
基于深度学习的个性化音乐推荐算法研究
2020-11-13 03:38余莉娟
微型电脑应用 2020年10期
余莉娟

摘要:互联网技术和电子信息技术的迅速发展为整个时代提供了巨大的计算能力,个性化推荐系统成为时代产物的缩影。结合常用的推荐系统核心算法,设计了一种针对个性化音乐的Apriori改进算法,此算法通过用户信息进行深度学习,利用候选矩阵压缩的方法进行推荐优化,采用准确性、召回率等参数作为评价标准。以Last.fm音乐网站的部分数据作为分析样本,对选定音乐按个性化音乐推荐方式进行试验,Apriori改进算法在准确率和召回率方面均得到优化,推荐效果更优。在考虑推荐数量的前提下,Apriori改进算法的准确率和召回率均高于Plaucount算法,而相似度方面低于Plaucount算法。
关键词:深度学习;推荐系统;个性化;音乐
中图分类号:G643
文献标志码:A
ResearchonPersonalizedMusicRecommendationAlgorithmBasedonDeepLearning
YULijuan
(CollegeofArt,ShangluoCollege,Shangluo726000,China)
Abstract:RapiddevelopmentoftheInternettechnologyandelectronicinformationtechnologyhasprovidedhugecomputingpowerforthewholeera,andpersonalizedrecommendationsystemhasbecometheepitomeoftheproductoftheera.Combinedwiththecommoncorealgorithmofrecommendationsystem,thispaperprovidesanimprovedApriorialgorithmforpersonalizedmusic.Thisalgorithmappliesuserinformationforindepthlearning,candidatematrixcompressionforrecommendationoptimization,accuracy,recallrateandotherparametersasevaluationcriteria.TakingpartofthedataofLast.fmmusicWebsiteastheanalysissample,theselectedmusicistestedaccordingtothepersonalizedmusicrecommendationmode.TheAprioriimprovedalgorithmisoptimizedinaccuracyandrecallrate,andtherecommendationeffectisbetter.Onthepremiseofconsideringthenumberofrecommendations,theaccuracyandrecallrateofAprioriimprovedalgorithmarehigherthanthatofPlaucountalgorithm,andthesimilarityislowerthanPlaucountalgorithm.
Keywords:deeplearning;recommendationsystem;personalization;music
0引言
伴隨着互联网技术和电子信息技术的迅速崛起,大数据技术、云计算技术、机器人技术、人工智能技术、深度学习技术[1]等方面的发展尤为突出,对整个信息时代的进步与发展提供了巨大的计算能力。在如此海量的信息中,快速准确地找到所需信息变得越来越重要,而且有价值。由此而诞生的推荐系统[23]成为了用户需求与内容之间的桥梁,既可以满足用户找到感兴趣的潜在内容,也能够更好地展示冷门内容,发掘潜在用户。
