
基于导数光谱与主成分分析的小麦籽粒赤霉病识别
2020-11-17 10:59琚书存汪志存林芬芳谷春艳潘正高张东彦
安徽大学学报(自然科学版) 2020年6期
琚书存,汪志存,林芬芳,谷春艳,潘正高,张东彦*
(1.安徽省农村综合经济信息中心,安徽 合肥 230031;2.安徽大学 农业生态大数据分析与应用技术国家地方联合工程研究中心,安徽 合肥 230601;3.南京信息工程大学 遥感与测绘工程学院,江苏 南京 210044;4.安徽省农业科学院 植物保护与农产品质量安全研究所,安徽 合肥 230031;5.宿州学院 信息工程学院, 安徽 宿州 234000)
中国是世界上种植小麦面积最广的国家,种植面积高达2.4×105km2[1].小麦是中国粮食来源之一[2],所以小麦病害一直为研究热点.赤霉病俗称麦穗枯,为小麦的常见高发病,感染赤霉病的小麦籽粒含有以脱氧雪腐镰刀菌烯醇为主的真菌毒素[3-4].该病严重影响小麦产量及出粉率,其中的真菌毒素通过小麦籽粒危害人畜生命健康[5-6].小麦赤霉病检测主要使用化学生物方法[7],此方法存在效率低、成本高等问题,因此迫切需要一种快速、无损识别方法.尽管文献[8]分析了气象因子与小麦赤霉病的关系,找到了与小麦赤霉病相关性最强的气象因子,建立了预测模型,但不能识别感染赤霉病的小麦籽粒.
近年来,高光谱遥感技术具有光谱范围窄及波段多的特性,且目标识别精度高[9-10],已成为精准农业的重要技术[11].文献[12]利用高光谱成像技术,对健康及患赤霉病的小麦籽粒进行分类,准确度达92%.文献[13]利用高光谱成像技术检测受镰刀菌感染的小麦,用主成分分析对健康和患病小麦进行识别,研究结果表明若对最佳分类时期内的小麦样本进行识别,可大大提高分类的精度.文献[14]找到了3个有效的高光谱窄波段间隔并将其用于检测小麦赤霉病,分类效果显著.文献[15]对感染赤霉病的小麦籽粒图像进行预处理和特征提取,提取图像的形态和纹理特征参数,根据相关性分析选择最优特征,建立线性判别分析、支持向量机和BP (back propagation)神经网络识别模型.
笔者以健康和感染赤霉病的小麦籽粒为研究对象,采用高光谱成像仪扫描小麦籽粒获取高光谱图像,使用图像处理技术分离籽粒和背景后,经导数、多元散射校正(multiple scattering correction,简称MSC)及主成分分析(principal component analysis,简称PCA)处理后,分别利用Fisher线性判别分析(Fisher linear discriminant analysis,简称FLDA)和BP神经网络模型识别小麦赤霉病籽粒,对比评估指标,确定最优的组合.该文研究结果以期为小麦收购、加工等生产环节提供帮助,降低赤霉病籽粒对公众健康的潜在威胁.
1 方 法
1.1 实验设置
小麦籽粒样本均来自安徽省农科院试验田,实验场地位于安徽省农业科学院(117°13′E,31°89′N),小麦品种为西农979.实验田划分为4块10 m×10 m的方形区域.待小麦成熟脱粒后,由植保专家从4块试验田中挑选检测用的健康小麦籽粒和感染赤霉病的小麦籽粒样本400个 (健康籽粒200个、染病籽粒200个),其中280个样本(健康籽粒140个、染病籽粒140个)用于识别模型的建立,120个样本(健康籽粒60个、染病籽粒60个)用于识别模型的验证.
1.2 数据采集及预处理
该文使用的SOC710E成像光谱仪,其光谱范围为374~1 030 nm,波谱分辨率为2.3 nm,光谱仪成像尺寸为1 392×1 392像元.为降低可见光影响,实验将光谱仪放入黑色箱,镜头垂直向下,将箱四周的卤素灯光聚于底部中心.底部平铺黑布,将小麦籽粒置于黑布,调整光谱仪的高度、焦距和曝光度,确保籽粒成像清晰.卤素灯距离黑布的高度为40 cm,曝光18 ms后采集籽粒图谱数据.
图像噪声主要是光照强度不均匀形成的.为尽可能减少噪声对实验结果的影响,需校正图像.图像校正后的光谱反射率为
(1)
其中:Roriginal为光谱仪直接测得的光谱反射率,Rdark为光谱仪在无光源环境下测得的光谱反射率,Rwhite为白板的光谱反射率.
