
基于近红外光谱的杏仁蛋白软糖理化指标快速无损检测
2020-11-09 04:16陈素彬
食品与机械 2020年10期
陈素彬
(南充职业技术学院,四川 南充 637131)
杏仁蛋白软糖是重要的食品和食品生产原料,可用作蛋糕内馅、糕面及富有色彩的糕点装饰,制作小杏仁蛋糕、杏仁饼及饼干。杏仁蛋白软糖富含蛋白质、单不饱和脂肪酸、维生素E、纤维和镁等物质,不仅能改善食品的风味、口感和外观,而且还具有很高的医用价值。
根据GB/T 20977—2007《糕点通则》之规定,杏仁蛋白软糖的理化指标应包括干燥失重(水分)、蛋白质、粗脂肪和总糖,其中总糖含量检验方法为其附录A给出的斐林氏容量法;水分含量按GB 5009.3—2016《食品安全国家标准 食品中水分的测定》的第一法测定。这些方法的优势为准确度高、重复性好、设备成本较低,适用于仲裁检验,但需用仪器设备和化学试剂较多,具有操作复杂、耗时长、污染环境等缺点[1],致其测定结果易受人为因素影响,不利于食品生产中的大样本快速检测。近年来,随着化学计量学方法的发展和仪器研制水平的提高,近红外光谱(Near infrared spectroscopy,NIRS)分析方法检测高效、操作简便、无化学污染、支持多成分同时测定等优势日益凸显,作为一种非破坏性的“瞬间分析”技术[2],被越来越多地应用于食品行业的各种定性和定量分析,但目前中国尚未见以NIRS法检测杏仁蛋白软糖组分的报道。
NIRS法是一种间接定量分析技术[3],在确保样品光谱和待测成分参考值准确性的情况下,其预测结果取决于所建定标模型的质量。在实际应用和相关研究中,通常采用随近红外光谱仪器附送的OPUS、TQ Analyst、QUANT等分析软件[4-5],以偏最小二乘法(Partial least squares,PLS)进行建模和预测。对于食品营养成分、品质指标检测,李路等[6]用PLS法和BP神经网络法建立了大米总糖、水分等成分的近红外检测模型,其决定系数(R2)均大于0.9、相对标准差均小于2.6%。陈冲等[7]建立了冬枣水分、糖分无损检测的PLS和主成分回归(Principal component regression,PCR)分析模型,其水分预测PLS模型的相关系数(R)为0.997 45、校正均方差(Root mean square error of calibration,RMSEC)为0.044 5、预测均方差(Root mean square error of prediction,RMSEP)为0.367,糖分预测PLS模型的相关系数(R)、RMSEC和RMSEP分别为0.960 78,0.853,1.64。