
大规模商品知识的组织和查询优化
2020-11-10 07:10黄涛贻林煜明
计算机工程与应用 2020年21期
黄涛贻,李 优,宋 浩,林煜明
1.桂林电子科技大学 广西可信软件重点实验室,广西 桂林 541004
2.桂林电子科技大学 广西自动检测技术与仪器重点实验室,广西 桂林 541004
1 引言
随着Web技术的不断发展,互联网正由以人与人互联为主要特征的Web2.0 时代迈向基于知识互联的Web3.0时代[1],其目标是实现人和机器都可以理解的互联网,使网络更加智能化。在这种背景下,如何将Web上的海量数据知识化并进行高效的管理,使之为用户提供更高质量的信息服务,这已经成为学术界和工业界共同关注的热点问题。2012 年谷歌率先推出知识图谱,并以此作为增强其搜索功能的辅助知识库,构建下一代智能化的搜索引擎。随后,各种类型的知识图谱陆续推出,例如基于维基百科的YAGO[2-4]、DBpedia[5]和Freebase[6]等。
与此同时,网络上商品相关的数据也在急剧增长,而上层应用/用户对商品信息准确获取的需求却难以满足。这两者间的矛盾不但没有得到缓解,而且存在日趋严重的态势。造成该矛盾的主要原因一方面是绝大部分承载商品信息的数据均以无结构的形式存在,严重地限制了它们自动化和智能化的应用;另一方面,这些大规模的信息缺少高效的数据管理机制,导致用户直接面对碎片化和高冗余的信息,进一步加剧了信息过载的问题。对Web 上包含商品信息的海量数据进行知识化和结构化处理,并实现统一、高效的管理不仅能有效地解决该矛盾,而且能向用户提供更全面和更准确的信息服务[7-8]。如何高效地检索大规模商品知识成为一个重要的问题。已有许多知识检索系统支持大规模知识图谱,如 SW-store[9-10]、RDF-3x[11-13]、Hexastore[14]和 gStore[15-17]等。它们在存储数据时,通过映射字典将知识图谱中URI(Uniform Resource Identifier,统一资源标识符)文本转换为ID 值,从而降低数据存储和查询的代价。基于图模型的知识检索系统,如gStore,能够利用知识图谱的图结构特性处理知识检索,具有较高的查询效率。
当处理大规模查询时,大量文本需要转换成对应的ID值,这导致频繁地访问映射字典,此时映射字典的时间代价不能忽略。另外基于图模型的检索系统在处理商品知识查询时,无法充分利用商品知识图谱的结构特征,导致在进行商品观点知识查询时性能低,无法满足商品知识检索性能的要求。本文围绕上述问题展开研究,主要贡献如下:
(1)提出了一种融合客观与主观知识的商品知识图谱框架,实现对商品客观信息与用户观点信息统一组织。
(2)提出了一种结合学习索引[18]的映射字典,提高映射字典的查询速度,并利用前缀树进一步减少检索时间,实验证明该方法提高了映射字典检索效率。
(3)提出了一种商品属性观点变量组合策略,该方法基于商品知识图谱的结构特点,实验证明该方法有效降低了商品知识检索的时间。
2 相关工作
已有基于单机的RDF 数据存储与查询可以分为2大类,分别为基于关系模型和基于图模型。基于关系模型的方式是利用成熟的关系型数据库进行管理,从而实现知识存储与查询的功能。例如三列表构建具有3 个列属性的表,并将RDF三元组数据直接插入到表中,虽然这种方式实现简单,但处理复杂查询时包含大量自连接操作。水平表将RDF数据中所有的属性都作为表的列属性,避免了自连接操作,但导致存在大量的空值。属性表[19]通过对属性聚类从而减少空值的产生,但是聚类是需要交给数据专家进行,当数据更新时,可能需要重新聚类,造成巨大的表的维护代价。垂直切分[9-10]为每个属性构建一张两列表,分别存储主语与宾语,RDF三元组按照属性归类,并存储在对应的表中,具有良好的性能,但当属性为变量时,需要遍历所有的表,导致性能急剧下降。全排列索引[11-14]是对RDF 三元组中元素进行全排列组合并构建索引,解决了垂直划分查询属性效率低的问题,但存储空间代价较高。
基于图模型的方式是利用RDF数据转换成的数据图,与基于关系模型的方式不同,其能够保留原有的图结构。知识查询将转换为子图匹配问题[15]。图划分[20-21]将图划分成若干子图,对每个子图包含的节点构建了布隆过滤器(bloom filter)。GRIN[22]用节点之间的距离采用聚类的方法对图进行划分,然后根据每个聚类的中心节点和半径构建树状索引。gStore 中对每个实体节点进行签名(Signature)编码,构建基于二进制的签名图(Signature Graph),并在此基础上建立VS-tree 索引,减少搜索空间。
总的来说,基于关系模式的方式破坏了RDF 数据原有的图结构,导致额外的存储或查询代价。而基于图模型的方法能有效保存RDF 数据的图结构,提供较好的查询性能,但依赖数据的图结构,现有方法检索商品知识时性能较低。
3 大规模商品知识的组织
3.1 整体框架概况
商品知识图谱辅助用户提供基于知识的检索功能,因此该框架应该与在线购物平台数据结构保持一致,其概要结构如图1所示。