为了获得小麦籽粒的光谱,使用ENVI5.3软件中的感兴趣区域工具提取并观察小麦籽粒影像和光谱.从影像中手动提取健康籽粒(sound and none-damaged,简称SND)和感染赤霉病的患病籽粒(fusarium-damaged kernel,简称FDK),图1为患病和健康小麦籽粒样本的图像.从图1可看出:健康的小麦籽粒饱满,颜色呈棕褐色;染病的小麦籽粒干瘪,胚芽处呈白色至粉红色.
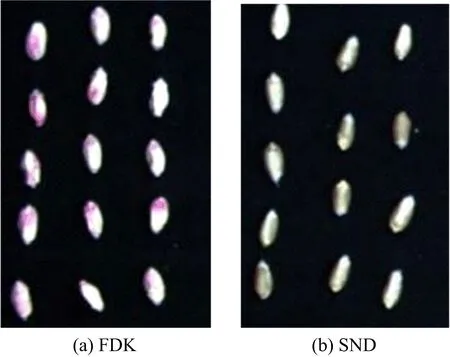
图1 患病和健康小麦籽粒样本图像
高光谱成像仪在成像时很容易受到外界环境和噪声的影响,因此须对高光谱图像进行如下预处理.
(1) 导数光谱.为了凸显光谱的微小变化,对光谱反射率求1阶导数.1阶导数的光谱反射率为
(2)
其中:Xi为波长i的光谱反射率,Xi+Δλ为波长i+Δλ的光谱反射率,Δλ为波长i与i+Δλ的波长间隔.
为消除因光强不均匀、样本表面不平导致的基线漂移,再求导一次.2阶导数的光谱反射率为
(3)
其中:Xi,1st为波长i的1阶导数光谱反射率,Xi+Δλ,1st为波长i+Δλ的1阶导数光谱反射率.
(2) 多元散射校正.多元散射校正(multiplicative scatter correction, 简称MSC)技术能降低散射对光谱反射率的影响,提高原始光谱的信噪比,校正样本的平移和偏移.建立一个理想光谱,对理想光谱和样本光谱作一元线性回归,求偏移系数和平移系数,根据这两个系数修正其他样品的光谱.实际应用中,很难找到样本的理想光谱,故将所有样本的平均光谱作为理想光谱[16].多元散射校正的相关公式为
(4)
其中:X为理想光谱反射率,n为样品数,Xi是第i样本的原始光谱反射率,mi和bi分别为偏移系数和平移系数,Xi,MSC是经多元散射校正后得到的光谱反射率.
(3) 主成分分析.通过主成分分析能快速降维.主成分分析的步骤如下:
步骤1 数据矩阵标准化(按照行向量计算);
步骤2 计算标准化后的数据矩阵的协方差矩阵;
步骤3 求协方差矩阵的特征值及其特征向量;
步骤4 计算主成分(按照行向量计算).
1.3 识别模型及评估指标
1.3.1 识别模型
FLDA和BP神经网络是两种常用的识别模型,在高光谱分析中应用较广.
FLDA的思路是转换原始样本点的投影,寻找新的1维线性函数来代表原始多维样本点投影,再根据该1维线性函数判别样本点的类别[17].
BP神经网络,是一种经误差逆向传播算法训练的多层前馈神经网络.利用Matlab R2016b软件中的initlay函数,对网络权重和偏值进行初始化,利用adaptwb函数对网络权重和偏值进行动态调整.BP神经网络由输入层、隐含层、输出层构成,其中输入层有3个通道,隐含层及输出层均有1通道.输入层的变量是按光谱贡献率大小排序后位列前3的主成分值,输出层的变量是预测标签值(健康样本为1,患病样本为0).学习率、迭代次数分别设置为0.01,2 000.
实验中,随机选取70%试验数据作为训练集、30%试验数据作为验证集.
1.3.2 评估指标
总体分类精度是基于混淆矩阵(confusion matrix)的评估指标,其表达式为
P0=Pr/Pall,
(5)
其中:Pr为正确分类的样本数,Pall为样本总数.
KAPPA系数既考虑了正确分类的样本数又考虑了错误分类的样本数,其相关公式为
(6)
其中:Pe表示样本预测数与真实数的一致性,ai为第i类样本真实数目,bi为第i类样本预测数目,c为类别数,n为总样本数.KAPPA绝对值小于等于1,KAPPA绝对值越大,分类效果越好.
敏感性(sensitivity)为识别模型判定为健康的小麦籽粒中真正属于健康的概率,特异性(specificity)为识别模型判定为患病的小麦籽粒中真正属于患病的概率.敏感性和特异性计算公式分别为
(7)
(8)
其中:Tp为预测为健康的健康小麦籽粒样本数,Fn为预测为健康的患病小麦籽粒样本数,Tn为预测为患病的患病小麦籽粒样本数,Fp为预测为患病的健康小麦籽粒样本数.
2 结果与分析
2.1 健康及患病小麦籽粒样本的原始光谱特征
图2是健康及患病小麦籽粒样本的原始光谱反射率曲线.从图2可看出,健康小麦籽粒的原始光谱反射率曲线轮廓与患病小麦籽粒的基本一致,但患病籽粒原始光谱反射率曲线明显高于健康小麦籽粒,这可能是因为小麦感染赤霉病后,籽粒中的水分、蛋白质、淀粉的含量均低于健康小麦籽粒[18],导致反射光变强,从而有更高的反射率.

