
基于局部注意力的方面级别情感分析算法
2020-11-11 08:02:54邬向前
智能计算机与应用 2020年6期
张 硕, 卜 巍, 邬向前
(1 哈尔滨工业大学 计算机科学与技术学院, 哈尔滨150001; 2 哈尔滨工业大学 媒体技术与艺术学院, 哈尔滨150001)
0 引 言
随着互联网的快速发展,可以轻松地得到海量带有观点的数据。 各种购物平台、点餐平台以及社交平台的兴起,人们可以在购物平台上对所购买的商品进行评价,对消费过的餐厅进行点评,尽情地在社交平台上表达自己的观点,对事件的情感态度。对这些饱含大众情感的内容进行研究,发挖掘这些文本背后隐藏的大众的情感态度,将帮助购物平台和点餐平台等更好地了解购买者的喜好,同时也是对商家的监督。 对社交媒体上大众对于某些事件的情感分析,可以帮助了解大众,引导正确的社会舆论。 因此,近年来情感分析在自然语言处理领域的研究非常广泛。 研究表明:40%的情感分类错误是由于在情感分类中没有考虑目标造成的[1]。 近年来,研究者们开始将研究方向从单纯的文本情感分析转向方面级别的文本情感分析。
本文针对方面级别的情感分析,考虑上下文单词与方面序列之间的距离,提出了局部文本序列的定义,并提出了一种基于局部注意力的的网络框架。
1 相关工作
研究者们研究了各种基于神经网络的方法来解决方面级别的情感分类问题。 一些研究者设计了有效的神经网络,从目标及其上下文中自动生成有用的低维表示,在方面级别情感分类任务中取得了很好的效果,典型的方法是基于LSTM 的神经网络。Dong 等人通过开发两个LSTM 网络来模拟方面目标的左右上下文来解决这个问题,该方法利用这两个LSTMs 的最后隐藏状态来预测情绪。 为了更好地抓住句子中的重要部分,Wang 等人使用一个方面词嵌入,来生成一个注意力向量,集中在句子的不同部分。 Vo 和Zhang 将整个上下文分为目标、左上下文和右上下文三个部分,使用情感词典和神经池函数生成目标相关特征。 Tang 等人将上下文分为带目标的左半部分和带目标的右半部分,分别使用两个LSTM 模型对这两个部分建模,利用这两部分合成的目标特定表示进行情感分类。
2 算法详述
2.1 局部文本序列
