
面向三维人脸重建的自编码体素网络研究
2020-11-11 08:02:58董俊呈左旺孟
智能计算机与应用 2020年6期
董俊呈, 左旺孟
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨150001)
0 引 言
本文主要研究单幅人脸图像的三维重建问题,基于VRN 论文的相关方法和技术,完成面部照片三维重建任务的端到端的神经网络。 本文首先验证了现有各种三维重建方案的效果、性能和可行性,同时对3DMM 和VRN 进行复现并验证效果;其次,验证基本无误,并且复现效果达到baseline 水平后对VRN 的模型结构,损失函数和引导项这三个方向进行了改进。
1 对现有工作的复现和验证
1.1 三维可变形模板(3DMM)
本文实现了传统的3DMM 重建方法,用蒙特卡洛法对输入进行拟合,在适当的初始化条件下可以得到不错的效果。
代码实现的操作大体如下:
a.读取BFM 数据集,经PCA 后构建特征值和特征向量,目标是计算拟合所对应的的各个特征值系数。
b. 对于任意一个要拟合的人脸,检测36,39,42,45,31,33,35,48,54,51,57 号特征点,计算在齐次坐标系下经过平移,水平拉伸和竖直拉伸后得到的与原图对应特征点的MSE 距离最小的情况作为初始化,如图1 所示。

图1 通过人脸特征点进行初始化Fig. 1 Initialization by face landmark
c.如图2 所示,调用蒙特卡洛算法,以颜色直方图的MSE 距离作为优化目标,对三维人ß 脸的特征向量系数进行优化。 如果拟合中误差小于设定的最小阈值,则可以提前结束;如果误差大于设定的最大阈值,则认为模型已经偏离梯度下降方向,结束拟合过程,返回-1;否则,算法进行2 000 次后停止,返回当前的最好结果。
如果初始化得当,最终可以取得较好的拟合结果,如图3 所示。
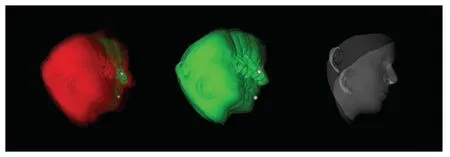
图2 蒙特卡洛算法进行拟合过程Fig. 2 The fitting process with Monte Carlo

图3 传统3DMM 拟合结果Fig. 3 The result of the traditional 3DMM fitting
利用蒙特卡洛方法对三维人脸进行拟合伪代码如下:
算法1利用蒙特卡洛方法对三维人脸进行拟合
输入:待拟合三维人脸特征向量系数矩阵G,输入RGB 图片I,蒙特卡洛步长l
输出:拟合结果人脸特征向量系数矩阵
1.function MontFit(G, I, l):
2. for i in range(2000):
3. if MSE(Z(P(G)),Z(I)) >ThresholdMax:
4. return -1
5. end if
6. if MSE(Z(P(G)),Z(I))<ThresholdMin:
7. return G
8. end if
