
基于模糊理论的大学生体质健康分类与综合评价分级研究
2020-11-10 04:20王军
商丘师范学院学报 2020年12期
王 军
(安徽财贸职业学院 公共教学部,安徽 合肥 230601)
大学生是我国社会经济发展的主力军,大学生拥有健康的体质是社会可持续发展的基本条件.经调查研究我国大学生的体质健康状况的总体情况不容乐观,大学生的身体素质呈缓慢下降的趋势.如何改变大学生体质健康的下降趋势,进一步增强体质,增进大学生的身体健康已是迫切需要解决的问题.
目前广大学者对学生的体质健康现状、学生体质健康评价、学生体质健康测试进行了大量的研究,并且针对各地、各区域高校学生体质健康的研究较多.但是这些研究大部分都是简单的统计比较和数据处理,文献[1-2]提出了影响大学生体质测试成绩的因素剖析,给出了影响体质测试成绩的因素体系;文献[3-6]提出了各个国家地区的大学生体质测试成绩分析,给出了数据的简单比较分析;文献[7] 提出一种基于因子分析的大学生体质测试成绩的影响因素研究;文献[8-9]中给出了高等学校中学生体测数据分析,给出了简单的比较分析方法.有些模型也只是停留在理论上,没有根据事实存在的数据进行处理,也没取得很好的效果,更谈不上帮助教师及学生更好地了解学生的体质状态,选择锻炼方法,提高大学生健康质量.
为此本文通过适当的数学模型深度挖掘体测数据的所隐藏的信息,建立具有代表性、科学性,又有实用性、可操作性的指标体系,分析大学生体质健康的类别和综合评价级别,提供操作简单的评估方法,对于科学地评价与监测大学生的体质健康状况和为学生提供适当的锻炼方法具有非常重要的现实意义.
1 数据来源与指标体系构建
1.1 数据来源与处理
研究所用数据来自于合肥市5所同类型高校大学生体测数据,本文采取整群抽样方法,从2011-2018级身体健康、无重大疾病的在校学生中拟抽取10000 人,男女分级,剔除无效数据,以此10000名学生作为样本,在此基础上展开实证分析.
选取的样本数据依据《国家学生体质健康标准》对身高、体重、握力、肺活量、立定跳远、速度等指标量化评分,本研究是在量化评分的基础上做定量分析.
1.2 体测数据评价指标构建
1.2.1 构建多层次结构的评价指标体系
体质健康测试成绩评价体系的构架关键在于如何设计评价指标体系,其首要问题是指标设计有客观的标准可以度量.从考察大学生体质健康测试成绩的全面性,根据《大学生体质健康标准》以及指标设定的针对性、科学性和合理性原则,参照国内院校大学生体质健康测试成绩测评体系建立多层次结构的评价指标体系,具体内容见表1.

表1 大学生体质健康测试成绩评价指标体系
2 大学生体质健康综合评价分级分析
2.1 模型指标与权重的确定
模型中评价指标的确定是大学生体质健康综合评价的关键,选择的变量不同,最终预测的效果也自然各异.依据《国家学生体质健康标准》,其指标的确定由学生体质综合评价研究小组推出的,具有一定权威性与科学性,对最终模型都是有显著贡献的.因此,从身体形态发育水平、生理机能水平、身体素质与运动能力发展水平3个方面选取了身高、体重、握力、肺活量、立定跳远、速度6项指标,确定为构建模型的评价指标.由于各个评价指标影响不同,故权重分配尤为重要,分配权重系数本文采用二元对比排序法和专家调查法相结合的方法确定,结合实时数据,确定权重真实反映大学生的体质状况.
2.2 综合评价分级研究
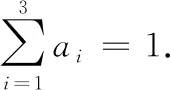
2.3 分析与计算
现结合模糊综合评价分级模型,对某一学生的体质健康测试成绩进行综合评价分级,其中权重的确定是采用专家调查法得到A=(0.24,0.35,0.41),A1=(0.29,0.30,0.41),A2=(0.55,0.45),A3=(0.47,0.53).其评价结果为:
一级指标的评价向量:

计算综合评价结果以及模糊综合评价值:

根据评价分级原则,B中最大隶属度为0.5084,超过0.5,说明其成绩等级属于“优秀”级别.其模糊综合评价值为
(0.5084,0.2363,0.1579,0.1047)·(100,85,70,30)T=85.1116
因此,该学生体测成绩的模糊综合评价值为85.1116,属于“优秀”级别.
3 基于遗传—模糊C均值算法的大学生体质健康分类分析
3.1 遗传—模糊C均值算法
模糊C均值聚类算法作为无监督机器学习的主要技术之一,是用模糊理论对重要数据分析和建模的方法,建立了样本类属的不确定性描述,能比较客观地反映现实世界,它通过优化目标函数得到每个样本点对所有类中心的隶属度,从而决定样本点的类属以达到自动对样本数据进行分类的目的.模糊C均值算法的步骤如下:

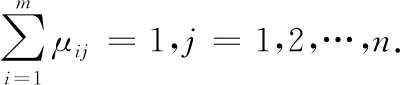
模糊C均值聚类算法是一个逐步迭代来完成的.但传统的模糊C均值聚类算法采用基于高斯最小二乘法的数值优化方法,需要函数的导数信息,容易出现不收敛、局部极小点问题,而遗传算法原理本身可保证实现全局最优逼近,可避免收敛到局部最优点上,从而具有良好的收敛性、内在的隐并行性和很强的全局寻优能力,且不依赖于目标函数的梯度信息,克服了基于梯度的下降法的一些缺点.遗传算法的基本操作主要包括:编码、生成初始种群、适应度函数、选择、交叉、变异.基于遗传算法的模糊C均值聚类算法的步骤:
1、对原始数据进行标准化;
2、计算初始指标权重;
3、将数据进行编码,选择方式简单、易于理解的二进制编码;
4、利用遗传算法中选择、交叉和变异算子进行运算;
5、利用终止条件去确定聚类中心的个数m和m个聚类中心点的坐标;
6、计算变化后的模糊分类矩阵;
7、计算变化后的指标权重;

3.2 实验结果分析与对比
利用SPSS软件对10000名学生样本进行数据处理,采取一般的K均值聚类算法得到表2中的初始聚类中心和表3最终聚类中心:

表2 10000名学生的体质测试成绩初始聚类中心

表3 10000名学生的体质测试成绩最终聚类中心
通过利用K均值聚类算法和SPSS得到表3中10000名学生的体质测试成绩的分类情况如下:

表4 10000名学生的体质测试成绩的分类情况分布表
针对10000名学生体测数据,用遗传—模糊C-均值聚类算法进行体测数据的分类,根据指标类型把学生体质分成若干类,并进行判别,这些类型由算法本身自动生成.在Matlab软件环境下数据处理结果,见表5和表6.

表5 10000名学生的体质测试成绩最终聚类中心

表6 10000名学生的体质测试成绩的分类情况分布表
根据表6的聚类结果可以看出,遗传—模糊C均值聚类算法相比较K均值聚类算法,迭代次数少,收敛速度快,得到的聚类结果较理想,聚类结果显示:2类肺活量欠缺,这一类大学生应该加强耐力的锻炼,可通过长跑、登山、骑自行车等方式进行锻炼;1类中肺活量和弹跳力不足,这一类大学生除了增加肺活量的锻炼以外,还应加强“负重深蹲”、蛙跳、俯卧背起,悬垂举腿等活动的练习;3类跑步等速度指标不足,这一类大学生应进行速度类锻炼,可通过蹲踞式起跑、高抬腿、快速起跳等方式锻炼速度素质;5类中力量指标明显低于其他指标,这一类大学生可以多做一些力量活动的练习,比如手臂运动、哑铃等等;而4类中指标比较均衡,4类中的数量占样本总数的38%左右,这一类中可以认为是优秀类型.根据不同类型的欠缺和不足项目,建立学生体质健康状况评价模块,用以帮助教师及学生更好地了解学生的体质状态,对每位学生提出合理建议,选择锻炼方法,提高学生健康质量.
4 结 语
针对近年来大学生的体质健康水平呈下降趋势,本研究以身高、体重、台阶指数、肺活量、立定跳远、握力6项指标作为模型构建的指标体系,运用模糊综合评价方法对样本进行了多元判别分析,构建了分级模型;采用基于遗传算法的模糊C均值聚类算法,在一定程度上避免了模糊C均值算法对初始值敏感和容易陷入局部最优解的缺陷,给出一种对大学生体质健康测试成绩模糊分类的方法,量化评价学生体质健康情况,根据每位学生身体素质得分对学生进行分类,了解每位学生体质发展状况,对提高不同学生的体质健康水平提出有效性的建议.
猜你喜欢
中老年保健(2022年2期)2022-08-24
中老年保健(2022年4期)2022-08-22
中老年保健(2022年6期)2022-08-19
海峡姐妹(2020年7期)2020-08-13
铁道通信信号(2019年6期)2019-10-08
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
