
多源数据融合驱动的居民出行特征分析方法
2020-10-31 03:29苏跃江温惠英韦清波吴德馨
交通运输系统工程与信息 2020年5期
苏跃江,温惠英,韦清波,吴德馨
(1.华南理工大学土木与交通学院,广州510641;2.广州市交通运输研究所,广州510635;3.广州市公共交通数据管理中心,广州510620)
0 引 言
居民出行特征包含出行总量、频次、OD、目的、方式、距离、时耗等指标,其作为分析交通需求和交通拥堵症结的基础手段,是研究交通政策、规划建设、运营管理的数据支撑,故科学分析居民出行特征具有重要意义.传统抽样调查对定制问卷采集信息,采取当面问询的调查方式,优点是调查内容针对性强、采集信息相对准确;缺点是采取人工回忆填写,而且涉及多个横向(包含交通、规划、统计等部门)和纵向(市、区、街镇、社区或村委等)组织机构,各层次组织培训质量参差不齐.产生以下几个问题:一是由于漏填、瞒报等原因造成出行率降低,使居民出行总量误判,影响交通设施规划问题;二是由于非通勤和通勤出行的时间差异性,非通勤出行的漏报扩大了高峰出行规模,不利于交通资源的配置均衡性;三是非通勤漏报导致弹性出行需求降低,影响出行特征精度.因此,如何充分利用传统抽样调查数据和大数据资源优势,构建一种基于多种数据源融合的居民出行特征分析方法具有重要的意义.
马小毅[1]基于居民出行和流量调查数据及交通模型分层次扩样,有效地控制了样本数据的分布特征;樊大可等[2]基于核查区居民出行OD 校核方法,分析了区域进出交通量与OD 间的关系;唐小勇等[3]基于手机信令数据对重庆市通勤OD进行扩样;陈必壮等[4]利用IC、GPS等数据,对上海市第五次居民出行特征进行扩样;苏跃江等[5]梳理传统抽样调查与大数据挖掘的关系,探讨大数据在广州市第三次交通综合调查中的作用.本文在基于传统抽样调查扩样分析的基础上,以手机信令、IC、AFC、GPS、车牌识别等大数据挖掘为补充和校核,提出多源数据融合驱动的居民出行特征分析方法,实现各种大数据资源与传统抽样调查数据的有机融合,并以广州市居民出行特征为例进行实证分析.
1 研究方法
本文提出一种多源数据融合驱动的居民出行特征分析方法.分两个层次:一是组合扩样,主要解决调查样本和实际数据扩样带来的人口分布问题,年龄结构、职业结构、车辆拥有分布不均衡问题,以及由于调查漏报、误填等导致出行频次分布不均衡问题;二是综合扩样,主要解决沉默需求造成的时间、空间分布不均衡而带来的总量上缺乏约束,时间上高峰高平峰低,空间上分布不均衡等问题.
1.1 组合扩样方法
首先,根据传统调查样本和实际数据分别对调查的户和人进行总体扩样,其中,家庭户扩样系数等于实际户数除以抽样样本户数,家庭户人口扩样系数等于实际人口除以抽样样本人口;其次,结合车辆拥有量、年龄结构、职业结构、人口总量,以及手机信令数据等实际数据进行分类组合扩样和矫正,其中,车辆拥有依据公安部门提供数据对样本进行扩样,职业结构根据统计部门的经济普查数据对样本进行扩样,年龄结构和人口总量主要根据街镇人口普查数据进行扩样.此过程中各扩样系数既是平行关系又是递进的关系,如图1所示.此外,针对传统入户调查因漏填、瞒报产生出行率低问题,通过大数据分析出行频次解决.有两种方法:一是利用互联网位置数据,通过招募志愿者安装APP主动动态采集居民一周的出行轨迹信息,经过驻点判断获取出行频次分布;二是利用手机信令数据经驻点分析判断后重构居民出行频次分布,如图2所示.
