
一种基于多层决策树分类的入侵检测方法
2020-11-10 01:44黄泽斌唐郑熠王金水
贵州大学学报(自然科学版) 2020年5期
方 伟,黄泽斌,唐郑熠*,2,3,王金水
(1. 福建工程学院 信息科学与工程学院,福建 福州 350118; 2. 湖南工商大学 移动商务智能湖南省重点试验室,湖南 长沙 410205; 3. 福建省大数据挖掘与应用技术重点试验室,福建 福州 350118)
入侵检测是网络安全防护的重要技术之一,是指对入侵行为的检测与识别。它通过对网络行为、安全日志、审计数据等信息的分析,来判断网络或系统中是否出现违反安全策略的攻击行为[1]。作为一种主动的安全防护技术,入侵检测可以在攻击行为产生危害前进行拦截,并且对内部和外部的攻击或危险行为都能提供有效的防护,因此被视为防火墙技术的必要补充。
入侵检测技术的基本原理是通过对相关数据的分析,构建正常或异常行为的模型,与用户行为进行比较匹配,以甄别出可能具有危害性的行为[2-3]。因此,从相关数据中分析发掘出有效的行为特征与模式是入侵检测技术的核心与关键。数据挖掘作为一种从海量数据中搜索挖掘隐藏信息的有效技术,十分适用于入侵检测,包括分类、聚类、异常检测在内的多种数据挖掘技术都在入侵检测领域取得了显著的成效[4]。
分类是入侵检测中较为常用的技术,研究人员使用了多种不同的分类算法来区分用户的正常行为和攻击行为:段丹青使用支持向量机(support vector machine,SVM)算法对用户行为进行分类[5],取得了97%的分类正确率,但其试验只将用户行为分为正常和异常两种类型,不能充分说明SVM算法的分类能力;马占飞等[6]采用粒子群算法来调整SVM算法的参数,在对5种用户行为分类的试验中取得了93%的正确率,同时根据其对比试验,传统的SVM算法在对同样的数据集进行分类时,正确率为85%;夏景明等采用随机森林算法对用户行为进行分类[7],其正确率高达99%,但其同样只将用户行为分为两类,缺乏对复杂类型分类能力的证明;丁红卫等采用深度卷积神经网络对5种用户行为进行分类[8],并更为细化地比较了每种类型的分类正确率,最高达99%,但该种方法不能对所有类型都保持理想的分类能力,最低的分类正确率仅有64%;SHONE等提出了一种多层非对称深度自编码器算法[9],对5种用户行为进行分类,除了小比例样本,都取得了100%的正确率,但由于深度学习技术的固有缺陷,其所训练的分类模型缺乏可解释性。