局部文本序列:对于给定一个句子s =[w1,w2,…,wi,…,wj,…,wn],和方面序列t =[wi,wi+1,…,wi+m-1],其中方面序列可能包含一个或多个词。 如图1 所示, 设局部文本序列为整个文本中,距方面词中心距离为k的序列片段。 当方面词为一个单词时,局部文本序列l =[wi-k,wi-k+1,…,wi,…,wi+k-1,…,wi+k],其中wi为方面词。 当方面词为多个单词时,局部文本序列l =[wi-k,…,wi,…,wj,…,wj+k],其中wi为方面词的第一个词,wj为方面词的最后一个词。
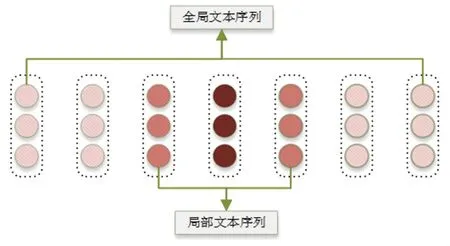
图1 局部文本序列示意图Fig. 1 The chart of local context
2.2 网络框架介绍
网络整体结构如图2 所示(与图的名字不一致),包括词嵌入层,特征提取层,注意力层以及分类层。
词嵌入层。 (1)Glove 词嵌入。 设L∈Rdw×|V|为预先训练的Glove(Pennington 等人,2014)嵌入矩阵,其中dw为词向量的维数,为词汇的数量。将上下文和方面的每个词wi∈映射到对应的嵌入向量ei∈Rdw×1, 它是嵌入矩阵L中的一列。(2)BERT 词嵌入。 使用预先训练的BERT 生成序列的词向量。 为了便于BERT 模型的训练和微调,将给定的上下文和目标分别转换为“[CLS]+上下文文本+SEP”和“[CLS]+方面序列+SEP”,从而作为文本序列的词嵌入进行模型训练。
通过词嵌入模块,将全局文本序列映射为S ={vs1,vs2,…,vsn},将方面序列映射为T ={vt1,vt2,…,vtm},将局部文本序列映射为L ={vl1,vl2,…,vlk}。其中vti∈Rdw,vsi∈Rdw,vli∈Rdw,dw为词嵌入维度。
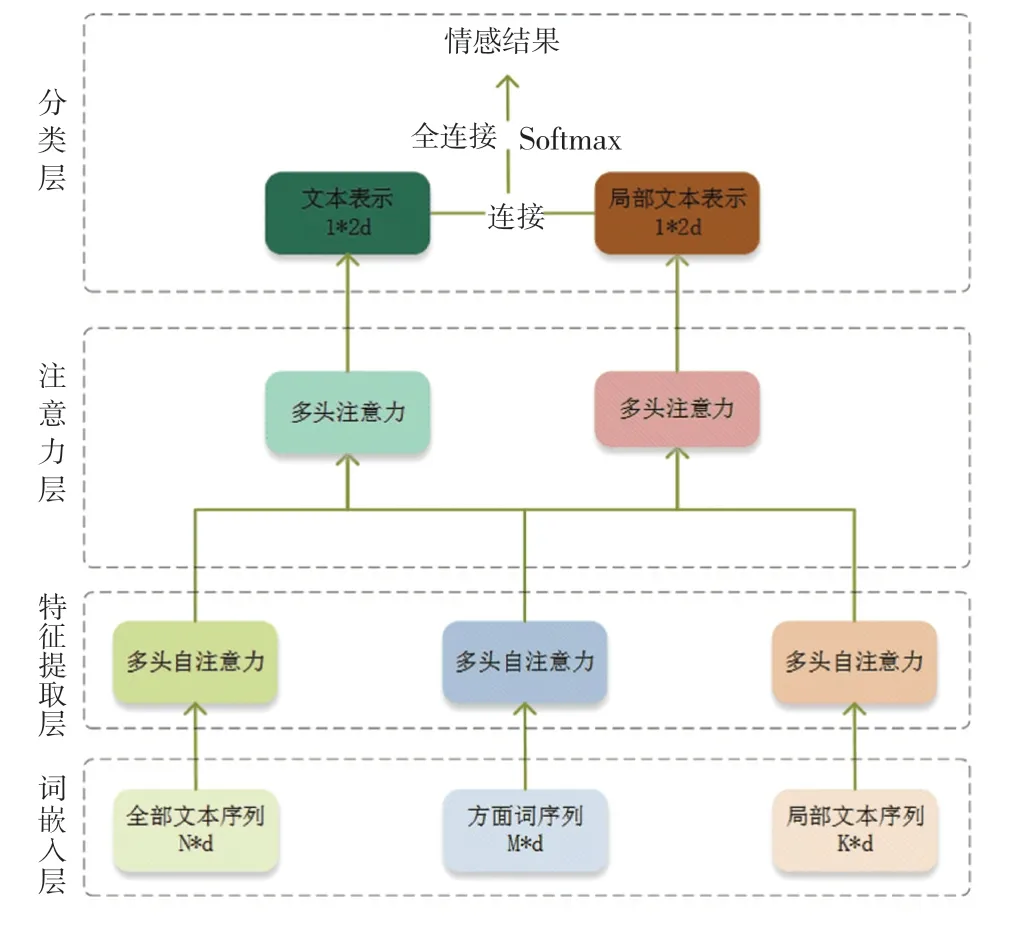
图2 网络框架图Fig. 2 The framework chart of our algorithm
特征提取层。 多头自注意是一种同时执行多次自注意力的操作。 为了对文本进行特征提取,利用多头自注意力机制分别对全本文本序列、方面词序列以及局部文本序列进行建模。 注意函数将Key 序列K ={k1,k2,…,kn} 和Query 序列Q ={q1,q2,…,qm} 映射到输出序列,其中对全局文本自注意力计算方式如公式(1),局部文本的自注意力计算方式如公式(2),方面序列的自注意力计算方式如公式(3)。

