
基于ZYNQ集群的神经形态计算加速研究与实现
2020-11-10 07:10张新伟郁龚健刘家航李佩琦柴志雷
计算机工程与应用 2020年21期
张新伟,李 康,郁龚健,刘家航,李佩琦,柴志雷,2
1.江南大学 物联网工程学院 物联网技术应用教育部工程研究中心,江苏 无锡 214122
2.数学工程与先进计算国家重点实验室,江苏 无锡 214125
1 引言
深度学习已经在语音识别、物体检测、自然语言处理、自动驾驶等各个领域中展现出了优异的性能。但高准确率的背后还存在计算代价大、通用智能水平弱等许多局限性[1]。而具有通用智能处理能力的人脑在执行推理、分辨目标、控制移动时,能量消耗不足25 W[2]。因此,各个国家纷纷建立脑研究平台[3-5],希望通过分析生物大脑的工作机制发展神经形态计算,克服现阶段深度学习的不足[6]。
目前,神经形态计算系统实现的方式有软件模拟和硬件实现两种。软件模拟工具主要有NEURON[7]、NEST[8]、SpiNNaker[9]等。NEURON 和 NEST 软件仿真工具由于支持的神经元和突触类型多,因此具有很高的灵活性,而且还支持MPI,具有很好的可拓展性。但是在仿真速度和功耗方面表现不佳。硬件实现分为模拟、数字、模数混合三种方式[10]。鉴于模拟电路对环境特别敏感,目前大部分类脑计算系统都使用数字方式,如Intel 的 Loihi[11]、IBM 的 TrueNorth[12]等专用芯片。专用芯片在性能、功耗方面具有很大的优势,但是神经元和突触的模型较多,芯片一旦流片完成,将无法仿真其他神经元模型或突触模型。FPGA作为一种灵活性高、性能强和低功耗的可编程逻辑器件。与开发周期长、成本高、灵活度低的专用芯片和性能强但功耗高的GPU 相比,在开发SNN 仿真器方面更具有优势。脉冲神经网络的计算密集点主要分布在神经元和突触,突触主要分为静态突触(固定权重)和STDP[13]型突触。一般情况下,对于突触是静态的,计算密集点在神经元,而如果突触为STDP 型,由于突触数量相对于神经元数量较多,而且STDP型突触计算量大,突触计算将成为提高脉冲神经网络仿真速度的瓶颈[14]。所以目前使用FPGA加速脉冲神经网络主要关注点在神经元和STDP 型突触[10]。虽然通过优化公式减少逻辑资源,从而提高神经元和突触的计算并行度,极大地提高了仿真速度。但是与此同时,由于节点规模不可调,仿真规模将受到限制。因此考虑到以上问题,曼彻斯特大学的SpiNNaker采用软硬件协同的方式[9],设计了具有百万核心的类脑仿真平台。SpiNNaker的每个计算节点包含18个ARM核,节点间通过基于FPGA的高速路由进行通信,具有很高的计算速度和规模可伸缩性。但是当选择运行的SNN算法特性与硬件平台不匹配时,会导致其系统还不如通用计算机[15]。
NEST 作为比较流行的脉冲神经网络仿真器,具有支持神经元和突触种类多,而且其更加关注于脉冲神经网络系统的规模、动力学以及结构而不是对单个神经元的仿真。NEST 仿真工具完全开源,使加速NEST 仿真速度成为可能。因此,针对NEST 仿真工具灵活性高、支持大规模仿真,但是仿真速度慢的特点,将NEST 移植到ZYNQ集群。并且Xilinx的ZYNQ 7030是ARM+FPGA的SoC方式,可以很好地支持软硬件协同设计。
因此本文的主要工作如下:
(1)在ZYNQ集群上基于开源NEST类脑仿真器实现了一套类脑计算系统。
(2)针对STDP 学习算法中幂函数和指数函进行优化。并基于FPGA实现了硬件加速。
(3)为了平衡硬件资源、性能与功耗,采用了多节点协同与节点内部硬件加速相结合的方法。
2 脉冲神经网络
脉冲神经网络(SNN)相比于前两代的神经网络,有着本质的区别[16]。主要表现在它是以脉冲的形式传递信息。而且脉冲以时间相关联,是时间节点的离散活动,而不是连续的值。
如图1,脉冲是否能够激发,与神经元阈值电压和神经元前突触强度有关。神经元的微分方程是按照真实生物神经元模型建立。神经元的前突触权重是否有效,与该突触前神经元是否发生脉冲有关。权重的累加值通过一定的计算,超过神经元的阈值电压,神经元将会发出一个脉冲并进入不应期。

