
一种基于hadoop平台下的矩阵优化Apriori改进算法
2020-11-10 05:59陈建敏
黄山学院学报 2020年5期
梅 俊,陈建敏
(黄山职业技术学院 工贸系,安徽 黄山245000)
随着互联网技术的日新月异,数据增长速度迅猛。如何从海量数据中找出有用信息适应需求尤为重要,而海量数据挖掘系统[1]能够更好地为相关应用提供决策支持,大部分挖掘系统依赖于分布式架构。Hadoop 框架[2]是由Apache 组织基金会开发的一个开源项目。Hadoop 与传统数据处理方式不同之处在于面对海量异构数据能够敏捷地处理,具有跨时代意义。其核心在于两大模块HDFS 与MapReduce。
在海量数据中寻找数据集之间隐藏的关系即为关联规则挖掘[3]。Agrawal 等人在1994 年提出了Apriori 算法,就是一种关联规则挖掘算法。其设计思想是通过扫描对比事务数据库,得到支持度大于最小支持度的所有频繁集,然后循环直到没有最大频繁项目集产生[4]。姚亮[5]针对Apriori不足,提出一种Apriori优化算法。对事务数据库进行优化,将其转化为0 或1 值的矩阵,将hash 算法应用于扫描数据库中,直接生成频繁2项集,为了减少连接比较次数,用共同前缀划分的方法,在每个子空间内连接生成候选K项集。黄剑等人[6]针对Apriori 算法的频繁生成时扫描事务数据库需要花费大量时间,将数据中项压缩成矩阵,通过对矩阵做运算,降低时间复杂度,并将改进算法应用于Hadoop平台中。
1 Hadoop平台
Hadoop 其核心在于两大模块HDFS[7]与MapReduce。HDFS(Hadoop Distributed File System)应用于大规模数据集存储及访问。而MapReduce 是以两个函数Map(映射)和Reduce(归约),负责对HDFS存储的数据进行分布式运算,需将HDFS上的大数据块分解成若干个数据块,然后独立执行,最终经过归约得出结果。MapReduce的体系结构如图1 所示,通过主节点Master 将输入文件划分成若干份,然后将程序复制到集群机器上,Mapper 读取Split 中的数据,并转换成键值对进行处理,将结果放进缓存中,Reducer 归约数据,执行完成后输出结果。