何云啸等[8]建立了诺丽果粉在真空冷冻干燥过程中水分含量与红外光谱的定量模型,当水分含量在5.00%~9.00%时模型的R2为0.98、交互验证均方根误差(Root mean square error of cross validation,RMSECV)为0.26。贾柳君等[9]利用近红外光谱分析技术对葡萄酒的主要成分进行定量分析,其总糖预测模型的R2、RMSEP和相对分析误差(Residual predictive deviation,RPD)分别达到0.943 5,0.263 6,4.21。这些研究为应用NIRS分析技术进行食品营养指标检测提供了有益参考,但未充分运用化学计量学方法和软件技术优化模型性能,主要体现在:① 忽略了异常样本和不同的样本集划分结果对模型预测能力和稳健性的影响,未进行异常样本判断和样本集划分方法选择。② 根据谱图外观或待测成分对应的化学基团选择变量区间,建模波长较多,模型运算量大而运行效率较低;或用组合方法优选特征波长,增加了建模过程的复杂性。
1 材料与方法
1.1 材料与仪器
杏仁蛋白软糖:南充多家糕点企业;近红外光谱仪:NIRSystems 6500型,丹麦FOSS公司。其光源为钨卤灯,波长范围400~2 500 nm,检测器为硅(400~1 100 nm)和硫化铅(1 100~2 500 nm);取点间隔2 nm,扫描速度1.8次/s,扫描次数32,工作温度15~32 ℃。配有往复移动式样品池,以标准陶瓷片为参比。
1.2 样品采集与制备
按GB/T 20977—2007规定之方法和数量,在南充糕点企业采集杏仁蛋白软糖样品32个,用四分法缩减、混匀后分成4份,取其中2份为试验样品,分别用于水分、总糖含量参考值测定和光谱数据采集。试样装入广口瓶,保存在冰箱中。
1.3 待测成分含量参考值测定
1.3.1 水分 称取试样8 g(精确至0.000 1 g),按GB 5009.3—2016的第一法测定。
1.3.2 总糖 准确称取样品2.0 g,按GB/T 20977—2007附录A的斐林氏容量法测定。
1.4 NIRS定标模型的建立
1.4.1 样品近红外光谱采集 依次将试样装入样品杯,以近红外光谱仪扫描。设置波长范围450~2 448 nm、间隔2 nm,每个试样重复装样、扫描10次,取其平均值为样品光谱。