当今社会已拥有更为强大的包容性,不同领域也均呈现出独有的个性化和多元化,个性化推荐系统则能够满足不同用户的需求,精准地为用户提供更好地体验,由此产生了巨大的商业价值,成为互联网企业争相抢夺的“蛋糕”。
目前,个性化推荐系统早已得到广泛认可,并悄然融入到我们的生活中。音乐作为一种古老的艺术形式,能够为人们带来愉悦,但从海量的音乐作品中精准地找到满足用户需求的音乐,则需要个性化音乐推荐系统根据用户行为筛选适合用户的个性化音乐,满足用户在当时情景的需求,从而达到“众口可调”的目的。
1推荐系统及核心算法
电子商务领域的推荐系统应用最为广泛,随着互联网在各领域的不断渗透发展,音乐推荐系统也映入眼帘,根据用户偏好、音乐描述信息等内容构建推荐模型,将满足用户需求的音乐内容推送出来。目前,常用的推荐方法主要分为基于内容的推荐方法、协同过滤推荐方法和混合推荐方法三种类型[4]。
(1)基于内容的推荐算法[5]
该方法为一类传统的推荐方法,其基本思路就是根据用户的历史信息,对用户的偏好行为进行特征分析,得到用户偏好集合,将这些集合与代推荐内容进行信息匹配,从而实现推荐。常用的音乐推荐算法有基于标注内容的推荐算法和基于音乐特征的音乐算法[6]。
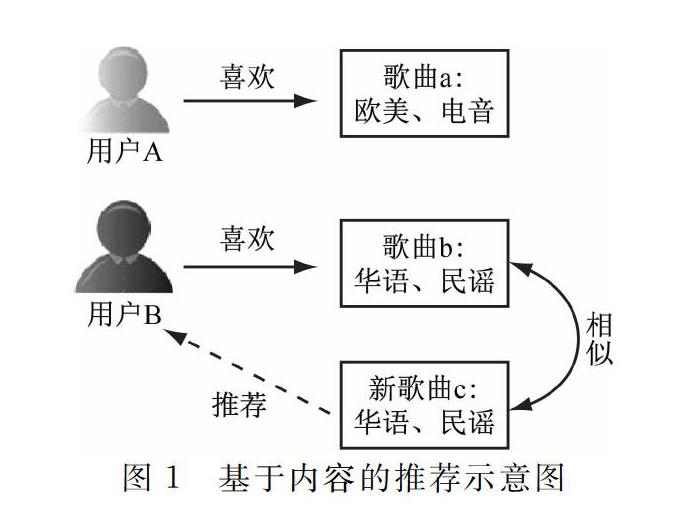
以基于音乐标注内容的推荐算法为例,用户A和用户B对音乐的偏好类型分别为欧美、电音和华语、民谣,其中欧美、电音、华语、民谣均代表歌曲的风格和类型,当新歌曲c出现时,华语和民谣就成为该歌曲的标注内容,属于特征信息,推荐系统则会根据这些特征信息优先向用户B推荐,从而实现精准推荐,如图1所示。
(2)协同过滤推荐算法
鉴于协同过滤算法具有普遍适应性的特点,该算法被广泛应用于众多领域。利用用户偏好的相同性或相似性进行内容推荐是该算法的核心思想。协同过滤推荐算法主要包含基于用户的协同过滤推荐算法、基于物品的协同过滤推荐
算法和基于模型的协同过滤推荐算法3种类型[7]。
以基于用户的协同过滤推荐算法为例,用户A、C在歌曲偏好的相似程度更高,如图2所示。
推荐系统首先了解到两位用户对歌曲偏好的历史数据,再利用数据挖掘或深度学习的方式建立预测模型,虽然用户A没有关注歌曲d,但推荐系统仍可将歌曲d向用户A实行预测推荐。
(3)混合推荐算法
单一的推荐算法在使用过程中都存在不足和局限性,很难满足准确推荐的要求。随着用户个性化要求的日益严苛和数据量的激增,需结合多种推荐算法发掘用户信息和需求信息之间的相关性。目前混合推荐算法的发展方向主要有加权的混合、切换的混合、融入其他因素的混合和分层混合四种[68]。
1)加权的混合如式(1)。
fu,i=α1s1u,i+α2s2u,i+…+αnsnu,i
(1)
式中:u——任一用户;
i——任一物品;
αn——不同的权重系数;
sn——不同的推荐算法。
2)切换的混合如式(2)。
fu,i=β1u,is1u,i+β2u,is2u,i+…+
βnu,isnu,i
(2)
式中:β1u,i——用户u推荐物品i时,snu,i所占的比重。
3)融入其他因素的混合如式(3)。
fu,i=∑nj=1λjsju,i,e1,e2,…,ek
(3)
式中:ek——需要特别考虑的因素。
4)分层的混合如式(4)。
fu,i=g∑nj=1λjsju,i
(4)
式中:g()——外层嵌套推荐算法;
∑nj=1λjsju,i——内层推荐算法,加权、切换或融入其它因素的混合。
2个性化音乐推荐方法
2.1改进的Apriori算法原理
