
基于LightGBM算法的MR网络信号预测
2020-11-18 08:12:50张硕伟裴明丽高有利刘贤松中国联通网络AI中心上海00050科大国创软件股份有限公司安徽合肥30000
邮电设计技术 2020年10期
张硕伟,裴明丽,高有利,黄 铭,刘贤松(.中国联通网络AI中心,上海 00050;.科大国创软件股份有限公司,安徽合肥 30000)
1 概述
随着LTE网络大规模应用以及市场竞争的白热化,用户越来越重视自身的感知体验,因此运营商对覆盖优化和质量优化的要求也越来越高[1]。现阶段的无线网络优化工作[2],主要采用CQT(Call Quality Test)、DT(Driving Test)和用户投诉等方式发现覆盖问题和质量问题[3-6]。但是CQT和DT方式需要运营商投入大量的时间和人力,用户投诉方式又严重影响用户感知和满意度。
针对传统方法存在的弊端,本文提出了一种基于LightGBM算法的网络信号预测的新方法,使用MR数据和LightGBM算法对未知地区的网络信号进行预测,不仅解决了现有技术数据采集成本高、数据分析过程烦琐等问题,还创新地将AI技术与网络优化相结合,提高无线网络优化的自动化水平。
2 LightGBM算法介绍
在机器学习算法领域,监督学习算法中最常用的2类算法为回归(Regression)算法和分类(Classification)算法[7]。回归算法和分类算法的区别在于输出变量的类型不同,定量输出或者连续变量预测称为“回归”;定性输出或者离散变量预测称为“分类”[8]。而对网络信号预测过程是一个典型的回归问题,因此,可以利用回归算法对网络信号进行精准预测。目前比较流行的回归算法是集成学习Boosting算法中的梯度提升树(GBDT——Gradient Boosting Decision Tree)算法[9-10]和极端梯度提升(XGBOOST——eXtreme Gradient Boosting)算法[11-12]。其中,GBDT算法是一种迭代的决策树算法,该算法由多棵决策树组成,所有决策树的结果累加起来做为最终结果。在机器学习领域中,GBDT是一个经久不衰的模型:
GBDT=Gradient Boosting+Decision Tree
GBDT具有Gradient Boosting和Decision Tree的功能特性,主要优点是训练效果好、不易过拟合且泛化能力较强。通过多轮迭代,每轮迭代产生一个弱分类器,后续每个分类器在上一轮分类器的残差基础上进行训练,如图1所示。
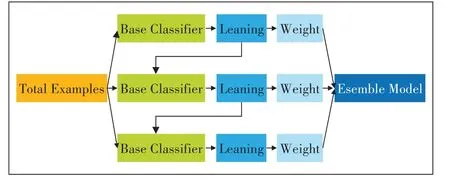
图1 GBDT的模型训练过程
XGBOOST算法是GBDT的改进,它是大规模并行boostedtree的工具,是目前最快最好的开源boostedtree工具包。在XGBOOST之后,微软公司又提出了一种LightGBM算法来增强GBDT的性能[13]。LightGBM是一个实现GBDT算法的框架,主要用于解决GBDT在大规模数据处理上遇到的问题。采用带深度限制的Leaf-wise的叶子生长策略[14],其计算代价小,且避免了过拟合。为了减小存储成本和计算成本,LightGBM算法是一种基于Histogram的决策树算法。此外Light-GBM直接支持类别特征处理,使其性能得到较好的提升。因此,基于以上集成机器学习算法优劣势比较,提出了一种基于LightGBM算法的网络信号预测方法。
3 一种网络信号的预测方法
为了提高算法模型预测的准确性,本文采用了LightGBM机器学习算法和迭代优化的训练方式。该模型算法的整体流程框架如图2所示,整个模型训练过程可分为5个步骤:数据收集、数据处理、模型训练、模型验证和精度评价。
3.1 数据采集与处理
本文采集了某市不同基站的MR原始样本数据,MR数据是一种测量报告,由用户终端周期性上报给基站控制器(包含小区下行信号强度、信号质量等信息),再由基站控制器收集和统计[15]。将采集到的MR数据映射到栅格上,得到栅格基本信息,包括位置信息和小区配置数据,其中位置信息包括区域、经度、纬度、位置类型(室内/室外);小区配置数据包括基站位置、基站高度、小区方位角、工作频段、总下倾角、中心载频的信道号等。具体字段描述如表1所示。
