
基于点云深度学习的3D目标检测
2020-11-05 05:05:38敖建锋苏泽锴刘传立李美妮
激光与红外 2020年10期
敖建锋,苏泽锴,刘传立,李美妮,朱 滨
(江西理工大学建筑与测绘工程学院,江西 赣州 341000)
1 引 言
激光雷达获取得到的点云数据具有精度高、鲁棒性强等特点,点云是一种表达形式简单、灵活多变的数据形式,在自动驾驶[1]、目标识别、三维重建[2]、城市规划和遥感测绘等方面有着广泛的应用。近年来,随着机器学习的发展,如何利用点云进行3D目标检测受到了人们的关注。与二维图像相比,点云可以更好地表现出地物的表面特征及距离信息,然而与基于图像的目标检测的快速发展形成鲜明的对比[3],由于点云本身的无序性、稀疏性等特点,在基于点云的目标检测准确度方面远不如图像目标检测,研究还存在着诸多难点亟待解决。卷积神经网络对于输入顺序是敏感的,而点云数据具有置换不变性,即以任意顺序输入点云都能表示同一物体。目前,利用点云数据进行深度学习主要有以下三种方法。多视角投影[4-5]是通过将点云转换为在多个角度下投影的图像,形成多张二维图像,最后将其输入到2D卷积神经网络进行特征的提取。这种方法借助了成熟的图像处理技术来解决难以直接输入点云的问题,但从三维点云到二维图像这一转换过程中,不可避免地会造成信息的丢失。另一种方法是在三维空间中划分规则的立方体,将点云数据栅格化转换为体素来解决点云无序性的问题,并将2D卷积神经网络拓展到3D卷积神经网络。但三维卷积随着空间复杂的增加和分辨率的提升计算量呈3次方的增长,这就需要对立方体的大小进行谨慎地选择。目前基于体素的方法[6-8]一般将立方体大小限制在30×30×30,相比图像的高分辨率,三维空间中的分辨率成为限制模型学习能力的瓶颈。前两种方法都是先将点云转换为其他形式,在进行目标检测中存在局限性,理想情况下是直接使用点云进行输入,保留信息的完整性,实现端到端的特征学习。斯坦福大学的QI提出了PointNet[9]模型有效地解决了这一问题,利用对称函数(最大池化)进行对称化操作处理点云,直接将点云输入神经网络中进行特征的提取,有效地解决了前两种方法信息丢失的缺点。避免了点云数据特点带来的局限性[10]。
因此本研究将采用对称函数的方法,利用直接处理原始的点云数据的Frustum-Pointnets模型[11]进行3D目标检测,避免了转换点云数据时的特征损失。并在该模型的基础上进行改进,提升了模型了性能,得到了很好的检测效果。
2 构建Frustum-Pointnets模型