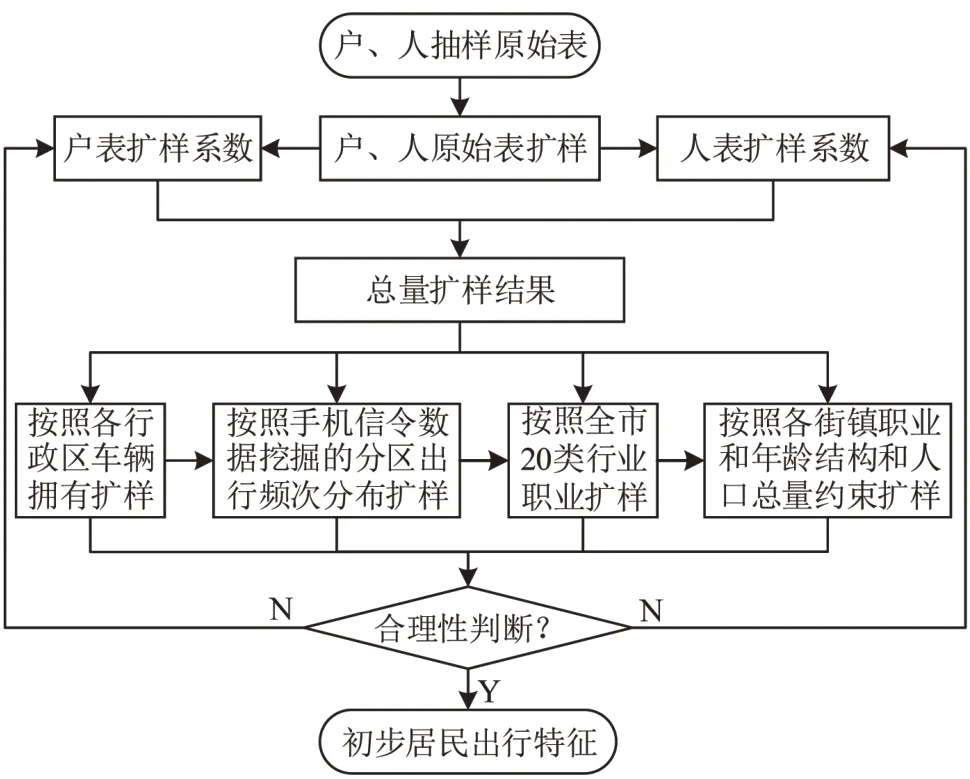
图1 居民出行特征的组合扩样技术路线Fig.1 Technical route of expanding combination of residents'travel characteristics
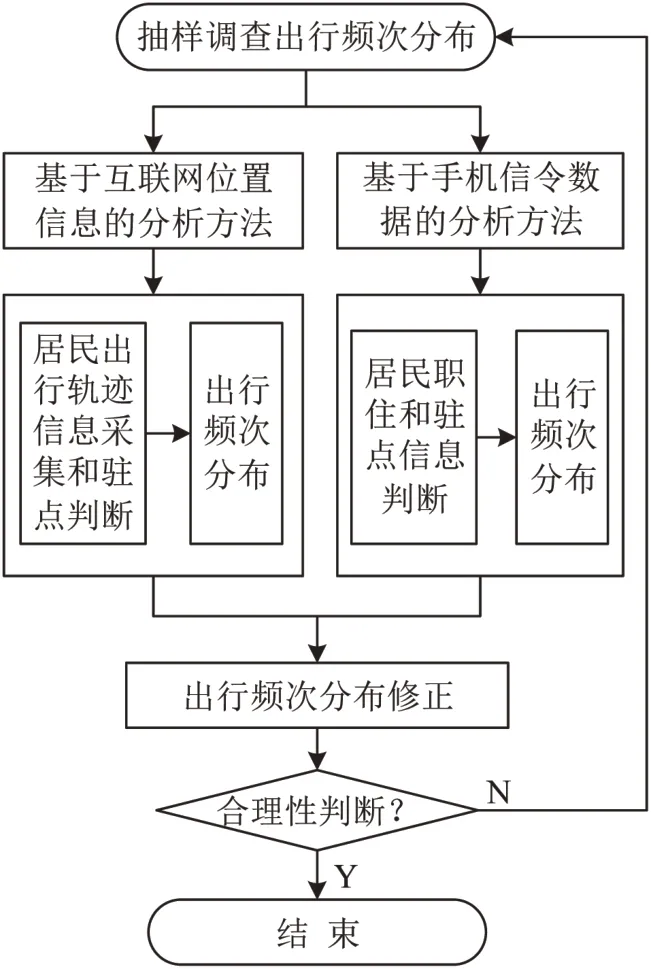
图2 居民出行频次分布的修正技术路线Fig.2 Technical route for correction of distribution of residents'travel frequency
1.2 综合扩样方法
首先,利用组合扩样获取居民OD 分布,并拆分为小汽车、公交、地铁等交通方式OD;其次,利用IC、AFC、GPS等大数据分别矫正公交、地铁、出租汽车的OD 分布;第三,利用手机信令数据对通勤与非通勤出行时间分布进行矫正;最后,以区域出行总量和出行方式结构为约束条件,对出行总量、出行方式、出行OD 分布进行综合矫正,如图3所示.
2 案例分析
研究数据来自广州市2017年9月传统入户抽样调查数据,人口就业,以及IC、AFC、GPS、车牌识别、高速公路流水、手机信令等,如表1 所示.主要包括8.2 万户家庭的46 万条出行信息,100 万条居民出行轨迹信息,2.2 万台出租汽车GPS 信息,500 万张IC 和AFC 刷卡信息,2 144 个卡口车牌识别数据,816 收费站流水数据,600 万手机用户信息等.