9. L←{for i in range(20), MontStep(G,l)} + {G}
10. temp L←{for i in range(20), MSE(Z(P(L[i])), Z(I))}
11. G←L[minIndex(tempL)]
12. end for
13.return G
1.2 自编码体素网络(VRN)
VRN 是一个端到端的神经网络,输入是一张三通道RGB 或灰度的任意姿态,任意光照,任意表情,允许遮挡的人脸照片,输出是一个三维人脸的体素表示[1],即一个192×192×200 的三维矩阵,其中数字“1”代表该位置有一个体素立方体,“0”则代表没有,这个三维人脸向Z轴的垂直投影应该与输入人脸对齐。 需要注意的是,由于姿态变化,人脸(尤其是鼻子导致的)会有自遮挡问题,因此这个体元表示与简单输出一张深度图是有区别的。
本文将VRN release 的MATLAB 代码重写成了pytorch 代码,完成了training 和testing 的工作,并用原文所列出的训练集对模型进行了训练并达到了baseline,在原文中提供的测试集 Florence 和AFLW2000-3D 上均达到了原文的水平,同时对文中用于比较VRN 性能的重建方法EOS 和3DDFA在对应数据集上进行了验证,与VRN 提供的数据基本一致,本文复现VRN 的可视化结果如图4 所示。

图4 VRN 复现的可视化结果Fig. 4 Visualization results of VRN reproduction
同时测试了文中用于比较效果的3DDFA 和EOS,证明VRN 的方法是可行的。 图5 是在AFLW2000-3D 上比较VRN,复现VRN(VRNrepro),EOS 和3DDFA 的NME 损失,图5(a)是VRN 论文中的结果,图5(b)是复现的结果;图6 是在Florence 上比较VRN,复现VRN(VRN-repro),EOS 和3DDFA 的NME 损失,图6(a)是VRN 论文中的结果,图6(b)是复现的结果。 本文在各数据集上各个方法的平均NME 损失值如表1 所示。
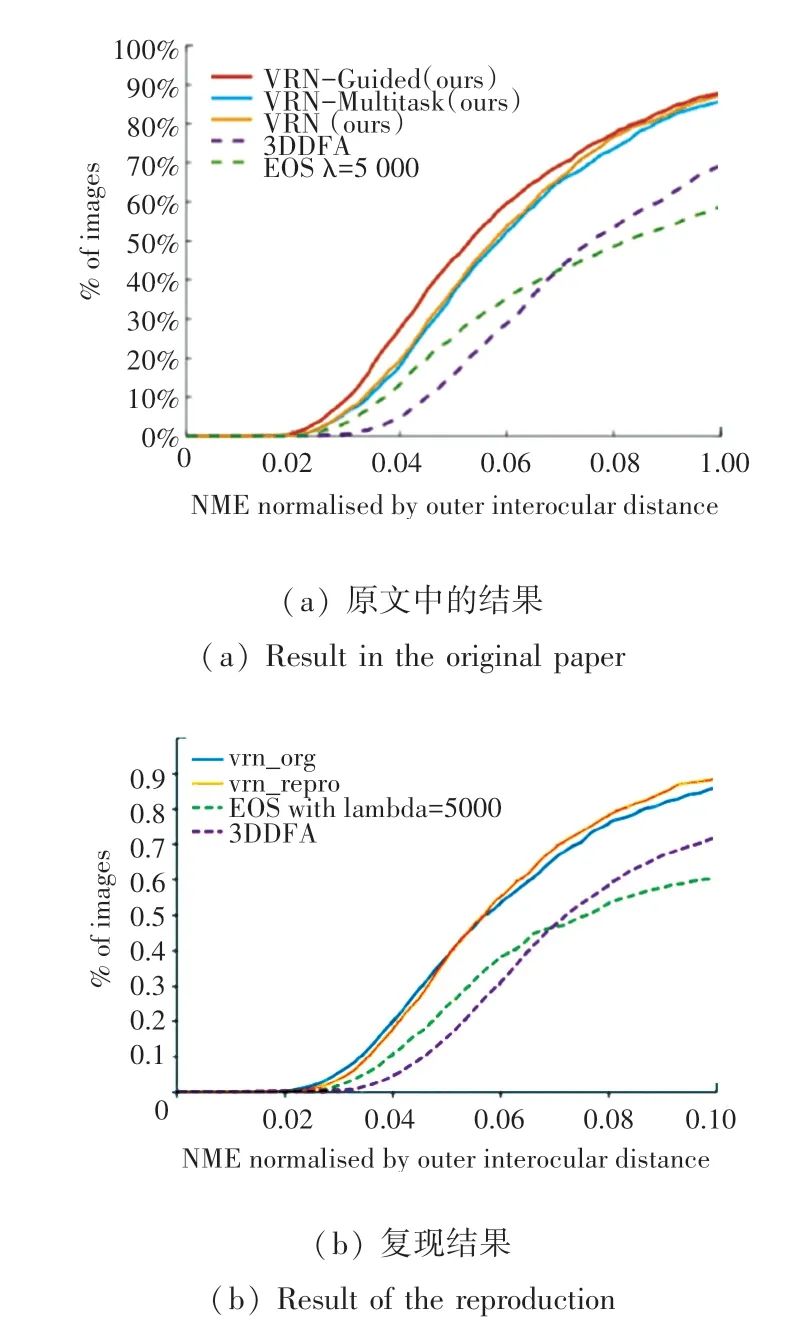
图5 AFLW2000 数据集上的结果Fig. 5 The result on AFLW2000

图6 Florence 数据集上的结果Fig. 6 The result on Florence
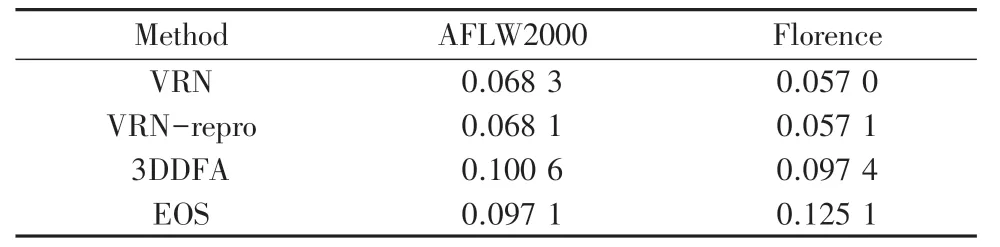
表1 在各数据集上各个方法的平均NME 损失Tab. 1 The average NME loss of each method on each data set
2 对自编码体素网络的改进
