
用户评论与产品销售量的相关性研究
2020-11-16 22:34李跃武梁凯
电力与能源系统学报·下旬刊 2020年4期
李跃武 梁凯

摘要:通过LSTM模型和Word2Vec对数据进行预处理以及量化评论,可以获得客户对产品偏爱程度的相关信息。建立了视觉监控模型来及时监视客户的评论,通过聚类分析,来确定产品的评分预警点。研究结果发现:对于微波炉产品,评分、评论和帮助等级与产品评论数量有很大的相关性。对于吹风机、婴儿奶嘴、微波炉的评分预警点分别为1、2、2。
关键词:LTSM;线性回归;SPSS;聚类分析
文本的情感倾向性分析,即针对每一条文本,实现正向、中性和负向的三分类,以识别其情感倾向。以此为基础,去建立视觉监控模型,处理评分评定和评论文字情感倾向性问题。通过分析之前的数据来检测数据预警点。
1 基于LSTM模型的数据处理
1.1 数据处理流程
首先,归纳具有相同product_parent类型的案例,即具有相同product_parent特征的案例总数,获取CNT_PP作为因变量。然后,使用LSTM长期和短期存储网络处理独立变量审阅标题和审阅主体中的现有文本。利用LSTM模型,训练了一个文本分类器,它可以识别三种情绪:积极,中立和消极。
具体流程如下:
(1)进行句子的特征提取。利用多维向量解决单词的多向散度。为了解决高维向量的变化范围,使用word2vec模型来拟合实际文本评估。
(2)完成单词分类并转换为高维向量后,通过建立递归神经网络,将矩阵形式的输入编码转换为低维一维向量,同时保留最有用的信息。
(3)经过上述处理后,评论文本被重新定义为否定/肯定评论,并对处理后的注释进行情感评分。(负分+正分=1),得分示例表1所示。
(4)对三种产品的评估得分进行分级([0,0.2],(0.2,0.4],(0.4,0.6],(0.6,0.8],(0.8,1.0)),并计算频率。
1.2 数据处理分析
对自变量进行分类,计算平均值并将其视为一个。
首先,将position_probs的值分为五个级别,每个级别的间隔为0.2。数字越大,position_probs的值越高。帮助等级的价值分为五个等级,每等级间隔为100,分别用数字表示。数值越大,帮助等级的数值越大。
接下来,计算上述处理后的每个product_parent的评分评分,有用票数和positive_probs的平均值,并将其标准化。
2 线性回归模型的建立和求解
2.1 模型建立
本次线性回归模型仅以微波炉产品为例,来分析产品的评分,评论和有用评分与产品受欢迎程度之间的相关性,使用线性回归模型解决了该问题。首先,建立线性回归方程:
2.2 模型求解
根据分析,R值大于90%,R平方和经调整后大于80%。在此分析中,D-W残留测试的值为2.212。参考Durbin Watson表并结合R的相关值,可以认为该回归模型的拟合效果非常好。通过分析,可以看出方差分析的显著值为0.00,小于标准值0.05,说明自变量Star_avg_01,positive_avg_01,Helpful_avg_01和因变量Cnt_pp之間具有显著的线性关系。同时,我们得到线性回归方程中的相关系数,α=1.807,β=-23.164,γ=337.313,θ=26.346。
通过分析,残差的分布没有明显的规律性,表明变量之间没有自相关,因此可以直接使用回归模型。从以上分析可以看出,对于微波炉产品,评分,评论和帮助等级与产品评论数量有很大的相关性。
3 检测模型的建立与求解
3.1 模型准备
(1)数据处理
在评价文本分析的过程中,情感分析和量化也是基于LSTM模型而进行的,这里不再赘述。获得每个评估的情感分数后,将其记录为正值。
(2)模型的基础
我们的可视化模型侧重于评分和评论文字情感倾向性的数据测量。通过对先前数据的分析,我们可以得到数据预警点进行预警。我们的预警点是确定阈。当测得的数据低于预警点时,公司应注意持续关注,并采取一定措施,避免舆论失控等严重事故对产品销售的不利影响。