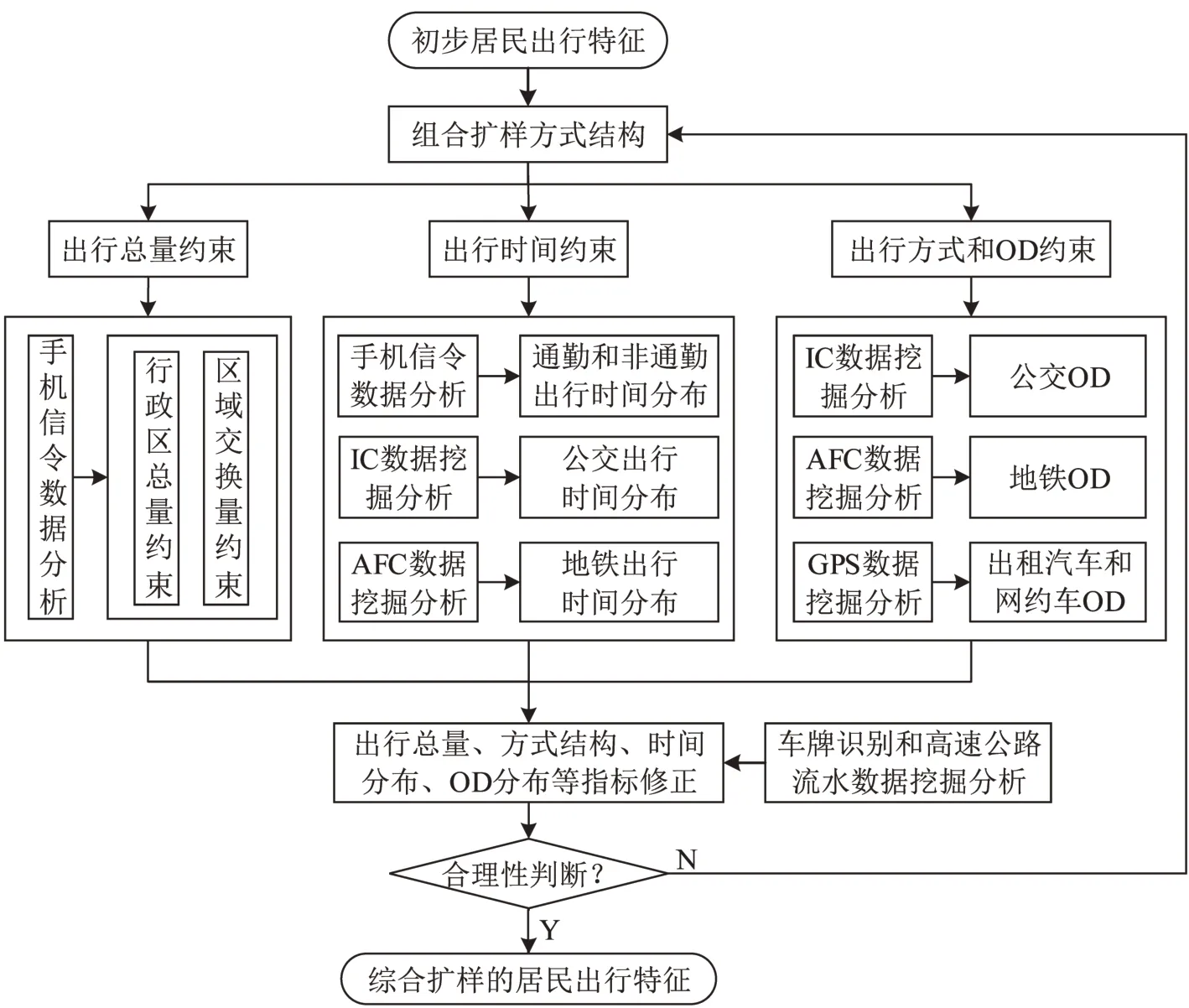
图3 居民出行特征的综合扩样技术路线Fig.3 Technical route for comprehensive expansion of residents'travel characteristics
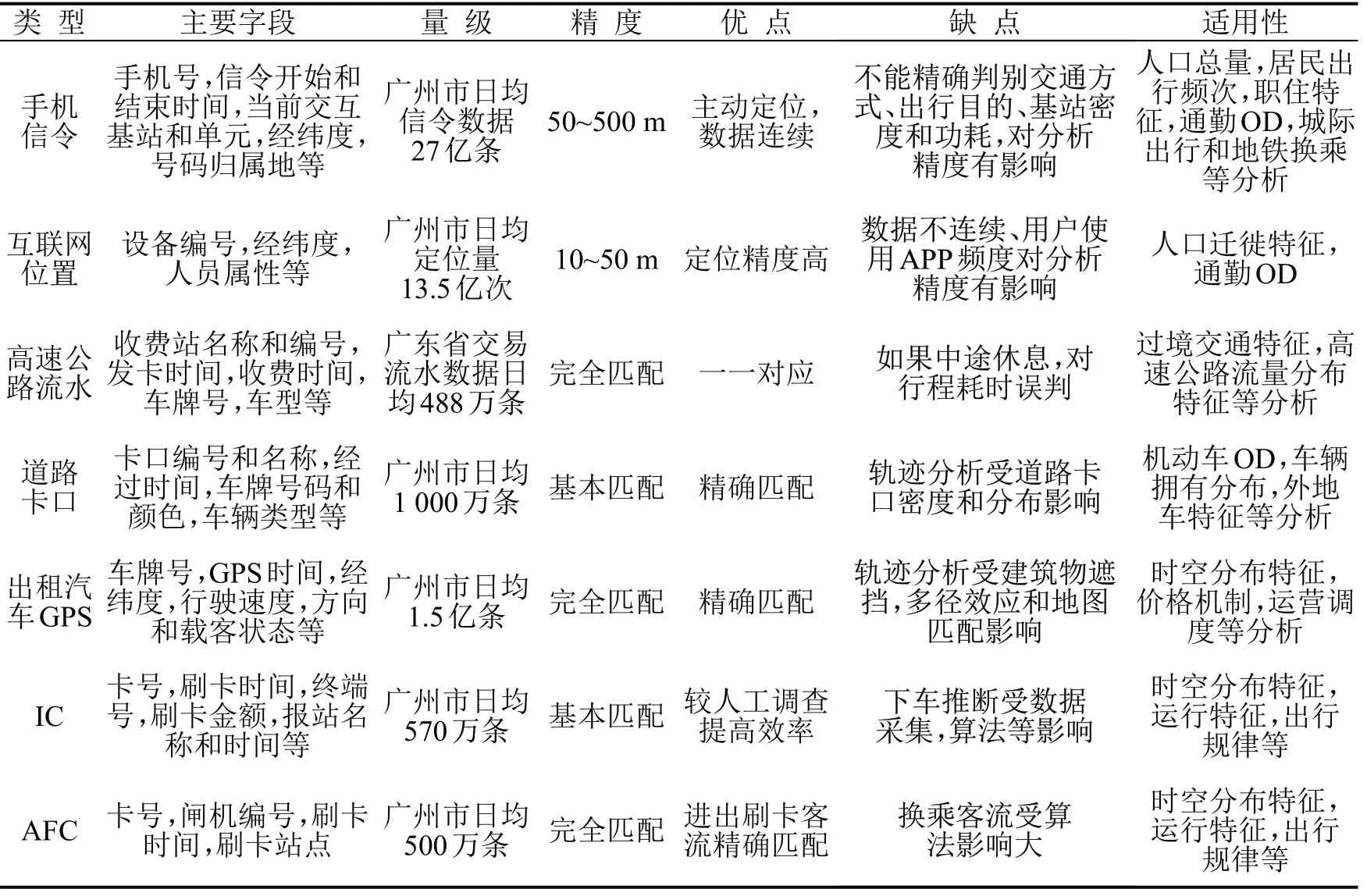
表1 交通大数据基本情况Table 1 Sorting out basic situation of traffic big data
2.1 出行频次分布校核
使用本文方法分析广州市居民出行特征.年龄构成方面:6岁以下样本数据因无出行导致调查比例很低(平均值为0.4%),较母体数据5.8%差距较大,扩样后数值(5.7%)与母体基本一致;[6, 60]岁样本数据和母体数据比例接近,扩样后趋势基本一致,达到扩样效果,如图4所示.职业结构差别较大的有两类职业:一是样本数据中公共管理、社会保障和组织人员所占比例偏高(7.7%),与母体数据2.2%相差5.5%,扩样后职业分布与母体数据基本一致;二是制造业(12.3%)和农林渔牧业(0.9%)比例偏低,与母体数据31.6%和7.4%差异较大,扩样后与母体数据结果一致;其他行业样本与母体数据差异不大,经扩样后其数据结果与母体数据更为吻合,如图5所示.组合扩样后,人口总量与行政区分布关系如下:越秀、荔湾、海珠等老城区,以及南沙、花都、增城等外围区,样本数据较母体数据均超过30%,其余行政区差值均低于22%;经组合扩样的结果与母体数据基本一致,如图6所示.
