
YOLO 算法在交通监控目标检测中的研究与应用
2020-11-11 08:02陈小娥
智能计算机与应用 2020年6期
陈小娥
(福建船政交通职业学院 信息工程系, 福州350007)
0 引 言
随着我国社会经济的快速发展以及城市化进程的加快,道路上车辆和行人数量不断增多,交通问题也随之变得日益严重。 道路交通目标种类繁多,对不同车辆和行人进行快速检测和识别是计算机研究者近年来面对的挑战性任务之一,也是智能交通监控系统和自动驾驶技术等应用的关键。
目标检测是计算机视觉技术的一项重要研究课题,是指通过相关算法来实现客观世界中对象的分类和定位。 主要分为传统目标检测和近阶段基于卷积神经网络的目标检测。 传统目标检测主要先通过手工提取特征,然后针对特定检测对象设计和训练分类器,该方法很大程度上依赖于提取的特征的准确性,然而手工提取的特征往往对目标的表达能力不足,鲁棒性低。 近阶段基于卷积神经网络的目标检测,又分为两大类,包括Two- Stage 和One-Stage的两种不同的方法和路线。 其中,Two-Stage 方法主要通过利用RPN 网络来对候选区域进行推荐,其中具有代表性的是R-CNN、Faster RCNN 系列方法,如2014 年R-CNN 框架[1]被提出,通过大容量卷积神经网络来提取特征,而后接连出现了一系列改进框架,如SPP-Net[2]、Fast-R-CNN[3]、Faster RCNN[4]、R-FCN[5]等算法。 而One Stages 主要通过直接回归目标的位置来进行目标的检测,比较典型的有YOLO 和SSD 系列方法,能够对目标检测的速度进行进一步的提升,如2015 年Joseph Redmon等[6]提出的YOLO,用一个卷积神经网络实现定位分类一体化,是一个不基于区域算法的代表。 接着,刘维等[7]借用了区域目标检测的思想,将提取候选框的网络和目标分类的网络进行合并,提升了准确率。 2017 年和2018 年,YOLOv2[8]和YOLOv3[9]版本相继被提出,它们在保持高效检测速度的基础上,引入了anchor box 和多尺度等思想,进一步改进了网络结构,特别是YOLOv3 引进了ResNet 思想,进一步提高了网络的检测精度和速度。
本文采用基于YOLOv3 深度学习网络,对道路交通中的行人、自行车、小汽车、公共汽车、卡车等目标进行检测。 首先,对采集的数据集进行预处理,然后利用YOLOv3 对交通监控对象进行目标检测,最后进行实验结果分析。
1 YOLOv3 网络结构
YOLOv3 采用Darknet-53 作为骨干网络,进一步地提高了目标检测的定位和分类精度。 Darknet-53 包含53 个卷积层,大量采用3∗3 和1∗1 的卷积核。 为了训练53 层的深度网络,借鉴了ResNet的思想,在卷积层之间构建残差模块,设置跳跃连接。 YOLOv3 通过借鉴特征金字塔网络,设计多尺度特征提取结构,提升了小目标的检测效果。YOLOv3 模型结构如图1 所示。
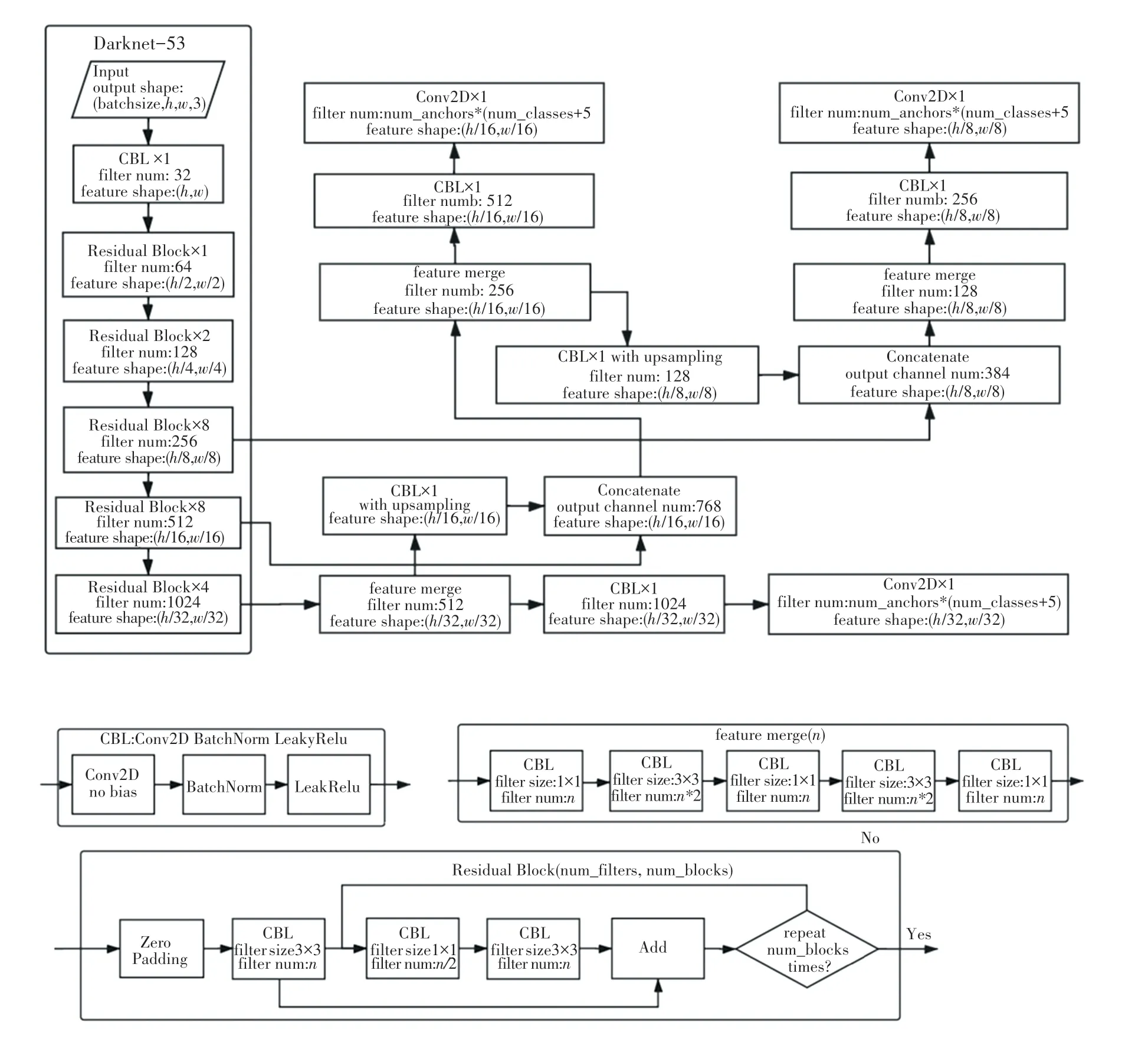
图1 YOLOv3 模型结构Fig. 1 Yolov3 model structure
2 实 验
2.1 实验环境及步骤
本实验采用的硬件配置参数如下:Intel(R)Core(TM)i7-8750H CPU@2.20 GHz 处理器、16 GB内存、6G NVIDIA GeForce GTX 1060 GPU。
实验的主要步骤如下:
(1)数据集的采集。 实验中数据集一部分来自网络上搜集到的交通监控视频,一部分通过爬虫程序直接爬取网络上交通监控目标图像。
(2)数据预处理。 数据预处理包括对采集到的监控视频分解出视频帧、对视频帧和直接爬取的目标图像进行清洗等,以及对它们进行标注。
(3)采用Yolov3 对测试数据集进行目标检测,并进行结果分析。
2.2 数据预处理
实验中的数据集包含提取的视频帧和爬取的监控目标图像,以及扩充后的图像,共4 490 幅。
提取视频帧的核心代码如下所示,按照每秒取1 帧图像进行保存,crop_vertices 存放待保存的图像的裁剪范围,可以根据实际情况设定,提取的帧也可不裁剪。
提取的视频帧和直接爬取的图片,经过一定的筛选,过滤到没有目标的样本,使用labelme 进行标注。 数据集的样本示例如图3 所示,上方两图是交通监控视频提取的帧,下方两图是网上直接爬取的交通监控图像。 表1 中主要包含了数据集所有图片中小汽车、自行车、公共汽车、卡车和行人的目标数量。 表2 中显示了这些目标像素大小的分布情况,尺寸介于(0,32∗32]之间的属于小物体,(32∗32,96∗96]属于中物体,大于96∗96 的属于大物体。

