
完全辅助信息下非参数模型校准估计方法研究
2020-11-04 14:13贺建风陈茜儒
统计与信息论坛 2020年11期
贺建风,陈茜儒,陈 飞
(1.华南理工大学 经济与金融学院,广东 广州 510006; 2.安徽长丰双凤经济开发区管理委员会,安徽 合肥 231100)
一、引 言
随着信息技术快速发展,云计算和大数据技术正不断成熟,在现代化的统计调查实践中,我们更容易获取大量与研究变量相关联的辅助信息,例如普查资料、前一期调查数据、卫星遥感信息、行政记录以及商业大数据资源等。利用辅助信息构建抽样估计量能够在不增加调查成本的同时,极大地提高估计精度。校准估计方法就是一种能够很好利用辅助信息改进抽样估计效率的方法,其基本思路是通过校准约束信息来修正原有估计量的权重系数,从而达到提高估计精度的目标。然而,传统的校准估计量仅利用到了总体和样本观测个体所构成的部分辅助信息,对于调查环节中未被观测样本的辅助信息并没有加以利用,这样势必会浪费更多可利用的辅助信息。事实上,在信息比较容易获取的大数据时代,我们通常有条件利用每一个总体单位的完全辅助信息来进行校准估计。最早Wu和Sitter通过构建研究变量与辅助变量之间的超总体模型,将完全辅助信息应用于校准估计,首次提出模型校准估计的概念[1]。在此基础上,Wu证明了模型校准估计为最优估计量,即在超总体模型下,其渐近设计方差的期望最小[2]。利用完全辅助信息构建模型校准抽样估计过程中,关键在于选择合适的模型以及模型的估计方法。
传统校准估计方法适用的前提较为严格,要求研究变量与辅助变量之间呈线性关系。然而大数据时代背景下,数据结构较为复杂,研究变量与辅助变量之间往往并没有明显的线性关系,为了构建适应性更强的模型校准估计量,本文考虑在超总体模型的基础上构建非参数模型校准估计方法体系。与线性假定条件下的传统校准估计方法一样,直观上来看,由于非参数模型校准估计量中也会纳入辅助信息,其估计精度在理论上将高于HT估计量。为了更全面、深入地研究具有完全辅助信息条件下,且辅助变量与研究变量之间呈非线性关系时,如何更好地开展模型校准抽样估计,本文将对此问题进行系统性讨论。本文的主要贡献在于:第一,在文献梳理的基础上,将校准抽样估计方法归纳为部分辅助信息下的传统校准估计和完全辅助信息下的模型校准估计两大类;第二,在介绍局部多项式模型校准估计的基础上,拓展性地提出了基于惩罚样条的模型校准估计方法,对非参数模型校准估计方法体系进行了补充;第三,理论分析与数值模拟均表明,完全辅助信息下的模型校准估计方法具有较好的性质与更好的估计效果。
二、文献综述
(一)校准估计方法的研究进展
20世纪90年代,Deville和Särndal最早提出了校准估计法,并通过拉格朗日函数求极值的方法求得校准权数和总体总值的校准估计量形式[3]。之后的20多年间,抽样校准估计方法很快成为了国内外抽样调查研究领域的热点。Deville等在常用距离函数的基础上提出指数型、二次型和logit方程等其他形式的距离函数,并证明不同形式的距离函数均可得到估计量的渐近无偏性和一致性[4]。为了解决部分距离函数求解校准权重中可能出现负值和极端值的情况,Rao和Singh采用岭回归压缩系数方法,在给定容忍度范围情况下使得满足约束条件的校准系数落入指定范围[5]。