐
(1.安徽三联学院 计算机工程学院 ,安徽 合肥 230601;2.安徽省普通高校交通信息与安全重点实验室,安徽 合肥 230601)
随着互联网技术的进步和进步,人们在日常生活中越来越多地使用互联网。因此,大量的数据是以各种格式生成的。如何存储数据、分析数据并找到有用的信息成为重要的问题。云计算技术正是针对这些问题而发展起来的,如Google在2003年、2004年和2006年分别针对分布式文件系统、并行计算和分布式计算以及NoSQL数据库提出的Google文件系统(GFS)、MapReduce 架构和BigTable。Google提出了一个将数据分割成小块并在节点上执行相关作业的方法框架。结果将从节点收集、集成,然后返回到用户。这样,MapReduce将单节点处理作业转换为并行处理作业,提高了执行效率。
随着“云计算”技术的普及,一方面,现在仍有多数企业使用传统的关系数据库(RDB)处理业务。伴随着数据的争夺,RDB遇到了海量数据的处理瓶颈。另一方面,使用云数据库处理数据是一种可行的解决方案。这就需要企业将数据从RDB迁移到云数据库,进行分布式存储和非结构化转换,以提高数据库使用方面的性能。
然而,NoSQL与传统的数据库不同,数据文件在不同的虚拟机(VM)中被分割和分发[1]。RDBMS将数据存储在表(关系)中,表(关系)之间又有关系。从而数据被格式化和索引,因此从这些关系中获取相关数据可能需要从2x表中提取它们,其中x>=1。然而,大多数NoSQL存储(例如HBase)没有标准化和索引。数据可以转储到一个或几个独立的表中,从而减轻了对联接操作的需要。HBase不支持联接操作,因此,如果执行联接操作,并且表的数据分布并存储在不同的VM上,则会出现问题。这是本文要解决的问题。
1 关系型数据导入NoSQL
1.1 相关平台与工具的特点
1.1.1 Hadoop
Hadoop是一个Apache顶级开源项目,它提供了一个分布式系统架构,主要由Hadoop分布式文件系统(HDFS)和MapReduce组成。HDFS是在GFS概念的基础上发展起来的,它将节点连接在一起,形成一个大规模的分布式文件系统。HDFS设计用于处理大量数据,并提供安全的存储体系结构以避免硬件故障。它还设计了一次读写多文件访问模型,提供了简单的一致性机制,提高了数据转换的吞吐量。HDFS在不同的数据节点上复制数据,以确保在任何数据节点崩溃时用户仍然可以访问其数据[2]。
1.1.2 HBase
HBase也是一个Apache开源项目,是一个基于HDFS的分布式容错、高度可伸缩、面向列的noSQL数据库。HBase用于对非常大的数据库进行实时读写随机访问。从逻辑角度看,HBase中的数据是按标签表组织的。每个HBase表都存储为一个多维稀疏映射,包含行和列,每一行都有一个排序键和任意数量的列。表单元格已版本化。默认情况下,它们的版本是HBase在插入单元格时自动分配的时间戳。