多头自注意力就是平行地进行多词注意力计算,将结果拼接到一起作为最终的结果,其中三个序列的计算方式是一样的,这里只以全局文本为例子,具体计算如公式(4)和公式(5):

除了多头注意力之外,每一次注意力计算后都包含一个全连接的逐点前馈网络(Point-wise Feed Forward,PFF)。 共包括两个线性转换,以及一个relu激活。 公式如(6)和(7)。

其中:W1∈Rdw×dw,W2∈Rdw×dw是两个可学习权重,b2∈Rdw,b2∈Rdw是两个偏置参数。relu为激活函数。
注意力层。 在这一层中,将利用特征提取层得到的结果,以方面序列的输出作为新的注意力中的Query,全局文本序列的输出作为新的注意力计算中的Key 以及Value,计算方面序列对全局文本的注意力分数,如公式(8)。 同样地,以方面序列作为Query,以上一层中局部文本序列的输出作为Key 和Value,采用多头注意力的方式计算方面序列对局部文本的注意力分数,并更新局部文本表示,如公式(9)。 之后将更新后的全局文本表示rs以及局部文本表示rl分别作为输入,通入到PFF 函数中,如公式(10)和公式(11),从而得到最终的全局文本表示以及局部文本序列的表示。

分类层。 将注意力层输出的全局文本表示和局部文本表示连接到一起,如公式(11),由于分类结果分为积极、消极和中性三个类别,所以将连接后的向量输入一个三个神经元的全连接层,如公式(12),然后送入SoftMax 函数得到和为1 的三个概率值,如公式(13),概率最大的即为最终的情感类别。

其中:Wl∈R3×2dw和bl∈R3×1分别表示权重矩阵和偏差。
3 实验
3.1 数据集介绍
实验的数据集来自Semeval2014 语义评测任务的任务4 的第四个子任务:方面级别情感分类。 该任务给定一个句子以及句子中包含的一个或多个方面类别,输出每个方面类别对应的情感分类。 分类分为积极,消极和中性。 数据集一共包括餐厅评论数据集以及笔记本电脑数据集。 本文用到的数据集还包括ACL 14 Twitter 数据集。
“All the money went into the interior decoration ,none of it went to the chefs”,对于这个句子,当方面序列为“interior decoration”时,情感分类为积极;当方面序列为“chefs”时,情感分类为消极。 这些数据集被大多数提出的模型所采用,是方面级别情感分析任务中最流行的数据集,表1 展示了3 个数据集中训练集和测试集的细节。

表1 数据集统计表Tab. 1 The statistics of dataset
3.2 实验评价指标
为了能够评估不同的情感分析算法的行能,对算法的泛化性能进行评估,本文采用该领域常用的评价指标: 准确率(Accuracy) 和综合指标(F1),其中准确率计算方式如公式(14),F1 计算方式如公式(15):

其中:TP表示被模型预测为正的正样本;FP表示被模型预测为正的负样本;FN表示被模型预测为负的正样本;TN表示被模型预测为负的负样本。N表示总的样本数量。
3.3 模型参数
词嵌入中Glove 的嵌入方法的词嵌入维数设置为300。 BERT 词嵌入方法,隐藏层维度设置为768。LSTM 网络隐藏状态的维度同样设置为300,并在训练期间固定。 为了确保在训练过程可以学到有用的信息,参数梯度不为0,模型的权重是用Glorot 随机初始化的[2]。 L2 正则化项的系数λ 为10-3,dropout设置为0.1,Batchsize 设置为32,Adam you 优化器用于更新所有参数。
3.4 损失函数
本文在损失函数中使用了标签平滑正则化(Label smoothing Regularization, LSR)的。 它惩罚了低熵输出分布[3]。 LSR 可以通过防止网络在训练期间为每个训练示例分配全0 或全1 概率来减少过度拟合,用平滑的值替换分类器的0 和1 目标,如用0.1 或者0.9 替代0 和1。 利用公式(17)中的q′(k |x) 代替原本的标签分布q(k |x)。 令u(k) 服从简单的均匀分布,如公式(16)。