图1 神经元脉冲激发图
神经元类型主要分为三种:LIF[17]、Izhikevich[18]、HH[19]。突触分为STDP和静态突触两种。
2.1 脉冲神经网络仿真器NEST介绍
NEST是一款开源的脉冲神经网络仿真工具,NEST可以模拟任何规模的脉冲神经网络。如动物的视觉皮质层和皮质层的平衡随机网络。还可以模拟大脑的学习机制以及可塑性突触模型。NEST本身还支持分布式计算,节点内使用OpenMP和节点间使用MPI进行信息交互。
NEST仿真器仿真SNN分为两个阶段:建立连接和网络仿真。建立连接是将神经元分配到各个节点后,记录每个神经元的连接关系。网络仿真分为神经元计算、突触计算、脉冲发送三个阶段。神经元计算使用时间驱动,即不管神经元前突触是否有脉冲,都会对神经元进行计算。突触使用事件驱动的方式,即有脉冲,神经元后突触才会进行突触更新。
2.2 STDP学习规则
大脑记忆和学习机制的形成被认为主要取决于神经元之间突触连接的改变机制。最近的研究表明,脉冲时间依赖可塑性(STDP)是突触改变的重要机制[20]。基于STDP 的学习机制被广泛用于无监督学习。Diehl 等人[21]使用完全无监督的SNN学习,在不要大量训练的前提下,其对图片的识别精度可以与深度学习相媲美。STDP 虽然有多种运算规则,但都大同小异。设计所涉及到的STDP 运算规则采用NEST 官方给出的运算方法。这种运算规则是由Abigail Morrison在研究真实生物皮质层具有连通性和稀疏性递归网络的突触权重而提出的改进型STDP[13]。STDP的表达式为:

Δt→∞为突触后发射脉冲时间和突触前发射脉冲时间之差。λ为学习率,w0为参照权重,τ为时间常数,α为抑制性增量强度相对于增强性增量强度参数。
2.3 ZYNQ集群
ZYNQ集群是基于ZYNQ 7030的分布式FPGA异构平台。每个节点包含一个ZYNQ 7030的FPGA异构SoC。它包含ARM Cortex-A9处理核心(PS)以及可编程逻辑模块(PL)。PS提供主框架的运行,而PL实现专用硬件架构。计算节点之间使用MPI通过千兆以太网通信。
图2 是ZYNQ 平台的总体架构。每个节点包含一个ZYNQ 7030,节点内部分为处理系统(PS)和可编程逻辑(PL)两个部分。通过级连扩展,系统可以扩展到更大的规模以适应不同规模的仿真。

图2 ZYNQ分布式FPGA异构平台
3 支持NEST仿真器的FPGA硬件设计
3.1 NEST仿真器计算密集点分析
为了分析NEST 仿真器不同突触类型的计算密集点,分别选取突触为静态突触和动态突触(STDP)两种典型案例分析。
在突触为静态突触的物体识别[22]案例中,分别统计1 050、2 100、4 200、6 300、10 500、21 000 个神经元在各个阶段时间消耗情况。由图3可见,突触为静态突触的案例中,神经元的计算时间占比较大。

图3 静态突触各阶段运行时间占比
如果突触是动态突触(STDP)。以NEST 官方给出的衡量多节点计算性能的HPC_BenchMark[23]为例子,分别统计1 125、2 250、4 500、6 750、11 250、22 500 个神经元的Poisson更新时间、突触更新时间和神经元更新时间占比情况。图4中可以看出,在突触为动态突触(STDP)的脉冲神经网络中,突触的计算阶段在总仿真时间中占比较大。
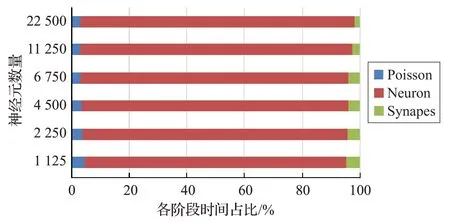
图4 NEST仿真器各阶段运行时间占比
这是因为在脉冲神经网络中,突触的数量要比神经元的数量多的多,突触总数的计算方法如式(2):