接下来,我们将为三种产品(吹风机,微波炉和奶嘴)建立数据测量方法和相应的警告点。
3.2 模型建立
假设每个评论分布在接下来的十个评论中。换句话说,假设s评论的有效性仅在S+1到S+10评论中起作用。为了便于数据处理,最后的十个评论首先被删除,然后进行预测。
(1)评分预警点的建立
为了确定预警点,首先选择每个评论文本的评分(记录为评分)和此文本之后的10个评分的平均值(记录为影响评分),然后对这些数据进行无监督的聚类处理。
完成上述步骤后,我们将使用它们的真实数据对三个产品进行建模,并获得数据的聚类结果。
将十个评论之后的每个评论平均值的评分评定值导入SPSS中,以进行KNN无监督聚类分析。分析之后,可获得以下两个聚类中心:(5,4.1)和(2,3.8)。将这个聚类结果与日常生活相联系,可以将2和5作为警告点,分别表示评分的低级警告点和评分的高级警告点。对于微波炉来说,通过相同的分析步骤以及在相同的聚类分析操作之后,两个聚类中心分别为(4,3.7)和(1,3.3)。将两个值分别作为高级别警告点和低级别警告点。对于婴儿奶嘴来说,两个聚类中心分别为(4.8,4.3)和(2.0,4.3)。将两个值分别作为高级别警告点和低级别警告点。
(2)文本评论预警点的建立
为了确定预警点,在此选择了每个文本注释的情感极值(记录为评分)和此文本后的10个评分情感极值的平均值(记录为影响等级),并选择了这些数据由无监督的群集处理。
因此,评论通常具有三个区别:正面,负面和中立。因此,在处理该实验时,我们选择将实验数据汇总为三类。
在KNN无监督聚类分析之后,吹风机的相关数据可以获得三个聚类中心:(0.93,0.83)(0.66,0.77)(0.35,0.55)。在这里,将0.93和0.35视为高警告点和低警告点。对于微波炉,我们采用相同的分析方法,在KNN无监督聚类分析之后,可以获得三个聚类中心,分别为(0.91,0.83)(0.58,0.73)(0.00,0.002)。在此,将0.91和0.00分别视为高警告点和低警告点。对于婴儿奶嘴,三个聚类中心分别为(0.93,0.88)(0.66,0.76)(0.38,0.72)。在这里,将0.93和0.38视为高警告点和低警告点。
3.3 建模结果
通过聚类分析模型对上述数据进行处理后,可以建立基于评分和舆论分析的实时检测模型。
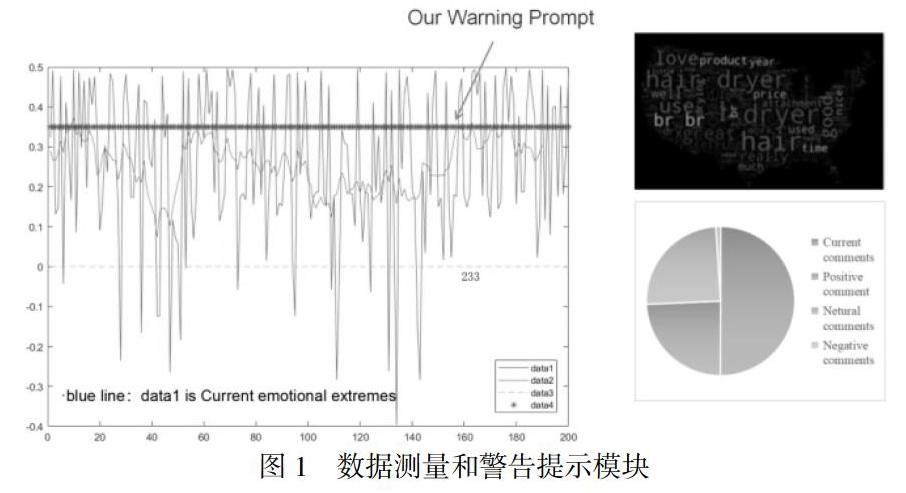
实时监控模型的机制是检测评分和情绪极性的当前趋势,并以视觉形式显示出来,以便及时监控购物评价,实现评论文本的高频有效词汇云显示。在视觉检测系统中,我们使用正面和负面的词云来显示评论文本,并检测负面/正面/中性评论的数量和舆论的总体变化趋势,实时销售和其他参数作为数据测量手段,向制造商提供信息。圖1是一个示例(以吹风机的销售为例,并假设时间是最后一次售出吹风机)。
4 总结
本文通过LSTM模型实现了用户评价文本的三种分类和量化,并以此为基础,建立了关于评分、评论和有用评分与产品受欢迎程度之间的线性回归模型,证明了产品的销量与其评分、评论和有用评分有很强的相关性。
在量化评论的基础上,本文提出了可视化检测模型,通过聚类分析,求得了三种产品的预警点;通过对吹风机的模拟来看,也取得了很好的效果。
参考文献:
[1] 王坤亮. 汉语情感倾向自动分类方法的研究[J]. 软件, 2013, 34(11): 73-76.
[2] 姚天昉, 程希文, 徐飞玉, 等. 文本意见挖掘综述[J]. 中文信息学报, 2008, 22(3): 71-80.
作者简介:李跃武(1999-10),汉,男,山东聊城,本科在读,研究方向:用户评论与产品销售量的相关性研究。
猜你喜欢
中国科技纵横(2016年15期)2016-12-27
大经贸(2016年9期)2016-11-16
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
科技视界(2016年9期)2016-04-26
科技视界(2016年1期)2016-03-30
