
基于随机森林的高能物理数据放置策略
2020-11-10 07:10:20程振京程耀东李海波胡庆宝
计算机工程与应用 2020年21期
程振京 ,程耀东,3,陈 刚,汪 璐,李海波 ,胡庆宝
1.中国科学院 高能物理研究所,北京100049
2.中国科学院大学,北京100049
3.中国科学院 高能物理研究所 天府宇宙线研究中心,成都 610041
1 引言
随着高海拔宇宙线观测实验LHAASO[1]、大亚湾及江门中微子实验JUNO 等高能物理实验建成运行和陆续建成,数据累积规模不断扩大。超大规模的数据量对数据存储的性能和效率提出了更高的要求。高能物理领域一般使用EOS[2]、Lustre[3]等分布式集群文件系统,整合集群存储空间,数据分散存储在集群各个节点服务器上,对外提供统一的文件访问服务。
为了应对超大规模数据集的存储和降低系统构建成本、提供较好的访问性能,集群系统一般使用统一命名空间的分级存储架构,使用介质包括传统机械磁盘HDD 和固态硬盘SSD 等。在现有计算和存储架构上,大数据集在节点和存储设备之间的移动会与性能和用户体验产生诸多负面影响。因此,合理的数据放置策略对于提升集群存储系统效率非常重要。
海量数据治理的公认最佳实践是分类分级管理[4]。传统的高能物理文件放置方法是根据文件内容,对实验原始数据、蒙特卡洛模拟数据和重建数据进行简单分类。这种方式是基于规则的,非常依赖系统管理员和用户的先验知识[5]。文献[6]利用文件已创建时间与访问热度之间的相关性完成文件放置,保持各存储节点的负载均衡,但未考虑存储节点异构情况。文献[7]考虑节点负载、节点硬件性能和网络距离找到最佳文件副本放置节点,但未考虑文件的访问特点和访问场景。
本文在这些方法的基础上,提出了基于随机森林算法的高能物理文件放置策略。综合考虑访问场景和访问特点将文件划分为两类:交互式文件和批处理文件。相比于批处理文件,交互式文件随机访问占总体访问的比例较大,读写带宽和用户体验联系更加紧密。数据放置过程中优先将交互式文件放置在随机IO性能更好的固态硬盘SSD 中,同时考虑各存储设备当前负载情况。实验结果表明,使用此算法可以在不升级扩容现有存储节点和硬盘的情况下,优化数据放置和用户体验,发挥固态硬盘的性能优势,同时维持各节点的负载均衡。
2 相关工作
2.1 高能物理计算模式
典型的高能物理计算模式是从海量数据中挖掘出稀有事例。事例以文件形式存储在分布式存储系统中。基于上述特点,高能物理领域普遍采用集群文件系统以及计算和存储分离的模式,如图1所示。
海量实验数据存储在I/O服务器中,通过EOS分布式存储系统来管理,计算节点通过高速网络从I/O 服务器中获取数据[8]。中科院高能物理研究所计算中心开发了基于DNS负载均衡的前端登录系统[9],提供大规模用户登录服务,作为用户在计算和存储集群的单一入口点。用户在前端登录节点可以进行数据文件检查、计算程序调试、分析作业提交等交互式操作,存储系统的数据访问性能对于用户使用体验影响较大。后端计算集群通过作业调度系统统一调度和执行用户批处理计算作业。作业执行时间受任务类型、CPU 主频、I/O、网络等因素共同影响。作业完成后,用户将数据分析结果拷贝到个人计算机上做进一步分析,存储系统的数据访问性能对于用户使用体验影响相对较小。

图1 高能物理计算系统典型结构
2.2 EOS架构及数据放置策略
为了满足PB 级甚至EB 级的高能物理数据存储与分析压力,欧洲核子中心CERN 于2010 年开发了EOS文件存储系统。EOS 是一种基于xrootd 协议[10]框架实现的分布式并行文件系统,采用基于内存的元数据管理架构,节点支持条带化、文件多副本,可扩展性较好。它提供较高的聚合I/O 带宽,数据可以透明地在不同存储池间转储,特别适合高能物理高吞吐量的计算模式,和其他传统分布式文件系统相比具有很大优势。EOS 主要由元数据管理服务器(MGM)、消息队列(MQ)和文件存储服务器(FST)、客户端四部分组成,如图2所示。