本文提出一种子栅格的概念,将50×50栅格根据道路和楼栋的GIS边界进一步细分成子栅格。首先,将带有经纬度的MR数据进行异常数据清洗和室内室外用户识别;其次,将带有室内室外标签的MR数据映射到对应子栅格之中。同时,为便于对MR数据主邻小区计算处理,根据当前主邻小区的记录数,将单条MR记录拆分多条记录,新增主邻小区标识,包括中心载频的信道号、物理小区识别码和识别邻区CGI等信息。最后,基于小区间和电平值间的相似性,利用Kmeans聚类算法将MR样本点分组,提升子区域内电平值的特征性,得到子栅格的基本信息。
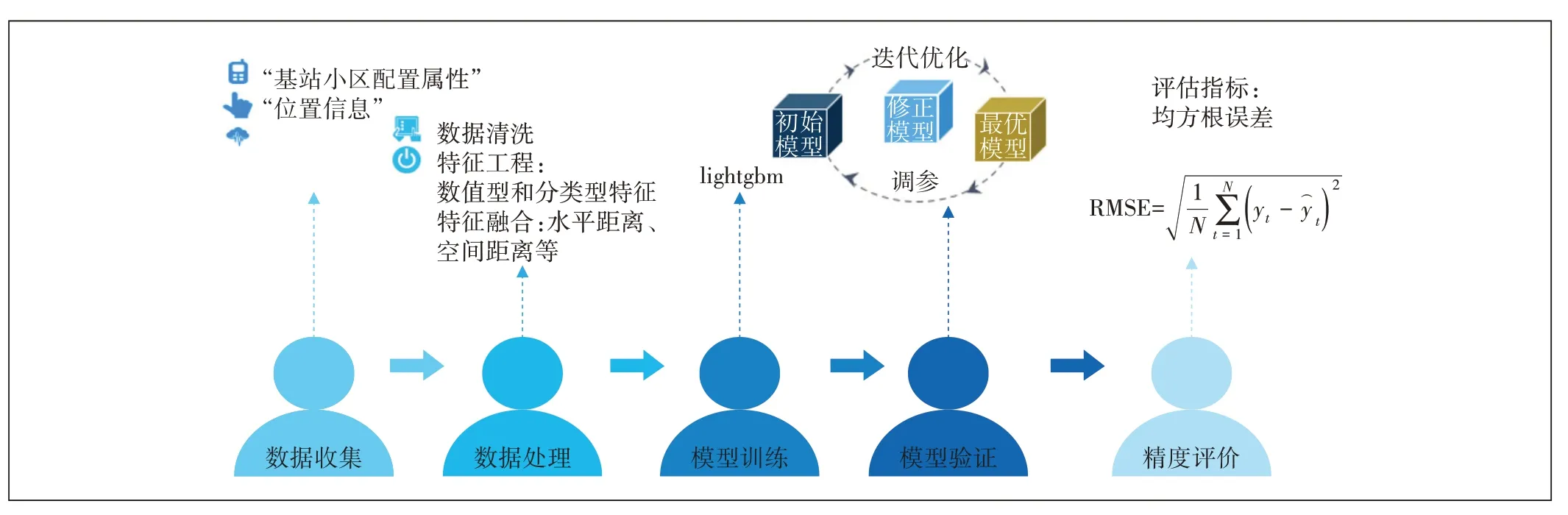
图2 模型整体流程图
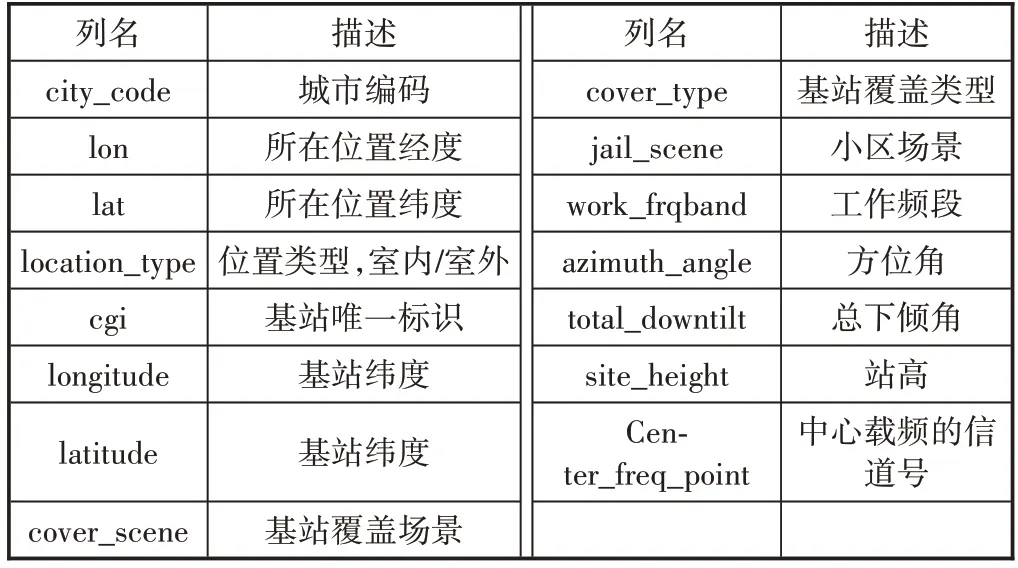
表1 MR原始数据信息表
子栅格信息具体字段信息如表2所示,其中字段rsrp能够用于判断是否需要调整小区的天线天馈角以及确定小区各位置的信号强度。

表2 子栅格信息表
栅格位置信息表反应了每个栅格中子栅格的具体位置信息,具体字段如表3所示。
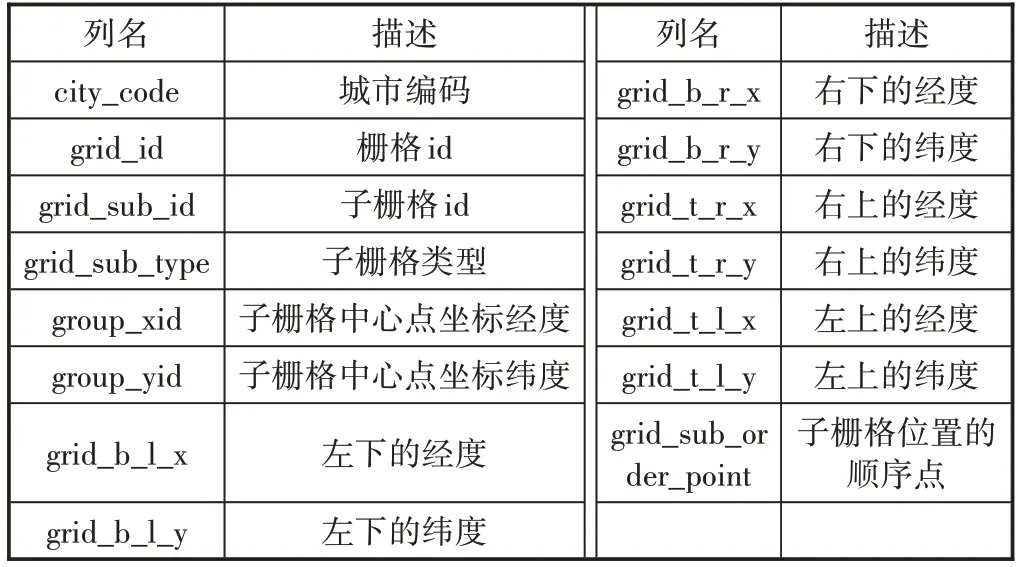
表3 栅格位置信息表
3.2 特征工程
特征工程是机器学习研究课题中最重要的部分。在这一过程中需要找到最能反映分类本质的特征来完成原始数据的分类工作。总之,特征工程的研究是否精细,会直接影响到模型的预测性能。因此,需要对训练数据集进行特征处理。
3.2.1 处理无效值和缺失值
对MR原始样本数据集进行删除、去重和缺失值填充等处理,删除数据集中缺失经纬度以及group_id、date无关字段,去除数据集中重复数据以及中心载频的信道号(center_freq_point)中的空值以平均数填充。
3.2.2 文本数值化