图3 数据集的样本示例图Fig. 3 Sample pictures of data set

表1 数据集中目标数Tab. 1 Target number in dataset

表2 目标像素大小分布Tab. 2 Target pixel size distribution
2.3 结果分析
实验过程中,使用原Yolov3 权重文件[9],其训练参数中批次大小batch_size 为64,初始学习率为0.001。 对标注好的数据集进行测试。 YOLOv3 算法对交通监控目标检测的结果如下图所示。

图4 检测结果示例图Fig. 4 Some pictures of test result
通过实验结果定量评估YOLOv3 算法对于交通监控目标检测识别的效果。 从准确率Precision 和召回率Recall 对算法进行评价。 具体地,

其中,TP 表示本身是正样本,分类器也认为它是正样本;FP 表示本身是负样本,分类器认为它是正样本;FN 表示本身是正样本,分类器认为它是负样本;Precision 表示的是分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例;Recall 表示的是分类器认为是正类并且确实是正类的部分占所有确实是正类的比例。 IOU 交并比衡量监测框和标签框的重合程度。 表3 中显示了对应不同交并比阈值的平均精度,AP 表示Average Precision,第1 个AP 对应的IoU =0.5:0.95,第2 个和第3 个AP 对应的IoU 分别为0.5、0.75,后3 个AP 的下标分别对应小、中、大目标。 另外,对应大、中、小目标在IoU =0.5:0.95 的AR (average recall)值分别为0.279、0.468、0.584。

表3 实验结果分析Tab. 3 Analysis of experimental results
3 结束语
本文自行设计标注了交通监控目标的数据集,使用Yolov3 算法对交通监控对象进行了目标检测,最后进行了实验结果分析。 下一步可以增加样本的多样性、同时针对自己的数据集进行模型的训练,进一步提高准确率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
计算机系统应用(2021年2期)2021-02-23
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
软件导刊(2017年4期)2017-06-20