VRN 网络是一个端到端的,简洁轻量的模型,但是模型的表达效果仍然没有达到理想的效果。 因此,本文又训练了vrn-multitask,来提取人脸特征点的热度图,把热度图信息和原图一起输入到vrnguided 中来优化输出,确实得到了提升。 但是本文认为VRN 采用的U-Net 结构是可以改进的,尝试如Fish-Net 这些被证明相同结构下效果更好的网络[2]。 另外,只有二维的特征点信息并不能最好的起到引导的作用,希望加入pose 等更多的信息来对VRN 进行引导,试着得到更好一些的效果。 VRN 采用的全局的损失本文认为也是有一定不足的,显然人脸内部的体素权重应当小于靠近边缘和表面的体素。
2.1 对自编码体素网络结构的改进
在VRN 中,本文使用两个串联的UNET 端到端训练了一个输出体元人脸的网络,U-Net 使用的“上/下采样+跳跃连接”的结构,使得其构成的神经网络具有易收敛、轻量级,深层网络容易更快的获取浅层网络梯度,保留了图片各个像素的位置信息的优点。 但也存在当多个U-Net 共同工作于同一个模型时,各个U-Net 直接配合较差的问题,据此UNET 被提出后,已经产生了很多基于UNET 结构的其他模型结构,如FishNET 等。
Fish-Net 是对U-Net 的一种改进。 Fish-Net 认为,当多个U-Net 串联时,单个U-Net 内的对应上采样和下采样之间有跳跃连接,但两个相邻的UNet 之间的下采样和上采样之间没有跳跃连接,因此两个U-Net 之间的通路可能会成为梯度传播的瓶颈;同时Fish-Net 的作者提取了相邻两个U-Net对应的下采样层和上采样层,发现从语义信息的角度这两个特征也处于不同的域。 因此Fish-Net 除了将下采样层和自身对应的上采样层进行连接,还将每个U-Net 的上采样层和后面相邻的一个U-Net的下采样层做了跳跃连接,使得后面的U-Net 可以更容易的感受到前面U-Net 的梯度。
在Fish-Net 中,有两种用于上采样和下采样的卷积块,分别是上采样-重制块(UR-block)和下采样-重制块(DR-block)。 通过在FishNet 中设计的身体和头部,将尾部和身体各个阶段的特征连接到头部。 Fish-Net 精心设计了头部中的各层,以使其中没有I-conv。 头部中的层是由串联,具有特征的卷积和池化层组成。 因此,Fish-Net 解决了尾部在躯干网络前获得梯度传播的问题,用到的两种方法分别是:1)排除头部的I-conv 和2)在身体和头部使用串联。 为了避免像素之间重叠,对于跨度为2的下采样Fish-Net,将卷积核大小设置为2×2,消融实验显示了网络中不同种类的内核大小对实验效果的影响。 为了避免I-conv 问题,应避免采用上采样方法中的加权反卷积,为简单起见,Fish-Net 选择最近邻插值进行上采样,由于上采样操作将以较低的分辨率稀释输入特征,Fish-Net 在重制模块中还应用了膨胀卷积,该方法被证明是可行并且确实可以提高UNET 效果的,本文将UNET 替换成FishNET,并对数据结构进行相应的更改并重新训练,实验证明在相同参数和模型规模下,不论是AFLW2000 数据集上,表2 所示,还是Florence 数据集上,表3 所示,FishNET 的表现都要优于UNET(图7)。