Nneurons为神经元数,Csynapes为平均连接神经元的突触数。STDP 型突触一般含有指数运算和幂运算[13],计算相对复杂,这是突触计算成为提高仿真速度的瓶颈的原因。由于神经元部分的加速已经完成[24],所以本文选择对STDP型突触进行加速。
3.2 函数优化与硬件设计
NEST 所使用的STDP 突触模型[13]含有幂函数和指数运算,在硬件实现时,如果不对幂函数和指数函数进行优化,将会损耗很大的逻辑资源,从而使并行度减小。同时,因为单节点的FPGA 逻辑资源有限,不能实现突触的全部并行,所以采用并行+流水的方式满足一定并行度的同时兼顾逻辑资源的使用。
3.2.1 幂函数优化
在NEST仿真器中,STDP学习算法的初始值为45,通过实验得知,在整个仿真阶段,权重值的取值范围是[40~51]之间。对于幂函数weight0.4,可以使用泰勒公式对其优化。幂函数的泰勒公式如下:

当f(x)为 (1+x)α,有:
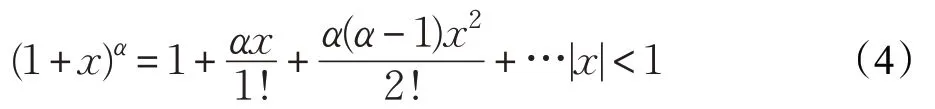
由泰勒公式的特性知道,当x→0 时,获得的误差最小。由于weight >1,并不符合泰勒公式,需要做一定的转换,对于取值范围在[40~51]之间的动态权重,需要在一定范围内动态的改变x的取值范围。如果权重的值在[40~40.5]之间,公式weight0.4可以改写成:


此时的 |x|<1 ,现在,已经满足泰勒公式。将40.250.4约定成常数C,则原有的公式有:

将其代入泰勒展开公式,有:
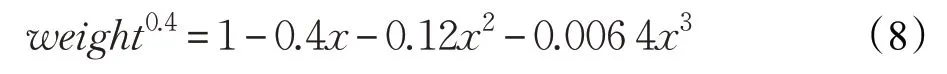
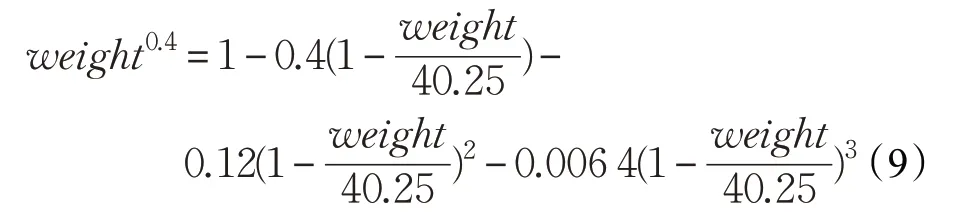
最后,利用乘法的分配率和结合律,将公式(9)进行化简,这样的目的是减少乘法运算和加法运算。用A、B、C分别代表公式的几个常数,最终,公式化简成:
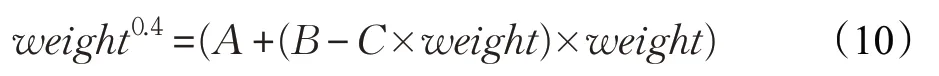
在x的取值方面,如计算[40~40.5]之间的数时,x对应于,当计算[45~45.5]之间的数时x对应于。
图5 显示优化前和优化后神经元的膜电位,图5 可以看出,优化前与优化后神经元膜电位随着时间的变化并无明显改变,优化前与优化后神经元的膜电位已经重合,优化后与优化前误差极小。

图5 优化前与优化后神经元膜电位
将使用泰勒优化后所损耗的FPGA 资源与未优化情况下FPGA 资源损耗情况进行对比,如表1。其中,Block RAM 减少 100%,DSP 减少 93.9%,FF 减少92.4%,LUT 减少67.9%,时钟延迟减少56.1%。Block RAM 减少100%的原因是,常数A、B、C被HLS 使用FF+LUT 综合成了ROM 的形式,从而没有将数组存储在Block RAM上。