对于同一行键,每个特定列可以有多个版本。每个单元格都由列族和列名标记,因此程序始终可以标识给定单元格包含的数据项类型。单元格的内容是一个不间断的字节数组,由Table+Row Key+Column Family:Column+Timestamp唯一标识。表行按行键排序,行键也是字节数组,用作表的主键。所有表访问都是通过表主键进行的,对HBase表的任何扫描结果都会被扫描到Map/Reduce作业中。根据Map/Reduce作业结果到更快的查询响应时间和更好的总体吞吐量的并行扫描[3]。
1.1.3 Sqoop
图1显示了Apache Sqoop系统架构。Sqoop专注于在RDB和Hadoop之间迁移大量数据。通过Sqoop,用户可以轻松地以命令行模式将数据迁移到HDFS或HBase。
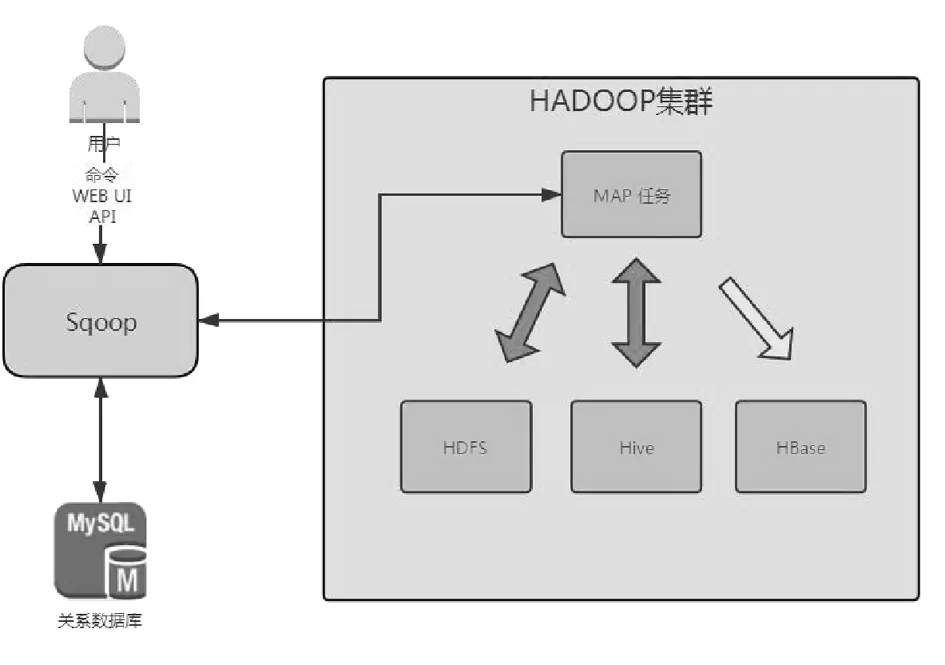
图1 Apache Sqoop 系统架构
Apache Sqoop是为从RDB到NoSQL数据库的数据迁移而开发的。Sqoop在2012年成为顶级项目,用户可以将大量数据迁移到云环境中,并通过云技术进行访问。Apache Sqoop将一个表分成四部分,并由Mapper通过JDBC连接将它们迁移到HDFS或HBase[4]。
1.2 关系型数据的导入
本文利用Apache Sqoop将MySQL关系数据库的数据导入到Hadoop平台中HBase非结构化数据库中。导入数据的过程分为两个步骤,第一步,收集与导入的数据相关的所有元数据信息。第二步是向Hadoop集群提交Map作业。在这一步中,实际的数据传输是通过使用在上一步中捕获的元数据来完成的。导入的数据保存在HDFS的目录中。默认情况下,这些文件使用逗号分隔的字段,用新行分隔不同的记录,这样就很容易覆盖已复制的数据的格式。
Apache Sqoop客户端可以为导入过程设置映射任务的数量。这意味着从MySQL获取数据的并行查询的数量可以由客户端控制。图2显示了从MySQL导入100条记录的两个、三个和四个Map作业的结果。表1显示了用于导入100条记录的两个、三个和四个Map作业的比较。
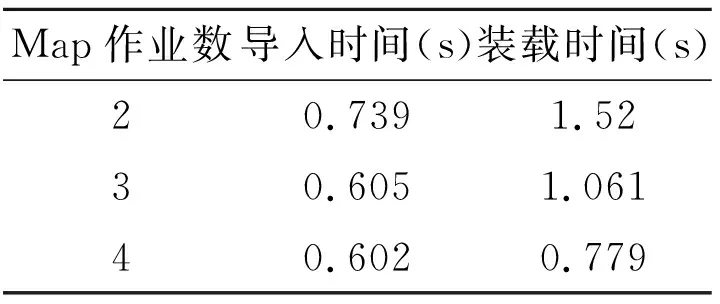
表1 Map作业数和时间关系

图2 Map作业数和时间关系图
2 模式转换和相关性感知技术
2.1 关系模式非结构化的转换
关系模式和非关系模式是两种完全不同的数据库模式。因此,两种模式间的转换也是关键的问题之一。在关系数据库中,存在着多表联接相互关联的特点。例如以下的3个关系(表):
●学校(学校编号,名称,语言)
●考试(编号,学校号,通过人数,失败人数,总人数,考种编号)
●考试种类(编号,名称,网站地址)