本文采用Frustum-Pointnets模型,直接对原始点云进行处理并实现3D目标检测。Frustum-Pointnets模型基本框架如图1所示。
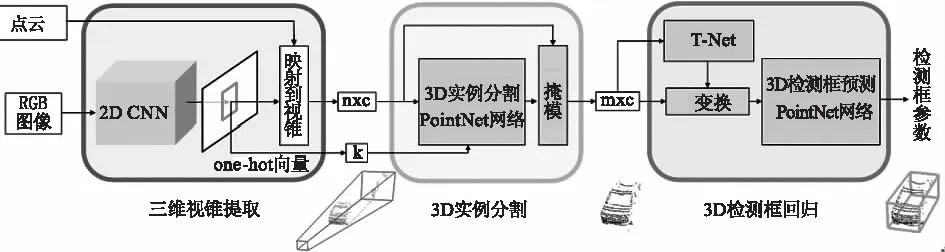
图1 Frustum-Pointnets模型框架
其中,n为视锥提取出来的点云数;m为分割出的点云数;c为点云的通道数;k为点云被分为k个类。模型共分为3个部分:三维视锥提取、3D实例分割、3D检测框回归。该模型结合了图像和点云的优点,先通过图像生成2D检测框并将其扩展到三维空间对目标点云进行检索,然后对区域内的点云利用Pointnet网络进行实例分割,最后估计目标点云的3D检测框。
2.1 三维视锥提取
由于大多数的三维传感器的数据分辨率尤其是实时3D激光雷达采集的点云相比图像的分辨率低很多,因此Frustum-Pointnets利用图像进行二维目标区域的定位,然后扩展到三维空间形成视锥,如图2所示。
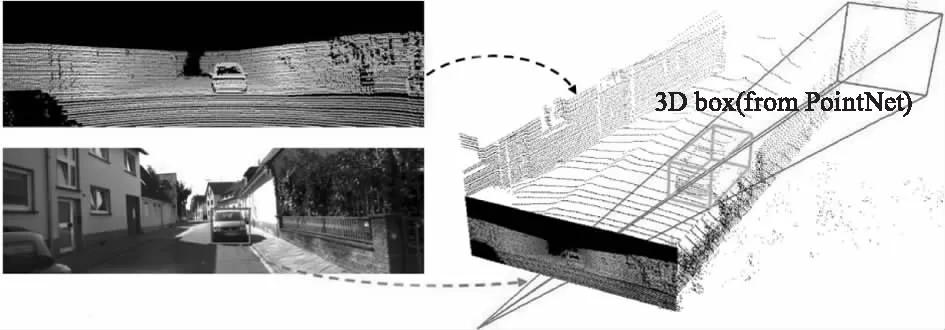
图2 三维视锥提取示意图
2D目标检测器是基于FPN模型[12],先在image-Net和COCO上预训练生成训练模型并根据KITTI数据集[13-14]进行微调,生成2D检测框,然后结合标定好的传感器内参和已知的相机投影矩阵,二维的检测区域就可以变换到三维视锥(图3),过滤三维视锥外的点云并对视锥内的点云进行提取,这样就只需要在视锥中对点云进行检索,而不需要在整个场景中检索,大大地减少了计算量。由于在实际中视锥的朝向是各异的,需要对视锥进行旋转归一化处理,从相机坐标系图3(a)转换到视锥坐标系图3(b),使视锥的中心轴(z轴)与图像所在的平面正交化,归一化处理有利于提升模型的旋转不变性。
2.2 3D实例分割
由于在场景中有很多前景的遮挡和后景的干扰,直接对视锥中的点云进行3D检测框回归是很困难的。考虑到目标在三维空间的自然状态下是自然分离的,而在二维空间中并没有目标之间的深度信息,因此3D点云分割是比在图像上更加容易和自然的。3D实例分割模块使用了PointNet网络,对视锥中的点云进行语义分割得到目标点云(一个视锥只分割出一个对象),分割网络结构如图4,其中mlp为多层感知器。在该模块中还加入了一个预定义的语义类别one-hot向量,利用图像的检测结果辅助网络对目标点云进行分割。最后对目标点云进一步地平移归一化操作,将视锥坐标系图3(c)转换到掩模坐标系图3(d),坐标系原点为点云掩模的质心,提高模型的平移不变性。这样目标点云就都集中在坐标原点附近,使得后续的处理进一步地简化。