MR原始样本数据集中有很多字段是文本形式,如位置类型(location_type)、基站覆盖场景(cover_scene)、基站工作频段(work frqband)、基站覆盖类型(jail_scene)、基站覆盖类型(cover_type)等字段。文本形式计算机无法识别,需要做数值化映射操作。
3.2.3 特征构造
首先,将子栅格经度lon、子栅格纬度lat、基站经度longitude、基站纬度latitude转化为对应的弧度值lon1、lat1、lon2、lat2,然后分别计算经纬度差值:

其次,计算空间距离,构造相应特征:

最后,计算空间距离,构建相应特征:
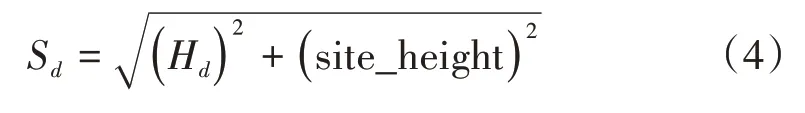
3.3 模型训练
本文研究了包括GBDT、XGBOOST和LightGBM 3种最常用的机器学习算法的区别和特点,通过比较预测精度和复杂度,最终选择了LightGBM作为整个模型的核心算法,并通过Python编程语言实现数据处理和模型训练。其中,Python中的LightGBM参数设置如表4所示。
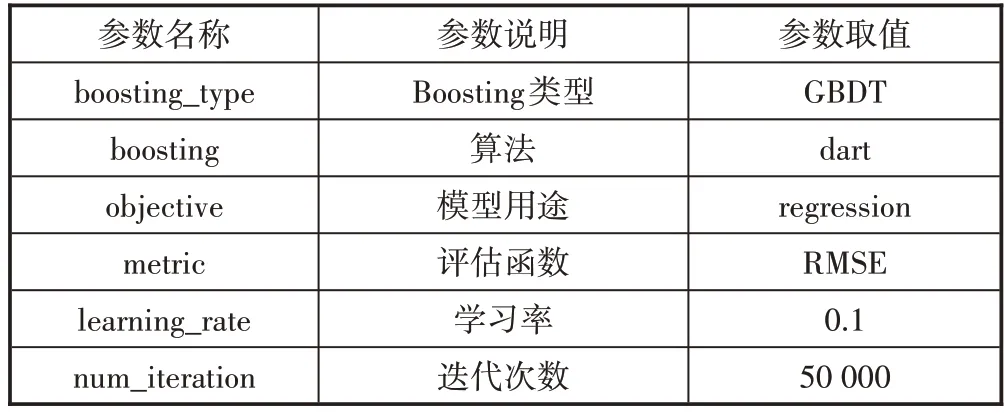
表4 模型参数设置表
3.4 模型验证
为了保障模型的泛化性及精准度,将MR数据集划分为训练数据集和测试数据集,通过MR测试数据集验证模型对新的MR样本数据的判别能力,以测试误差作为模型泛化误差的近似值,最后选择泛化能力强的模型作为最终模型。本文采用留出法划分样本数据集,具体过程如下。
a)将MR样本数据集D划分为训练数据集X和测试数据集C,比例为9∶1。X⋂C=∅,X⋃C=D。
b)将训练数据集X再次划分为模型训练数据集T和模型验证集Y,比例为8∶2。T⋂Y=∅,T⋃Y=X。
c)为了保证训练和测试数据集的随机性,采用对MR样本数据集D多次划分的方式,每次数据集划分模型都会重新训练,计算每次模型训练的rsrp误差率,来反应模型预测效率。

3.5 精度评估
为了保证模型训练后的精确度,采用均方根误差(RMSE——Root Mean Squared Error)来评估其预测精度[16]。RMSE的值越小,说明模型的预测结果越准确,即具有更好的精确度,RMSE公式如下:
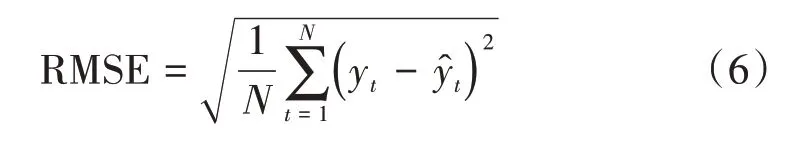
式中:
N——观测次数
yt——信号强度(rsrp)的真实值
4 实验分析
4.1 不同学习率对RMSE结果的影响
如图3所示,横坐标表示迭代次数,纵坐标表示RMSE值。在同样的迭代次数下,学习率为0.3时,RMSE的值最小,即模型预测效果越好。随着迭代次数的不断增加,5种不同的学习率表现出不一样的预测效果,RMSE值越来越小,呈现较为明显的下降趋势,并慢慢地达到收敛状态。此外,也可看出,虽然随着迭代次数的不断增加,其RMSE值越来越小,即模型预测精度有所提升,但模型训练时间也会不断增加。
4.2 不同学习率对rsrp误差率均值的影响
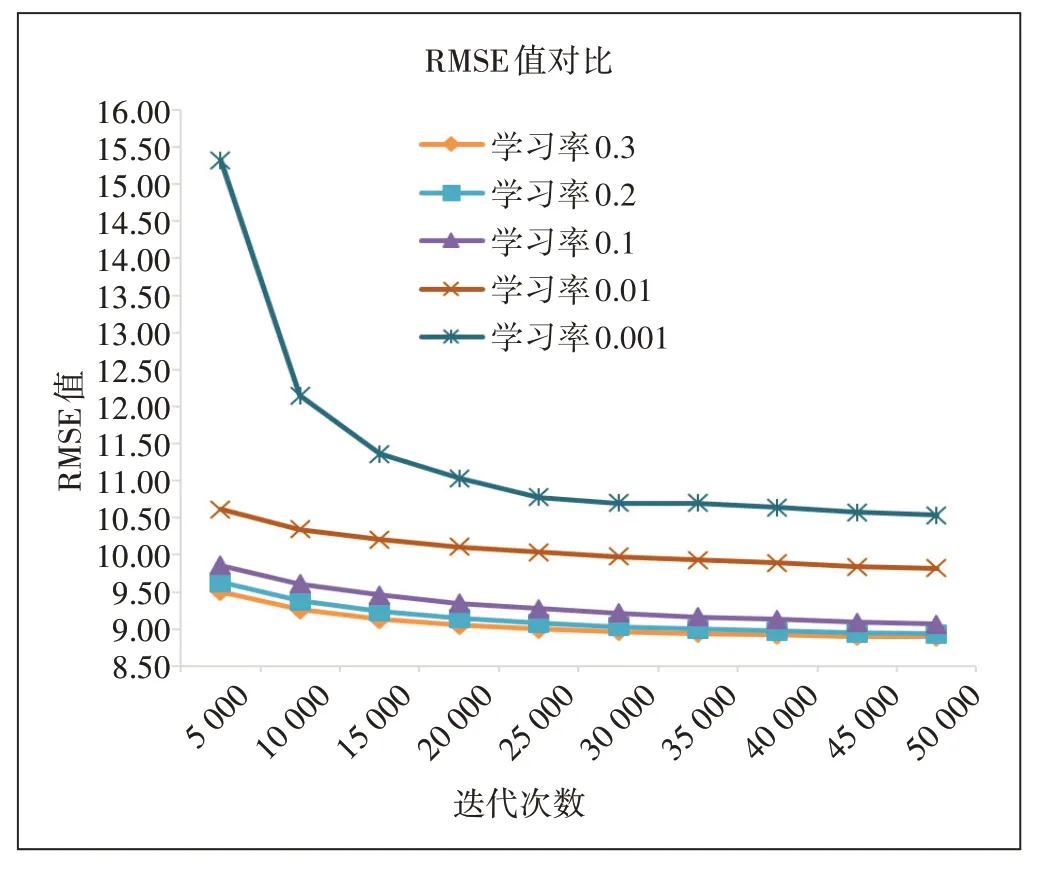
图3 不同学习率的RMSE结果对比
如图4所示,横坐标表示学习率,纵坐标表示所有rsrp误差率的平均值。模型迭代次数为50 000次,随之学习率不断减小,其rsrp误差率均值越来越大,最大差值达到5.1%,即反应了模型效果越来越差。从图4中可以看出,学习率为0.3时,rsrp误差率均值达到最小,模型的泛化性更好。
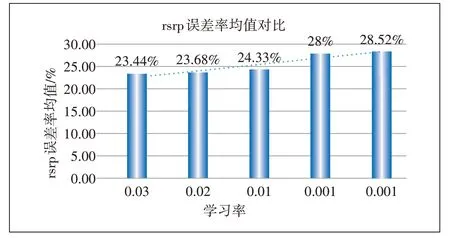
图4 不同学习率的rsrp误差率均值对比
综合图3和图4可知,RMSE值越小,rsrp误差率均值越小,二者相辅相成,并且都能够体现模型对信号预测的效果,RMSE值越小,模型预测精度越高。
4.3 同学习率、不同迭代次数时不同模型RMSE值对比
如图5所示,横坐标表示迭代次数,纵坐标表示RMSE值。从图5可以看出,当学习率为0.3时,随着迭代次数的不断增加,RMSE值越来越小,3个模型均慢慢地达到收敛状态。另外在同样的迭代次数下,Light-GBM模型训练结果RMSE值始终优于XGBOOST和GBDT,其平均预测精度要比XGBOOST高出8.4%,比GBDT高出15.36%。
4.4 同迭代次数、不同学习率时不同模型RMSE值对比