关联规则主要应用于数据挖掘中发掘用户行为,最早由Srikan提处[8],已在教育、保险等众多领域内得到广泛应用。Apriori算法是关联规则挖掘算法中的基本类型之一,属于一类频集理论递推的方法,主要依靠“频繁项集的所有非空子集必定是频繁的”[9]这一性质得以实现。
Apriori算法通常是在首次循环实现对数据库的扫描后得到1阶大项集;在后续的第k次循环中对k-1阶大项集Lk-1(第k-1次循环时产生)进行Apriori_gen运算,从而得到Ck,即k阶候选项集;继续对数据库进行扫面后得到Ck的支持数,进一步会得到不小于最小支持数的k阶大项集;对上述步骤进行重复,当出现某一阶的大项集为空时,算法则会停止。
Apriori算法的详细过程如下:
L1=large1-itemsets;
fork=2;Lk-1≠φ;k=k+1do
Ck=Apriori_genLk-1;//构造候选项集
Foralltransactionst∈Ddo
Ct=subsetCk,t;//搜索事物t中包含的候选项集
ForallC∈CtdoC.sup=C.sup+1;Endfor//计算支持数
Endfor
Lk=C∈CkC.sup≥minsup;//得到k階大项集
Endfor
L=∪kLk
Apriori算法同其他算法一样,也具有自身的优缺点。优点在于当支持度较高时,数据库的扫描次数会较少且空间复杂程度低,缺点就是在数据库扫描过程中会产生海量的候选集,存在重复扫面的现象出现。由于Apriori算法存在耗时长、效率低的劣势,本文通过候选矩阵压缩的方法进行了优化,在准确性和效率方面均有所提升。具体步骤如下:
1)扫描整个音乐数据库得到事务矩阵D;
2)对矩阵中的事务信息进行编码、排序处理,记录为一行,对于小于阈值的项进行删除,得到只含0和1的d1,d2,d3,…,dn;
3)将矩阵H分解并升序排列为H1,H2,H3,…,Hm;
4)扫描列向量Dm,并对dnm进行判断;
5)若dnm=1,则取前m项(含dnm在内)形成子矩阵Hm,如式(5)。
M1M2M3M4M5M6
H=110001011000110100101011010011110011000011T1T2T3T4T5T6T7
(5)
假设支持度阈值为2,则得到的个性化音乐事务如表1所示。
与权重相结合,得到子集Ti的支持度如式(6)。
SupportTi=1l∑j∈tiwj×SupportTi
(6)
其中,l表示Ti的长度。
计算得到列向量和行向量分别为4,5,2,1,4,5T和3,2,3,4,3,4,2,经降序排列得到矩阵H′,如式(7)。
M2M6M1M5M3M4
554421
H′=1100010110001101001010110100111100110000114433322
(7)
将行列和不满足支持度阈值2的项处理后,得到矩阵H″,如式(8)。
M2M6M1M5
5544
H″=111101011110101011010101
(8)
矩阵H″经分解处理后可知,M2、M6和矩阵H″经分解处理后可知,M2、M6和M2、M1具有很强的关联性。实际情况下,如果M2属于用户的关注音乐作品,即使M6、M1与M2缺乏内容上的相似性,也会因强关联性而被推荐给用户。
2.2个性化音乐推荐方法
个性化音乐推荐的第一步计算用户的兴趣度。为了方便计算,需先对音乐库中乐曲进行分类编号,则用户在第i类歌曲中第j首歌曲的欣赏时间占音乐欣赏的总时间比如式(9)。
ρij=tij-αijβij-αij
(9)
式中:βij为收听时间最大值,αij为收听时间最小值,tij的取值如式(10)。
tij=αij,t′ij≤αij
t′ij,αij≤t′ij≤βij
βij,t′ij≥βij
ρij,t′ij∈R,收藏歌曲
(10)