为了使求解校准权重的方法更加多样化,Estevao和Särndal对校准权重的获得采取了一种新的方法,在新的方法中放弃原有的约束等式进而应用工具向量法,该方法可以在同一组辅助信息上产生多种校准权重[6]。Estevao和Särndal等人将工具向量法拓展到了复杂抽样中,例如二重抽样、二阶抽样、无回答问题中[7]。Wu和Sitter研究在辅助信息完全的情况下,通过构造超总体模型求得总体简单参数的校准估计量,放松了研究变量和辅助变量之间关系的假定,一定程度上拓展了校准估计法的运用空间。进一步地,Wu证明了在没有模型误设的条件下,通过模型校准估计法获得的估计量是最优的;若模型有误,所得到的估计量在性质上至少具有一致性。Montanari和Ranalli将局部多项式回归和神经网络回归两种非参数方法引入校准估计中,采用模型校准估计方法,在研究变量和辅助变量是非线性关系的情形下,分别得到其模型校准估计量,并证明了在合适的条件下估计量具有渐近正态性和一致性等良好性质[8]。Rueda等在有限总体分布函数的估计中运用校准估计法,并运用局部线性回归,得到模型校准估计量[9]。
国内学者对校准估计法的研究大部分集中在对校准估计理论的梳理和方法的应用上。刘建平和常启辉对国外抽样调查中的校准估计在理论方法和应用方面做了系统的梳理,并对其在中国抽样调查中的应用前景做了一些展望[10]。马志华和陈光慧将局部多项式回归引入模型校准抽样估计中,得到了局部多项式模型校准估计量,并说明了该估计量具有良好的统计性质[11]。贺建风则将校准估计方法引入到多重抽样框的情形,并比较了不同模式下的估计功效[12]。金勇进等将RGRG法引入不可忽略的无回答机制下的校准估计,并证明该方法对无回答具有双重保护作用[13]。
(二)非参数抽样估计的研究现状
本文对研究总体特征进行统计推断的另一个理论基础是非参数回归方法。在基于模型(Based model)和模型辅助(Model assist)两种不同的估计框架下,国外学者对非参数方法在抽样估计中的运用进行了广泛且比较深入的研究。在基于模型的框架下,Kuo最早运用核估计方法在单个辅助变量的条件下对总体分布函数和总体总值构造了基于模型的估计量,得到了总体总值的Kuo估计量[14];Dofman在对有限总体总值估计抽样单元的研究变量估计中使用了Nadaraya-Watson核估计量[15];Chambers等在得到核估计量后运用了非参数校准方法,研究显示该估计量在线性超总体模型正确情况下比Kuo估计量有效,当模型误设时,模型对估计量的估计效果影响较小[16]。
基于模型的估计量有一个突出特点,即当模型设定正确时,估计量的估计效果要远高于其他类型的估计量,但当模型误设时,估计量的估计效果较差,甚至不如一些线性估计量。为了解决这一问题,不少学者开展采用模型辅助方法进行抽样估计的研究工作,产生了大量模型辅助估计量。Breidt和Opsomer最早在模型辅助框架下,利用非参数回归中的局部多项式回归估计方法构建基于局部多项式模型的辅助回归估计量,研究表明该估计量具有一致性和渐近正态性的良好性质,模拟研究显示该估计量在模型误设时,其估计精度仍然很高[17]。Breidt等构建了惩罚样条的非参数模型,结合差分估计方法,得到了惩罚样条模型辅助估计量,并把惩罚样条方法推广到半参数回归估计中[18]。Montanari和Ranalli运用了神经网络回归方法对研究变量和辅助变量的关系进行建模,得到模型辅助的神经网络估计量,并证明了在一定的条件下,该估计量具有一致性和无偏性等良好的性质。Opsomer等研究了非参数可加模型在模型辅助估计中的应用,得到的半参数估计量具有设计一致和渐近性的性质[19]。