图1 MapReduce体系结构
2 改进的矩阵优化Apriori_MR算法
2.1 算法思想
针对经典Apriori算法存在不足,如Apriori算法会多次访问数据库,每次生成Lk频繁项目集需多次进行I/O 操作,且在自连接生成频繁项集过程中产生大量候选集,存在很多冗余项,且Apriori 算法只能单线程处理,不适合并行大数据处理。在文献[8-14]的基础上,本文基于Hadoop平台下,用0或1值来量化事务项,转化为矩阵,经二次优化后减少3-项及以上的候选项目集合时间及数量,提出一种Apriori改进算法Apriori_MR。
首先,遍历数据库D将其事务项进行量化,用值为0或1代表当前事务项是否存在,如Dij位置为1表示第i条事务项中存在Ij项,为0则表示不存在。将其值写入矩阵中,行列分别为每条事务、事务项。计算每列1 的个数即为各事务项的支持度,将大于最小支持度的项并入频繁1-项目集合L1。
再对矩阵进行第一次优化,由定理[15]可知,频繁2-项目集合L2中项不可能存在小于最小支持度事务项。因此,为了减少矩阵规模、去除生成候选集判断时间,删除小于最小支持度事务项所在的列。
经一次优化后,由1阶-频繁项目集L1自连接生成2 阶-候选项目集C2,扫描矩阵,统计C2项的值为1的个数,例如I1I2∈C2,如果事务S1里,I1I2皆为1即个数为2,统计计数1 次,如此,统计2 阶-候选项目集C2的各项支持度。将支持度大于最小支持度的2阶-候选项目集C2中项目并入频繁2-项目集合L2。
其次,对3阶-候选项目集C3进行二次优化。为了减少3-项及以上的候选项目集合,缩短自连接过程中判断时间,故统计各I 项在频繁2-项目集合L2中出现的次数,按照次数大小降序排序,次数多的项放在前面。由自连接产生候选项目集过程可知,频次高的项自连接生成候选项集判断少,成为频繁项集的可能性高,也会减少无用候选项目集产生。
由此反复直到生成的k项频繁集的个数少于k+1时,算法终止。
2.2 并行化设计
根据算法将各个任务流程分解如下。
1.将存储在HDFS 上输入数据分成n 个规模相当的数据块 inputsplit,格式为<tid,itemset>,每个 inputsplit分配到m个节点上。
2.生成1 阶频繁项集L1。扫描每个数据块<tid,itemset>,Map 阶段计算出各自分块的所有1-项候选集C1,Reduce阶段对所有Mapper结果进行合并即相同的项值累加,即为该项的总支持度,确定支持度不少于最小支持度的1 阶-频繁项目集合L1。构建向量矩阵,进行一次优化,删除支持度低于最小支持度的列,以减少矩阵规模。
3.根据1 阶频繁集L1生成2 阶候选项目集C2。将L1保存在HDFS,自连接生成2 阶候选项目集C2,分配到各个节点上。在节点上先求局部支持度,map 函数产生<项集,支持度>键值对,使用combine函数合并所有mapper 生成新的<项集,支持度>,将支持度大于最小支持度的键值对并入局部频繁2阶项集,其他节点步骤相同,合并所有局部频繁2阶项集,得出全局频繁2阶项集L2。
4.自连接成3 阶候选项目集C3。二次优化,先统计各项在频繁2 阶项集L2出现的次数,按从大到小顺序重新排序频繁2 阶项集L2,快速自连接生成C3候选项目集,减少判断时间。
5.重复第三步,统计支持度,确定全局频繁3阶项集L3。
6.重复第四步,自连接成4阶候选项目集C4,按照第四步的步骤排序,重复第五步步骤。当生成的k项频繁集的个数少于k+1时,算法终止。
2.3 算法实例
为了更好地说明Apriori_MR 算法,以下面的实例说明执行过程。
已知条件见表1。