图2 EOS典型架构
元数据服务器MGM管理文件系统的元数据,维护数据条带和文件位置等信息,并且提供命名空间、用户配额、用户认证等功能。文件存储服务器FST使用本地文件系统存储数据条带,响应客户端请求读出或写入数据。消息队列MQ负责元数据管理服务器MGM和文件存储服务器FST之间的信息同步,数据传输等。在EOS元数据服务器设计了存储池(storage group),存储池是一组存储服务器FST 和本地文件系统目录FS 的集合。可以为每个存储池配置不同的用户配额、负载均衡策略、数据冗余、副本和纠删码级别等。实际应用中通常根据硬件性能划分不同存储池,对用户提供透明、统一的文件访问入口。
EOS 中文件写入过程如图3 所示。客户端将请求发给元数据服务器,元数据服务器收到请求后首先检查用户权限和文件逻辑路径,如果成功则创建一条元数据记录,包括用户名uid、用户组名gid、创建时间、访问权限、逻辑路径、文件名等,但不会记录文件大小和文件在存储集群中的物理路径。客户端初始时先把文件写入本地缓存,完成后再借助放置策略确定数据在存储集群中的物理位置。最后客户端和相应存储服务器FST 建立连接,通过xrootd协议将文件或数据条带写入到各存储设备中。

图3 EOS文件写入过程
3 改进的数据放置策略
3.1 问题描述
EOS 默认的文件放置策略是随机选择一个当前活跃的存储池,通过GroupBalancer 组均衡程序选择一个存储服务器FST 和本地文件系统目录FS,但只考虑了存储空间利用率。高能物理实验交互式访问数据和批处理访问数据(见2.1节)混合放置在不同性能的存储设备上,可能导致某些存储设备比较空闲,造成存储节点负载不均衡。
3.2 策略基本思想
EOS 在数据放置过程中没有考虑高能物理数据访问特点和访问场景的差异。考虑EOS 使用的存储设备既包含前期部署的基于SATA协议的廉价HDD盘,又包含后期扩展的基于PCIE等协议的高性能SSD盘,将存储服务器FST和硬盘设备按照性能划分为快慢两种存储池。
改进的数据放置策略首先使用基于决策树的随机森林对文件访问场景进行识别。决策树[11]是一种无参数的有监督学习模型,本质上是从带有标签的训练数据集中学习分类和决策规则。决策树计算速度快,能处理训练数据的离散值和连续值,训练后的决策树能够生成在逻辑上解释的规则,缺点是容易过拟合,对输入噪声和异常值敏感,准确率不高。随机森林(Random Forest,RF)[12]是一种基于决策树的集成模型,包含多棵决策树的弱分类器,通过重采样从原始训练样本集N中有放回地抽取n个样本构成新的训练样本集,进而训练m棵决策树,输出的类别由个别树输出的类别的众数而定。因此随机森林有很好的抗噪声和泛化能力。本文使用sklearn[13]数据挖掘和分析工具,在随机森林训练和推理过程中利用多核CPU 的并行计算能力,对于大规模数据集计算速度比较快,适合对于性能要求较高的存储系统场景。
如图4 所示,在文件写入本地缓存后,采集文件后缀名、文件大小、文件目录、访问权限、创建时间、文件所属用户uid、用户组gid 等信息,经过预处理、特征提取、One-hot编码[14]作为随机森林的输入数据。随机森林模型保存了文件访问场景的识别规则。例如,同种访问场景中的高能物理实验数据往往文件格式一致,访问权限相似,甚至共同的父级目录等。

图4 基于随机森林的文件放置框架结构图