三、校准抽样估计方法的分类
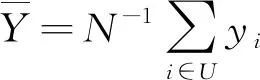
(1)
其中di=1/πi,显然HT估计量具有设计无偏性,其估计量方差为:
(2)
虽然HT估计量具有良好的性质,但是由于在估计过程中仅利用到研究变量本身的样本信息和样本单元的包含概率,并没有利用其他任何辅助信息,其估计效率必然不会很高。下面我们根据利用辅助信息的不同程度介绍两类针对式(1)的校准估计方法。
(一)基于部分辅助信息的传统校准估计

(3)
式(3)中qi是调节参数,取值为正,且与di不相关。利用拉格朗日极值法可求出校准估计为:
(4)


(二)基于完全辅助信息的模型校准估计
根据前文的分析可知,传统校准估计量至少存在辅助信息利用不全和要求研究变量与辅助变量之间呈线性关系两大缺陷,因此其在应用中会出现效率不高和范围受限等问题。为了解决校准估计量在这两方面的难题,Wu和Sitter提出了模型校准估计方法,基本思路是在超总体模型的基础上,利用完全辅助信息来重新构建校准估计量,进而得到模型校准估计量[1]。事实上,随着大数据时代的来临,各种信息和数据搜集的手段不断进步,获取完全的辅助信息已不再是难事。因此,在抽样调查的估计推断环节中,我们可以充分利用完全的辅助信息来建立模型校准估计量,进而提高估计精度。
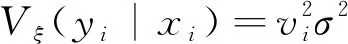
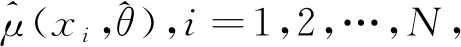
(5)
其中,模型校准权重ωi与初始基于设计的权重di之间的平均距离最小,并满足如下限制条件:
(6)
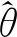
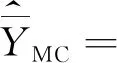
(7)
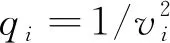
四、非参数模型校准估计方法构建
在上一节所介绍的模型校准估计方法中,假定μ(xi,θ)是一个包含总体参数的已知函数,其函数形式并未做出明确要求。未知总体参数可以依据样本的信息进行估计,进而可得到超总体模型中均值方程的估计式。当研究变量与辅助变量之间不呈线性关系时,我们可以建立更为复杂的非参数超总体回归模型来得到模型校准估计量,其估计效果将优于传统校准估计方法。非参数回归模型可以针对非线性的复杂问题进行灵活的推断,模型的形式可以灵活变化,在实际中应用范围十分广泛。由于对总体分布的假定要求条件较宽,因而非参数回归模型的估计效果往往不会因为假定不当而导致较大误差出现,通常表现出较好的稳健性。
这里我们沿用Montanari和Ranalli的基本思路,在介绍传统局部多项式回归的非参数模型校准估计方法的基础上,将惩罚样条估计方法引入到非参数模型校准估计框架中,并与局部多项式模型校准估计方法进行比较分析[8]。借鉴Breidt和Opsomer提出的非参数模型基本框架,非参数超总体回归模型ξ可设定为[17]:
yi=m(xi)+εi,i=1,2,…,N
(8)
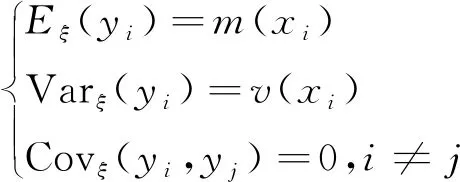
这里m(·)是辅助变量xi的光滑函数,εi是均值为零的独立随机变量,其方差为v(xi),且v(·)是严格为正的光滑函数,{(yi,xi):i∈U}是超总体模型中的一个随机实现组合。在非参数模型校准估计的方法体系中,辅助变量的光滑函数m(·)不再是经典的线性模式,而需要通过非参数的方法得到具体的估计形式。下面在已有的局部多项式模型校准估计方法的基础上,给出了一种全新的惩罚样条回归模型校准估计方法。
(一)局部多项式模型校准估计
目前,局部多项式估计方法是一种应用广泛的非参数技术。这种估计方法的基本思想是假定距离当前位置较远的数据点能够提供的信息很少,当前位置的信息主要利用其附近的局部数据来推断。在模型辅助抽样估计中,Breidt和 Opsomer首次给出了局部多项式模型辅助估计方法的基本框架[16]。局部多项式模型校准估计是在其基础上针对权重系数进行校准所得。
假定m(x)在x=x0处存在p+1阶导数,则可以用该点的泰勒展开式来表示光滑函数m(x)的近似形式,所以对于式(8)而言,可近似表示为:
yi=m(x0)+m′(x0)(xi-x0)+…+
(9)
接下来,使用局部加权多项式的模型方法进行估计,可得到多项式模型校准估计。其中拟合过程的目标函数为:
(10)
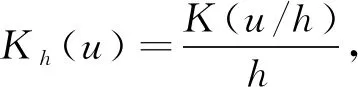
(11)

(12)
求解最小化问题可得局部多项式模型校准估计量的具体表达式为:
(13)
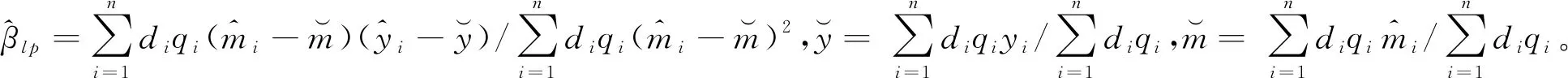
Montanarii、马志华等的模拟研究均表明,当研究变量与辅助变量之间并不呈线性关系时,传统的校准估计量的估计效率与经典HT估计量相比并没有显著改善,而基于局部多项式回归的模型校准估计量有着较高的估计效率,很好地解决了抽样估计中,辅助变量与研究变量呈非线性关系时的估计问题[8,11]。但是基于局部多项式回归的模型校准估计也存在一些缺憾,比如很难将多个协变量组合在一起引入到核函数中,特别是分类变量和连续变量的组合比较困难。利用大量的样条或其他形式的基函数,结合变量选择或正则化惩罚方法来控制模型的复杂性,能够在很大程度上克服上述局部多项式模型校准估计的缺点。
(二)惩罚样条回归模型校准估计
在超总体模型辅助的框架下,Breidt等最早给出了总体总值的惩罚样条回归估计量,并证明了该估计量具有渐近正态性、渐近一致性等一系列良好的统计性质,并把研究变量和辅助变量的关系描述成一个线性混合模型,使得惩罚样条模型很容易处理连续数据或分类数据、参数和非参数关系、空间和时间结构的数据等,极大地拓展了惩罚样条方法在抽样估计中的应用[18]。因此,我们接下来将惩罚样条这种非参数方法引入到完全辅助信息条件下的模型校准估计中,首先,需要按照惩罚样条的基本形式来定义光滑函数m(·),其定义如式(14)所示:
m(x;β)=β0+β1x+…+βqxq+
(14)
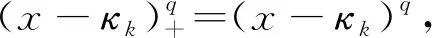
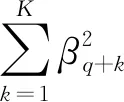