另外,本文提出了MR-UNET,如图8 所示,来对原UNET 进行多尺度条件下的改进,实验结果表明,在相同的网络规模和参数量下,Stacked UNET表现不如原UNET,但随着网络规模的增加,其准确度依然有很高的上限,且其网络结构和输出的特征与FishNET 和UNET 有着较好的契合度。 因此,本文在后面的实验中也使用该网络来产生用于引导原网络的pose 信息。
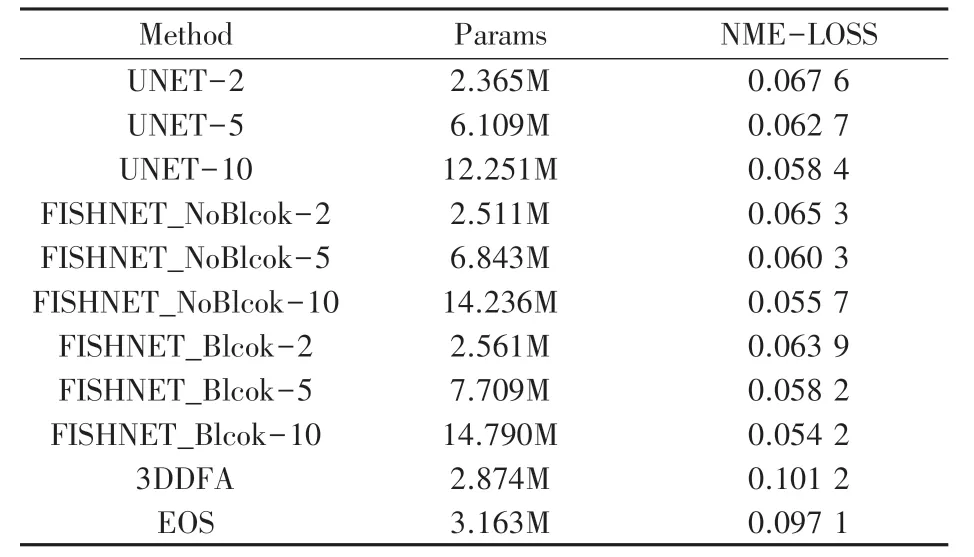
表2 AFLW2000 上各个模型的参数规模和对应的NME-LOSSTab. 2 The parameter scale and corresponding NME-LOSS of each model on AFLW2000
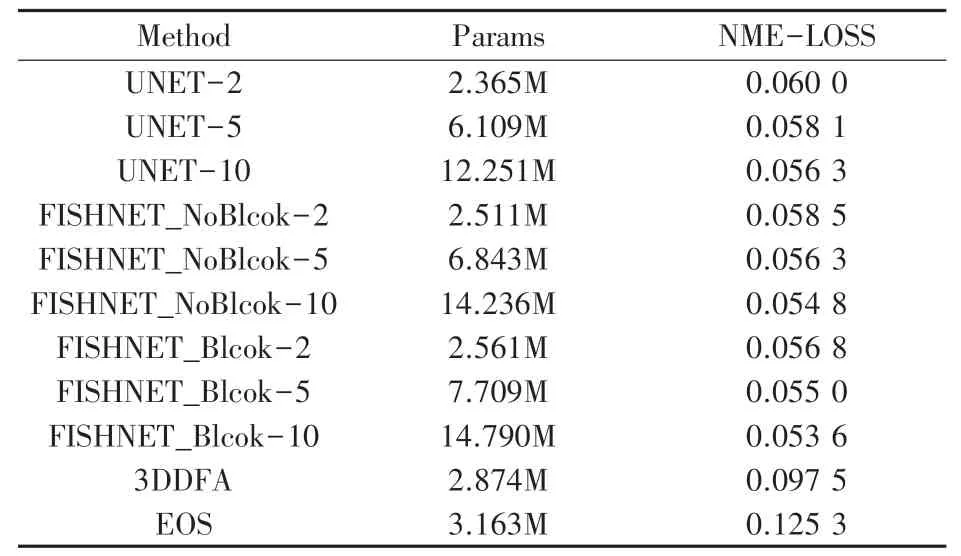
表3 Florence 上各个模型的参数规模和对应的NME-LOSSTab. 3 The parameter scale and corresponding NME-LOSS of each model on Florence
MR-Net 全程端到端训练模型,使用RMSProp方式。 首先关闭所有上下采样通路,使模型中只有主干网络(第一行)处于工作状态,初始化学习率,每40 个epoch 后学习率衰减为之前的0.1。 在训练中对数据进行一系列增强操作:输入图片被施加一个XOY 平面的旋转,旋转处于{-45,…,45}之间的整数,然后被施加一个随机的平移操作,平移距离是{-15,…,15}之间的整数像素,然后被施加一个缩放,由于尽量不使面不变形过于明显,以及方便groundtruth 的z 方向,可以根据输入图片的变化产生对应变化,本文中的缩放均使用等比例缩放,这样groundtruth 的三维数据可以直接按照相同的比例进行缩放,随机缩放比例处于1-{-0.15,…,0.15}之间,随机选取20%的样本做水平翻转,最后输入数图片在RGB 三个通道分别做等比例的随机亮度调整,调整范围在{0.6,…,1.4}之间。 同时,作为对应的三维人脸也要做同样的变换,与输入的RGB 图片保持对齐。
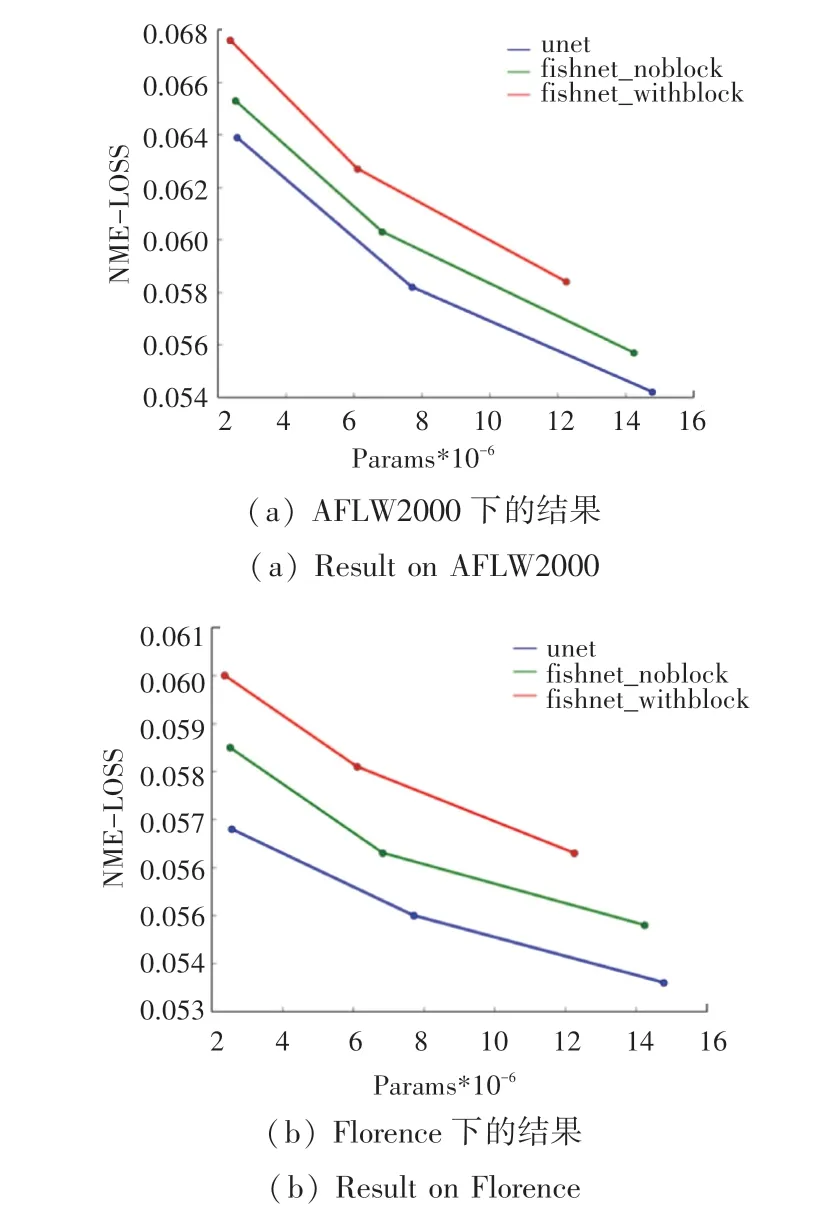
图7 FishNET 与UNET 的参数规模和NME-LOSS 关系的比较Fig. 7 Comparison of FishNET and UNET parameter scale and NME-LOSS relationship

图8 MR-UNET 的网络结构Fig. 8 MR-UNET network structure