硬盘性能和IO负载是影响存储节点数据写入和读出快慢的重要因素之一。随机森林根据输入将文件识别为交互式数据或批处理数据,根据系统管理员事先定义的规则,分别存储在快速存储池和慢速存储池中。存储池的划分标准主要考虑硬盘IOPS和吞吐量[15]。同时本文定义了IO 负载指标来衡量存储设备的负载情况。在存储池内部选择FST和硬盘时,综合考虑所有服务器和硬盘的当前负载。负载指标可以用以下公式来表示:
其中,avgqu表示服务器平均I/O队列长度;svctm表示服务器平均每次I/O 请求的服务时间;util表示每个硬盘用于I/O操作时间的百分比;iowait表示CPU等待I/O请求时间的百分比。Linux中的top命令和iostat命令[16]主要用于监控节点系统设备的I/O 负载情况,以时间段为单位提供了上述硬盘负载指标。改进的策略模型对同一存储池内所有服务器和硬盘的负载进行计算,选取负载最低的存储位置。
3.3 算法描述
算法思想:针对高能物理计算和存储模式,在文件创建时,从本地客户端缓存写入到集群存储系统之前,根据文件元数据特征,识别为交互式访问文件或批处理访问文件,分别选择合适的数据放置位置,提升数据访问效率和用户体验。
输入:文件属性信息,各节点和存储设备空间利用率、负载指标等
输出:可以放置文件的FST节点和硬盘
伪代码如下:
1.while(客户端发出数据提交至存储系统的请求){
2.i(f在EOS中分离了快速和慢速存储池){
3.提取新创建文件元数据特征,包括文件名后缀、文件大小、文件路径(各级目录)、访问权限、创建时间、文件所属用户uid、用户组gid等
4.if(已训练随机森林模型){
5.文件元数据特征输入随机森林模型进行推理
6.对文件进行分类,并转至步骤10
}
7.else{
8.根据用户使用场景不同标记训练数据
9.离线训练随机森林模型,并转至步骤4
}
10.根据文件类别选择快速或慢速存储池
11.统计节点FST 空间利用率以及集群平均空间利用率
12.从步骤11 中挑选空间利用率小于集群平均值的FST节点,计算节点下各存储设备的IO负载,挑选负载最低的存储设备作为文件存储位置。算法结束
}
13.else{
14.使用EOS原有数据放置策略,随机选择一个可用存储池,根据存储空间利用率选择一个节点和硬盘存储设备。算法结束
}
}
4 实验结果及分析
4.1 实验环境
本文以中科院高能物理所部署的分布式集群存储系统EOS 0.4.31[17]为基础,重写了元数据服务器MGM中Scheduler 类,该类负责将新创建的文件从客户端缓存传输至存储集群,默认随机选择一个可用存储池并调用GroupBalancer类,调用Strategy类选择FST节点。继承Strategy 类并重载了其中的FilePlacement 方法,增加了使用随机森林推理文件类型的PredictFileCategory方法,同时增加了GetServerLoad和ChooseDisk方法,计算服务器和硬盘IO负载,选择一个当前时间段(10 min)内负载最低的存储节点和硬盘。
实验环境配置如下:EOS的MGM元数据管理器操作系统选用centos7.4,通过虚拟机构建了四个FST文件存储服务器节点,根据硬盘介质种类分别定义了快速和慢速两个存储池。fst01 和fst02 节点位于快速存储池,分别配有两块240 GB固态硬盘SSD(SSD01-04)。fst03和fst04 节点位于慢速存储池,分别配有两块2 TB 机械硬盘HDD(HDD01-04)。
4.2 实验结果分析