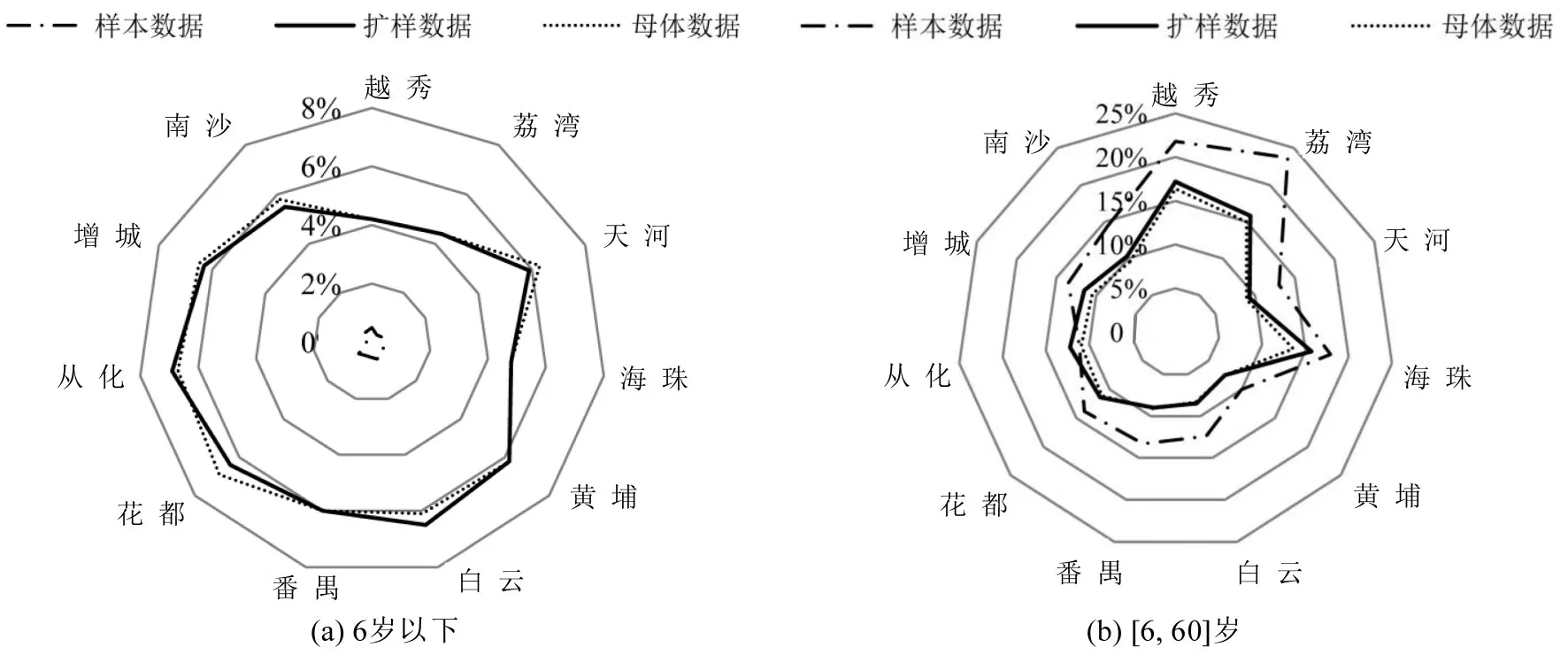
图4 抽样调查与扩样分析和母体数据的年龄结构分布差异Fig.4 Difference age structure and sample survey and actual data
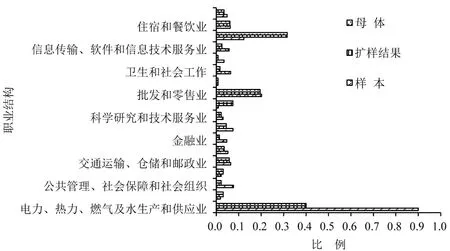
图5 抽样调查与扩样分析和母体数据的职业结构分布差异Fig.5 Difference between occupational structure distribution and sample survey and actual data
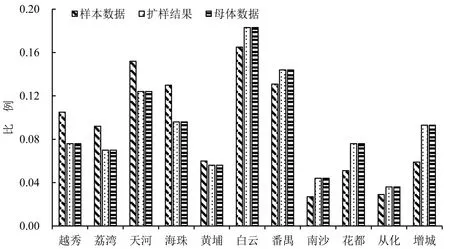
图6 抽样调查与扩样分析和母体数据的人口分布差异Fig.6 Difference between population expansion distribution and sample survey and actual data
传统抽样调查具有漏报、瞒报等情况,需要对出行频次分布进行修正.基于互联网位置信息的分析方法发现,抽样调查出行漏报率在29.5%;利用互联网位置跟踪居民出行轨迹信息分析发现,出行频次在2次/日出行比例为36.8%,低于抽样调查35.6 个百分点,3 次及/日以上出行比例43.7%,高于入户抽样调查17.9 个百分点.基于手机信令数据的分析方法,判断抽样调查出行漏报率在30.5%,2 次/日出行比例为32.9%,低于抽样调查39.6 个百分点,3 次/日及以上出行比例42.8%、高于抽样调查17个百分点.由此可见,基于互联网位置信息和手机信令数据两种方法出行频次分布规律较为一致,两种方法的沉默需求率约为30%,如图7所示.