本文研究了数据集中记录类型的层次性现象,提出了一种多层次的分类方法,对处于相同层次的记录类型训练分类模型,从而得到多个针对不同层次记录类型的分类模型,能够根据记录类型的层次性实现自顶向下的识别。将该方法应用在入侵检测中,不仅能够实现高效准确的行为分类,而且能够灵活地控制分类的粗细程度。以决策树作为分类算法,在权威的入侵检测数据集上进行试验,结果表明该方法具有理想的检测性能,并且能够有效地缓解由于行为类型增多造成的检测性能下降的问题。
1 预备知识
1.1 决策树分类
分类是指根据数据记录的各个属性取值,识别数据记录所属的类型。通过已有数据可以训练得到分类模型,其定义如下:
定义1 分类模型一个分类模型是一个映射f:Xy,其中X= {x1,x2, …xn}是属性集合(即数据记录),yP是记录类型,P为记录类型集合。
决策树是一种树形的分类模型,其节点分为测试节点(非叶子节点)和决策节点(叶子节点)两类:每个测试节点包含一个测试条件,每条出边是测试条件的一个输出;每个决策节点包含一个记录类型的取值,其定义如下:
定义2 决策树一棵决策树T= (N,E),其中N=NT∪ND为节点集合,E为带值的有向边集合:
(1)NT= {nt0,nt1, … }为测试节点集合,每个测试节点是一个测试条件Vi=nti(X′),X′⊆X,Vi是nti的输出值集合。
(2)ND= {nd0,nd1, …}为决策节点集合,每个决策节点是一个记录类型ndiP。
(3)E= {
(4)有且只有一个根结点nt0NT:不存在
图1是一棵决策树的示例。

图1 决策树示例Fig.1 The example of decision tree
在使用决策树对记录X进行分类时,从根节点开始进行测试,即计算v=nt0(X),根据v的值决定下一个测试节点,直到遇到决策节点终止,即得到该记录的类型。
Iterative dichotomiser 3(ID3)是Quinlan于1986年提出的算法,它以贪心策略为基础,以信息增益作为测试条件有效性的度量指标,是第一个具有广泛影响力的决策树算法。Classification 4.5(C4.5)算法同样是由Quinlan于1993年提出的,它是ID3算法的改进,既能够处理离散型的属性,也能够处理连续性的属性,是目前最常用的决策树算法[10]。
1.2 入侵检测