表1 使用泰勒展开式优化后幂函数资源占用
3.2.2 指数优化
STDP 学习算法除了幂函数运算,还包括指数运算。所包含的指数运算如式(11):
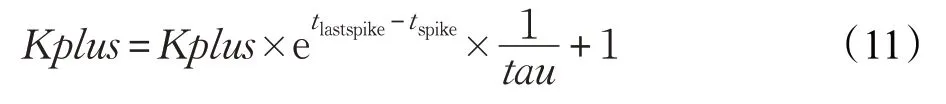
tau为常数,对于tlastspike-tspike,因为仿真精度是0.1(对于仿真精度为1时同样适用),所以tlastspike-tspike的结果只能是I.(0,1,2,3,4,5,6,7,8,9) ,其中I是整数。通过STDP对脉冲时间存储的特性分析,tlastspike-tspike的取值范围在[-70,0]之间。而且每个数的取值之差为0.1,即可能取值数为700个。通过tlastspike-tspike之差的值乘以10,然后转换成整数的形式进行索引取值。表2显示了原指数运算和查找表计算指数运算所使用资源的对比。从表中可以看出,DSP、FF、LUT 分别减少100%、97.3%、83.1%的资源损耗,时钟延迟方面,减少84.6%的时钟延迟。

表2 使用查找表求解指数函数的资源占用
3.2.3 输入硬件架构设计
设计的FPGA 加速器架构为ARM+FPGA 的形式。ARM 运行NEST 仿真器的基本结构,如网络的创建、MPI 通信、脉冲数据收集、各进程之间的信息分配等。ARM 通过AXI-LITE 口控制FPGA 端的突触计算核,AXI-STREAM 协议由 4 个 DMA 控制器来实现,突触数据的传输通过4根HP口来传输数据。
对于计算时的数据,通过AXI-STREAM 的形式将数据传输。具体传输硬件架构如图6。
AXI-STREAM的最大数据位宽为1 024 bit,本设计采用的数据位宽为256 bit,4 个输入口组成1 024 bit。ZYNQ 7030 内存带宽为2.01 GB/s,本文设计的加速方案,每秒所需的数据带宽为1.9 GB/s,在数据传输方面,并没有成为整个设计的瓶颈。
3.2.4 加速器整体架构设计
为了节约FPGA资源和提高吞吐率,整个设计采用上层流水+底层并行的设计方式。单个突触的STDP学习算法加速方案如图7。

图6 运行阶段数据传输硬件架构
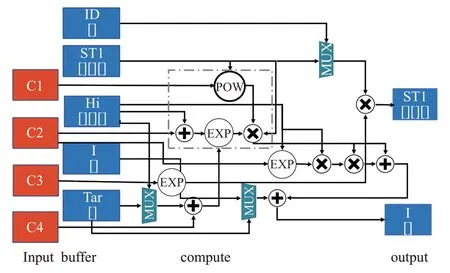
图7 突触更新硬件架构
单个突触的加速方案并没有最大化利用FPGA 资源。对于单个时间片上的NEST仿真,如果为全链接,则突触的STDP算法需要计算的总数为Spikes×NeuronE,NeuronE代表兴奋性神经元总个数。突触总数由外部输入决定。由于每次更行10个STDP型突触,在突触总数未知的情况下设计的上层流水采用向上取整的方式,如公式(12):

X代表需要计算的突触总数,Y代表每次并行计算的个数,整体架构的流水设计如图8。
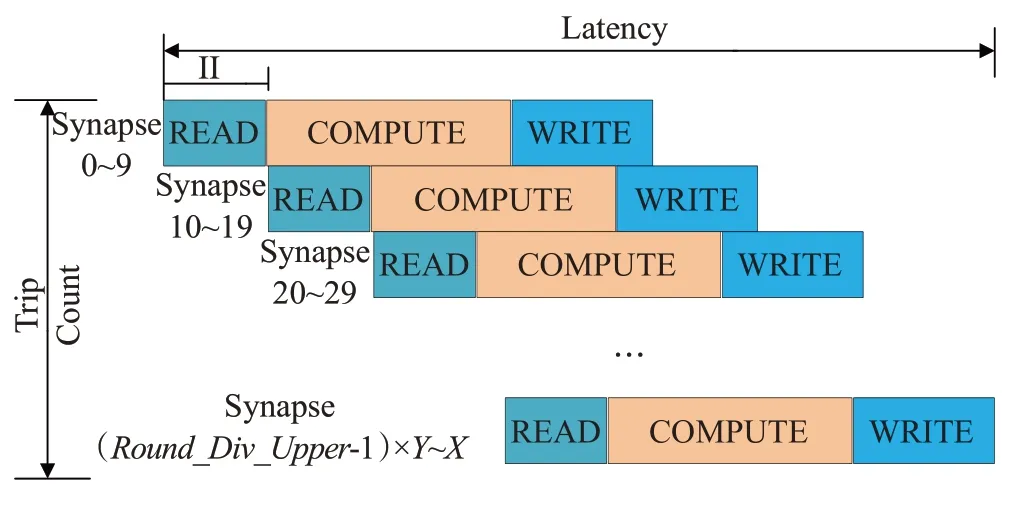
图8 突触计算的流水线设计
图8 中分为读取数据模块、计算模块、写回模块三个部分,整个流水线的总时间由以下公式计算:

其中,Latencytotal为所需要的总时钟,Roun_Div_Upper为Trip count 次数。II(Initiation Interval)为初始化间隔,IL(Iteration Latency)为迭代延迟,即R+C+W一次所需要的总时钟周期。
3.3 支持NEST仿真器集群的FPGA硬件架构设计
如图9 所示,在集群的硬件架构设计中,对于每个计算节点,NEST 仿真器将神经元和突触分配到每个节点并记录神经元之间的连接关系。当进行集群仿真时,每个节点计算每个节点的神经元和突触。每个节点,ARM端负责任务的分配和系统的运行,FPGA端负责对突触的计算。在进行仿真之前,NEST 会将神经元和突触平均分配到每个节点,每个计算节点计算任务不同且无主从关系,当一轮更新完成后,节点之间使用MPI 通过以太网通信。得益于NEST 仿真工具本身就支持MPI,在将 NEST 移植到 ZYNQ 集群上时,NEST 顶层的工作方式没有改变,只是将底层计算部分移植到了FPGA。所以NEST仿真器本身的支持节点规模可调的优点尚在。在仿真之前,可以根据所要仿真的规模,选择相对应的节点数量。因为神经元和突触是平均分配到每个计算节点,在运行大规模任务时,只要所需运行内存未超过ZYNQ内存大小,仿真时节点的规模可以任意调整。