2.2 出行时间分布校核
从居民出行时间分布来看,通勤出行(包含上下班和上下学出行)中基于手机信令数据和入户调查数据分析结果相似,两者呈现典型的“双峰”特征.其中,早高峰小时比例约为13%,晚高峰手机信令数据分析结果相对高1.5 个百分点且峰值时间后移1 h,如图8所示.非通勤出行中两者分析结果差异较大:样本调查早晚高峰出行峰值比基于手机信令数据分析的结果偏高,早高峰(07:00-09:00)高25.9个百分点,晚高峰(17:00-19:00)高25.9个百分点;平峰大部分时间段过低,这是因为入户调查中非刚性出行的漏报和瞒报使早晚高峰出行比例过高(早晚高峰分别相差25.5个和15.9个百分点),平峰和夜间出行比例过低的现象(00:00-06:00、09:00-16:00、19:00-23:00 分别相差6.6%、19.1%、15.4%).经扩样分析后结果与手机信令数据分析更为贴切,起到了“削峰填谷”的作用,如图9所示.

图7 入户抽样调查与基于互联网位置信息和手机信令数据分析的出行频次分布差异Fig.7 Travel frequency distribution difference baseon sample surveys and big data analysis
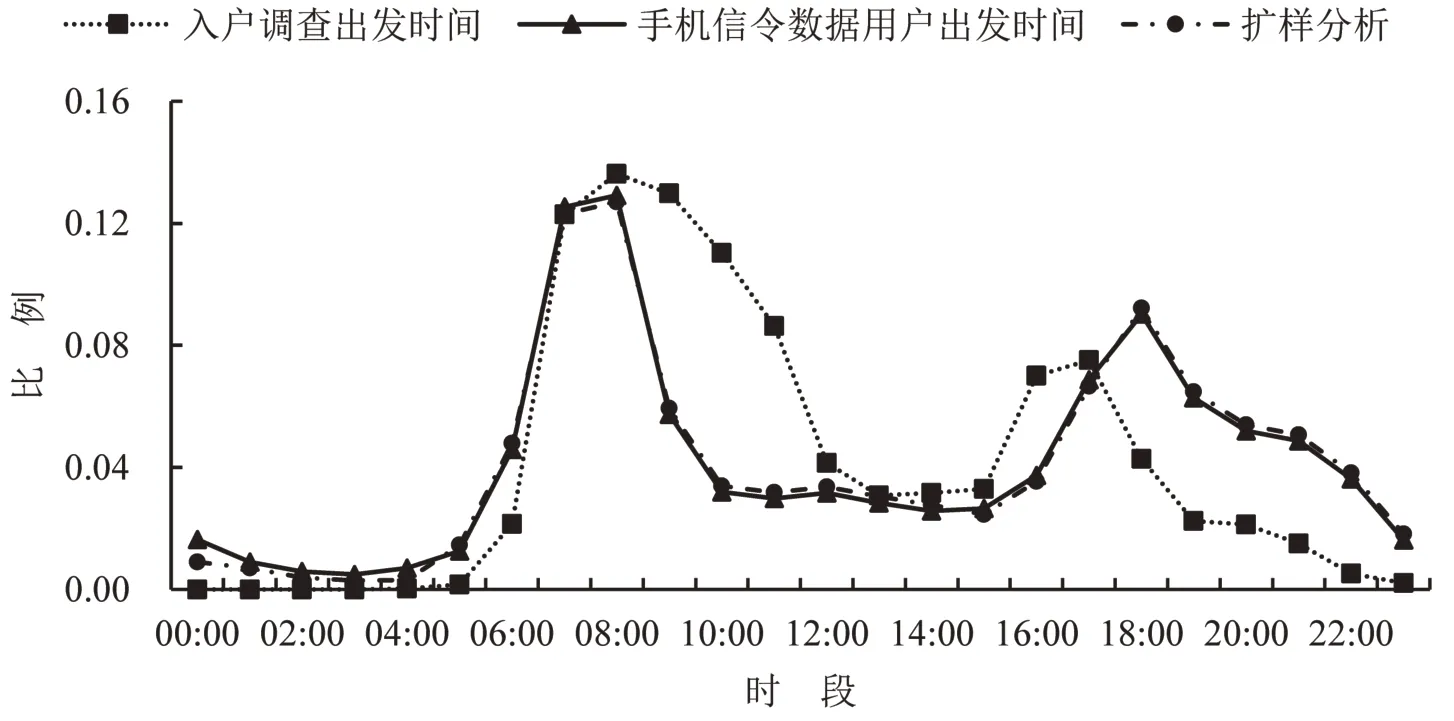