入侵检测是通过分析用户行为或系统的相关数据,提取各种行为模式或特征,进而识别出系统中存在的危险行为。目前的入侵检测技术大致可以分为两类:
(1)异常检测:构建安全的行为模型作为用户行为的评价标准,当用户行为明显有别于安全行为模型时,则认为出现了入侵。
(2)特征检测:根据已知的入侵来提取并构建入侵行为的特征库,当用户行为与特征库中的某个特征模式匹配时,则认为出现了入侵。
在设计一种新的入侵检测方法时,需要一个包含正常行为和入侵行为的数据集,用于检测新方法是否有效。目前最为权威的入侵检测数据集是1999年国际知识发现和数据挖掘竞赛所公布的数据挖掘与知识发现数据集(knowledge discovery and data mining,KDD_Cup_9)[11],它来源于1998年MIT的Lincoln试验室所承担的DARPA入侵检测评估项目。该项目建立了一个模拟军事网络中各类入侵行为的数据集,共计约700万条记录,包含5大类网络攻击。基于该数据集,Columbia University的入侵检测系统(intrusion detection systems,IDS)试验室进行了精简和完善,发布了KDD_Cup_99数据集。该数据集包括两个版本,完全版本包括约500万条记录,而10%的抽样版本包含约50万条记录。迄今为止,KDD_Cup_99是有关入侵检测的研究中应用最为广泛的验证数据集。
2 多层决策树分类方法
2.1 基本原理
决策树是一种简单有效的分类技术,易于使用和理解。但是,当需要分类的数据记录具有较多的类型时,会使决策树的规模变得庞大,从而降低分类的准确率与效率。因此,减少数据记录的类型,是提高决策树分类技术性能的可行途径。但数据记录类型的减少,不能以弱化分类需求为手段,否则可能导致分类技术的效果大大降低。
在分类问题中,存在着数据记录的类型具有层次性的现象,例如,人类是哺乳动物的子类、轿车是汽车的子类等。然而决策树无法识别类型之间的包含关系,其分类性能也会受到一定程度的影响。
针对这一问题,可以对每一个层次的类型分别训练决策树,从而显著减少每棵决策树所要划分的类型数量。同时,通过多棵决策树的组合,能够保证对所有的类型完成分类。下面给出形式化定义。
对于两个记录类型x和y,若y是x的子类,则记为
定义3 记录类型的层次性对于一个记录类型集合P和一个子类关系集合R,如果满足:
记录类型如果具有层次性,则可以表示为一棵树。由于树的0层只有一个根节点,即在该层次上只有一个类型,这在实际的分类问题中是不可能出现的。为了解决这个问题,可以在记录类型的最高层次上,额外添加一个origin类型,作为最高层次类型的父类型,用伪代码表达为:
For allyPThen
R:=R∪ {
End If
P=P∪ {origin}
End For
对每个记录类型及其子类型,可以训练一棵分层决策树:
定义4 分层决策树一棵分层决策树TH= (T,p,Pp)。
其中:T是一棵决策树;(2)p是一个记录类型;(3)Pp是p的子类型集合。
算法1描述了如何对训练数据集D(记录类型集合为P,子类关系集合为R),训练出一个分层决策森林F。
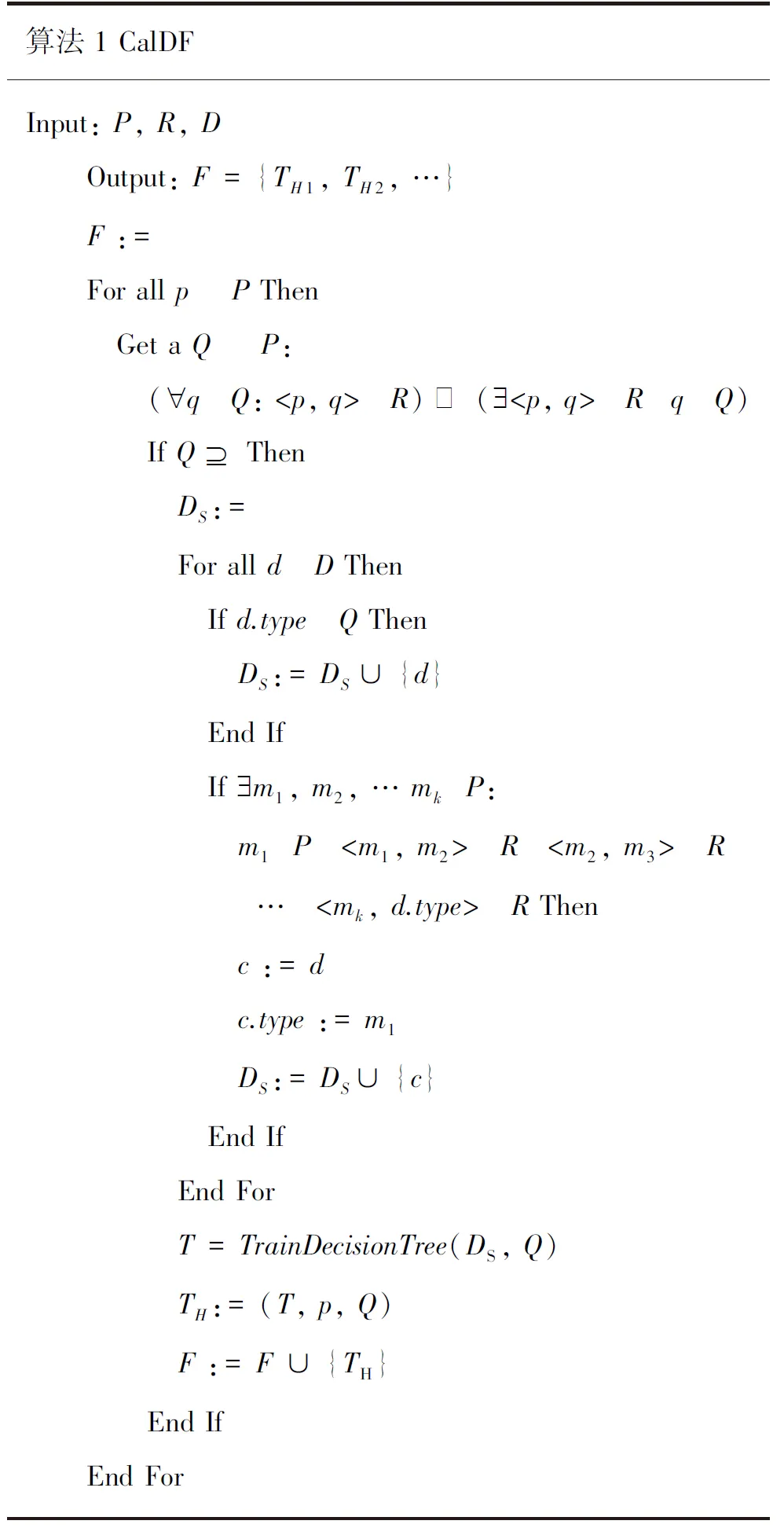
表1 训练决策森林算法Tab.1 Calculate decision forest(CalDF)
算法1对每个记录类型p,找出其所有子类型集合Q。根据Q,筛选出D的子集DS,其所含数据记录的类型(d.type),或者属于Q,或者是Q中某个类型的子孙类型,并将数据记录的类型修改为Q中的对应类型。由数据子集DS和记录类型子集Q,使用决策树算法Train Decision Tree(如C4.5)训练出一棵决策树T,从而得到一棵分层决策树TH= (T,p,Q)。所有的分层决策树构成分层决策森林F。
算法2是使用分层决策森林F对数据记录d进行分类的过程。

表2 多层分类算法Tab.2 Multilayer classification(MLC)
首先从分层决策森林F中选择TH·p=origin的分层决策树,用其对记录d进行分类,得到d在该分层决策树上的类型t。若存在另一棵T=t的分层决策树,则继续使用T对d进行分类,得到新的、更为细化的类型。重复以上过程,直到不存在T=t。
基于多层决策树的分类模型具有以下优点:
(1)能有效降低决策树的规模,避免出现具有大量节点的复杂决策树。
(2)分类模型易于解释和表达。
(3)能够根据分类的粒度要求,提前终止对数据记录的细化分类,从而提高分类效率。
2.2 KDD_Cup_99数据集的多层决策树模型
本节以KDD_Cup_99数据集为例,说明多层决策树的构建与应用方法。
KDD_Cup_99数据集中的记录类型共计有23种,除了表示正常访问的normal类型,剩下的22种类型都表示攻击访问,分属于4大类网络攻击类型[12],具有明显的层次性。为了进一步减少单层决策树所要分类的记录类型,为其增加一个attack类,作为所有攻击类型的父类。数据记录类型的层次结构如图2所示。