表1 事务数据信息
每条事务中包含的事务项见表2。

表2 事务项包含项信息
1.量化事务。用0或1值简化项集表示,转化为矩阵。表3为事务量化表,行列分别为事务、项。
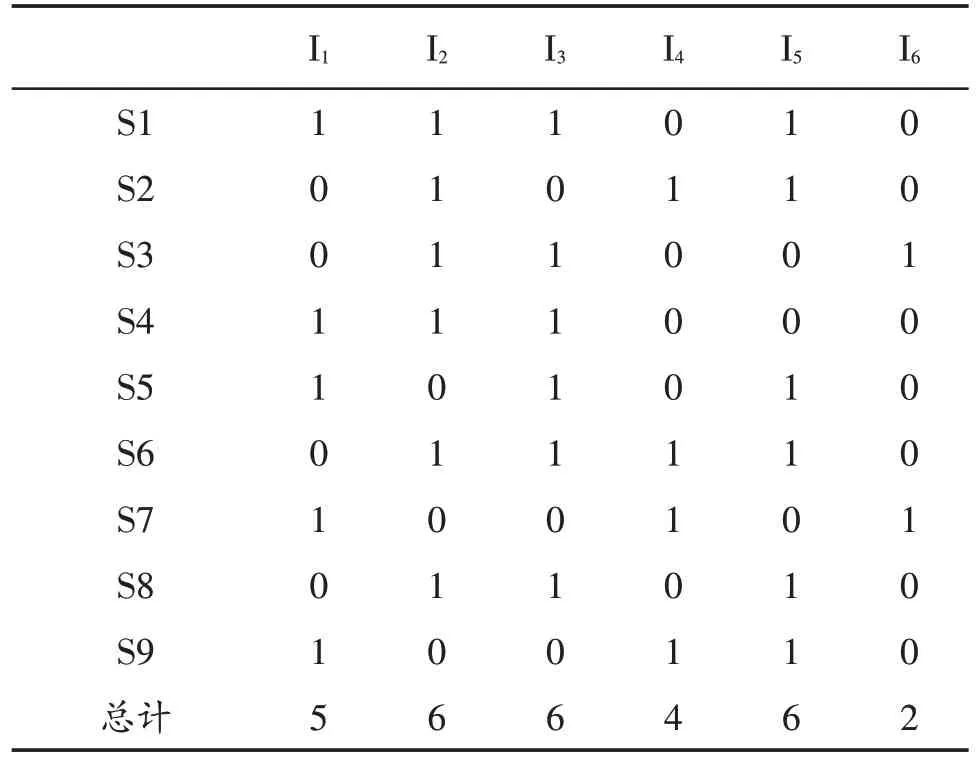
表3 事务量化表
2.优化矩阵,删除不可能是频繁集的事务项。由最后一列计数,可得出I6事务项支持度小于3,不可能是频繁集,删除I6项。
3.将事务矩阵划分成2 个数据块分配到2 个节点 上 D1={S1,S2,S3,S4},D2={S5,S6,S7,S8,S9},Map 计算出各自分块的所有1-项候选集C1,Reduce累加各自支持度,D1中{I1,I2,I3,I4,I5}支持度分别是{2,4,3,1,2},D2中{I1,I2,I3,I4,I5}支持度为{3,2,3,3,4},使用combine函数将所有mapper 函数的合并支持度为{5,6,6,4,6}与最小支持度相比较,得出频繁集L1={I1,I2,I3,I4,I5}。
4.自连接L1生成2阶候选项目集C2,生成2阶候选项目集C2={I1I2,I1I3,I1I4,I1I5,I2I3,I2I4,I2I5,I3I4,I3I5,I4I5},Map计算出各自分块的所有2-项候选集C2支持度,D1中C2支持度为{2,2,0,1,3,1,2,0,1,1},D2中C2支持度为{0,1,2,2,2,1,2,1,3,2},combine 函数合并总支持度为{2,3,2,3,5,2,4,1,4,3},最后得出L2={I1I3,I1I5,I2I3,I2I5,I3I5,I4I5}。
5.二次优化,优化三阶候选项目集。在L2频繁项集中对每个项出现的次数统计结果为{I1:2,I2:2,I3:3,I4:1,I5:4},并将 L2频繁项目集按照单项支持度降序排序{I5I3,I5I1,I5I2,I5I4,I3I1,I3I2},自连接快速生成C3候选项目集{I5I3I1,I5I3I2,I3I1I2},减少自连接次数。而未经处理的L2频繁项集自连接生成C3候选项目集为{I1I3I5,I1I3I2,I1I5I2,I1I5I4,I2I3I5,I2I4I5,I3I5I4},产生了许多无用候选项目集。由C3候选项目集{I5I3I1,I5I3I2,I3I1I2},同上步骤在两个节点中分别统计支持度,最后combine 函数合并得出3 阶候选项目集支持度{2,3,2},所以L3={I5I3I2}。
3 实验验证
3.1 平台搭建
Hadoop集群环境搭建见表4。

表4 Hadoop集群环境配置表
3.2 实验结果分析
实验采用FIMI Repository(Frequent Item-set Mining Implementations Repository)数据集Webdocs.data,在该数据的基础上,抽取其中100M,200M,300M,400M,500M。最小支持度为10%,15%,20%时,算法运行效率测试结果如图2所示。

图2 算法运行效率测试结果
实验结果显示,当支持度高时算法运行速度快,与支持度增加会造成频繁集合减少的算法规律一致,验证了Apriori_MR 算法的有效性。另一方面,当增加节点时,运行效率越高,证明算法的并行处理性能良好。
4 结束语
本文在深入研究Apriori算法和Hadoop平台后,提出一种Apriori_MR 算法。该算法采用了事务压缩矩阵,故不需要多次扫描事务数据库,此外,由于算法采用二次优化,减少候选项目集产生,缩短候选项目集生成预判时间,并将改进算法结合Hadoop框架进行并行化实现。实验证明,该算法的有效性与并行性良好,适用于大数据挖掘。
猜你喜欢
节能与环保(2022年7期)2022-11-09
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
河南水利年鉴(2020年0期)2020-06-09
通信技术(2019年11期)2019-12-04
计算机技术与发展(2019年11期)2019-11-18
计算机与数字工程(2018年10期)2018-10-23
计算机与数字工程(2017年2期)2017-03-02
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