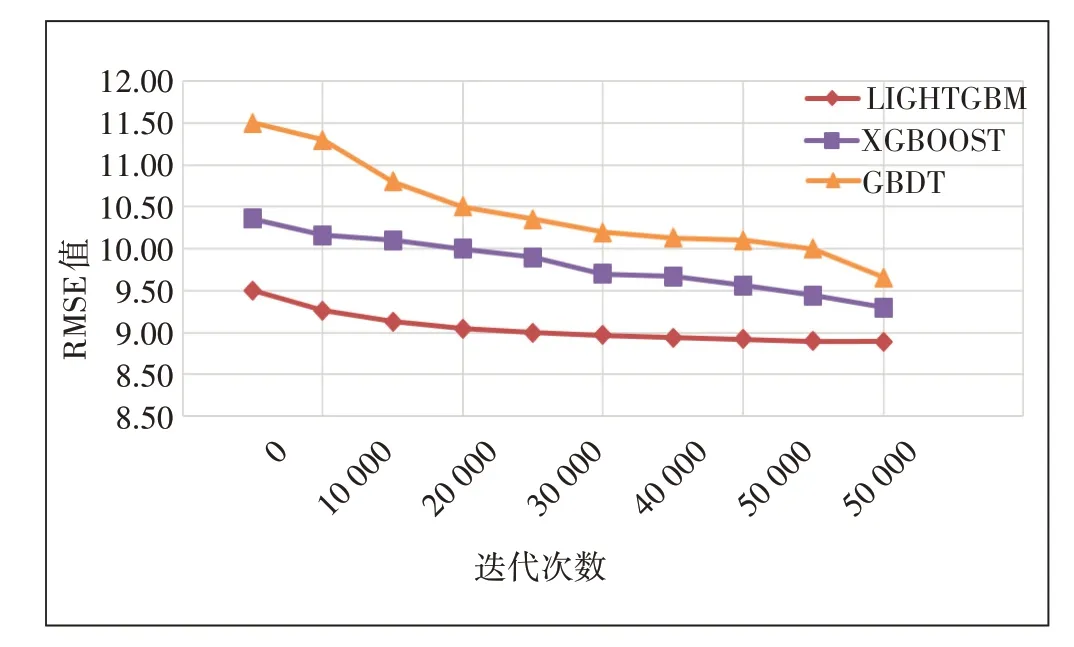
图5 同学习率、不同迭代次数时不同模型RMSE值对比
如图6所示,横坐标表示学习率,纵坐标表示RMSE值。图6反映了当迭代次数为30 000时,随着学习率的不断减小,RMSE值越来越大,说明了3个模型在学习率为0.3时,取得较好效果,在学习率为0.001时,模型效果最差。另外在同样的学习率下,LightGBM模型下训练结果RMSE值始终优于XGBOOST和GBDT,其平均预测精度比XGBOOST高出13.84%,比GBDT高出27.85%。
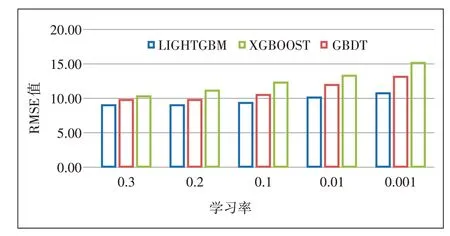
图6 同迭代次数、不同学习率时不同模型RMSE值对比
5 结束语
本文提取了某市各区域基站的MR样本数据,首先对数据进行栅格化并清洗,再对模型进行训练,从网络信号强度预测结果得出:使用LightGBM算法进行预测,修改训练迭代次数和学习率参数,模型训练取得了较好的效果,令人较满意。从rsrp误差率均值可以得出:不同学习率下,随着迭代次数的增加,模型能够快速收敛,且模型训练效果也越来越好。
猜你喜欢
科技创新与应用(2021年31期)2021-11-09 13:11:18
健康大视野(2020年1期)2020-03-02 11:33:53
科技创新与应用(2019年26期)2019-10-24 08:49:44
探索科学(2017年4期)2017-05-04 04:09:47
电脑知识与技术(2017年2期)2017-04-25 13:32:31
中小企业管理与科技·中旬刊(2016年6期)2016-06-20 14:51:04
中国交通信息化(2016年8期)2016-06-06 03:56:25
移动通信(2015年17期)2015-08-24 08:13:10
弹箭与制导学报(2015年1期)2015-03-11 15:32:23
发明与创新(2015年29期)2015-02-27 10:39:43