根据算法1,可以训练出由以下6棵分层决策树构成的决策树森林:
F= {TH1,TH2,TH3,TH4,TH5,TH6};
TH1= (T1,origin, {normal,attack});
TH2= (T2,attack, {dos,probel,r2l,u2r});
TH3= (T3,dos, {back,land,neptune,pod,smurf,teardrop});
TH4= (T4,probel, {ipsweep,nmap,portsweep,satan});
TH5= {T5,r2l, {ftp_write,guess_passwd,imap,multihop,phf,spy,warezclient,warezmaster}};
TH6= {T6,u2r, {buffer_overflow,loadmodule,perl,rootkit}}。
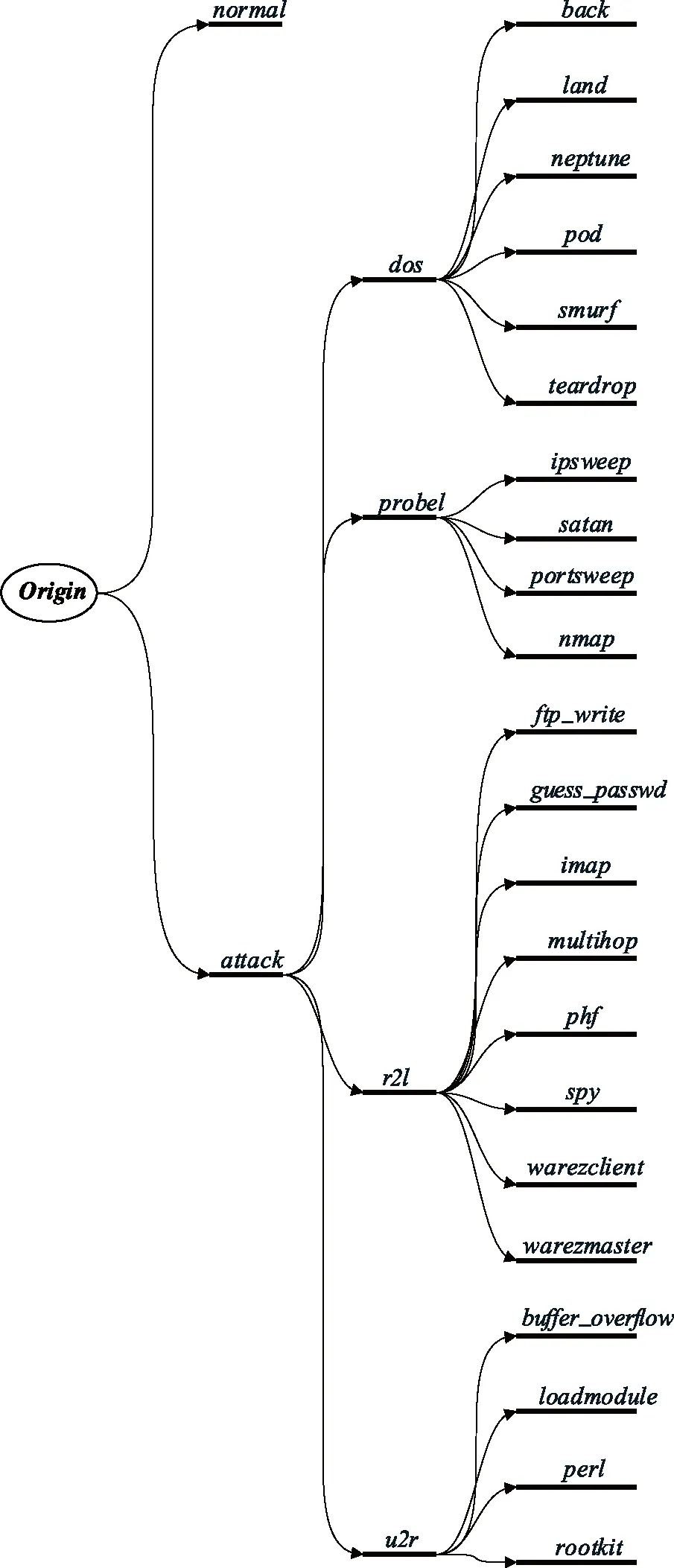
图2 数据类型的层次结构Fig.2 The hierarchical structure of data type
对于一条数据记录,如果它的实际类型是guess-passwd,则会先后调用TH1、TH2和TH5进行分类。分类过程也可以根据分类需求,终止在某个中间层次。
3 试验与结果分析
3.1 数据预处理
KDD_Cup_99数据集共含有4 898 430条记录,但在记录类型上的分布并不均衡,并且部分记录类型的数据量过于稀少,对于决策树的训练没有实际意义,如表1所示。为了保证记录类型的均衡,以达到更好的训练效果,将所有类型的记录数量限制在2 000~40 000的范围内,故对数据集进行以下抽样处理:
(1)若某种类型的记录数量小于2 000,则将该类型的记录全部删除。
(2)若某种类型的记录数量大于40 000,则从该类型的记录中随机抽取40 000条。
(3)若某种类型记录数量在2 000~40 000之间,则全部保留。
经过抽样处理后,用于试验的数据集中所包含的记录类型及其数量如表3所示。
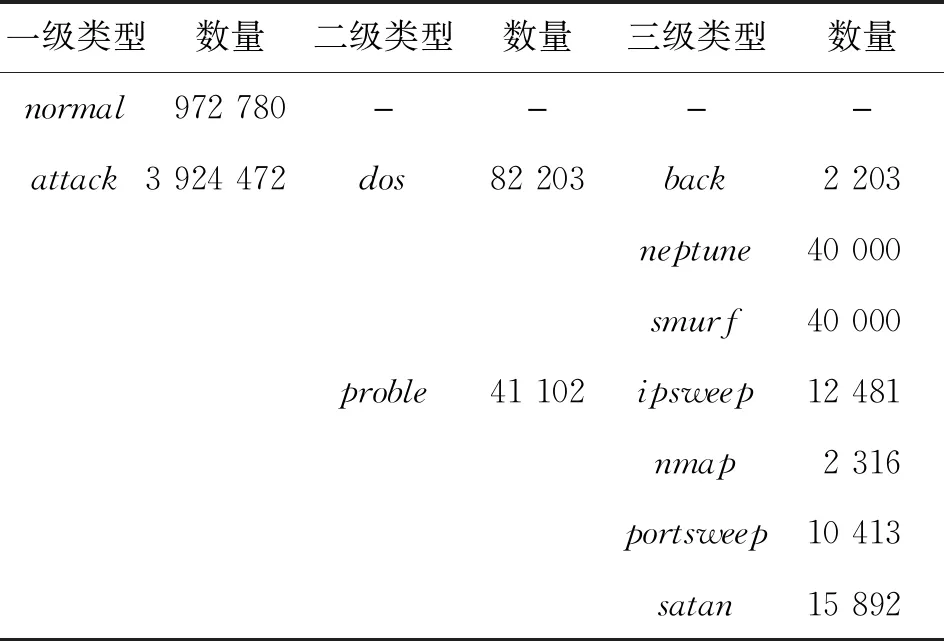
表3 试验数据集Tab.3 Dataset for experiment