图8 抽样调查与手机信令数据分析、扩样分析的出行时间分布差异(通勤)Fig.8 Differences in travel time distribution between sample survey and mobile phone signaling data analysis and sample expansion analysis in commuter
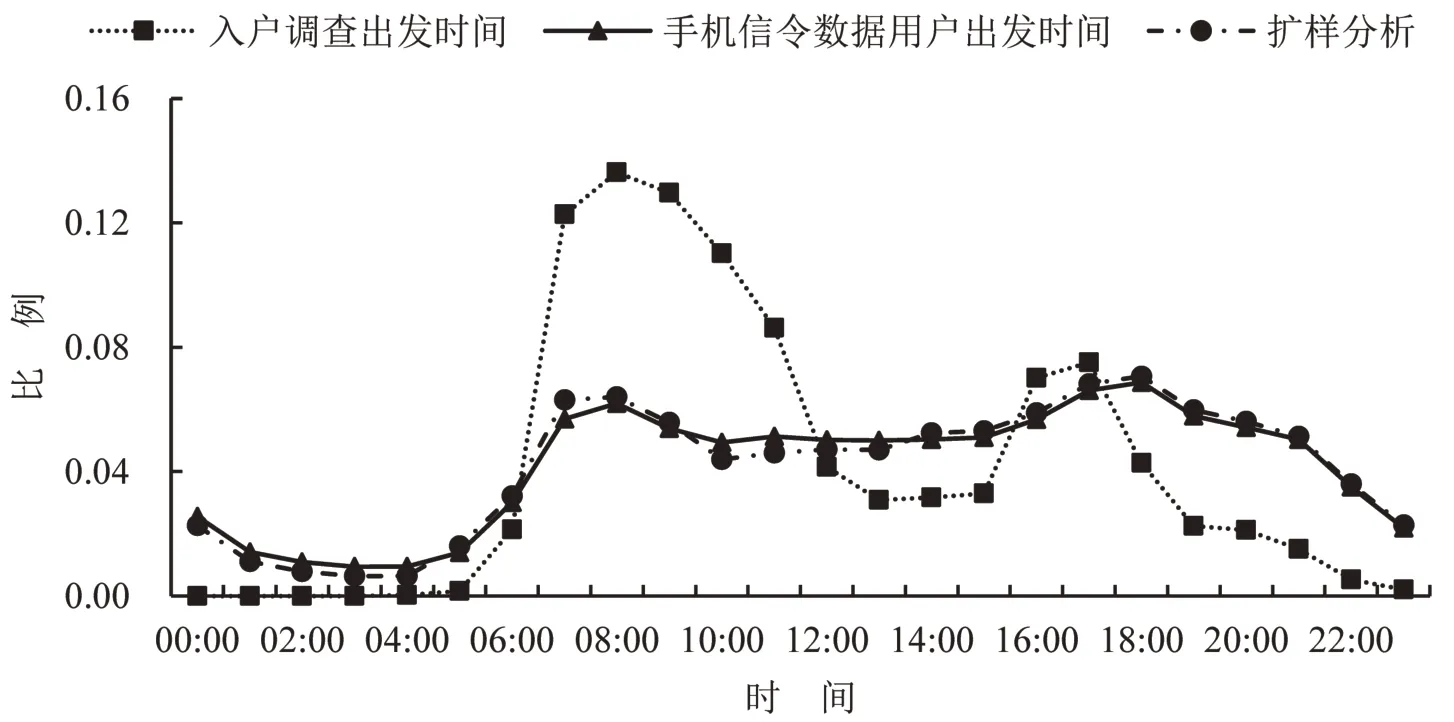
图9 抽样调查、手机信令数据分析和扩样分析的出行时间分布差异(非通勤)Fig.9 Differences in travel time distribution between sample survey and mobile phone signaling data analysis and sample expansion analysis innon-commuting
公共交通方面,样本调查中出行时间分布呈现高峰过高,平峰过低情况,与居民出行时间和手机信令数据分析结果相同.早高峰(07:00-09:00),公交和地铁样本调查数据分别比IC分析结果高出11%和16.4%;晚高峰(17:00-19:00),公交和地铁样本调查数据分别比IC 分析结果高出8.1%和12.6%;平峰和夜间时段,公交和地铁样本调查数据分别比IC分析结果低19.1%和29.0%.经扩样分析后,公共交通出行时间分布的高峰降低,平峰和夜间出行比例增大,起到“削峰填谷”的作用,与真实数据分析结果更为吻合,如图10和图11所示.