图1 商品知识图谱框架
商品知识图谱总共分为5层,其中最上面两层为客观知识,剩下的三层为主观知识,每层包含的知识分别如下:
(1)商品分类层。在线商城通过对商品进行分类并构建分类树实现对大规模商品的管理,潜在消费者则可以通过商品分类进行目录式检索商品。
(2)商品实例层。这一层主要包含商品实例,以及在线购物平台提供的客观信息,例如商品名称、品牌、价格以及网站提供的商品属性等。
(3)商品属性层。这一层主要包括商品的属性,这里的属性不是平台提供的属性,而是用户评论中观点描述的属性。
(4)观点层。观点层主要包含了用户发表的观点信息,包括对商品或商品属性的观点。
(5)用户层。用户层包含了平台的注册用户,是在平台上进行消费和发表观点的主体。
3.2 商品客观知识
商品客观知识主要是网站提供的客观信息,包括商品分类信息和商品信息。首先,针对客观知识定义如表1所示的类型。

表1 客观知识类型
当表示客观知识时,所需用到的属性如表2所示。
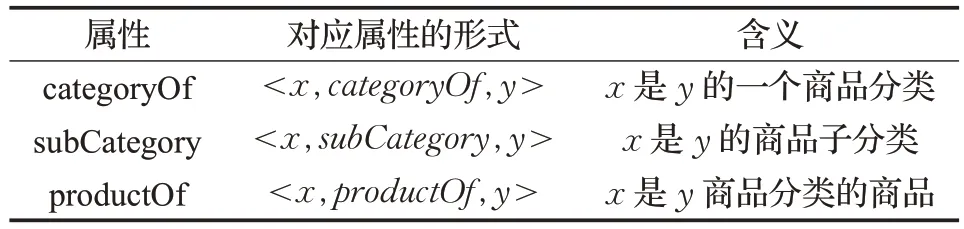
表2 客观知识属性
例如在亚马逊购物平台中,亚马逊网站拥有一个electronics(电子产品)商品分类,headphones(耳机)也是一个商品分类,是electronics 的子分类,商品编号为B0753GRNQZ 的商品属于headphones 商品分类,对应RDF数据图如图2所示。

图2 商品客观知识样例
3.3 用户评论主观知识
用户评论主观知识主要为用户对商品的属性表达的观点,即从评论中抽取的商品属性-用户观点词对。用户评论主观知识是一种多元关系,涉及到用户、商品和商品属性,然而RDF 三元组不能直接表示多元关系。解决该问题的方法是引入中介节点,通过中介节点从而表达多元关系。由于用户的观点是包含于用户所撰写的评论中,因此将用户评论作为中介节点,从而实现表示用户评论主观知识。表示主观知识将引入如下的类型,其定义如表3所示。

表3 主观知识类型
表示主观知识时,所需要的属性如表4所示。

表4 主观知识属性
例如用户A001307232 认为商品B0753GRNQZ 的尺寸好,利用RDF数据图表示如图3所示。其中用户发表的观点都作为opinion的子属性,例子中用户观点good(好)可以通过三元组表示成