图2 健康及患病小麦籽粒样本的原始光谱反射率
2.2 不同预处理下小麦籽粒的光谱特征
图3为多元散射校正后健康及染病小麦籽粒样本的平均光谱反射率.从图3可看出,多元散射校正后,在可见光波段(380~780 nm) 曲线平滑,在近红外(780~1 030 nm)波段健康籽粒的反射率与患病籽粒的差异较大.

图3 多元散射校正后健康及患病小麦籽粒样本的平均光谱反射率
图4为健康及染病小麦籽粒样本1,2阶导数的平均反射光谱率.从图4可看出,两类小麦籽粒样本的1,2阶导数的平均光谱反射率在一些波段几乎重合,但在1阶导数的374~800 nm波段,2阶导数的530~805 nm和930~1 030 nm波段,二者的平均光谱反射率差异较大.

图4 健康及染病小麦籽粒样本1,2阶导数的平均光谱反射率
对4种光谱数据(原始光谱、MSC、1,2阶导数)进行主成分分析,可得到特征分布图.不同预处理方法在主成分上提取信息的效果不同.前3个主成分包含了数据的大部分信息,因此该文选用前3个主成分的特征进行分析.图5为不同预处理的患病和健康小麦籽粒的第1, 2主成分的特征分布,图6为不同预处理的患病和健康小麦籽粒的第2,3主成分的特征分布.由图5,6可知,经1阶导数—PCA处理后,能明显区分患病和健康小麦籽粒前3个主成分的特征分布,而经原始光谱—PCA,MSC—PCA,2阶导数—PCA处理后,患病和健康小麦籽粒的前3个主成分特征分布有明显的重叠.

图5 不同预处理的患病和健康小麦籽粒第1,2主成分的特征分布

图6 不同预处理的患病和健康小麦籽粒的第2,3主成分的特征分布
2.3 不同数据处理方法及识别模型的评估指标对比
表1为不同数据处理方法及识别模型的评估指标对比.由表1可知:对于原始光谱—PCA处理方法提取的特征,2种识别模型的总体分类精度均达到84%左右,但是KAPPA系数均较低,患病和健康样本错分的均较多;对于MSC—PCA处理方法提取的特征,2种识别模型总体分类精度均较低,其原因是该方法不能凸显健康籽粒与患病籽粒主成分特征间的差异;对于2阶导数—PCA处理方法提取的特征,2种识别模型的精度均最低,其原因是原始光谱数据2次求导后的光谱反射率降低,有用信息被削弱,不能凸显患病与健康籽粒的光谱差异;1阶导数—PCA—BP神经网络组合的总体分类精度最高,其值为91.67%.

表1 不同数据处理方法及识别模型的评估指标对比
3 结束语
笔者利用SOC710E成像光谱仪采集健康和感染赤霉病的小麦籽粒高光谱图像,分别经MSC,1,2阶导数预处理后,采用主成分分析提取小麦籽粒的光谱特征,使用Fisher线性判别分析和BP神经网络模型识别,比较不同数据处理和模型组合的评估指标.结果表明:1阶导数—PCA—BP神经网络组合的总体分类精度最高,其值为91.67%.该文存在的问题为:所采集的小麦籽粒样本数量较少,可能对结果产生一定影响;另外,该文采用的主成分分析快速降维且提取了主成分,虽提取的主成分包含原始变量的大部分信息,消除了波段间冗余或重叠信息,但忽略了贡献率很小而对输出变量有较强解释能力的主成分,此对识别性能产生影响.笔者将针对这些问题进行后续研究.
猜你喜欢
冶金能源(2022年5期)2022-10-14
农业知识(2022年9期)2022-10-13
——缺陷度的算法研究
条码与信息系统(2022年3期)2022-07-05
汽车电器(2022年6期)2022-07-02
今日农业(2021年9期)2021-11-26
今日农业(2021年9期)2021-07-28
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20
汽车文摘(2018年2期)2018-11-27
数学大世界·中旬刊(2017年3期)2017-05-14
高中生学习·高三版(2016年9期)2016-05-14