其中,c为情感分类的类别数3,得到了新的标签分布,如公式(17)。

最终的损失函数依旧采用交叉熵损失函数,但是将真实标签换成平滑后的标签,如公式(18)。
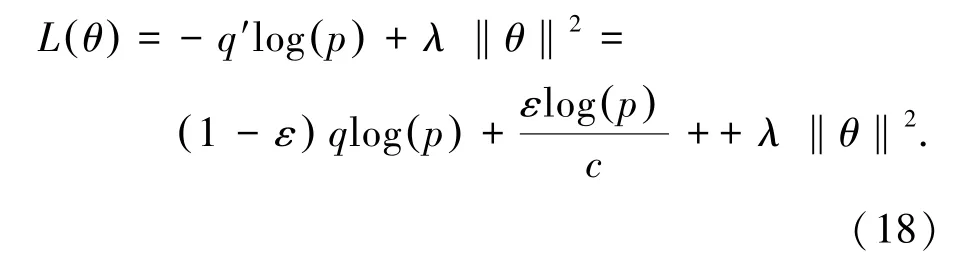
其中,q′为平滑后的标签,p为预测标签,q为真实标签。 λ 为l2 正则化项系数,θ为参数。
3.5 实验结果
首先针对局部文本序列的长度进行了实验,分别取k =1,2,3,4,5。 对应的局部文本序列长度位:3,5,7,9,11。 如表2 所示,可以发现当k =2 或3时,结果最好,也就是局部文本序列的长度为5 或者7 时,模型的效果最佳。 当序列长度过长时,局部文本序列的长度趋近于全局文本序列长度,本文的模型失去了意义;当序列长度过短时,局部文本序列几乎等于方面序列。 因此,在后续的实验中, 都采用k =2 来训练。

表2 局部文本序列长度K 不同取值的对比Tab. 2 Comparison of K in local context length
为了证明本文提出的基于局部注意力的方面级别情感分析网络(Local Attention Network, LAN)的优越性,将其与以下模型进行了比较,结果如表3 所示。

表3 模型对比结果Tab. 3 Model comparison results
LSTM。 使用一个LSTM 网络对句子进行建模,最后一个隐藏状态作为句子的表示形式进行最终分类;TD-LSTM:使用两个LSTM 网络来模拟,围绕方面术语的前后上下文,这两个LSTM 网络的最后隐藏状态被连接起来,以预测情感极性。 ATAELSTM:通过将方面嵌入到每个词向量中来进一步扩展T-LSTM;IAN:使用两个LSTM 网络分别对句子和方面项进行建模,利用句子中隐藏的状态为方面生成一个注意向量,反之亦然。 基于这两个注意向量,输出用于分类的句子表示和方面表示;MGAN:提出了一种细粒度的注意机制,捕获方面和上下文之间的词级交互;PBAN:关注方面术语的位置信息,并通过双向注意相互模拟方面术语和句子之间的关系;TNet:提出了一个特定目标的转换组件,用于生成基于特定目标的词向量,并利用上下文信息保留机制维持原有信息;TransCap:提出了一种将文档级知识转移到方面级情感分类的转移胶囊网络模型;IACapsNet:提出利用胶囊网络构造基于向量的特征表示,并通过EM 寻路算法对特征进行聚类。 此外,在胶囊寻路过程中,引入了交互注意机制,以建立方面和上下文之间的语义关系。 结果显示本文的模型在推特数据集上略低于IACapsNet 和TNet,餐厅数据集以及笔记本电脑数据集上准确率和F1 都取得了最好的结果。
4 结束语
本文提出了一种基于局部注意力的网络框架,由于距离越近,上下文对方面序列情感倾向影响可能越大,考虑到上下文与方面序列之间的位置关系,提出了局部序列的定义,局部文本序列的构建取决于方面序列。 同时本文提出了用标签平滑正则化修正损失函数,并在词嵌入分别为Glove 和BERT 的基础上进行了实验。 最终结果显示,本文的模型在前两个数据集上都超越了先前的模型。
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29 05:08:09
新高考·高二数学(2022年3期)2022-04-29 05:08:09
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化·七年级数学人教版(2022年11期)2022-02-22 22:13:22
数学物理学报(2021年2期)2021-06-09 08:54:42
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14 07:36:40
中学生数理化·高一版(2018年6期)2018-07-09 06:00:54
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
发明与创新(2016年38期)2016-08-22 03:02:50