(15)
其中,λ为光滑参数,为了得出估计量,这里假定为一个固定的常数,光滑参数值决定最终拟合的效果。根据最小二乘法的基本计算过程,可得系数向量βU的岭回归估计量如式(16)所示。
βU=(XTX+Aλ)-1XTY
(16)
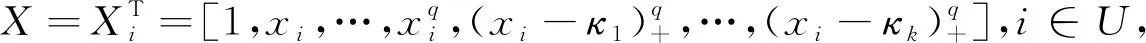
(17)
其中,mi=mi(x),可以证明该估计量是设计无偏的,其设计方差为:
根据样本信息,可以构造广义差分估计量式(17)中βU的估计形式:
(18)
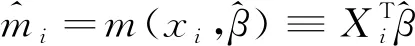
(19)
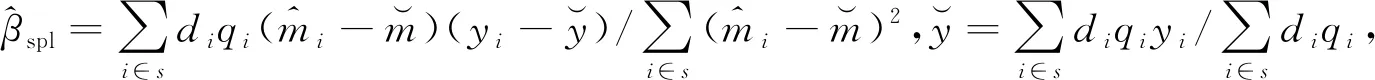
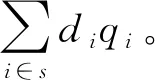

=Xsβ+Zsb+εk
(20)
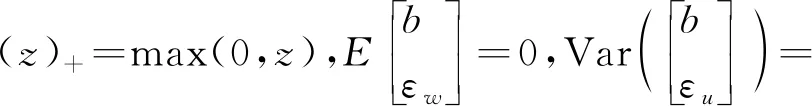
与基于局部多项式回归方法的模型校准估计不同,这里采用惩罚样条回归的估计方法,研究变量与辅助变量之间的关系可以表达成线性混合模型的形式,因此可以很方便地将连续型或者分类型的辅助变量都纳入模型中,从而进行有效的校准估计。
(三)模型校准估计量性质
在大样本情况下,局部多项式和惩罚样条两种非参数方法具有相似的渐近性质,这里我们不加以区分,进行统一讨论。对于局部多项模型校准估计量的性质,Montanari和Ranalli针对单一辅助变量的情形进行了一般性的探讨[8],马志华和陈光慧在其基础上讨论了多元辅助变量条件下的估计量性质,理论上来看是完全一致的[11]。由于实际中多元辅助变量情形操作比较复杂,这里同样给出一元辅助变量情形下的局部多项式模型校准估计量和惩罚样条回归模型校准估计量的性质。为了研究该估计量的性质,需要作以下基本假设:

(2)对于每个v值,辅助变量xi基于式(8)中假定的超总体模型ξ来说是固定的。模型误差项εi相互独立,其均值为0,方差为v(xi)是连续函数且严格为正。
(3)均值函数m(·)是连续函数,且p+1阶连续可导,p为局部多项式函数的最高次数。
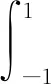
(5)当v→时,有n/N→π∈(0,1),带宽hv→0和均成立。
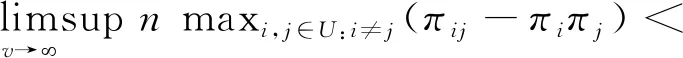
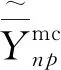
(21)

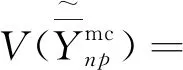
(22)
当ν→时,有也意味着
由式(22)可得,方差的设计一致估计量为:
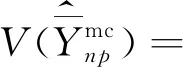
(23)
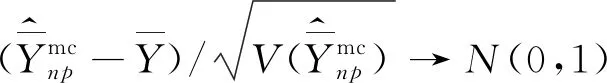
五、模拟研究
线性函数:m1(x)=1+2(x-0.5)
二次函数:m2(x)=1+2(x-0.5)2
指数函数:m3(x)=exp(-8x)
Bump函数:m4(x)=1+2(x-0.5)+
exp(-200(x-0.5)2)
Jump函数:m5(x)=1+2(x-0.5)I(x≤0.65)+0.65I(x>0.65)