图3 商品主观知识样例
4 学习映射字典
当同时处理大规模查询时,大量URI文本需要通过映射字典转换为对应的ID值。传统的映射字典使用B-tree,但随着映射字典规模的增大,其查询效率逐渐降低。学习映射字典结合学习索引技术,基于数据的分布利用机器学习模型对数据分片,从而提升查询效率。
4.1 学习索引
学习索引是将传统索引结合机器学习技术,通过对数据的分布进行训练,得到符合数据分布的模型,从而将传统索引对数据的查询转换为模型对数据位置的预测,而查询时间也转换成机器学习模型的执行时间。同时随着GPU、TPU和FPGA等高性能计算硬件的发展和广泛应用于复杂计算中,同时在机器学习领域也被用于提升模型的执行效率,从而有效降低检索的时间成本。
4.2 文本分布
构建URI文本的学习映射字典,首先需要明确文本的分布。文本是一种复合数据类型,是由多个字符组合构成,可以通过ASCII 编码转换成一个一维整形数组,如图4所示。

图4 文本通过ASCII编码转换成数组
商品知识图谱中所有URI 文本排序构成一个有序集合U={u1,u2,…,uM},每个 URI 文本ui通过 ASCII编码转换成数组xi。数组xi取前N个元素,对于数组长度n<N的,设置=0(j>n),最终得到数组集合XN={x1,x2,…,xm} 。对URI文本集合U转换的XN,构建累积分布函数如式(1)所示:

4.3 学习映射字典结构
学习映射字典分为两个层,第一层包含机器学习模型,第二层包含了B-tree,URI文本集合通过第一层机器学习模型将数据分片,每一个数据分片使用B-tree 保存,其结构如图5所示。

图5 学习映射字典结构
第一层是机器学习模型。首先将URI文本集U通过ASCII编码转换成数组集合XN,使用神经网络对文本分布进行训练,最终得到学习模型P(x),该模型实现预测URI文本ui在数据集U中的位置p。为了降低神经网络在查询时执行的时间代价,这里采用单隐层全连接神经网络,如图6所示,其输入层神经单元数量为N,输出值为p。

图6 单隐层全连接神经网络
URI 文本ui在数据集U中的位置不可能为负数,同时取值跨度广,因此,需要激活函数具有较广的输出范围并且避免预测值p≤0 ,所以神经网络模型采用ReLu函数作为激活函数,如式(2)所示:

训练模型时,利用URI 文本ui在数据集U中真实位置y与模型预测位置p之间的误差值,采用方差作为损失函数,如式(3)所示:

第二层包含多棵B-tree。理想状态下,第一层的模型能正确预测ui在文本集中的位置,但数据的复杂性导致预测位置与真实的位置仍存在较大的误差,因此基于第一层预测位置,设置阈值s,将数据切分,即当(h-1) ⋅s≤P(xi)<h⋅s时,将ui保存到第h个数据分片,每个分片分别使用B-tree保存。
4.4 URI文本压缩
商品知识图谱中完整的URI文本较长,如表5展示了商品知识图谱中部分类型实体对应的完整URI 文本。其中,商品类型实体的URI文本包含了41个字符,前面30个字符用于表示命名空间。当神经网络输入层的神经单元数量N≤30 时,对于神经网络模型,所有商品类型的URI将会是一样的,所以输入层的神经单元的数量至少需要N>30。在商品知识图谱中,命名空间作为完整URI 的前缀,其种类较少并且固定,但文本长度普遍较长,导致神经网络模型需要更多的输入节点,这造成神经网络模型的执行效率降低。

表5 部分类型实体对应的完整URI文本样例
为了提高机器学习模型的执行效率,利用前缀树对URI文本中冗余的前缀进行压缩,减少神经网络模型输入层的神经单元的数量N。URI文本的前缀为命名空间,其通常使用斜杠(/)符号表示命名空间的目录或分类层级,因此利用斜杠符号对URI 命名空间分割,然后构建前缀树,图7 展示了命名空间压缩前缀树的结构。该结构中,圆形表示前缀树的节点,内部的数字为节点对应的编号,边的标签对应命名空间分割后得到的文本子串。
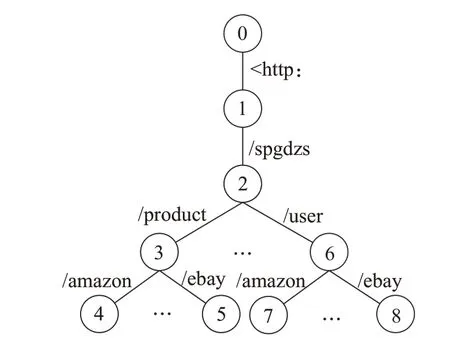
图7 命名空间压缩前缀树
通过前缀树压缩后,表5中完整的URI文本将转换成如表6 所示,相比完整的URI 文本,压缩后的URI 文本长度较短,减少了神经网络输入层神经单元数量N,这有效降低了学习映射字典第一层神经网络模型的执行时间代价。