图9 支持NEST的FPGA集群硬件架构
4 实验和分析
4.1 实验环境
NEST 2.14.0、Xilinx Vivado 2018.3、Xilinx Vivado HLS 2018.3,实验平台如表3。
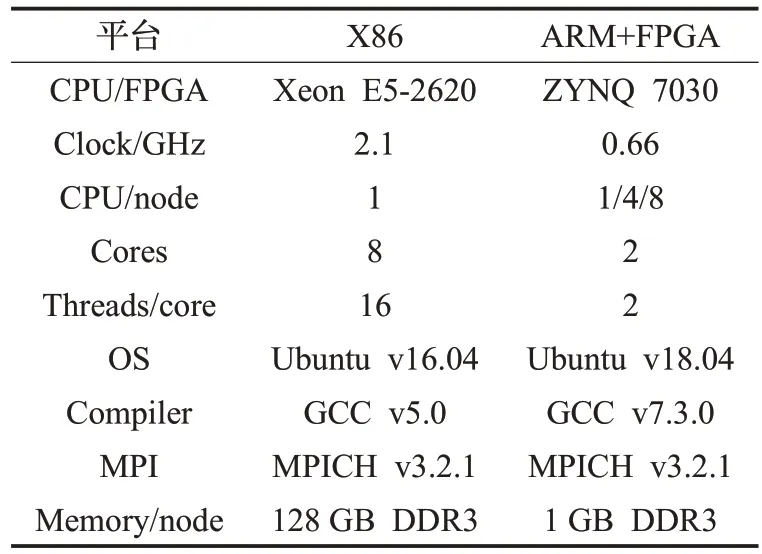
表3 两种平台的环境参数
因目前暂未有适合的X86+FPGA实验平台,这里只选择X86、ARM、ARM+FPGA 三种平台,下一步将与更多不同特点的平台进行比较。
4.2 测试集
HPC BenchMark 是NEST 官方推出的衡量系统性能的基准测试。目前,已经在多个平台或环境下使用[23,25]。网络中的神经元由兴奋性和抑制性神经元组成,组成比例为4∶1。突触使用STDP 型突触。时间步长为0.1 ms,突触延时为1.5 ms。模拟250+50 ms 生物大脑的活动。测试集中的神经元数量可调,调整的幅度为11 250的倍数。
4.3 FPGA资源利用情况
单节点ZYNQ 7030上FPGA资源损耗情况如表4。
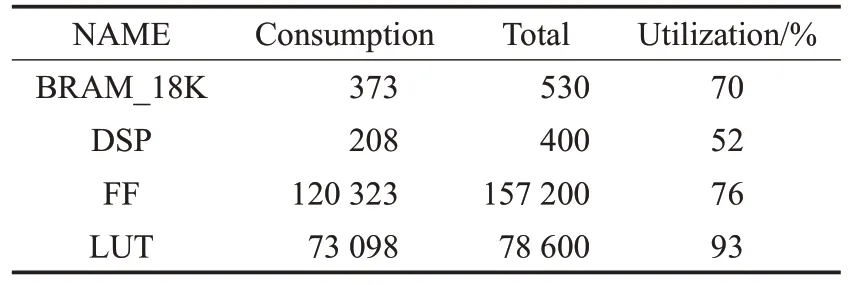
表4 单节点FPGA资源损耗
4.4 性能评估
本文实现基于ZYNQ 7030集群的类脑计算加速器的设计。实验分为三种运行环境,分别是Xeon E5-2620、ARM A9、ARM A9+FPGA。为了体现仿真平台的可拓展性,将HPC BenchMark例子神经元规模调整为1 125、6 750、11 250 三种,分别对应于单节点、4 节点和 8 节点。由于篇幅有限,在性能和能效对比时,只选取单节点和8节点与Xeon E5-2620进行比较。
如表5 所示,与其他仿真架构相比,单节点ARM+FPGA 异 构 平 台 性 能 是 ARM-A9 的 61.79 倍 ,Xeon E5-2620 的4.1 倍。能效比方面,能效是Xeon E5-2620的115倍,是ARM A9的55.5倍。
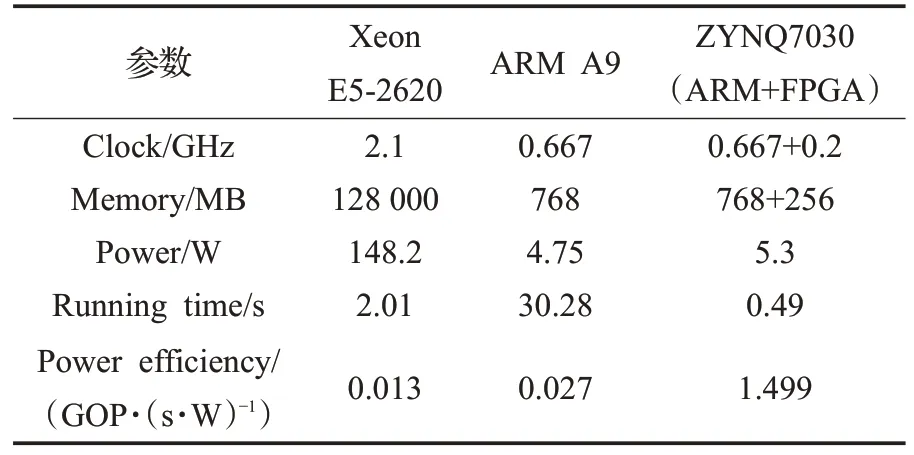
表5 各节点性能对比
8节点和E5-2620仿真11 250个神经元的数据如表6。
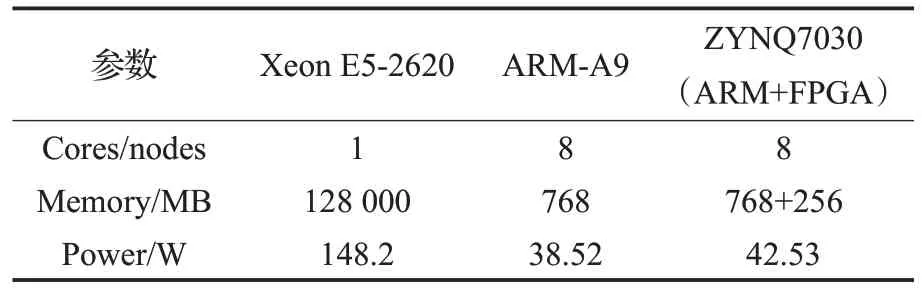
表6 FPGA集群和纯CPU参数
图10 为仿真11 250 个神经元生成的结果图对比,从图分析,两者结果相同。图10(a)为加速前的脉冲发射率和脉冲发射时间图,图10(b)为加速后的图。