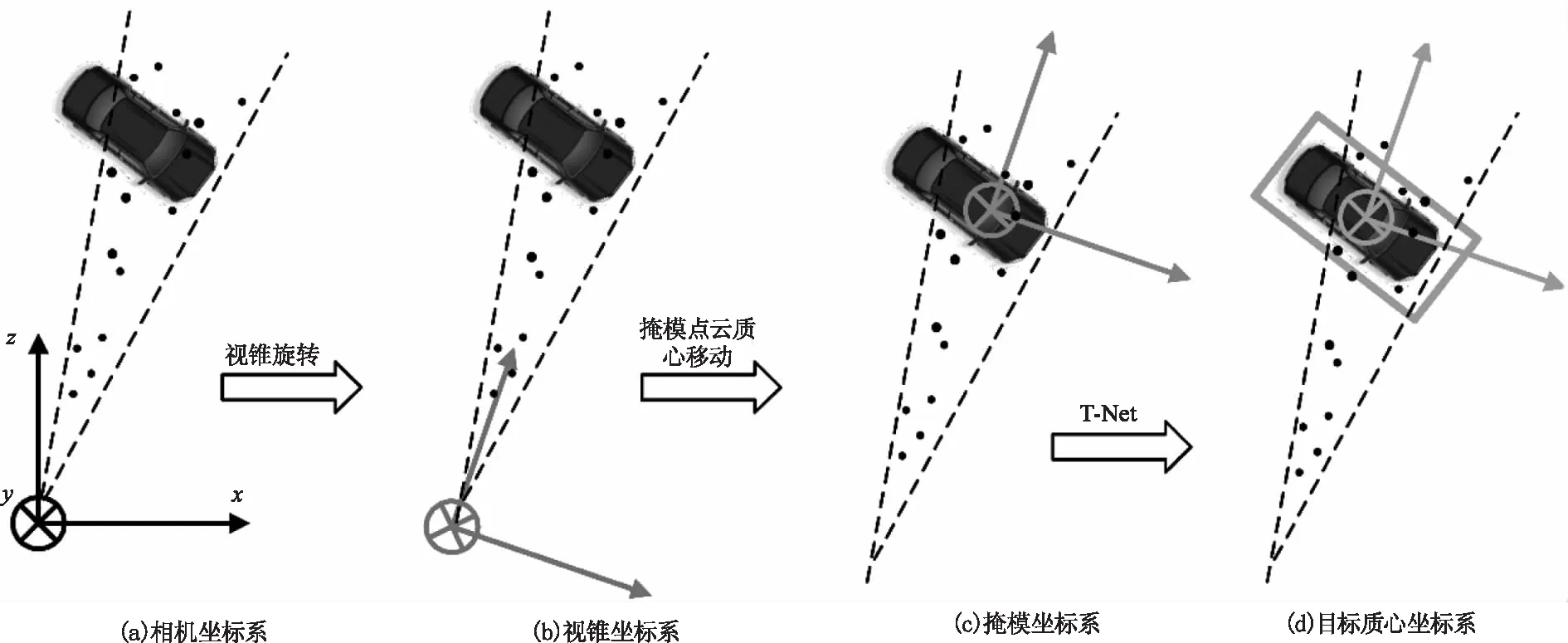
图3 坐标归一化

图4 3D实例分割结构
2.3 3D检测框回归
由3D实例分割得到的目标点云在掩模坐标系下的质心并不是物体真实的质心,这是因为3D激光雷达在采集点云的过程中会被其他目标物遮挡或一部分目标点云在视锥之外,造成目标点云并不完整,因此计算出的目标点云质心可能与目标物体真实的质心距离很远。模型采用一个轻量的变换网络T-Net来估计完整目标物体的质心,预测目标物体的质心和掩模坐标系原点之间的残差。最后一步为3D检测框的估计,通过PointNet网络如图5所示,对3D检测框的中心、尺寸、朝向进行估计。对于检测框的中心采用残差的方法来进行估计,由3D检测框估计网络(PointNet)估计的中心残差与T-Net先前估计的中心残差和点云掩模的中心进行组合,以恢复目标物体真正的中心,再将点云从掩模坐标系转换到预测的以目标物体真实质心为原点的坐标系。如公式(1)所示,Cpred为最终预测的检测框中心残差,Cmask为点云掩模的中心残差;ΔCT-Net为T-Net估计的中心残差;ΔCBox-net为PointNet估计的中心残差。最终由全连接层(FCs)输出3D检测框的质心坐标(cx,cy,cz)、长宽高(h,w,l)、航向角(θ)共7个参数。
Cpred=Cmask+ΔCT-Net+ΔCBox-net
(1)
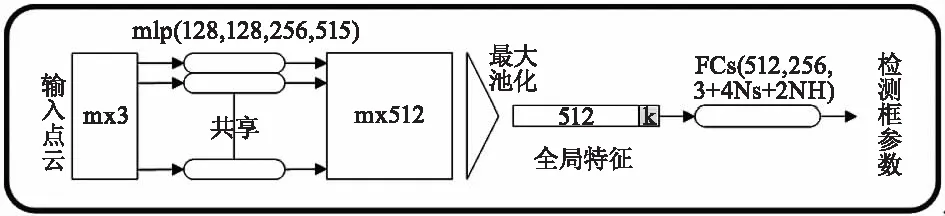
图5 3D检测框评估PointNet网络结构
3 Frustum-Pointnets模型改进
3.1 激活函数
激活函数是深度学习中的核心单元,主要目的是对神经元的输入映射到输出,通过引入一个非线性的函数,使得神经网络在传递过程中每一层的输入端和输出端不再是简单的线性函数,而是可以逼近任意的非线性函数,让神经网络拥有强大的表达能力。选用合适的激活函数可以提高模型的性能和收敛速度,常见的激活函数有sigmoid、tanh、ReLU函数,但sigmoid和tanh函数在输入值非常大或非常小时函数的输出值的变化很小,在反向传播中会导致梯度逐渐变小甚至消失,最终导致权重得不到更新。在本实验中选用了ReLU[15]和Swish函数[16]。
ReLU函数的表达式非常简单,如图6(a)当x>0时,输入值等于输出值,当x<0时,输出值等于0。ReLU函数的表达式为:
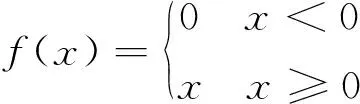
(2)
其中,f(x)为输出值;x为输入值。
ReLU函数的优点在于解决了sigmoid、tanh函数梯度消失的问题,计算量小收敛速度快,只需要一个阈值(是否大于0)就可以得到激活值,但是在输入值小于0时直接简单地置0,导致该神经元不再被激活,参数永远得不到更新,最终造成大量有效特征被屏蔽。
Swish函数是由谷歌大脑团队提出的。如图6(b)Swish函数与ReLU函数一样无上界而有下界,但Swish函数是平滑且非单调的函数。函数表达式为:
(3)
其中,f(x)为输出值;x为输入值;β是一个常数或者是可训练的参数,当β=0时Swish为线性函数,当β→∞时Swish函数变为ReLU函数,因此Swish函数是介于线性函数与ReLU函数之间的平滑函数。虽然收敛速度相比ReLU函数慢,但Swish的平滑和非单调性是它的优点,在输入为负值时仍能输出有效值,避免了神经元坏死梯度参数无法更新的情况的出现,而且由于是非单调函数,因此即使输入值增大输出值也可以减小,更加适合深层次的神经网络。
3.2 参数初始化
参数初始化是深度学习中一个很重要的方面,合适的参数初始化方法能让神经网络在训练的过程学习到更多有用的信息,这意味着参数梯度不应该为0。在全连接的神经网络中,参数梯度与反向传播得到的状态梯度和激活值有关,激活值饱和会导致该层状态梯度信息为0,然后导致下面所有层的参数梯度为0,因此参数初始化函数应该使得各层激活值不会出现饱和现象且激活值不为0。选用合适的参数初始化函数不但能够避免梯度消失的现象,同时也能加快收敛速度提高网络的训练效率。传统的参数初始化方法从高斯分布中随机初始化参数,甚至直接全初始化为1或者0,这样的方法虽然简单计算量小,但效果往往很差。为了提高模型的性能,本试验选用了Xavier初始化[17]和He初始化方法[18]。
Xavier初始化的基本原理是若对于一层网络的输入和输出可以保持均匀分布而且方差一致,就能够避免输出值都为0的情况,从而避免梯度消失,使得信号在神经网络中可以传递得更深,在经过多层神经网络元后输出值保持在一个合理的范围。根据输入和输出神经元的数量自动决定初始化的范围,初始化范围如公式(4),n为所在层的输入维度,m为输出维度。
(4)
He初始化考虑到了ReLU函数的影响,基本原理是对于ReLU激活函数,当输入小于0时其输出为0,会导致该神经元关闭,影响其输出值的分布模式。因此在Xavier初始化的基础上,假设有一半的输出为0,就需要对权重的方差进行加倍补偿,使得参数的方差保持平稳。