1.4.2 NIRS定标模型建立及其性能评价 以KS法将样品按2∶1划分为定标集和验证集。用定标集光谱数据和水分含量参考值建立PLS定标模型,并将验证集光谱数据代入该模型预测相应的样品水分含量;用同样方法建模、预测验证集样品的总糖含量。
(2)制定相应的优惠政策。如高速公路服务区旅游厕所建设减免收投资许可证、行政事业单位免收公厕拆迁建设管理费用等。
以校正决定系数(Rc2)、预测决定系数(Rp2)、RMSEC、RMSEP和RPD为评价指标,分析所得水分和总糖测定的NIRS定标模型性能。
1.5 NIRS定标模型的优化
1.5.1 异常样本剔除 以蒙特卡洛采样法(Monte Carlo sampling,MCS)从全部样本中抽取80%为校正集、其余为验证集,建立PLS模型进行预测,计算各样本的预测残差。重复该过程使全部样本被预测,计算各样本预测残差的均值(MEAN)和标准差(Standard deviation,STD),绘制全部样本预测残差的MEAN-STD分布图,图中位于均值和标准差较高区域的样本即为异常样本[10]。
1.5.2 光谱变换处理与样本集划分 以多种算法分别对定标集和验证集光谱数据进行变换处理,包括均值中心化(Mean centralization,MC)、萨维茨基—戈莱平滑(Savitzky-Golay smoothing,SG)、标准正态变量变换(Standard normal variable,SNV)、去趋势(De-trending,DT)和多元散射校正(Multiple scattering correction,MSC)以及基于MC的组合算法;同时分别以KS法和SPXY法按2∶1划分样本集,用变换处理后的光谱数据与相应待测成分参考值分别建立PLS模型预测水分和总糖含量,比较其性能指标以确定最优光谱预处理和样本集划分方案。
1.5.3 特征波长选取 用MCS法抽取80%样本构成校正集、其余为验证集,建立PLS模型进行预测,计算波长j对目标的贡献|bj|和权重wj,以指数递减函数计算波长点的保留率ri=ae-ki(a、k为常数,i为采样次数);去掉|bj|较小的波长点,用自适应重加权采样(Adaptive reweighted sampling,ARS)法由m×ri个波长点中得到样本优选子集(m为波长点数),取相应光谱数据建立PLS模型,计算其RMSECV。重复此过程200次,取最小RMSECV值对应的优选子集为特征波长。
