
基于迁移学习的中文阅读理解
2020-11-11 08:01孙一博
智能计算机与应用 2020年6期
孙一博, 秦 兵
(哈尔滨工业大学 计算机科学与技术学院社会计算与信息检索研究中心, 哈尔滨150001)
0 引 言
近年来,机器阅读理解任务引起了学界越来越多的关注,其旨在验证机器以类似于人的方式理解文档的能力。 基于神经网络的模型在机器阅读理解任务上大获成功,但大多数都是针对大量数据的数据集而设计的,例如:CNN,Squad,NewsQA 等。 本文要研究的中文高考阅读理解任务,由于其数据量较小,主流的神经网络模型在其上容易收敛失败。
为了解决数据稀缺的问题,本文采用基于迁移学习的方法,即使用来自数据丰富的源领域的知识来帮助模型在数据稀少且不宜获得的目标领域进行高效的训练[1]。 迁移学习在神经网络模型中的一个比较直观的应用是微调(fine-tuning),即用源领域的数据对模型进行预训练,应用训练得到权重来初始化模型,随后在目标领域的数据上通过反向传播对模型的权重进行微调。
本文基于渐进神经网络(Progressive neural network)进行中文机器阅读理解的研究。 渐进神经网络是近期提出的一种迁移学习框架,它使用横向的链接机制来保留从历史任务中学习得到的权重,从而在一定程度上解决了迁移学习中的灾难性遗忘问题[2]。 本文针对机器阅读理解任务对渐进神经网络进行了扩展,使用注意力机制对不同任务间的表示进行计算,并且使用长短记忆网络对得到的表示建模。 利用中国高考历届试卷构建中文阅读理解数据集CTARC 作为目标数据集,并使用已有的英文阅读理解数据集RACE 作为源数据集。 实验结果表明,本文提出的方法优于所有的基线模型。
1 方法
1.1 渐进神经网络
如图1 所示,一个渐进神经网络由若干个互相链接的列组成,其中每列代表一个由参数构成的L 层的神经网络,每层都包含隐层输出∈,其中ni是第j 列第i 层的输出维度。 在第一列中,代表建模第一个任务的神经模型的训练过程结束后,可以得到其参数。 随后,在两个任务的情况下,当第二个任务来临时,保持在第一个任务中学习到的参数不变,并使用随机初始化的新参数初始化代表第二个任务的神经网络模型,其中该模型第i 层的输入包含两个部分:一部分来自第二个任务自身的输入,另一部分来第一个任务上一层输出的横向连接。 具体的,当推广到K个任务,这种用于融入历史任务信息的横向链接可以形式化为(1)式:
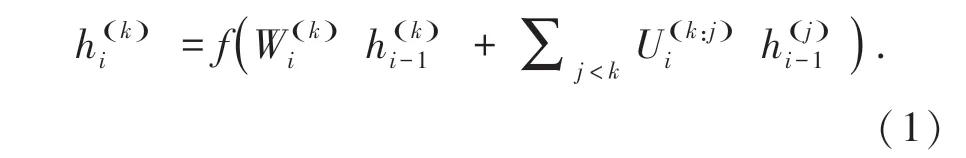

图1 渐进神经网络Fig. 1 Progressive Neural Network
1.2 适配器

1.3 交叉注意力适配器
在渐进神经网络架构中,单列的所有层都可以看作是一个单变量函数y =f(x),这种架构适用于强化学习,其中神经模型的设计是为了解决特定的马尔可夫决策过程。 当尝试将渐进神经网络框架应用于阅读理解模型时,为了找到文档中与问题相关的部分,注意力机制几乎在所有的为了阅读理解设计的神经模型中都经常被使用。 注意力机制层通常以文档表示和句子表示作为输入,根据问题输出文档表示的加权求和,使得该层成为一个二元函数,不符合原来的渐进神经网络框架。
为了克服这个限制,一个直接的方法是使用公式(2)分别处理两个输入,而不考虑它们之间的交互作用,这使得当前任务中的注意力层的输入和前一个任务中的输入属于不同的语义空间。 使用两个不同的语义空间的组合可能会破坏原有的意义,这种方式很难从前面的注意层中学习到注意力权重。
如图2 所示,为了能更好地学习注意力知识,本文提出了一种方法,旨在通过让两个语义空间的两部分跨越不同的任务来进行注意力机制,缩短两个语义空间之间的距离。 形式化的,用二元组 () 表示第j 列第i - 1 层的两个输出,用g 表示注意力机制的二元函数,每个函数g 都有不同的参数。 在当前列k,通过将对前序相应位置做注意力机制,可以得到如下的两个列表(3)和(4):

图2 交叉注意力适配器Fig. 2 Cross Attention Adapter

实际上,列表C 代表不使用外部链接的条件下计算第i 层的注意力机制。 在跳过代表注意力机制的第i 层后,可以用渐进神经网络的方式计算第i +1 层的输入。为了更好的获得组合语义性的表达,相对于使用带有非线性的前馈神经网络,本文使用循环神经网络来构建适配器模块:首先,用列表A,B,C 和当前的内部注意力结果构建了序列T =,g ()] 。 用 长 短 记 忆 神 经 网 络(LSTM)按(6)、(7)式得到其组合语义表示:

1.4 Stanford AR 模型
Stanford Attentive Reader cite 是一个强大的模型,在CNN 数据集上取得了最先进的结果。 作者声称,该模型在这个数据集上的性能几乎达到了上限。
用(p,q,o) 来代表由文章,问题,选项,构成三元组。 p =p1,…,pm和q =q1,…,ql是长度为m 和l的文章词序列和问题词序列,o =o1,…,oC是包含C个候选答案的答案集合,每个答案也是一个句子。任务的目标就是在集合o 中找到正确的答案。

类似的,使用双向GRU 将选项oi编码为oi,使用双线性注意力机制计算选项与文章t 的相关性得分,并将该得分送入softmax 函数来得到最终的概率分布。 具体的,第i 个选项是正确答案的概率计算公式(10)为:
2 实 验
2.1 数据集
RACE 数据集是从中国三家大型免费的公共网站上收集到的原始数据,其中阅读理解题都是从中国老师设计的英语考试中提取出来的。 清洗前的数据共计137 918 篇文章、519 878 道题,其中初中组有38 159 篇文章、156 782 道题,高中组有99 759 篇文章、363 096 道题。 清洗后的数据量如表1 所示。

表1 数据集划分Tab. 1 The separation of Dataset
本文收集了2004 ~2016 年中国高考的原始资料,其中阅读理解题提取了中国高考专家设计的科普文章阅读理解部分的阅读理解题。 该部分中的文章主要是以科普类文章为主。 为了对原始数据进行清洗,进行了以下筛选步骤。 首先,删除所有与问题设置格式不一致的问题和试题,例如:如果某道题的选项数不是4 个,就会被删除。 同时,还删除了所有含有“下划线”或“段落”等关键词的问题,因为下划线和段落段信息的效果难以重现。 经过过滤步骤后,一共得到176 个段落和486 个问题。 为了进行数据增强,用谷歌翻译将得到的数据进行英文翻译,得到了CTARC-E 数据集。 CTARC 数据集的详细统计见表2。
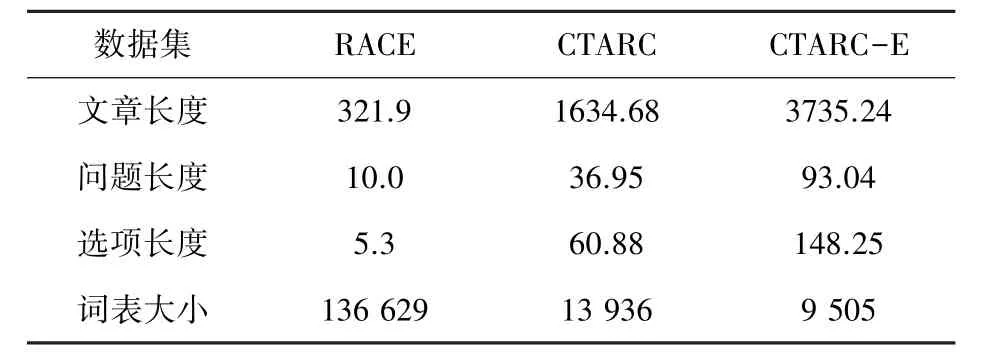
表2 数据集统计Tab. 2 Dataset statistis
2.2 实验结果
实验结果如表3 所示,其中RACE single 代表在RACE 数据集上训练Stanford AR 模型,CTARC single in Chinese 代表在CTARC 数据集上训练Stanford AR 模 型,CTARC single in English 代 表 在CTARC-E 数据集上训练Stanford AR 模型,Twocolumn finetuning 代表使用微调做迁移学习, Twocolumn PNN 代表使用原始的渐进神经网络做迁移学习,Two-colum PNN+CRA 代表使用融合交叉注意力适配器的渐进神经网络做迁移学习。 在应用渐进神经网络的设置时,使用RACE 作为第一个任务,使用CTARC-E 作为第二个任务。

表3 实验结果Tab. 3 Main results
Stanford AR 模型在RACE 数据集上的性能为43.3%,远低于人类上限性能94.5%,这意味着RACE 是一个具有挑战性的数据集,现有的模型可能会从数据集中学习到有限的知识。 然而,所有的迁移学习方法,都有助于模型在单一中文数据上集提高性能。 在这些方法中,本文提出的框架获得了10%的显著提高。 在迁移学习的三种设置中,Two-column finetuning 优于Two-column PNN 3.7%,这表明使用原始的渐进神经网络对于处理阅读理解问题并不是一种有效的方法。 本文所提出的方法的取得了最好的效果,显示出了交叉注意力适配器的有效性。
3 结束语
基于迁移学习的方法利用从一个大型的英语数据集中转移的知识来帮助模型更有效地解决中文高考中的阅读理解任务。 本文提出了一种具有交叉注意力适配器的渐进神经网络模型,用于解决阅读理解任务。 该方法在渐进神经网络模型的基础上进行了改进,提供了一种跨越不同任务的注意力机制,并使用长短记忆神经网络来表示所有注意力层的组合输出。 实验结果表明,与所有的基线模型相比,该模型在解决目标中文阅读理解任务上的表现更好。
猜你喜欢
模式识别与人工智能(2022年9期)2022-10-17
北京航空航天大学学报(2022年8期)2022-08-31
计算机研究与发展(2022年1期)2022-01-19
科学与财富(2017年24期)2017-09-06
电脑爱好者(2016年22期)2016-12-16
长江学术(2016年4期)2016-03-11
CHIP新电脑(2015年2期)2015-12-22
文苑(2015年9期)2015-09-10
轻兵器(2015年20期)2015-09-10
长江学术(2015年1期)2015-02-27