在主网络训练至LOSS 不再下降,打开对应通道,使第二行的网络加入训练,训练参数相较于第一行训练参数均减少为原先的一半,训练至LOSS 不再下降;同样在模型的LOSS 稳定且不再下降后,打开对应通路将第三行的网络加入模型,训练方式仿照第一二行的情况,同样需注意第三行和前两行的数据应保持等比例情况下的一致,且groundtruth 的三维人脸应做对应的变换来与输入图像保持对齐。
同样在模型的LOSS 稳定且不再下降后,打开对应通路将第三行的网络加入模型,训练方式仿照第二行的情况,同样需注意第三行和前两行的数据应保持等比例情况下的一致,且groundtruth 的三维人脸应做对应的变换来与输入图像保持对齐。
本文对MR-UNET 与UNET 的参数规模和NME-LOSS 关系的比较,结果如表4 所示。 可见MR-UNET 在单幅人脸图像三维重建任务上达到了最低的NME-LOSS。

表4 MR-UNET 与UNET 的参数规模和NME-LOSS 关系的比较Tab. 4 Comparison of the parameter scale of MR-UNET and UNET and the relationship between NME-LOSS
2.3 对自编码体素网络引导项的研究
简单的两个串联的UNET 模型表达能力有限,因此又训练了一个vrn-multitask 用于输出人脸特征点的热度图,模型结构如图9 所示。 将这个热度图与原输入连接到一起,输入网络进行重建,让这个特征点的热度图对原模型进行引导,称为vrn-guided,网络结构如图10 所示。
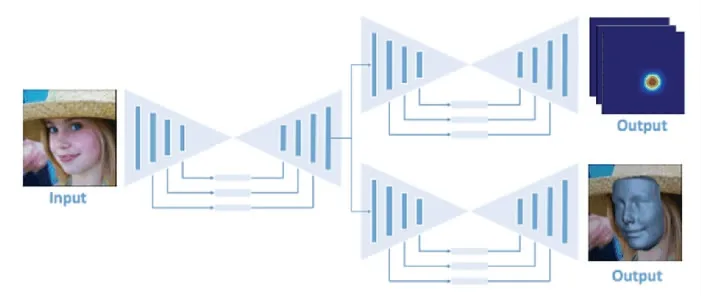
图9 VRN-multitask 的网络结构Fig. 9 VRN-multitask network structure
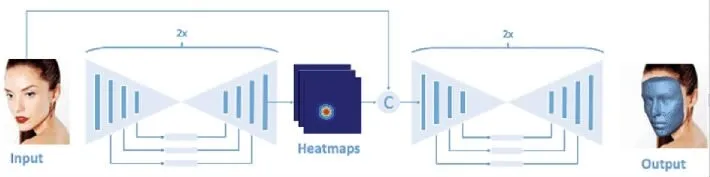
图10 VRN-guided 的网络结构Fig. 10 VRN-guided network structure
在vrn-duided 中,首先训练了一个叉状网,如图9 所示。 输入图片进入一个U-Net 后,输出的特征被分为两份,分别输入到两个单独的U-Net 中,上半部分用于预测输入人脸的热度图,下半部分用于预测三维重建结果,其中面部特征点热度图和三维体素人脸的损失同时能影响到左边第一个U-Net 的参数学习,vrn 原文中称这个网络为vrn-multitask,这个模型可以同时预测输入图片中人脸的特征点概率分布热度图和重建体素三维模型。 从模型角度来看,vrnmultitask 的左下半部分(去除第二列最上面的一个U-Net)与vrn-unguided 模型结构一致。
提取vrn-multitask 的左上半部分的热度图提取网络。 首先将RGB 人脸图片输入该网络,得到192×192×68 的面部特征点热度图矩阵,将其和输入图片的192×192×3 的矩阵连接,这一步要确定两者维度的对齐,一起输入到重建网络中进行重建,这个流程的模型就是vrn-guided,结构如图10 所示。