1.5.4 优化模型建立与预测 从样本集中剔除异常样本,用选定方案进行数据预处理、划分样本集、选取特征波长光谱,得到优化的定标集和验证集,以PLS方法分别建模、预测水分和总糖含量。将所得预测结果与相应成分的参考值对比,计算其平均回收率,并通过配对样本t检验判断其差异性。
1.6 NIRS定标模型优化性能对比
1.7 软件工具
1.7.1 待测成分参考值测定 数据记录、结果计算和数据统计用Microsoft Excel 2010完成。
1.7.2 NIRS定标模型建立和优化 初始模型的建立、预测用The Unscrambler X 10.4完成,模型优化用MATLAB R2019a编程、作图实现。
1.7.3 样品光谱图形绘制 用OriginPro 2019b完成。
2 结果与分析
2.1 NIRS定标模型建立和预测
2.1.1 样品近红外光谱采集结果 32个样品的近红外光谱如图1所示。
从图1可知,所有杏仁蛋白软糖样品的光谱特征较为相似,谱线较分散、谱图较宽,表明各样品组成基本一致、其成分含量差异较明显;样本光谱在1 100,1 288,1 652,1 848 nm左右存在明显波谷,而在1 010,1 208,1 468,1 724,1 938 nm左右有较明显的波峰,这些波段区域含有较多特征光谱信息。同时还可看到,样品光谱谱带较宽,基线漂移和谱带重叠严重,尤其2 150~2 448 nm波段的光谱信噪比较低,故建模时应对原始光谱进行变换处理;谱图中有2条谱线的走势明显离群,疑其为异常样本,宜在建模时剔除。
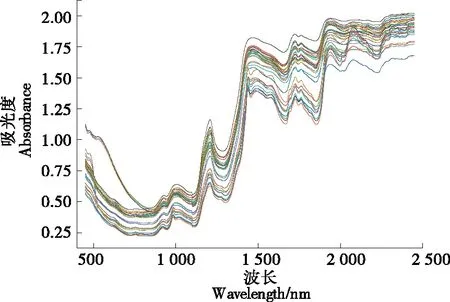
图1 样品近红外光谱
2.1.2 NIRS定标模型预测结果分析 用全部样本、全光谱、无预处理分别所建水分、总糖含量测定的NIRS定标模型预测结果如表1所示。
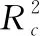
2.2 NIRS定标模型的优化
2.2.1 异常样本剔除结果分析 马氏距离法、主成分得分法、光谱残差检验法等传统方法判断异常样本,皆需根据经验设定阈值,且难以判断多个异常点。试验采用MCCV法,可根据光谱数据和待测成分之间的关系及异常值对模型稳健性的影响,同时筛选出两个方向的异常点,并以全部样本的预测残差MEAN-STD分布图直观地反映其整体分布情况,其结果如图2所示。