表6 部分类型实体压缩后的URI文本样例
5 商品知识查询优化
5.1 连接代价
每个变量在获得候选值集合后,需要根据查询图的结构对变量进行连接操作。连接一个变量的过程在算法1 中给出,其中IRT表示中间结果集,即已连接变量所构成的子图的结果集合。
算法1连接一个变量节点算法
输入:SPARQL查询图Q,当前中间结果表IRT,需要连接的变量节点v;
输出:连接变量节点v后的中间结果表nIRT;
1.设置新的中间结果集nIRT为空,即nIRT=φ;
2.if变量节点v的候选集为空then
3.returnnIRT;
4.forIRT中每条中间结果记录rdo
5.设置临时表格tmp为空,即tmp=φ;
6.for中间结果记录r中每个元素edo
7.ife对应Q中变量节点v′与v之间没有边相连then
8.continue;
9.通过e获取v的另一个候选集list;
10.iftmp为空then
11.list与v的候选集进行交集操作,并赋予tmp;
12.else
13.list与tmp进行交集操作,并将结果赋予tmp;
14.fortmp中所有的元素edo
15.创建r副本r′,将e添加到r′;
16.r′添加到nIRT;
17.returnnIRT;
连接操作的时间代价主要由两部分组成:交集操作代价和I/O 代价。其中交集操作受到列表的大小影响,在执行前难以预测其代价。I/O 代价是访问磁盘操作造成的,由于磁盘的访问速度比内存慢几个数量级,当频繁访问磁盘时会造成巨大的I/O 代价。这导致I/O代价成为连接操作代价的绝大部分,因此连接代价基本可以由I/O 代价决定。在算法中连接一个变量所造成的I/O代价由中间结果集IRT的大小决定,因此查询图连接的总代价可以由每一步连接操作时中间结果集IRT的大小共同决定。对查询图包含节点集合V={v1,v2,…,vn}和边集合E={e1,e2,…,em},假设每次只连接一条边,其连接的总代价cost如式(4)所示,其中Si表示进行第i步连接时中间结果集IRT的大小和第i步的代价。

5.2 连接顺序
第i步连接的代价Si是第i-1 步连接完成所得到,每步连接操作的代价都是由其前序连接操作得到,因此不同的连接顺序会造成得到不同的连接代价,这里针对表7所示的商品知识数据进行分析。

表7 商品知识图谱RDF三元组样例
表7 展示了商品知识图谱RDF 数据样例。为了简洁表示,所有的URI 都使用简写表示,并用URI 缩写的第一个字母表示该元素的类型,如P 开头的URI 为商品,C 开头的 URI 为商品分类,R 开头的 URI 为评论,O开头的URI 为观点,F 开头的URI 为商品属性。该数据假设有两个商品分类C1和C2,其中C1分类下有3个商品,C2分类下有1 个商品,有两个用户分别发表了3 条评论,且每条评论分别都包含了对特征F1和F2的观点。图8展示的是该样例对应的RDF数据图,其中省略了边的标签。