本文认为二维的特征点的热度图并不能最好的对模型进行引导,原图中很多信息并没有被包含进去:如姿态、光照等信息。 因此,希望能训练一个网络对姿态等信息进行预测,并与特征点信息一起对原模型进行引导,尝试达到比VRN 更好的效果。
2.3.1 面部特征点信息用于引导
在VRN 原文中,本文使用了一个另外的网络用于面部特征点的检测, 将检测结果转化为192x192x68 的热度图与vrn-unguided 连接后再输入到UNET 中,用于引导三维重建过程,本文首先复现了该工作并达到了baseline,复现结果的NMELOSS,如表5 所示。

表5 VRN-guided 复现结果的NME-LOSSTab. 5 NME-LOSS of the VRN-guided reproduction
本文认为就人脸特征点的表达来说,使用热度图并不是唯一且最好的方法。 通过面部特征点提取的神经网络获得人能理解的面部特征点的热度图,再从热度图转化为机器能理解的神经网络特征,经历了两次不同domain 的翻译过程,这个翻译的过程可能导致一些信息的损失和网络训练难度增加。 因此,本文在LFPW, HELEN, AFW, AFLW 等数据集上训练了一个以UNET 为基本结构的面部特征点检测网络,在IBUG 和MUG 数据集上测试达到dlib 的标准化MSE 误差,将倒数第二层的特征提取代替原先的特征点热度图进行引导。
希望倒数第二层的特征更好地起到引导重建的作用,本文首先将预测特征点网络和三维重建网络分别训练作为初始化,打开连接两个网络的通道一起训练,重复上面的两个步骤几次以后,得到最终结果,模型结构如图11 所示。
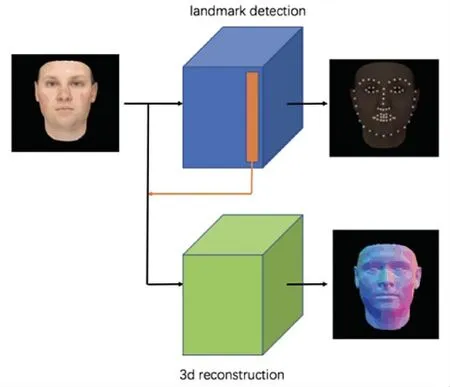
图11 模型结构Fig. 11 The model structure
最终保持了面部特征点检测的准确性,达到了dlib 相当的baseline,同时得到了比使用特征点热度图更高的结果,如图12 所示。 图12(a)是在AFLW2000上的结果,图12(b)是在Florence 上的结果。

图12 特征点信息引导方法与VRN 的比较Fig. 12 Comparison of vrn and method with feature point information guidance
2.3.2 面部姿态信息用于引导
同时本文发现MR-UNET 在面部姿态预测有着很好的表现,因此本文参考面部特征点信息用于引导的方法,将MR-UNET 的倒数第二层特征用于补充引导VRN-guided,最终在原基础上得到了更好的效果。 图13(a)是在AFLW2000 上的结果,图13(b)是在Florence 上的结果。
首先单独训练MR-UNET 和VRN-guided 作为初始化,然后将两个网络连接起来同时训练,重复这两个步骤若干次直到重建损失不再下降。