根据公式(9)中用户对不同音乐收听时间比例,则可计算用户对i类音乐的兴趣度,其计算如式(11)。
Inti=∑mj=1tij∑ni=1∑mj=1tij
(11)
获取用户兴趣度后,利用音乐本身标签等音乐信息和基于用户兴趣的音乐标签之间的对应关系,通过音乐信息预测和用户兴趣度计算的方式,从音乐库中将强关联性的音乐向用户进行推荐,满足用户的个性化需求,总体推荐流程,如图3所示。
3试验结果评估分析
(1)样本数据集及试验环境
为了减小数据采集对试验结果造成的误差,必须选用一个含有足够数据量的数据库,且各类算法的数据采集均出自于相同数据库。因此本文选用了公开的Last.fm音乐网站数据,目前该数据库已包含近40万条用户记录,且该数据库
能够支持用户进行自定义标签,方便对数据进行标定。本次试验随机选取4281条用户记录,其中包含音乐信息245314条和音乐标签14263个,利用数据处理软件TRIFACTA软件对数据库进行信息统计分析后得到标签分布情况如图4所示。
由于本次试验是对不同推荐系统推荐效率的横向对比,因此对比试验的外部环境应该是相同的,试验的外部环境,如表2所示。
(2)试验结果评价标准
本文是从评价的准确性作为结果评价的首要标准,在准确性相同时引入结果多样性指标作为评价的辅助标准。根据相关研究[10],推荐系统的准确度评价标准分类较多,各种分类标准间各有优势和不足,而本文的准确度评价采用了目前较为普遍的准确率和召回率两个定量指标,如式(12)、式(13)。
准确率=∑u∈URu∩Tu∑u∈URu
(12)
召回率=∑u∈URu∩Tu∑u∈UTu
(13)
式中:Ru——系统向用户u推荐音乐集;
Tu——用户u感兴趣的原有音乐集;
U——用户集。
在某些算法中,这两个定量指标在面对特定的数据集时的计算结果十分相近,难以对计算准确度进行客观评价,因此本文参考相关文献[1012],在计算准确度基础上引入结果多样性指标,如式(14)。
Simu,r=∑ti∈M(r)Mti1+countr∈Mti
(14)
式中:ti——音乐标签;
Mti——采用音乐标签ti标注的音乐集;
1+countr∈Mti——采用音乐标签ti的总数。
(3)试验结果分析
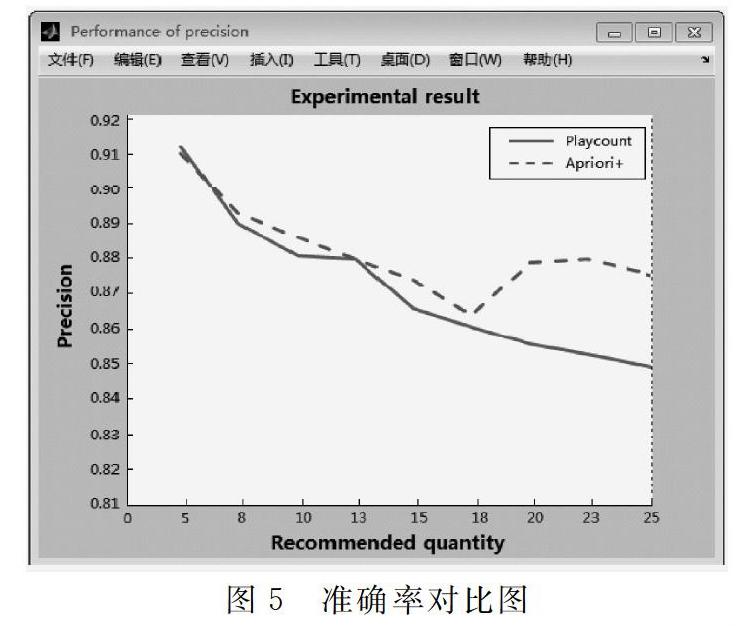
通过调查分析,目前較为受欢迎的软件大多采用Plaucount算法,因此本文采用Plaucount算法与改进的Apriori算法进行推荐对比分析,并以准确率及召回率为判断标准,得到的试验结果如图5、图6所示。
从图5可以看出,当音乐推荐次数不超过18次时,Plaucount算法和改进的Apriori算法在准确率方面相差不大;当音乐推荐次数超过18次时,改进的Apriori算法在准确率方面则会显著优于Plaucount算法;对比结果表明,当音乐推荐次数相同且达到一定数量时,改进的Apriori算法的推荐效果明显优于Plaucount算法,更容易满足用户的个性化要求。
从图6可以看出,改进的Apriori算法在召回率方面优于Plaucount算法,表明改进的Apriori算法推荐的音乐在数量方面也高于Plaucount算法,更容易成为用户感兴趣的音乐。
在音乐推荐系统中,过多或过少的音乐推荐均得不到理想的效果。推荐结果过多,则需用户在推荐音乐中进行二次筛选,系统推荐得不到认可,用户满意度会降低;推荐结果过少,则会出现筛选遗漏的现象,将用户感兴趣的内容直接过滤掉,造成内容缺少,达不到理想的推荐效果,如图7所示。
从图7可以看出,改进的Apriori算法在相似度方面低于Plaucount算法,表明改进的Apriori算法在推荐音乐时充分考虑了用户兴趣的相似性,在音乐相似性的冗余度方面做了考虑,实现了音乐推荐的多样化,避免出现筛选遗漏现象,相比于Plaucount算法,推荐结果的同质化相对较弱。