图8 商品知识图谱样例RDF数据图
查询1假设查询C1分类所有商品及所有观点特征的知识,该查询对应的查询图如图9 所示,同样省略了边的标签,但保留变量边的标签。图中每个变量的对应候选值集合均标在变量节点右侧。
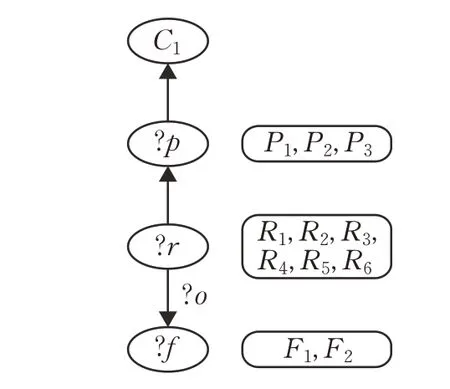
图9 SPARQL查询图及变量候选节点
查询1查询C1分类所有商品及所有观点特征
SELECT ?p ?f ?o where {
?p rdf:type Product.
?p productOf C1.
?r rdf:type Review.
?r reviewOn ?p.
?f rdf:type Feature.
?r ?o ?f.
};
从图中可知,变量?f候选值集合的大小为2,变量?r的候选值集合大小为6,变量?p候选值集合的大小为3。目前最新的图模型查询系统,例如gStore,在选择连接顺序时优先选择候选集中元素较少的变量节点进行连接,因此在针对该查询顺序为?f→?r→?p,其每步连接生成的中间结果集IRT如表8所示。
对于表8中的操作,首先选择变量?r作为连接操作的起始节点,将候选值集合中的元素依次加入到IRT中,此时|IRT|=|C(?f)|=2;然后与变量?r进行连接操作,此时S1=2,连接操作结束后|IRT|=12;最后与变量?p进行连接操作,此时S2=12,完成连后|IRT|=10。最后对根据IRT中每条记录变量获取?o的值,此时S3=10。因此总代价为S1+S2+S3=24。
在商品知识图谱中,用户评论唯一关联一个商品,但通常会包含多个观点。根据这个数据特征,将选择变量?p作为连接操作的起始节点,此时连接顺序为?p→?r→?f。其每步连接生成的中间结果集IRT如表9所示。
首先将变量?p的候选值集合中的元素依次加入到IRT中,此时|IRT|=|C(?p)|=3,然后与变量?r进行连接操作,此时S1=3,连接完成后|IRT|=5,然后再与变量?f连接,此时S2=5,连接操作完成后|IRT|=10。最后根据IRT中每条记录变量获取?o的值,此时S3=10。该连接顺序的总代价为S1+S2+S3=18。不同的连接顺序,虽然最终产生的结果不变,但每步生成的中间结果集不同。
在商品知识图谱中,每一条用户评论Ri由一个用户Uj撰写,并且描述一件商品Pk连接。但评论中会对多个商品属性表达观点,如图10所示。
在商品知识图谱中,商品、用户的数量规模庞大,而商品属性的规模相对较小,导致连接操作时,优先将商品属性与用户评论进行连接。然而用户评论唯一关联一个商品,但通常会包含多个观点。因此在商品知识图谱中,商品属性和评论进行连接时,中间结果集会扩大,所以连接过程中在进行评论与商品属性连接的操作应放在最后进行。

表8 连接过程中每步MRT 的数据

表9 连接过程中每步中间结果集IRT 的数据

图10 一条商品评论的数据图
5.3 变量组合连接策略
现有基于图模型的查询系统主要针对查询图中边标签均为常量的查询。在处理边标签为变量的查询时,其连接过程首先将节点变量连接起来,然后获取变量边的值,这种连接策略导致查询性能较低。
但是在商品知识图谱中,用户观点作为一种重要的知识,存在许多围绕用户观点的查询,查询1 展示了一种简单的用户观点查询。但围绕用户观点往往存在更加复杂的查询,例如查询与商品P1相关的商品,这些商品与P1拥有共同的买家,并且买家对该商品的某些属性具有相同的观点,该SPARQL如查询2所示。
查询2查找商品P1相关商品的SPARQL
SELECT ?p ?f ?o where
{
?r1rdf:type Review.
?r1reviewOn P1.
?r2rdf:type Review.
?p rdf:type Product.
?p productOf C1.
?r2reviewOn ?p.
?f rdf:type Feature.
?r1?o ?f.
?r2?o ?f.
?u rdf:type User.
?u write ?r1.
?u write ?r2.
}
针对该查询,首先排除变量?o与?f,并将其他变量根据查询图进行连接,得到中间结果集,如表10所示。

表10 查询2的连接中间结果集
这里针对中间结果集第二条结果进行讨论,当R1和R2对商品属性F1和F2分别发表了不同的用户观点,其RDF数据图如图11所示。
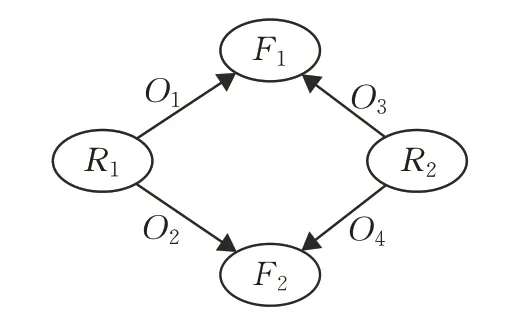
图11 两个用户评论的观点都不相同的数据图
按照原有连接策略,将对变量?f进行连接操作,将产生如表11所示的结果。