2.4 对自编码体素网络损失函数的研究
在VRN 的原文中,使用了一个全局的交叉熵损失函数作为网络的LOSS 进行训练,式(1):
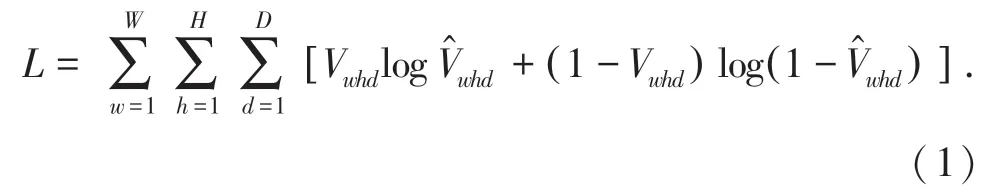
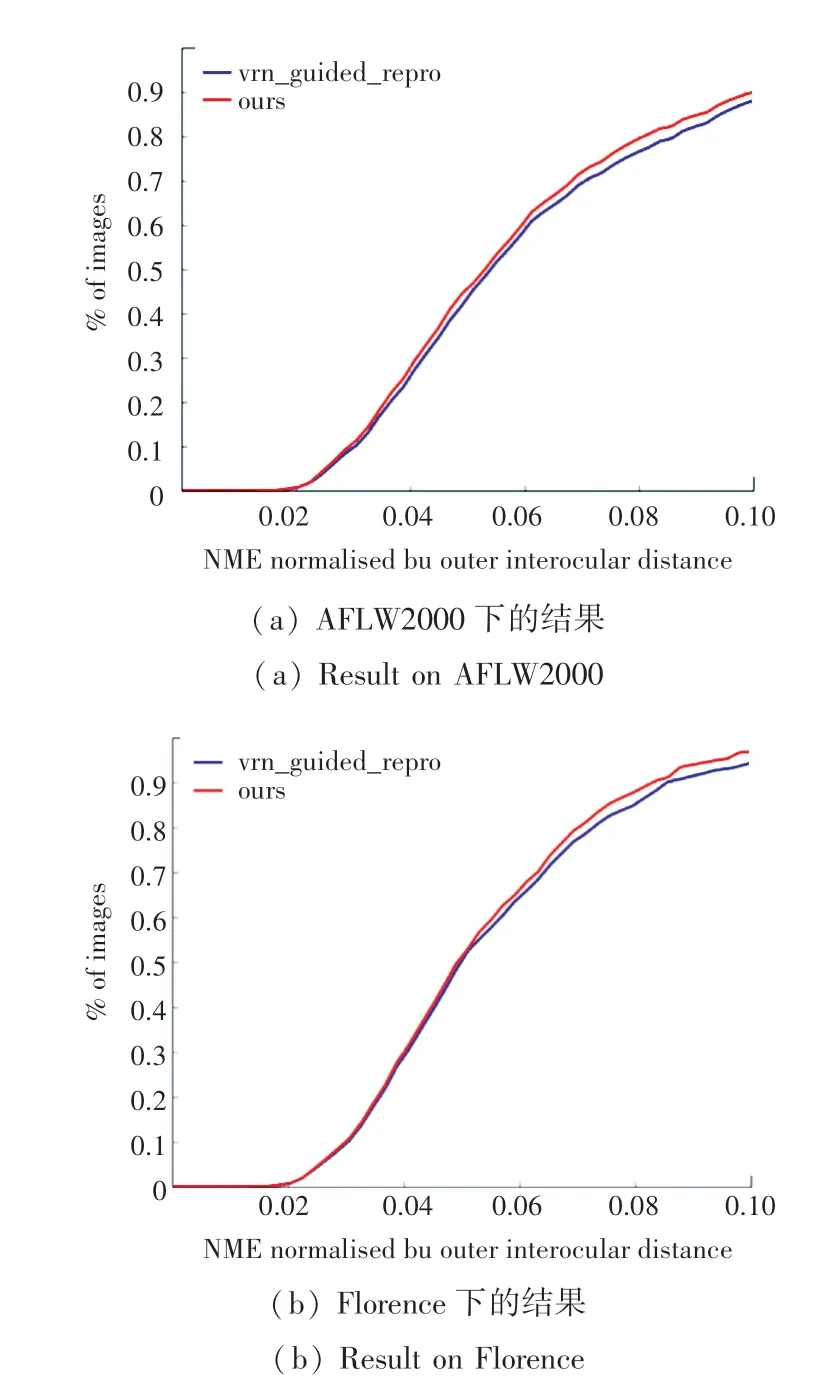
图13 姿态信息引导的方法与vrn 的比较Fig. 13 Comparison of vrn and method with pose information guidance
近期在目标检测领域Focal-Loss 被提出,用于优化交叉熵损失函数[3]。 目标检测通常被分成两阶段和一阶段两种算法,前者的代表是Faster RCNN,这类算法准确率高但执行效率低,虽然可以通过减少proposal 的数量或者降低输入图像的分辨率等方式来进行提速,但实际上治标不治本,速度并没有质的提升;后者的代表是yolo,这种直接回归的检测算法效率高,但准确度低。 经过实验研究表明单阶段的算法不如两阶段的算法准确度高是因为样本类别不均匀,在目标检测中,成千上万个候选位置中只有少部分是正样本,导致样本不均衡,这使负样本占据了总LOSS的大部分,而且大多数都是简单样本,导致了模型优化偏离了预期,之前的OHEM 方法也试图解决样本不均匀的情况,但是它虽然增加了分错的样本的权重,却忽略了容易分类的样本。 针对这个问题,本文提出了focal loss,通过减少易分类样本的权重使得模型在训练时能够更加专注于难分类的样本,同时在原文中还训练了一个retinaNet 来证明focal loss 是有效的。 实验结果表明retinaNet 即具有单阶段检测器的速度,又拥有两阶段检测器的准确度。
按照Focal Loss 的思想,全局形式的交叉熵损失未必是最好的损失函数表达,因为正负样本都被赋予了同样的权重。 而在体素模型下,本文统计得到三维空间中负样本(空块)与正样本(体元块)的比值大约为3:1,希望模型把更多注意力放在正样本上,也就是那些体元块上。 因此,本文提出Focal Loss 来解决这个问题,其表达式(2)如下:
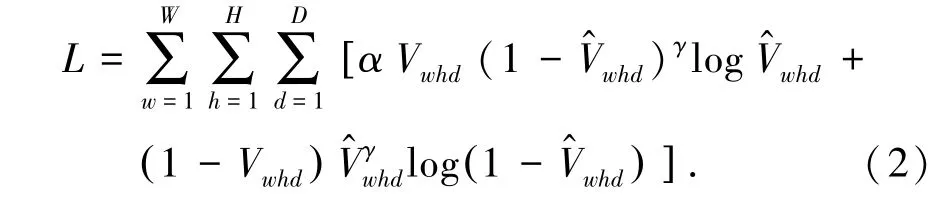
其 中,α和γ是 超 参 数。 本 文 测 试 了AFLW2000 和Florence 数据集下,不同α和γ下的VRN 的NME-LOSS,结果如表6 和表7 所示。
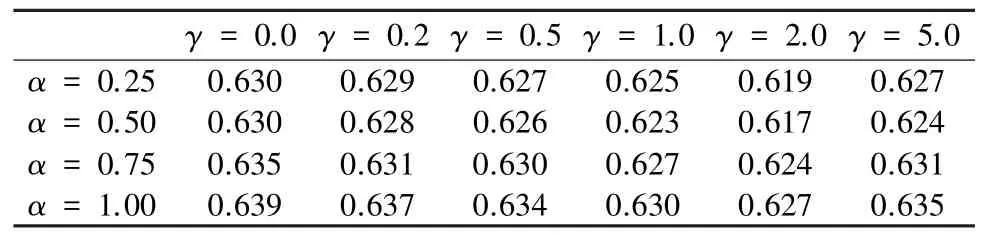
表6 AFLW2000 下的结果Tab. 6 Result on AFLW2000
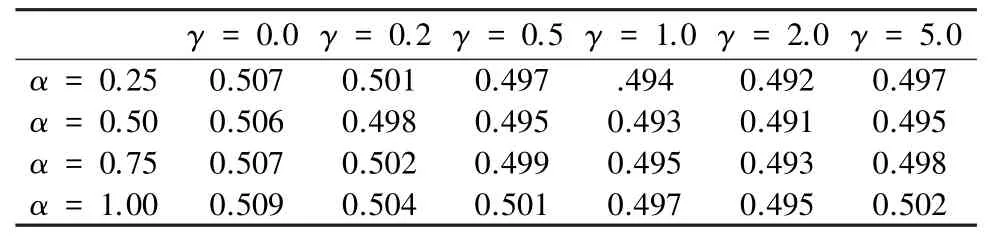
表7 Florence 下的结果Tab. 7 Result on Florence
实验证明:α =0.5,γ =2.0 时,模型的重建效果最好。
3 结束语