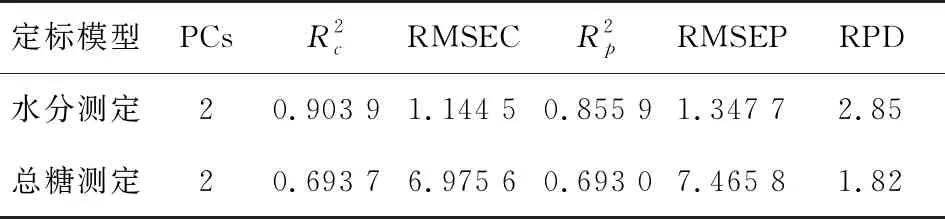
表1 NIRS定标模型预测结果
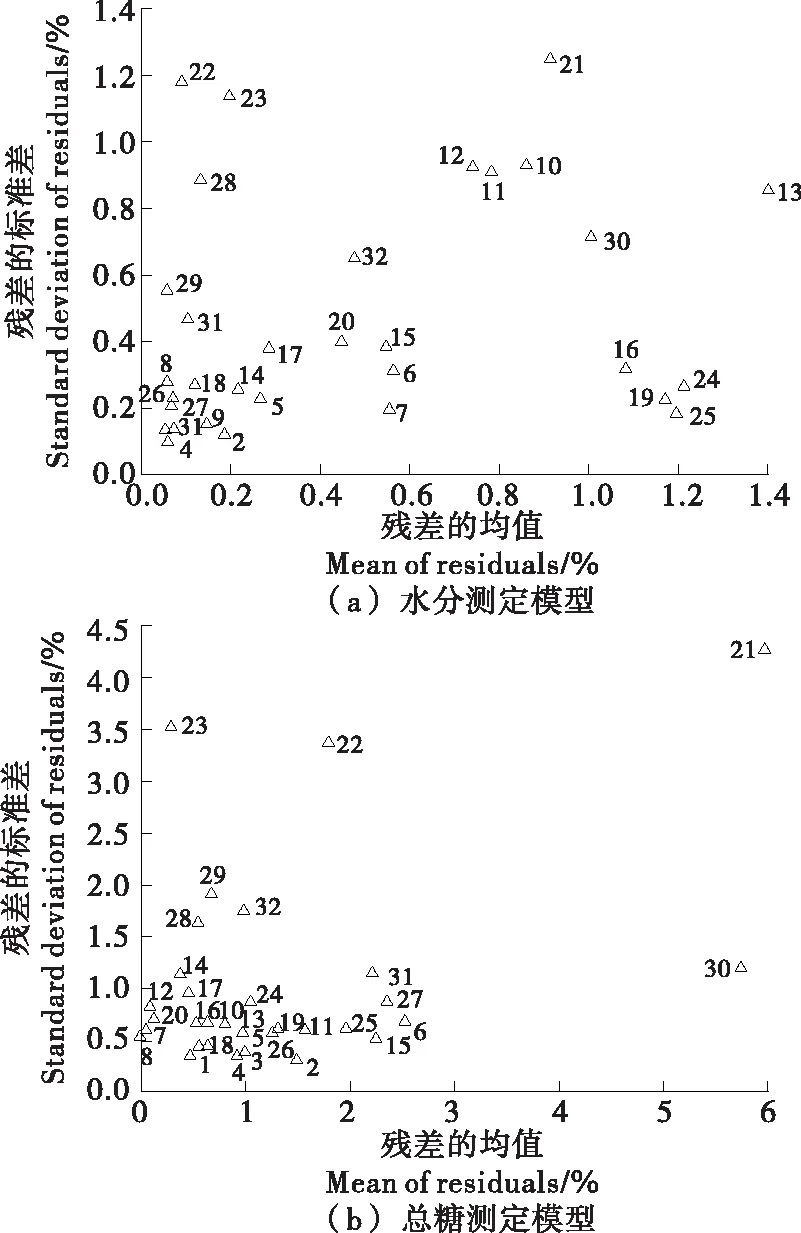
图2 全部样本预测残差MEAN-STD分布图
从图2(a)可看出,全部样本预测残差的均值和标准差分布较分散,其中位于高均值区域的样本依次为13、24、25和19号,位于高标准差区域的样本依次为21、22和23号,反映出在模型的多次运行中,这些样本的水分含量预测准确度或(和)稳定性与总体相差较大,剔除之将使所建模型的准确性和稳健性得到改善。因样本总数较少,实际建模时仅剔除预测残差均值和标准差都较大的13和21号样本即可;在图2(b)中,样本预测残差的均值和标准差分布较集中,位于高均值区域的样本为21和30号,位于高标准差区域的样本依次为21、23和22号,因此建模时宜剔除离群最远的21和30号样本。
2.2.2 光谱变换处理与样本集划分
(1) 样本集划分结果比较:在浓度梯度(Concentration gradient,CG)、随机(Random sampling,RS)、KS和SPXY等几种常用样本集划分方法中,KS法在实际检测和相关研究中采用最多;SPXY法则在计算样品间距时同时考虑了光谱和参考值变量,能有效覆盖多维向量空间,从而改善所建模型的预测能力。试验将30个正常样本分别用KS法和SPXY法按2∶1划分样本集,得定标集样本20个、验证集样本10个,其结果如表2 所示。
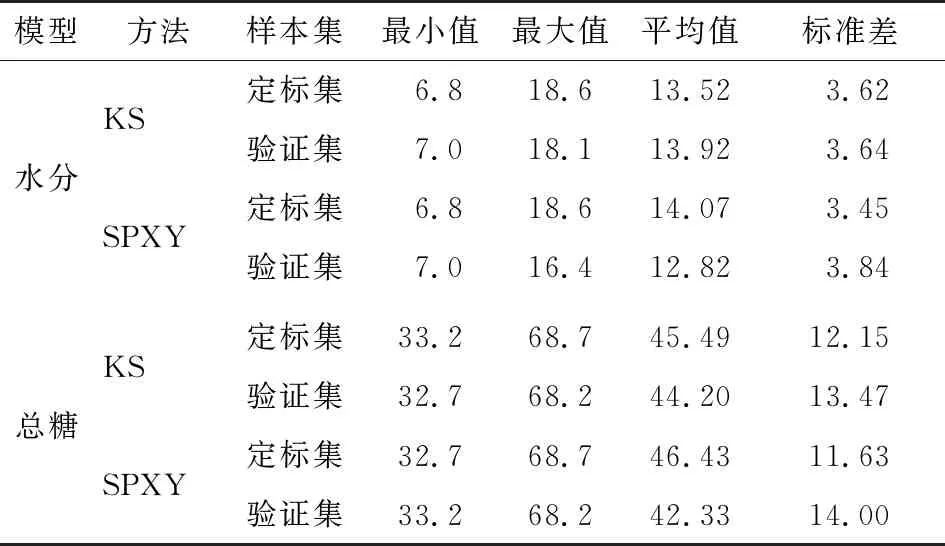
表2 两种方法划分样本集的结果
由表2可知,用KS法划分水分测定模型的样本集较好,所得定标集与验证集样本的水分含量区间分别为[6.8,18.6]、[7.0,18.1],前者完全涵盖了后者;其水分含量平均值(13.52,13.92)和标准差(3.62,3.64)都相差很小,表明定标集和验证集样本数据分布相似度高,适合于建立水分含量预测模型。
总糖测定模型则以SPXY法划分样本集较好,相应定标集和验证集样本的总糖含量区间分别为[32.7,68.7]、[33.2,68.2],前者亦完全涵盖后者;其验证集样本的总糖含量平均值小于定标集、标准差大于定标集,表明验证集样本数据分布于定标集数据区域内,且其较分散、多态性好,有利于建立一个预测能力强、泛化性能好的总糖测定模型。与之相比,KS法划分的定标集中未包含总糖含量值最小的样本,将对所建NIRS定标模型性能产生不利影响。