4 实验结果与分析
4.1 实验环境
实验平台为AMD锐龙R5 3600、NVIDIARTX 2060 Super、16 GB内存,在Ubuntu 18.04和Python 2.7下搭建CUDA 10.0、CUDNN 7.6.4、TensorFlow 1.15深度学习环境。实验采用自动驾驶场景KITTI数据集,KITTI数据集是目前公开的规模最大的交通场景数据集,包含市区、乡村和高速公路场景的真实图像和点云数据,每个场景中最多达15辆汽车和30个行人,根据不同程度的遮挡和截断,划分为简单、中等、困难三个等级。该数据集共有7481个场景对应7481张图像和相应点云数据,将KITTI数据集划分为3712份训练集和3769份验证集。
4.2 3D目标检测精度对比
采用不同的激活函数和参数初始化方法进行组合对比,模型优化器选择Adam,初始学习率设置为0.001,初始衰减率为0.5,衰减速度为800000,即每迭代800000次学习率减半,batch_size设置为32,num_point为1024,max_epoch为200,即每次迭代处理32份点云数据且每一个样本只从视锥里抽取1024个点用于训练,并对所有训练样本迭代200次。目标检测精度实验结果如表1所示。由表1可知:ReLU和Xavier组合对汽车的检测在简单与困难下准确率最高;使用Swish和Xavier组合时对行人的检测准确率最高;而使用Swish和He方法组合时对骑车人的检测准确率最高。虽然使用Swish激活函数和He初始化方法在汽车与行人的检测准确率比其他组合低,但是差距很小,而且在对骑车人的检测中,这种方法组合的准确率远高于其他的方法组合,因此综合考虑,选用Swish作为激活函数、He作为模型的初始化方法最为合适,在目标检测中可以达到较好的效果。
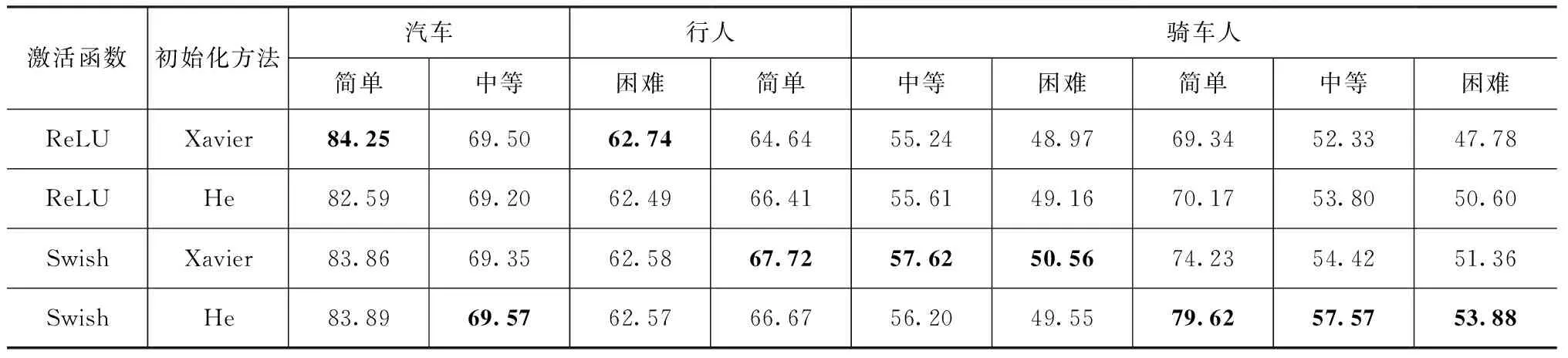
表1 不同激活函数和初始化方法组合目标检测精度对比
将改进过的模型与近年来主流的3D目标检测模型进行对比,不同模型的目标检测结果如表2所示,其中AVOD[19]和MV3D[20]是基于多视角投影的方法;VoxelNet[21]是基于体素的方法。从表2可以看出:改进后的Frustum-Pointnets模型只有汽车(困难)的检测准确率比VoxelNet略低,对行人和骑车人的检测准确率均高于其他模型;与原始的Frustum-Pointnets模型相比,目标检测准确率均得到了提升,特别是对骑车人的检测准确率提升更为明显,两者的差距最多达到了9.45 %。