图10 CPU端结果与集群结果对比
三种平台运行11 250个神经元,8 100万个STDP型突触的能效和运行时间如图11,突触部分并行计算,对整个系统的仿真时间减少作用明显。而且,相比于未经加速的ARM-A9集群,CPU相比于8节点的ARM-A9提升并不明显。因为脉冲神经网络的仿真,神经元和突触的参数较多,造成对内存的频繁访问。可见,单纯地提升单节点的性能并不是较好的解决方案,而是需要以集群的方式,增加访问内存的并行度。最终,8节点FPGA集群仿真时间为4.925 s,性能是Xeon E5-2620 的14.7倍,是8个ARM A9的22.68倍,性能功耗比方面,是E5-2620的51.6倍,是8节点ARM A9的20.6倍。
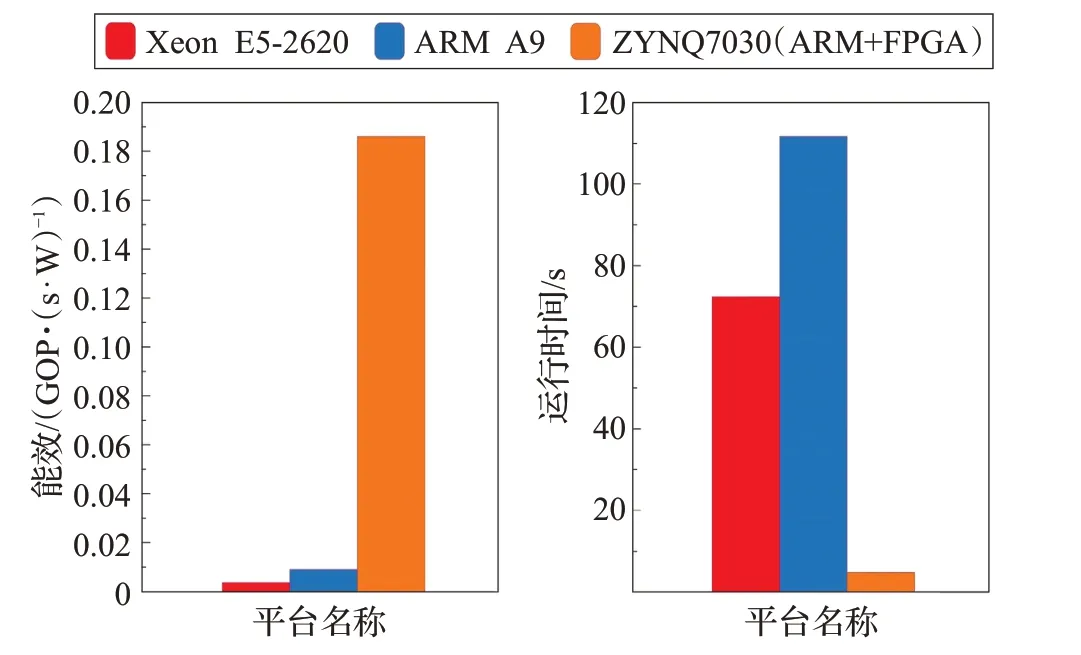
图11 三种平台对比
5 结语
本文设计并实现了突触的STDP 学习算法加速。通过软硬件协同的分布式方式,可以更方便地探索体系结构,本文的工作也说明了这种方式的优点。虽然节点数增加缩短了计算时间,通信时间也随之增加。且随着节点数增加,通信时间将会成为集群的瓶颈。先前对神经元部分的加速已经开源[26],后续也会将本文涉及的代码也开源。下一步的工作是扩展更大的规模,研究针对不同案例,提供不同的节点,以实现性能和功耗乃至通信的最佳平衡点。同时,节点数增加带来的数据同步等待,MPI通信时间变长也是亟需解决的问题。
猜你喜欢
数学物理学报(2022年3期)2022-05-25
中国计算机报(2020年9期)2020-03-25
数学物理学报(2019年5期)2019-11-29
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
铁路计算机应用(2018年4期)2018-05-03
中成药(2017年12期)2018-01-19
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
通信电源技术(2016年5期)2016-03-22