对于每一种类型的记录,都取50%作为训练集,50%作为测试集。因此,用于试验的数据集记录总量为1 096 085条,其中训练集数量为548 041条,测试集数量为548 044条。
3.2 试验过程与结果
本文的试验环境如表4所示。
试验过程:
(1)对类型属于{normal,attack}的记录训练分类模型T1,其对记录类型的分类准确率记为Acc(T1,normal)和Acc(T1,attack)。

表4 试验环境Tab.4 Experiment environment
(2)对类型属于{dos,probel}的记录训练分类模型T2,其对记录类型的分类准确率记为Acc(T2,dos)、Acc(T2,probel)。
(3)对类型属于{back,neptune,smurf}的记录训练分类模型T3,其对记录类型的分类准确率记为Acc(T3,back)、Acc(T3,neptune)、Acc(T3,smurf)。
(4)对类型属于{ipsweep,nmap,portsweep,satan}的记录训练分类模型T4,其对记录类型的分类准确率记为Acc(T4,ipsweep)、Acc(T4,nmap)、Acc(T4,portsweep)、Acc(T4,satan)。
试验结果如表5所示。
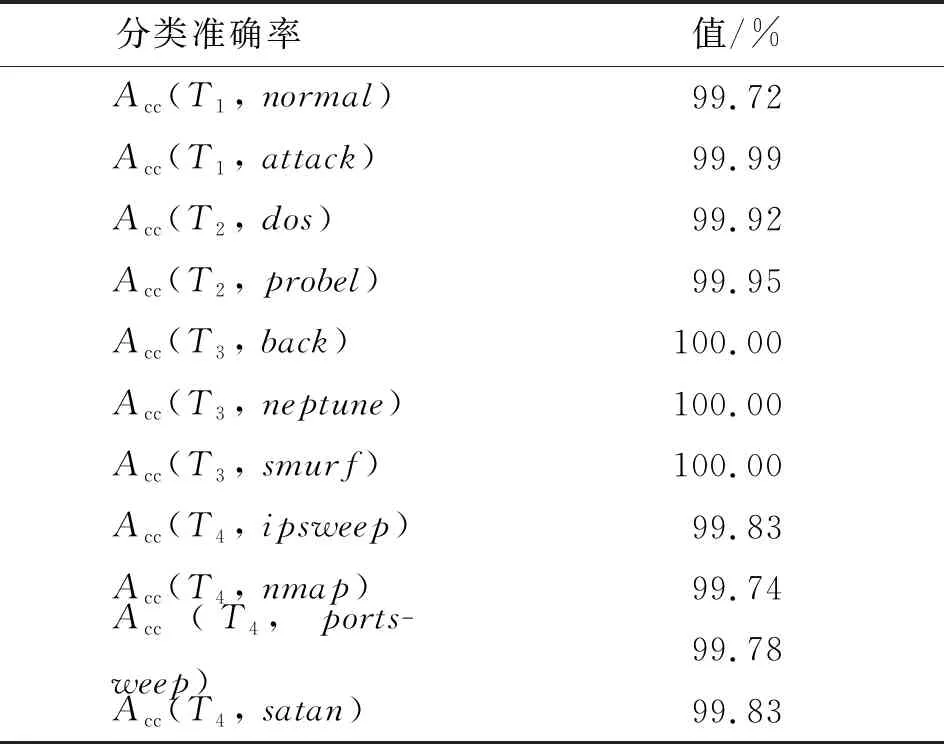
表5 试验结果Tab.5 Experiment results
根据算法2,一条记录要经过多棵决策树的分类,直至最底层的类型,因此其分类准确率应等于上层类型分类准确的乘积,即:
Acc(normal) =Acc(T1,normal);
Acc(attack) =Acc(T1,attack);
Acc(dos) =Acc(T1,attack) ×Acc(T2,dos);
Acc(proble) =Acc(T1,attack) ×Acc(T2,probel);
Acc(back)=Acc(T1,attack) ×Acc(T2,dos) ×Acc(T3,back);
Acc(neptune)=Acc(T1,attack) ×Acc(T2,dos) ×Acc(T3,neptune);
Acc(smurf)=Acc(T1,attack)×Acc(T2,dos) ×Acc(T3,smurf);
Acc(ipsweep) =Acc(T1,attack) ×Acc(T2,probel) ×Acc(T4,ipsweep);
Acc(nmap) =Acc(T1,attack) ×Acc(T2,probel) ×Acc(T4,nmap);