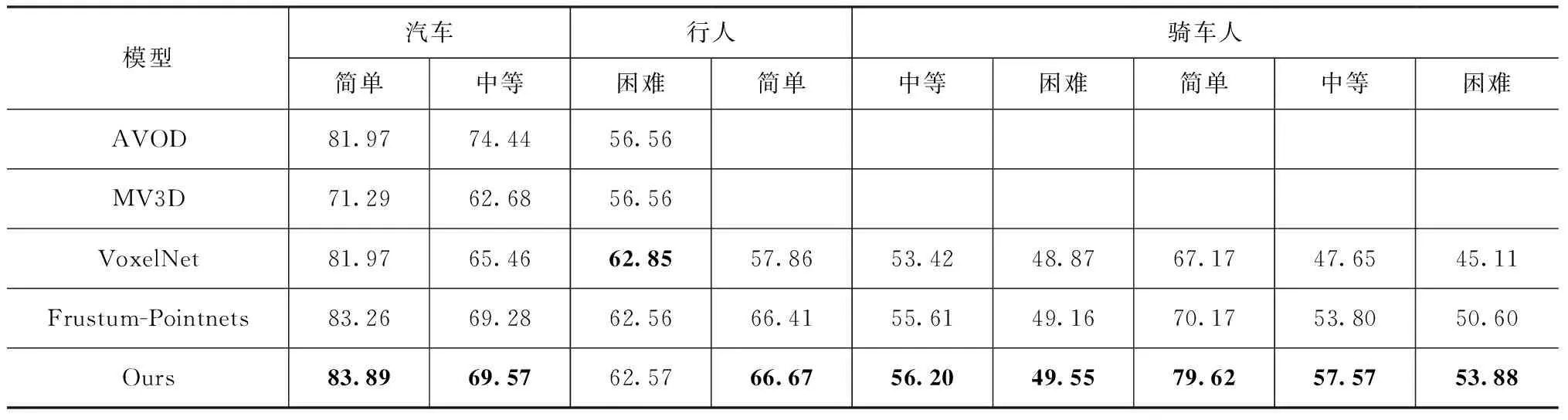
表2 不同模型目标检测精度对比
4.3 3D目标检测可视化与分析
对Frustum-Pointnets模型输出得到的7个参数进行三维空间的可视化。在图像中的真值框和在点云中预测的3D检测框如图7所示,图7(a)为图像的2D真值检测框可视化,图7(b)为图像的3D真值检测框可视化,图7(c)为点云的预测结果可视化。从图中可以看出:场景中的目标基本都能被准确的识别,即使左下角和右下角的汽车只能看到一小部分,在点云中仍旧能精确地检测出目标物体的边界和航向。而最远处的汽车由于距离太远目标点云过于稀疏,目标的位置和朝向被错误的估计,检测结果与真实值存在较大误差。

5 结 语
针对目前利用点云进行3D目标检测的准确率较低的情况,本文利用Frustum-Pointnets模型实现对点云的3D目标检测,并在该模型的基础上进行改进,选择合适的激活函数和参数初始化方法组合,提高了目标检测的精度,与原始的Frustum-Pointnets模型相比,在对骑车人的检测中准确率分别提高了9.45 %、3.77 %和3.28 %,对模型的泛化性有了进一步的提高。然而由于Frustum-Pointnets模型采用图像和点云串行处理结构,而不是图像和点云一起的并行处理,导致3D目标检测的精度依赖于图像的检测结果,在光线条件差和遮挡严重等情况下,2D检测器难以准确定位目标导致影响到3D目标检测的准确度。在目标物体离传感器太远的情况下,由于获取到的点云过于稀疏,模型无法准确估计目标的准确位置,出现漏判和错判的情况。接下来将对模型进一步研究,改善这些问题。
猜你喜欢
少儿科学周刊·少年版(2022年14期)2022-05-30 10:48:04
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年19期)2019-11-23 08:42:00
少儿科学周刊·儿童版(2019年6期)2019-08-24 03:28:31
中国交通信息化(2018年5期)2018-08-21 03:37:40
方圆(2016年8期)2016-05-04 19:46:47
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