该模式表示一个简单的学校考试记录。每所学校可以招收学生参加任何数量的考试,每项考试都由一个特定的考试机构管理。所以基本上我们有两个一对多的关系,就是学校->考试和考试种类->考试。这种关系显示了RDBMS中关系或表之间的相关性。由于HBase或大多数NoSQL存储中的表之间没有严格的关系,我们必须找到一种方法来标识这些数据并将它们合并到单个或几个独立的表中。
我们将转换过程分为两个阶段。在第一阶段,根据HBase的数据模型和特点,提出了一种启发式的方法将源数据库的关系模式转换为HBase模式。然后,第二阶段生成源架构和目标架构之间的映射。因此,源数据库中的数据可以根据在第二阶段生成的模式映射转换为目标表示。
我们的做法是将相关数据存储在一起。这包括以下三个重要步骤。以上述关系模式为例,我们将其转换为HBase模式。假定学校表中有2行,主键编号是000078和000079。其中000078在考试表中有2条记录通过学校号这个外键与之关联。也就是说,这两个表中有相关的数据。我们将按照以下步骤将架构更改为兼容的HBase架构。
步骤1:将表表示为列族:这涉及将所有或相关的RDB表存储在一个HBase表中。在这一小步中,我们必须留意将有多少列族存在在HBase表中。如果表之间存在关系,则可以将其数据合并到一个列族中。HBase不能处理表中超过三列的族。另一种方法是有几个独立的HBase表,这些表的源只是RDBMS模式中的相关表。从上述关系模式中的表中,我们的转换生成了两个列族。为了简单起见,我将分别使用school和exam来表示学校和考试表。例如,学校表转换成school:id,school:name,school:language这样的列族。考试表也作同样的转换。
步骤2:将引用的数据放在一个RowKey下(仅限JOINS),这将帮助我们在从多个表中提取数据时避免交叉连接。
步骤3:单元格版本的作用(仅限连接):单元格版本帮助我们保留表的多个面,例如,考试表存储在一个RowKey下,而不必将它们存储在许多新的RowKey下。因此,如果我们想检索与特定学校相关联的所有考试,我们可以只获取该RowKey的考试列族的所有版本。这有助于我们避免交叉相乘,而这是非常昂贵的,它完全取决于你的物理内存。默认情况下HBase检索的是最新版本,但您也可以通过扫描来获取特定RowKey->ColumnFamily的所有版本
2.2 相关性感知技术
尽管Sqoop可以方便和有效地将批量数据导入到Hadoop平台的分布式存储中。但是,由于执行Mappers的节点是由Hadoop随机决定的。因此,数据被随机存储在数据节点上,这会导致数据的局部性不好。
在数据库操作中,查询被用来访问数据库和显示具有不同含义的数据。JOIN是根据特定列合并两个表的常用操作。如果两个表的数据分布在8个数据节点上,则为了执行JOIN操作,网络上的数据转换和传递就不可避免。网络上的数据访问速度明显慢于本地磁盘。因此,为了避免网络上的数据转换,提高JOIN操作的性能,需要增加数据的局部性。因此,我们采用相关性感知技术,根据必要信息将数据分配给节点来解决这个问题。