本文首先讨论了基于单幅图像的三维人脸重构的研究背景、意义、和几种主流方法,包括传统的基于贝叶斯统计学习建模,使用马尔科夫-Metropolis算法优化的方法和以VRN 和3DDFA 为代表的利用卷积神经网络的深度学习模型,逐一讨论了这些方法的优缺点和适用的条件及范围。 复现了传统的基于统计学习的重建方法,并给出了实验结果,比较了这些结果和几种其他的已有方法的效果优劣。 另外,也复现了VRN 的有引导项和无引导向的两个版本,训练达到了原文的baseline,验证了VRN 算法的有效性,为接下来对VRN 算法的改进奠定了基础。
本文从3 个方向对VRN 算法进行了改进。 本文对体素重建网络使用的U-Net 结构和性能进行了描述,并分析了其优点和缺点;针对其缺点,介绍了Fish-Net 模型,并根据其思想对体素重建网络进行了修改和优化,给出了实验对比结果,证明了在同等参数规模下改进后的模型表现得更好;同时,本文提出了MR-Net模型,在多尺度下对VRN 进行优化,实验表明MR-Net在多尺度下对VRN 的改进是有效的;本文就带有引导项的体素重建网络进行了讨论,研究了带有引导项的重建网络效果优于不带有引导项的重建网络的原因,分析了利用人脸特征点热度图引导的优势和不足,进而构建了一个由串联U-Net 构成的面部特征点检测网络,使用网络的特征对体素重建网络进行引导,实验测试证明这种改进较直接用特征点热度图的方式引导更加合理,并且得到了更好的结果;本文还尝试了使用MR-Net 对姿态进行预测,用姿态预测网络的倒数第二层对重建网络进行引导,实验证明这种改进同样是有效的,相比VRN-Guided 得到了更好的结果;最后,本文对体素重建网络的损失函数进行了讨论和改进,叙述了VRN 的损失函数的推导方法,说明了其本质上是一种交叉熵损失函数及其原理,介绍了Focal Loss,并借助Focal Loss 的思想对这种交叉熵损失函数进行了改进,并给出了实验的对比结果,结果表明本文提出的非全局方式的Loss 形式相比与原文的全局形式在同等条件下有更好的表现。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05 11:40:44
江西教育·职教版(2022年9期)2022-04-29 00:44:03
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
计算机集成制造系统(2020年4期)2020-05-08 02:41:16
中国惯性技术学报(2019年1期)2019-05-21 00:58:46
今日农业(2019年15期)2019-01-03 12:11:33
动漫星空(2018年9期)2018-10-26 01:17:14
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
发明与创新(2015年33期)2015-02-27 10:40:09