(2) 光谱变换处理结果比较:近红外光谱吸收较弱、重叠严重,且存在样品物理性状不均、光的散射及仪器噪声等不利因素影响,致使扫描所得原始光谱信息复杂、信噪比低,以之直接建模难以获得预期的结果。试验分别尝试了多种光谱变换处理算法,其相应PLS定标模型的预测结果如表3所示。
从方法原理的角度讲,MSC算法能有效消除样品颗粒大小及其分布不均产生的散射影响,增强光谱与数据之间的相关性;MC变换可增加样品光谱之间的差异,从而提高模型的稳健性和预测能力。就实际效果看,试验将二者组合应用于半固体状的杏仁蛋白软糖样品光谱预处理,取得了优于其他各种方法的效果。
2.2.3 建模波长选取结果分析 试验样品的原始NIRS光谱包括1 000个波长,其中存在大量冗余信息和共线性变量,势必增加建模的复杂性和计算量,影响模型的预测精度和运行速度,因此建模时需选取能充分反映待测成分信息的特征波长,以简化模型、提高其性能。在无信息变量消除法(UVE)、连续投影算法(SPA)及遗传算法(GA)等众多方法中,试验采用CARS法进行建模特征波长优选[11],所得结果如表4所示。
由表4可知,用CARS法结合PLS模型筛选后,水分定标模型保留了8个波长变量,仅占全波长的0.8%。其中4个集中在1 590~1 692 nm波段,正好位于以1 652 nm 为中心的波谷内;另外4个中有2个位于1 938 nm 处的波峰区域、1个位于1 468 nm处的波峰附近、1个位于1 848 nm处的波谷区域。显然,选出的8个波长与样品谱图的特征基本相符,相应的光谱数据能够表达杏仁蛋白软糖样品中水分的主要信息。
总糖定标模型选取15个波长变量,仅为全波长的1.5%。其中7个集中在1 550~1 566 nm波段,另外8个中有3个位于1 848 nm处的波谷区域、2个位于1 208 nm 处的波峰区域、2个位于2 094~2 098 nm波段、1个位于1 010 nm处的波峰区域。对照图1可知,所选波长全部位于信噪比较高、特征变化显著的谱区,即第一个波峰(1 010 nm)和最后一个波峰(1 938 nm)范围,相应的样品光谱数据所含总糖信息足以满足建模要求。
2.2.4 优化模型建立与预测结果分析 将前述各项优化成果综合应用,以PLS法所建样品水分和总糖含量的NIRS定标模型预测结果如表5所示。