Acc(portsweep) =Acc(T1,attack) ×Acc(T2,probel) ×Acc(T4,portsweep);
Acc(satan)=Acc(T1,attack) ×Acc(T2,probel) ×Acc(T4,satan)。
将试验数据集直接使用C4.5决策树算法进行分类作为对照试验,结果如表6所示。
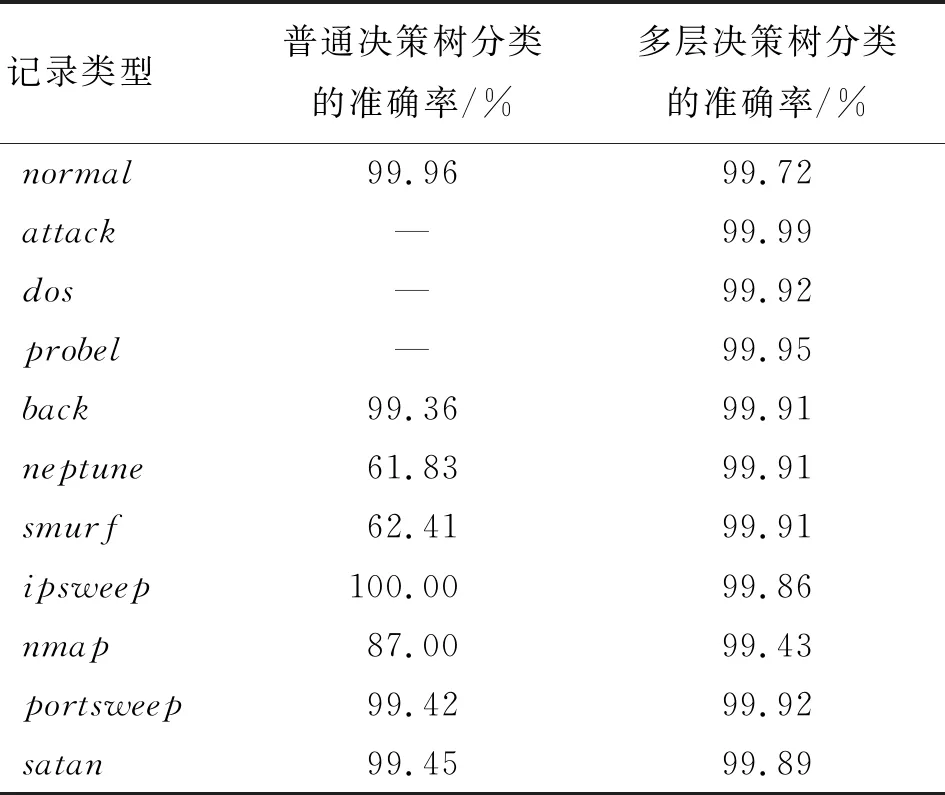
表6 对照试验结果Tab.6 The comparison of different experiments
由表6的对照试验结果可知,多层决策树分类方法具有较为优异的性能,对各种类型的记录都保持了很高的分类准确率。对比普通的决策树分类方法,由于其每次所需要区分的记录类型较少,对记录特征的识别更为准确。普通决策树分类方法不能有效地区分neptune和smurf两种记录类型,而多层决策树分类方法则能够进行有效的识别。
4 结语
分类技术在入侵检测中已经得到了较为成功的应用,攻击行为的识别效率和准确率方面都取了较为理想的结果。但分类技术在处理多类型数据集时,会产生模型构建困难、分类准确率下降的问题。本文针对这一问题,结合入侵行为的类型所具有的层次性特点,提出了一种多层分类的入侵检测方法,并以决策树算法进行了实现。试验结果表明,该方法能够有效提高入侵检测的识别准确率,特别是对小比例的入侵行为的识别上,具有较大的改进。
在本文工作的基础上,可进一步展开以下研究工作:
(1)研究和比较多层分类模型与单层分类模型的复杂度。
(2)研究不同分类算法对多层分类模型的性能影响。
(3)研究新出现的攻击行为类型,并构建相关的数据集。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
数学小灵通(1-2年级)(2021年4期)2021-06-09
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
成都信息工程大学学报(2019年3期)2019-09-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年16期)2018-09-26
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