在算法验证中,以位于四川稻城的高海拔宇宙线观测实验LHAASO为例,针对2019年1月1日至2019年2月1日这一个月内新创建的565 254个数据样本文件作为训练集。并根据文件创建后,数据访问请求的主要来源(前端登录节点或计算节点)标注不同访问场景,包含交互式样本文件80 135 个和批处理样本文件485 099个,离线训练随机森林模型。文件大小介于十几KB和GB之间。在测试中采集2019年2月2日这一天内新创建的19 149个实验数据文件样本作为测试集,其中交互式文件样本2 731 个,批处理文件样本16 418 个。本文首先验证随机森林模型对高能物理实验中产生的交互式访问的数据和批处理访问的数据分类和识别的准确率,如图5所示。

图5 文件类别识别结果
测试中分别使用了RF1(单棵决策树)、RF7(集成7棵决策树的随机森林)、RF15、RF31、RF63、XGBoost(eXtreme Gradient Boosting)极端梯度提升树、GBDT(Gradient Boosting Decision Tree)梯度下降树、SVM支持向量机等模型。使用随机森林对文件类别识别准确率最好能达到84%以上,超过了XGBoost、GBDT、SVM等机器学习分类模型。本文假设初始时各存储节点都处于空载状态,硬盘空间使用也是从0开始。数据分布分别如图6所示。
使用EOS 原有放置策略(图6(a)),LHAASO 交互式访问的物理数据和批处理访问的物理数据混合存储在所有节点,固态硬盘SSD 和机械硬盘HDD 盘上数据分布几乎无差异。使用改进的放置策略(图6(b)),交互式访问的数据集中存储在fst01、fst02 节点以及挂载的固态硬盘SSD上,批处理访问的数据集中存储在fst03、fst04节点以及挂载的机械硬盘HDD上。
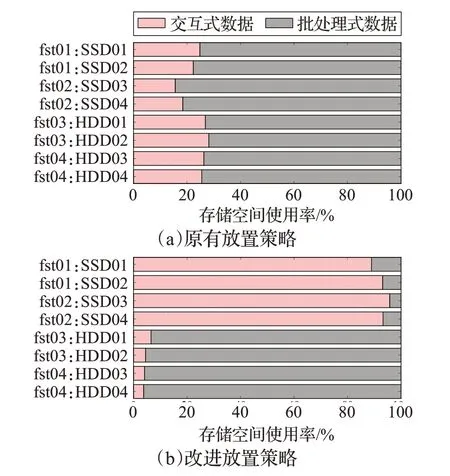
图6 原有策略和改进策略下数据在存储节点的分布
数据放置完成后集群存储节点和硬盘空间使用率如图7所示,可以看到,相比原有放置策略,改进放置策略提升了固态硬盘存储池对于交互数据的空间使用率。由于固态硬盘不需要寻道,随机读写速度快,能够极大提升交互式数据操作效率和用户使用体验。改进放置策略同时保证了同一个存储池内部下各硬盘的负载均衡。

图7 原有策略和改进策略下集群空间使用率
5 结束语
高能物理一般使用分布式集群存储系统来存放实验产生的海量物理数据。传统数据放置策略没有考虑用户不同访问场景,也没有考虑同时包含固态硬盘和机械硬盘的异构存储环境。针对上述问题,本文利用随机森林模型提出了一种改进的数据放置策略,提取文件大小、文件路径、权限、用户id 等多个维度的数据原始特征,对文件创建后的读写访问场景进行预测和识别,分别选取适合放置的存储池和存储节点、硬盘。实验结果表明,改进的放置策略将交互式访问数据放置在固态硬盘存储池,批处理访问数据放置在机械硬盘存储池,能够提升用户交互式访问体验,发挥固态硬盘速度快和机械硬盘容量大的优势。目前以LHAASO为代表的高能物理实验已积累超过8 200 万个样本文件,下一步的工作是在更大规模的样本文件集中验证算法的性能和有效性。同时在放置策略中考虑硬盘磨损程度和寿命,以减少数据放置时间和降低数据风险。
猜你喜欢
农业大数据学报(2024年2期)2024-12-01 00:00:00
科技资讯(2024年24期)2024-02-09 00:00:00
科学文化评论(2022年1期)2022-06-27 13:53:48
家庭影院技术(2020年7期)2020-08-24 08:18:10
家庭影院技术(2020年1期)2020-06-24 05:59:20
西部广播电视(2015年2期)2016-01-15 02:05:40
电力工程技术(2014年5期)2014-03-20 14:19:36
计算机应用文摘(2009年15期)2009-04-29 02:58:20
计算机应用文摘(2009年17期)2009-04-29 00:44:03
物理(2008年8期)2008-08-25 10:08:06