表11 无效的中间结果列表
最后获取变量?o的结果时,表11 的所有中间结果均是无效的,然后被删除。在考虑中间结果是否需要连接变量?f时,需要变量?r1和?r2对应的值都有相同的边才需要连接,因此,当变量?r1和?r2对应的值没有相同边时,该中间结果可以直接删除,而不需要进行下一步操作。
当两个评论R1和R2存在相同的观点,但是针对不同的商品属性,仅考虑是否存在相同的边标签,同样也会导致无效的中间结果的产生,如图12所示。

图12 两个评论存在相同观点但不是同一个属性的数据图
上面的连接方式都是将商品属性和用户观点分开单独进行查询,但在商品知识图谱中,商品属性和用户观点是组合并成对出现。因此利用这个特性,本节提出了一种商品属性观点变量组合(product Aspect and Opinion Combination,AOC)的连接策略,即将变量边?o与变量节点?f组合成一个整体变量,首先对变量?f和?o以外的变量节点进行连接,然后对变量组合进行连接操作。连接组合变量的过程如算法2所示。
算法2连接一个组合变量算法
输入:当前中间结果表IRT,需要连接的组合变量(e,v);
输出:连接变量节点v后的中间结果表nIRT;
1.设置新的中间结果集nIRT为空,即nIRT=φ;
2.if 变量节点v的候选集为空then
3.returnnIRT;
4.forIRT中每条中间结果记录rdo
5.设置临时表格tmp为空,即tmp=φ;
6.设置临时表格tmpv为空,即tmpv=φ;
7.for 中间结果记录r中每个元素eledo
8.ifele与v之间不是通过边edo
9.continue;
10.将ele添加到tmpv;
11.通过ele获取v的另一个候选值集合list;
12.iftmp为空 then
13.list与v的候选集进行交集操作,并赋予tmp;
14.else
15.list与tmp进行交集操作,并将结果赋予tmp;
16.iftmp为空 then
17.continue
18.fortmp中每个元素elethen
19.获取ele边候选值集合tmpe;
20.for 元素tmpe中每个元素edgethen
21.通过ele和edge获取候选列表list
22.iftmpv⊆listthen
23.创建r副本r′,将(edge,ele)添加到r′;
24.r′添加到nIRT;
25.returnnIRT;
6 实验与分析
6.1 实验环境
本实验硬件环境为单台Intel®Core™i5-6500 @3.20 GHz四核处理器的计算机,拥有16 GB DDR3内存和1 TB 机械硬盘。为了保证实验运行的公平性,没有采用GPU、TPU或FPGA等硬件加速。操作系统为64位Ubuntu 16.04操作系统。
实验数据将通过本文设计的商品知识图谱框架组织,其中知识图谱的数据为真实数据与仿真数据相结合,数据集的总体概况如表12 所示。其中商品分类、商品信息、用户知识为真实数据,来自于亚马逊平台,其中包含商品实体总数为478 626,用户实体总数为1 000 000。用户评论、观点知识为仿真数据,每个用户随机挑选商品并发表评论,评论中包含随机数量的观点知识。

表12 数据集的一些统计信息
6.2 实验结果与分析
6.2.1 学习映射字典
实验从存储空间和响应时间两个方面进行分析。由于学习映射字典与传统映射字典都采用了B-tree 结构,为了减少实验环境的差异性,实验中两者采用相同的B-tree。此外B-tree的阶数对数据存储空间和查询响应时间存在影响,将针对B-tree的阶数进行讨论。两种映射字典存储所占用的空间如表13所示。

表13 数据对应映射词典所消耗的存储空间 MB
根据结果显示,随着B-tree 阶数的增加,两种映射字典在存储空间上都呈现减少的趋势。当两个映射字典采用相同阶数时,学习映射字典的存储空间比传统的映射字典占用的空间少。学习映射字典中第一层只需要保存机器学习模型的参数,其占用的存储空间远小于整体存储空间,本实验中,模型存储空间占用约1 KB。在学习映射字典第二层中,第一层学习模型将数据切分成多个小规模的数据分片,每个数据分片对应的B-tree的高度均不高于传统映射字典中B-tree,同时其所有B-tree 内部节点包含键的总数也比传统映射字典中B-tree少。由于内部节点键的数量占用了绝大部分存储空间,所以学习映射字典相比传统映射字典的所占用的存储空间小。
接下来进一步验证学习映射字典的查询效率。首先讨论B-tree的阶数对响应时间的影响,这里随机查询URI 文本100 000 次,然后统计平均单次查询URI 文本的响应时间,如图13所示。