关系数据库通常有一个日志文件来存储操作,包括配置、修改和查询。日志文件通常用于监视数据库。此外,记录的操作可以视为访问数据库的查询。因此,一旦分析了日志文件,我们就可以知道查询访问频率较高的表。
表2通过分析日志文件中的查询,演示了一个显示表关联度(TC)的矩阵。以Table1和Table2为例,度为15,Table示根据历史记录有15个查询同时访问这两个Table。同样,根据日志,有45个查询访问Table4和Table5。
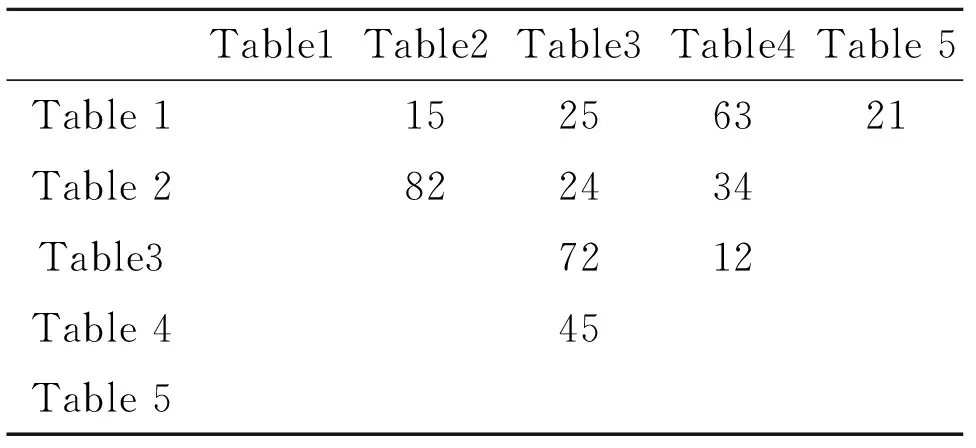
表2 表相关性
除了表的相关性程度外,还可以考虑表的大小。在某些情况下,即使表的相关性很高,也不必将两个相对较小的表放在一起。Hadoop将一个任务分配给其中一个节点,该节点拥有更多的数据以降低数据转换的成本。在本研究中,我们也应用此概念,以根据表格大小来改善效能。
以下给出了普通Sqoop方法和采用了相关性感知技术后的Sqoop(CA_Sqoop)在考虑了表布局后的性能对比。其中参数:
表的大小:1~10GB;
表相关性:1~1000;
节点容量:2~50;
表数量:20~300;
节点数:60~100。

图3 引入20个表到小集群
图3和图4是将表导入集群时节点容量不同的结果。可以看出,随着节点容量的增加,无论是小集群还是大集群,Sqoop导入数据后,集群处理能力,即数据局部性,变化不大。这是由于Sqoop数据导入后随机存储的原因。图3给出了使用小集群的数据局部性的改进,而图4给出了使用大集群的结果。可见,使用了相关性感知技术后的Sqoop在提高节点容量的同时,也克服了Sqoop的数据局部性问题。
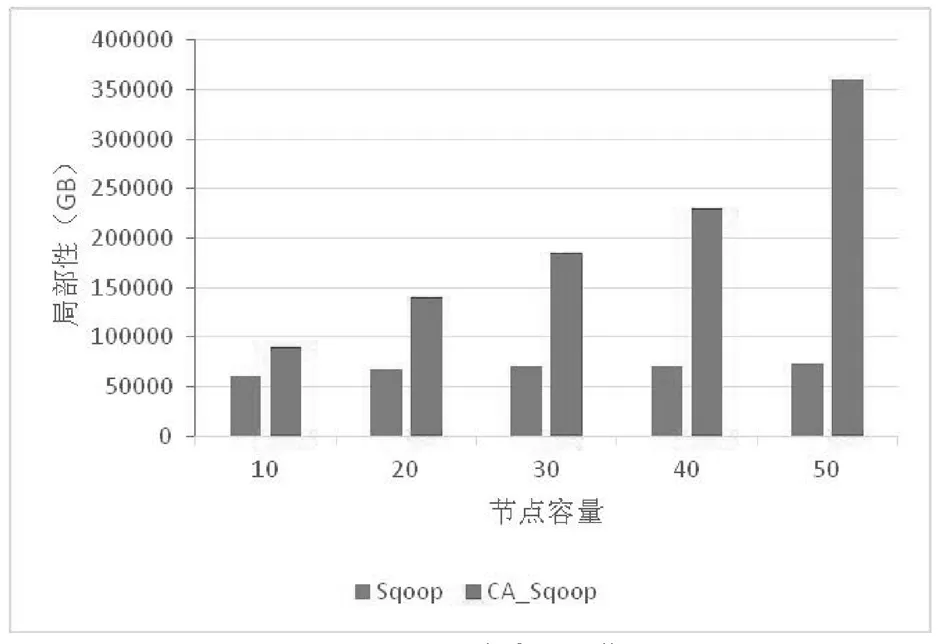
图4 引入100个表到大集群
3 结论
利用Sqoop,可以轻松地将关系数据库的数据批量导入到Hadoop分布式集群中。从而实现数据的非结构化。在数据批量导入过程中,Map作业数可以加快数据导入的速度,但对装载的速度影响不大。在数据转换过程中要充分考虑到源数据的关联度,合理地设计NoSQL的列族。同时,通过日志分析表间的相关性,安排数据在各节点间的布局,可以大大提升数据转换的性能。
猜你喜欢
电脑爱好者(2021年8期)2021-04-21
数学大王·趣味逻辑(2020年6期)2020-06-22
数学大王·趣味逻辑(2020年5期)2020-06-19
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
西部皮革(2018年6期)2018-05-07
中国交通信息化(2017年3期)2017-06-08
中学科技(2017年5期)2017-06-07
知识就是力量(2017年2期)2017-01-21
中学科技(2015年6期)2015-08-08