4总结
本文在概括介绍推荐系统常用的核心算法的基础上,结合个性化音乐推荐提供了Apriori算法的改进应用,并给出了基于深度学习的个性化音乐推荐的具体流程。通过选取Last.fm上的部分数据作为样本,经对比分析后得到如下结论:
(1)以推荐准确度为计算标准,采用候选矩阵压缩的方法对Apriori的计算原理进行了分析,在此基础上设计了个性化音乐推荐的流程。
(2)考虑到推荐数量对推荐效果的影响,将改进的Apriori算法与Plaucount算法对比可知,在准确率和召回率方面,改进的Apriori算法均优于Plaucount算法,表明改进的Apriori算法推荐的音乐能容易满足用户需求;在相似度方面,改进的Apriori算法则低于Plaucount算法,表明改进的Apriori算法的推荐在考虑了用户兴趣的基础上实现音乐推荐的多样化。
參考文献
[1]徐正巧,赵德伟.深度学习理论视角下的移动学习推荐系统的设计和研究[J].智能计算机与应用,2014,4(2):5758.
[2]GoldbergD.Usingcollaborativefilteringtoweaveaninformationtapestry[J].CommunicationsoftheACM,1992,35(12):6170.
[3]EpplerMJ,MengisJ.Theconceptofinformationoverload:Areviewofliteraturefromorganizationscience,accounting,marketing,MIS,andrelateddisciplines[J].TheInformationSociety,2004,20(5):325344.
[4]邓腾飞.个性化音乐推荐系统的研究[D].广州:华南理工大学,2018.
[5]朱志慧,田婧,林捷.大数据环境下基于用户位置的个性化音乐推荐系统设计[J].无线互联科技,2019,16(2):7980.
[6]艾笔.个性化音乐推荐系统的设计与实现[D].成都:电子科技大学,2018.
[7]杨凯,王利,周志平,等.基于内容和协同过滤的科技文献个性化推荐[J].信息技术,2019,43(12):1114.
[8]黄立威,江碧涛,吕守业,等.基于深度学习的推荐系统研究综述[J].计算机学报,2018,41(7):16191647.
[9]陈波.基于Apriori算法及其改进算法综述[C].中国通信学会第五届学术年会论文集.江苏南京:中国通信学会,2008(2):176181.
[10]李臻.应用于音乐节目分类的Apriori挖掘算法设计[J].现代电子技术,2019,42(19):9094.
[11]王彩强,赵宪中,刘涌,等.大数据环境下改进的Apriori算法研究[J].科技通报,2019,35(7):182185.
[12]AgrawalR,ImielińskiT,SwamiA.Miningassociationrulesbetweensetsofitemsinlargedatabases[J].ACMSIGMODRecord,1993,22(2):207216.
(收稿日期:2020.02.25)
猜你喜欢
教学研究与管理(2022年3期)2022-04-25
计算机应用(2016年12期)2017-01-13
电脑知识与技术(2016年28期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
电脑知识与技术(2016年25期)2016-11-16
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
小天使·四年级语数英综合(2015年7期)2015-07-06