图13 不同阶数B-tree的平均响应时间
实验结果显示,当B-tree 采用不同阶数时,学习映射字典的平均响应时间比传统映射字典的平均响应时间更短。此外,随着B-tree 阶数的增加,学习映射字典查询效率提升更加明显。
然后针对随机查询URI文本的次数进行比较,这里采用128 阶B-tree,统计平均单次查询URI 文本的响应时间,结果如图14所示。
实验结果表明,在处理不同随机访问次数时,学习映射字典的平均响应时间比传统映射字典的平均响应时间更短。

图14 B-tree阶为128时平均查询时间
学习映射字典利用机器学习模型将大规模URI 文本集分割成多个小规模URI文本集分片,当查询URI文本时,只需要对其中一个URI 文本集分片进行查询,相比传统映射字典,学习映射字典减少了查询过程中比较操作的次数。同时第一层的机器学习模型采用单隐层全连接神经网络模型,其模型复杂度较低,执行效率较高,使用CPU处理器执行此模型,平均单次执行时间小于100 ns,小于整体查询时间。
6.2.2 连接策略
实验针对商品知识图谱,围绕商品的主观与客观知识,设计了常用的商品知识查询语句,如表14所示。
上述SPARQL查询对应的含义如下:
Q1:在商品分类C1下,查找商品属性F1具有O1观点的商品。
Q2:查询商品P1所有的用户观点和对应的商品属性。
Q3:查询一个商品分类C1下所有商品,用户更加关心哪些属性。通过查询所有该商品分类下所有商品以及对应的用户观点和特征,并将数据通过商品属性进行聚合操作,然后统计数量。
Q4:查询与用户U1爱好相同的用户,这些用户不仅与用户U1购买过相同的商品,并且他们对该商品的某一商品属性发表过相同的观点。
SPARQL查询运行时间结果如表15所示。
实验结果显示,在查询Q1的查询性能相似,由于查询中不包含对商品属性和用户观点的查询,优化策略没有起到作用。而针对查询Q2、Q3 和Q4,这些查询中都包含商品属性和用户观点的查询,此时优化的查询策略发挥作用,采用AOC 策略的系统比gStore 具有更高的查询效率。其中查询Q2 语句较为简单,不存在复杂的关系,并且查询针对一个商品,相关的信息量较少,采用AOC 连接策略的系统相比gStore 性能提升了2 倍。查询Q3 语句同样较为简单,但查询涉及一个商品分类所有商品的数据,相关的数据量较大,gStore查询超过1个小时未获得结果,而采用AOC 策略的系统在较短时间内完成查询,通过减少中间结果的产生,提高了查询的效率。查询Q4的语言的复杂度比查询Q2,Q3大,gStore同样无法在1 h内完成该查询,采用AOC策略的系统在较短时间内完成查询,由于避免了生成无效的中间结果,从而提高了查询效率。

表14 商品知识查询

表15 SPARQL查询运行时间
7 结束语
首先,为了统一管理商品客观信息与用户观点主观信息,本文设计了一种融合商品客观与主观知识的商品知识图谱框架。然后,为了提升查询效率,降低URI 文本转换成对应ID值的代价,结合学习索引,提高查询效率,并利用前缀树对URI 文本中冗余的前缀进行压缩,进一步提高查询效率。接着,为了提高商品知识查询的效率,设计了商品属性观点变量组合的连接策略,具有较高的商品知识查询效率。最后在商品知识图谱数据上验证了本文提出的方法具有性能上的提升。在之后的工作中,将会考虑利用GPU构建异构计算平台,进一步提升商品知识检索的效率。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
少先队活动(2020年12期)2021-01-14
河北理科教学研究(2020年2期)2020-09-11
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
中成药(2017年3期)2017-05-17
读者(2016年14期)2016-06-29
领导科学论坛(2016年9期)2016-06-05
新高考·高二数学(2014年7期)2014-09-18
杂草学报(2012年1期)2012-11-06