Cdf函数:m6(x)=Φ[(1.5-2x)/σ],Φ是标准正态分布的累计分布函数。
Cycle1函数:m7(x)=2+sin(2πx)
Cycle4函数:m8(x)=2+sin(8πx)
(24)
(25)
接下来,通过编写Python程序,并运算分别得到这4种估计量的数值模拟分析结果。分析相对设计偏差模拟结果发现:局部多项式模型校准估计量和惩罚样条模型校准估计量在对应的参数之下,除了在指数函数总体外,局部多项式模型校准估计量相对于HT估计量的偏差较大之外,其他情况下,估计量的偏差并无明显的优劣区别,绝大部分都在0.1%以内(2)限于篇幅,这里并未报告相对设计偏差的模拟结果,有兴趣者可向作者索要。。下面我们将重点分析辅助变量不同分布情况下基于非参数方法得到的模型校准估计量和传统线性估计量的相对效率值,估计量相对效率的模拟结果如表1和表2所示。
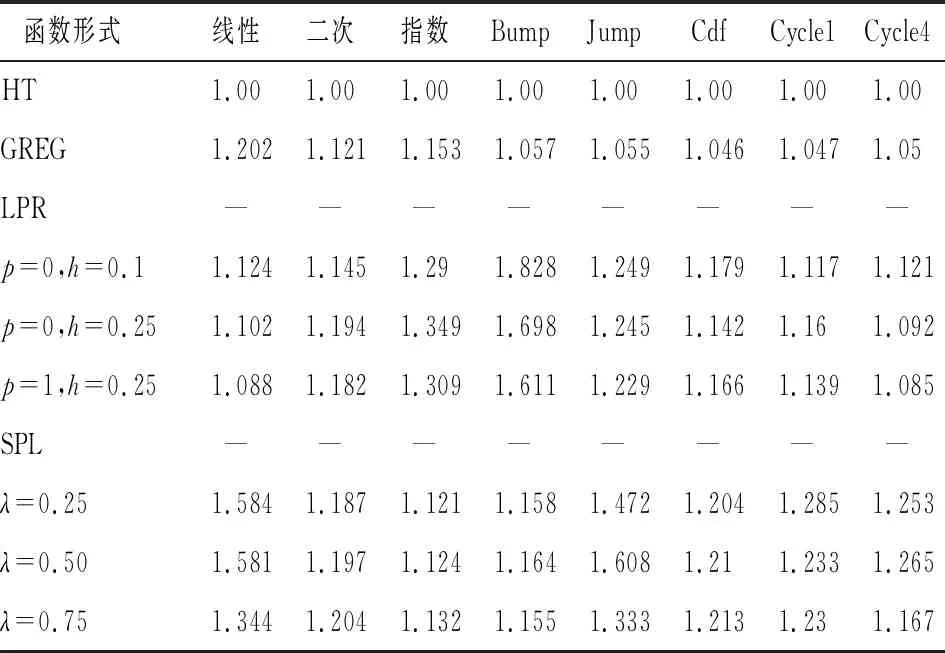
表1 辅助变量为均匀分布下各估计量的相对效率值
表1显示了在辅助变量为均匀分布情况下,各估计量在不同的总体回归函数下的相对效率值。从总体线性程度的角度看,在线性函数的总体下,非参数模型和参数模型的效率差距不大,GREG估计量甚至略优与LPR模型校准估计量,SPL模型校准估计量的估计效果的优势也比较微弱,其原因是对于线性函数而言,参数模型就能产生较好的估计效果,而不需要复杂的非参数模型。从纵向比较来看,非参数模型校准估计量的估计效果都优于参数模型,随着总体函数的线性程度不断降低,可以发现GREG的估计效果呈现下降的趋势,在最后的几个个函数中,RE值接近1,而非参数模型校准估计量的估计效果大致上保持不变,并且SPL模型校准估计量整体上要优于LPR模型校准估计量,此外各非参数模型校准估计量对GREG估计量的优势随着非线性程度的增强而不断增大。从系数对比的角度来看,在LPR估计中,窗宽h由0.1增大到0.25情况下,大部分RE值有所降低,可以猜测随着窗宽h的增大,LPR估计量的估计效果逐渐降低;SPL的光滑系数从0.25至0.75过程中,其估计效果差别不大,一个可能的解释是选择的光滑系数并没有落在最优的区间,因此光滑系数的变动对估计效果的影响很有限。
表2为辅助变量在服从有偏的beta分布情况下,各估计量在不同的总体回归函数下的相对效率值。从表中的数据可以看出,虽然辅助变量的分布确实影响了各个估计量的估计效果,尤其在总体函数为Cdf函数时,beta分布下的LPR模型校准估计量的相对效率有较大幅度的提高,其他情况下大体上与表1的分析情况相一致,这也说明了非参数模型校准估计是比较稳健的。
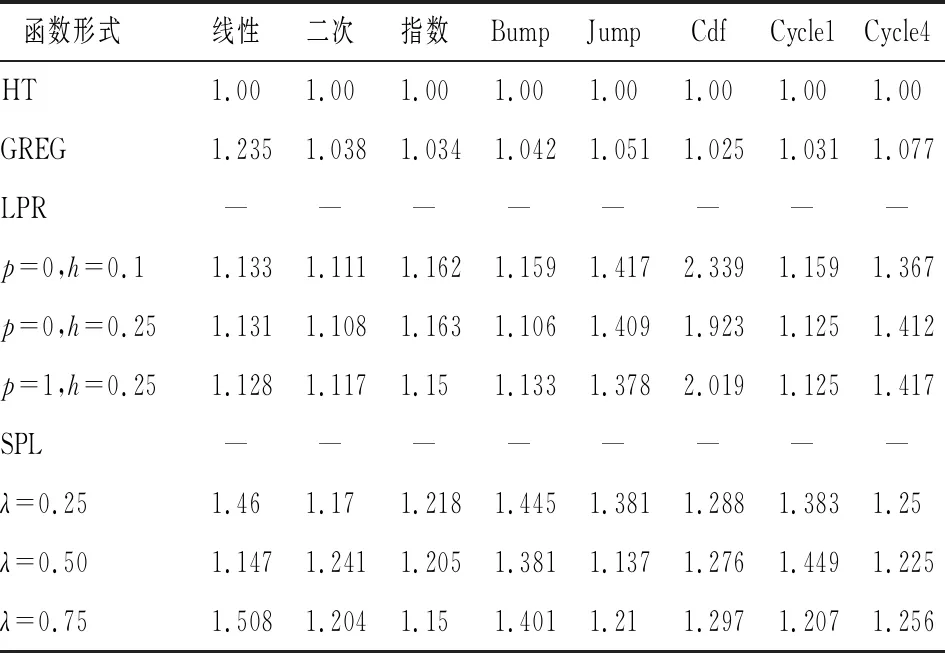
表2 辅助变量为beta分布下各估计量的相对效率值
六、实际应用中的展望