图10 样本调查和IC 数据分析的公交出行时间分布差异Fig.10 Differences in bus travel time distribution based on sample survey and IC data analysis
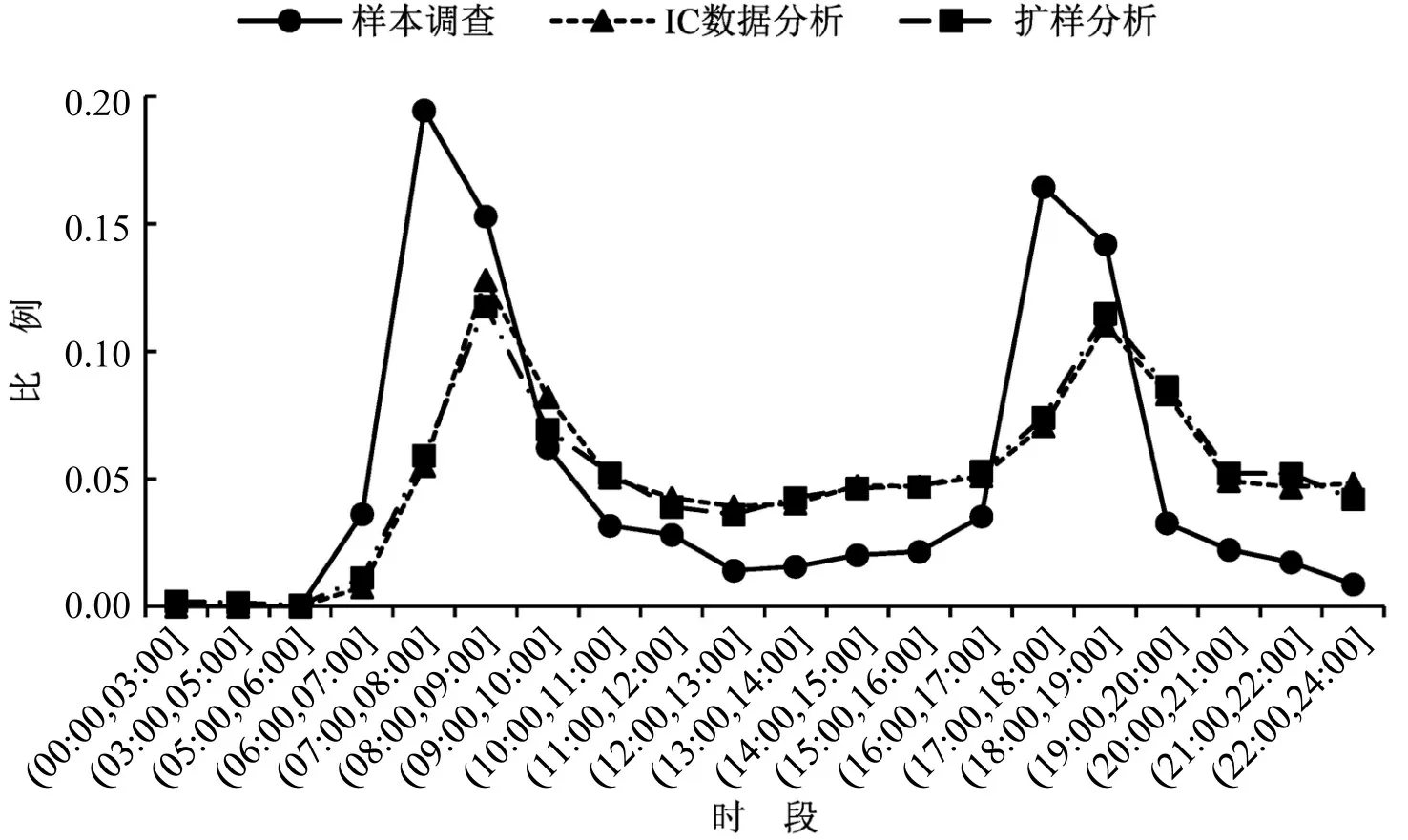
图11 样本调查和IC 数据分析的地铁出行时间分布差异Fig.11 Differences in metro travel time distribution based on sample survey and IC data analysis
3 结 论
大数据分析是通过连续数据和假设验证群体行为特征的过程,其数据分析由多到少,结论由杂到精,研判由表象到本质;小数据分析通过样本数据推演未来规律的过程,其数据分析由少到多,结论由已知到未知,研判由确定到不确定.本文基于传统入户调查数据分析,以及手机信令、IC、AFC、GPS 等大数据挖掘融合,提出基于多种数据源融合驱动的居民出行特征分析方法,实现了大小数据的融合.本文方法有效识别了居民出行因漏报和瞒报行为产生的30%沉默需求,合理地调整了居民出行频次和出行时间分布;与人工调查相比,居民出行频次为2次/日降低了39.5%,其他出行频次平均提高了5.1%,全方式非通勤出行比例降低了7.4%,晚高峰公交和地铁出行比例分别降低了8.1%和12.6%;对出行强度和时间分布起到削峰填谷作用,达到科学合理分析居民真实出行特征的目的,为后续交通规划和管理研究具有重要意义.本文多源数据融合方法仍是基于传统的“四阶段”交通规划理论进行分析,没有通过大数据系统分析居民的全过程出行,未来需要对居民的分段出行(包含出行活动链、目的链、方式链)进一步细化研究.
猜你喜欢
辽河(2021年10期)2021-11-12
铁路通信信号工程技术(2019年10期)2019-11-06
中国交通信息化(2019年2期)2019-03-25
消费导刊(2017年24期)2018-01-31
中国医药指南(2017年20期)2017-09-03
中国质量监管(2016年10期)2016-07-10
互联网天地(2016年2期)2016-05-04
中国当代医药(2015年20期)2015-03-01
中国当代医药(2015年8期)2015-03-01
火炸药学报(2014年1期)2014-03-20