由表5可知,得益于多项优化技术的综合应用,样品水分含量定标模型的预测残差为-0.4%~0.5%,其绝对值均小于0.5%;总糖含量定标模型的预测残差为-0.9%~1.0%,其绝对值均不大于1.0%。将预测值与参考值之比作为预测回收率,算得两个模型的平均回收率分别为99.5%,99.9%,表明其可用于预测杏仁蛋白软糖的相应成分含量。
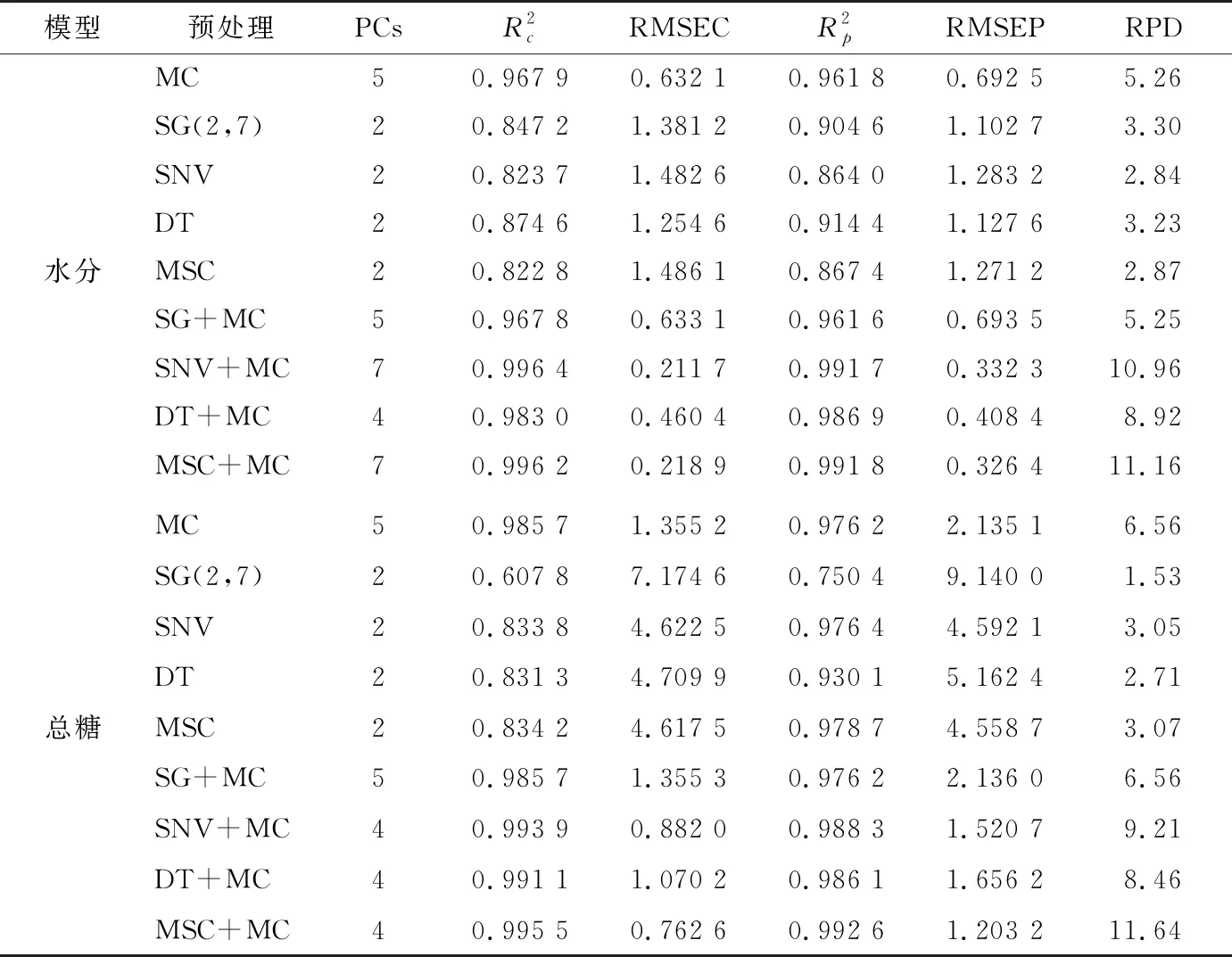
表3 各种预处理方法的建模预测结果

表4 NIRS定标模型特征波长选择结果

表5 优化的NIRS定标模型预测结果
分别将水分、总糖定标模型的预测值与参考值进行配对样本t检验,在设置置信水平95%的情况下,结果分别为P=0.83>0.05、P=0.84>0.05,说明95%概率下两组数据无显著性差异,两个模型可分别满足杏仁蛋白软糖水分、总糖含量快速准确测定的要求。
2.3 NIRS定标模型优化性能对比分析
从初始模型开始,到运用多项技术方法完成模型优化,各阶段分别所建杏仁蛋白软糖水分、总糖含量预测的NIRS定标模型性能对比如表6所示。

表6 NIRS定标模型优化性能对比
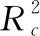
同时,由于建模波长变量大幅度缩减,大量非待测成分信息得以消除,使得优化模型的计算量显著降低,其运行速度也随之加快。在采用相同方法进行同类检测时,参照试验所选特征波长采集样品光谱,可极大节省其工作量。
3 结论

由此可见,试验所建杏仁蛋白软糖水分、总糖含量的NIRS定标模型均有较高的精度和运算速度,其性能指标优于同类试验模型,并达到国际谷物科技协会用于实际检测的标准,适用于杏仁蛋白软糖理化指标的快速检测。但因时间所限,试验采集样品数相对较少,以及未尝试非线性建模和更多波长选择方法,下一步将对此进行研究。
猜你喜欢
纺织标准与质量(2022年2期)2022-07-12
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
今日农业(2021年19期)2022-01-12
阅读(科学探秘)(2021年8期)2021-09-01
中国科学院大学学报(2019年1期)2019-01-21
雷达学报(2018年3期)2018-07-18
航天返回与遥感(2017年2期)2017-05-24
科技与创新(2016年22期)2017-03-30
科技视界(2016年20期)2016-09-29
长江蔬菜·学术版(2014年12期)2015-01-08