随着中国经济社会的持续快速发展,国家以及地方政府的管理与服务水平也在不断完善。为了更好地提供高质量的政府服务公共产品,需要依赖政府统计工作来获取高质量的基础性统计信息。在中国政府统计工作的数据搜集过程中,抽样调查是目前比较普遍的一种做法,比如自然资源环境监测调查、农产量调查、规模以下工业企业调查等,因此政府统计部门对抽样调查方案设计及其抽样估计工作均非常重视。在抽样估计环节,中国政府统计部门通常采用简单估计和比率估计,对于能够有效利用辅助信息的校准估计方法应用较少,更没有考虑到研究变量与辅助变量的非线性关系而应用非参数模型校准估计的方法进行总体信息的推断。随着卫星遥感技术和大数据技术的应用以及信息化水平的提高,在抽样估计阶段,可以通过模型辅助估计的方式充分利用有效的辅助信息来提高估计精度。当研究变量与辅助变量之间呈非线性关系,且能够掌握辅助变量的完全信息时,就可以使用本文构建的非参数模型校准估计方法。下面以中国水资源质量调查为例来介绍这套抽样估计方法的具体应用。
水资源是人类社会得以可持续发展的重要资源之一,目前,中国的水资源环境状况不容乐观,很多地区出现了水资源质量问题。党的十八大以来特别强调了生态文明建设,政府部门以及社会各界更加注重保护自然资源和生态环境,其中也包括水资源,因此,需要加强关于水资源环境状况的调查工作。中国水资源类型多样、分布广泛,通常适合采用抽样调查形式来开展实际调查工作。在水资源的环境调查中,水质的状况是最为重要的一项监测目标,有关水质标准的指标众多,其中反映酸碱性的PH值是一项比较重要且较为直观的指标,按照《地表水环境质量标准》可知,PH值为6.5至8.5区间的水质较好。PH值与水资源所在地的农业用地情况、工业企业排放二氧化硫以及氮氧化物等污染物的情况、污水处理工厂的数量与规模等周边的工、农业发展的辅助信息高度相关,且通常呈现非线性的关系。因此,在抽样估计推断中,我们首先可以利用卫星遥感技术得到水源地附近农业用地情况和具体的位置信息,并利用政府部门的行政记录以及工业企业大数据信息获取水源地附近工厂的数量、排污规模以及污水处理情况等辅助信息;然后利用水的PH值与农业用地比例、工厂数量、排污规模和污水处理率之间的关系,可建立合适的超总体回归模型;接下来考虑到研究变量与辅助变量之间呈非线性关系,利用本文所构建的非参数模型校准估计量对水的PH值进行估计,得到具有渐近无偏、一致且渐近正态等优良统计性质的估计量;最后利用本文所给出的方差估计量可以得到估计量的方差估计,且这里的方差估计也具有设计一致性,根据方差估计量的数值可以评估和改进抽样估计的精度。
中国政府部门主导的抽样项目绝大多数都不是简单随机抽样,因此,本文在一阶抽样下得到的估计量仍需改进以更贴合实际,目前中国的政府统计调查尚未充分利用完全辅助变量,利用非参数方法和模型校准估计方法对辅助变量和研究变量建模在实际中的应用还没有,虽然我们在本文提出了具体应用的展望,但是限于实际数据的可获得性,未能进行实际的估计推断。总体而言,本文所构建的非参数模型校准估计量,在中国以后的抽样估计实践中将具有很强的应用价值。
猜你喜欢
发明与创新(2021年39期)2021-11-05
中学生数理化·中考版(2021年8期)2021-07-31
小学生学习指导(高年级)(2021年4期)2021-04-29
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2020年23期)2020-12-15
中国交通信息化(2019年10期)2019-11-16
中国外汇(2019年6期)2019-07-13
中学数学杂志(初中版)(2017年4期)2017-08-28
中学生数理化·高一版(2017年2期)2017-04-25
汽车文摘(2015年11期)2015-12-02
