
基于Python 爬虫技术的QQ 空间说说的爬取
2020-10-30 05:49赵子钦
科学技术创新 2020年31期
赵子钦
(太原理工大学大数据学院,山西 太原030000)
随着互联网技术的发展,QQ 空间作为虚拟信息交流场所,愈来愈成为人们自我视界里广泛使用的一种社交工具。人们青睐于QQ 空间说说以文字语言形式记录生活点滴,抒发个人情怀,自我心迹表露,与朋友互动写留言,进行自我彰显,社会舆情传递等等,从而成为QQ 说说用户鲜活明亮的岁月留痕和见证成长的精神空间。随着时间的推移,用户说说条目不断增多,说说所涉及的范围也更加广袤,层级纷繁多样,内容也包罗万象。当人们想要在众多说说条目下找到某一条或某一类说说内容时,可能会比较困难。
大数据时代的到来和网络爬虫技术的应用,为采集和挖掘目标数据提供了可能并转化为现实。通过web 爬虫网络技术,把网页上的数据下载到本地数据库,从而方便对目标信息的查找和有效提取利用。结合Python 技术,可以实现对QQ 空间说说的爬取。
论文使用的平台是Anaconda3,浏览器为火狐浏览器:Mozilla Firefox-70 版本,浏览器驱动为:geckodriver-0.24.0 版本。通过selenium 库中的webdriver 实现从浏览器完全模拟人直接登录访问QQ 空间。针对登录产生的权限问题,使用webdriver中get_cookies()函数,将登录cookie 获取保存。然后通过cookie来构造一个session, 结合查看网页请求网址获取含有空间说说的网页。为了便于查看,可以通过json.loads()函数把内容转化为JS 格式。将抓取的网络页面形成队列,并通过对比发现每个网页地址特定参数的区别,确定循环对象,最后使用for 循环和while 循环把空间说说的内容爬取至本地。
1 相关技术分析
1.1 Python 网络爬虫原理
Python 是一种面向对象的计算机程序设计语言,内置有丰富的数据类型来表示函数、模块、对象、运行时的信息等,有着简单的说明文档,运行速度快,可用作图形、数字、文本处理,因此用Python 写简单爬虫获取数据库的信息,为人们在海量信息中获取目标内容提供更加方便快捷的功能。
网络爬虫属于一种自动检索工具,就是通过网络搜索主题,遍历网页内容,根据某个网站的分析算法和既定的抓取目标,过滤掉无关链接和大量用户不关心的网页,有选择的访问相关网页和相关链接,将其放置在一个队列被爬取,从而用户能够很方便的获取所需要的信息内容。
1.2 登录处理
1.2.1 处理登录表单
处理登录表单可以分为两步:第一步是分析网站的登录表单,构造具有POST 请求的参数字典。第二步是提交POST 请求。
1.2.2 处理cookies
爬取说说,首先要登录QQ 空间,为了避免每次爬取说说时需要登录这样的麻烦,可以利用seesion 保存的cookies 信息。
1.3 动态网页爬取
真实地址爬取:尽管数据没有出现在网页源代码中,但可以找到数据的真实地址,请求得到真实地址可以获得想要的数据。这里用到浏览器“查看元素”的功能。
步骤:(1)将QQ 空间登陆页面网址在Firefox 浏览器打开,右击页面,点击“查看元素”,打开开发者工具。(2)找到真实的数据地址。点击开发者工具页面窗口,选择“网络”选项,刷新页面。这时,“网络”会显示浏览器从Web 服务器获取的所有文件,目标数据就在其中。(3)爬取真实说说数据地址。获取了地址,继而使用requests 请求网页,获取网页地址中的数据。(4)一般获得的结果较为复杂,这些是JS 数据,我们可以使用json 库解析数据,从中提取想要的数据。
1.4 Session
这里最重要的一个变量是requests 库的Session 函数,可以帮助我们维持一个会话,还可以自动处理Cookies,令我们不再担心cookies 问题。
2 爬虫模型的设计
2.1 库的导入与变量赋值
2.1.1 导入模型所需库:json、requests、selenium 中的webdriver。导入程序如图1 所示:

图1 导入库
2.1.2 先将qq 账号和密码分别赋予变量user、pw。程序如图2 所示:

图2 变量赋值
2.2 模拟登录的实现
2.2.1 为了实现浏览器模拟登录,先转到QQ 空间登录页面,driver = webdriver.Firefox(),driver.get(“http://i.qq.com”),右击,选择登录框,driver.switch_to.frame(“login_frame”)。选择登录框、获取登录框位置如图3 所示:
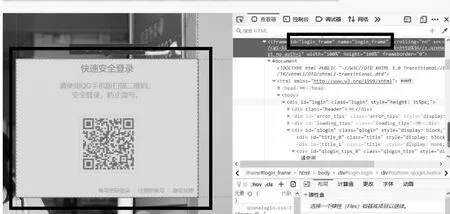
图3 寻找登录框
2.2.2 模拟浏览器点击选择到“账号密码登录”,driver.find_element_by_id(“switcher_plogin”).click()。选择账号密码登录如图4 所示:
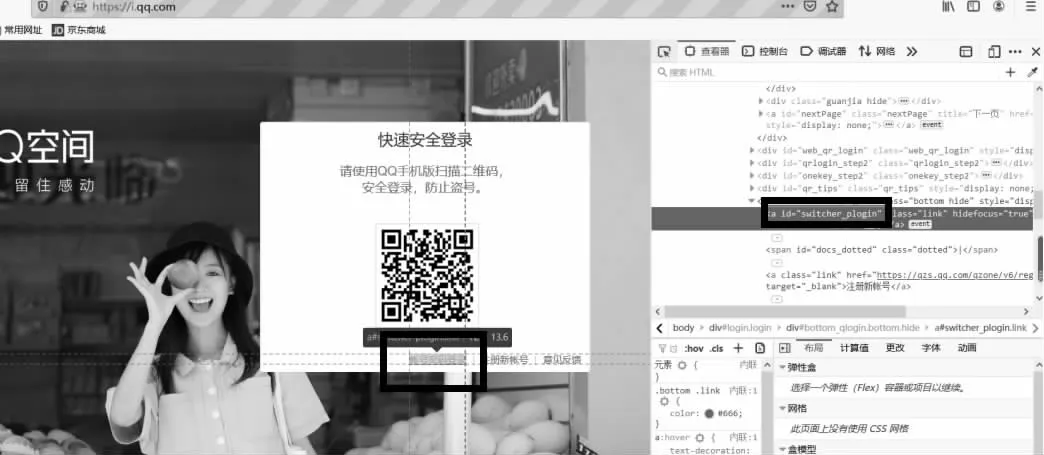
图4 选择账号密码登录框
2.2.3 选择点击填写账号(密码)框,并将qq 账号(user)、密码(pw)填写进去,driver.find_element_by_id(“u”).send_keys(user)driver.find_element_by_id(“p”).send_keys(pw)。填写结果如图5、图6 所示:

图5 选择输入账号框

图6 输入密码框
2.2.4 点击登录按钮进行登录(手动验证)driver.find_element_by_id(“login_button”).click()。选择点击登录按钮框如图7 所示:
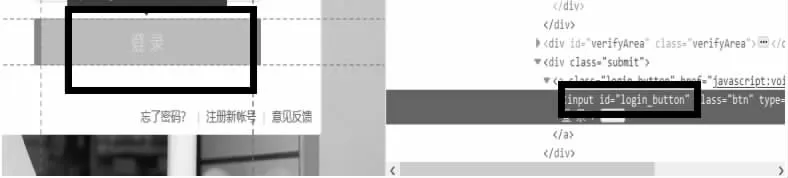
图7 登录框
2.3 cookies 及真实地址的获取
2.3.1 登录成功之后,使用selenium 得到cookies,并将其保存至“cookies.txt”文件。函数代码如图8 所示:
2.3.2 登录到主页后,为了获取到说说页面的真实地址,查看页面“查看元素”,观察网络栏,由于第一页内容含有其他元素,不易查找,所以,下拉动态加载完毕后,将网络中请求网址全部清空。之后再点击说说的“第二页”,“网络”中出现的第一个请求网址即为说说的真实网址。获取到真实地址如图9 所示:
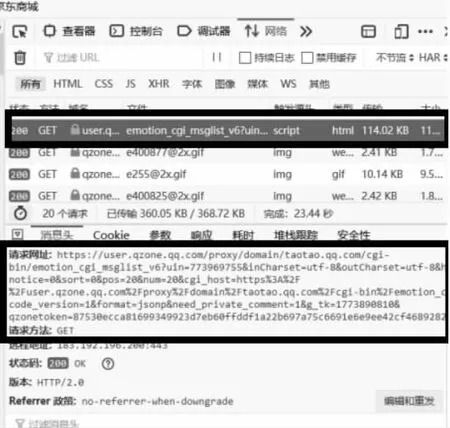
图9 获取到真实地址
2.4 免密登录及处理分析数据
2.4.1 将真实网址在浏览器中打开,分析后可知所需数据的范围为[10:-2]。如图10 所示:

图10 黑框部分不做选取
2.4.2 为了实现说说的真实网址的免密登录,定义此函数,利用保存的cookies 使其返回一个赋予cookies 的JS 对象的网页。函数代码如图11 所示:

图11 免密登录函数
2.4.3 利用获取真实地址的方法,得到第三页的网址。比较两个真实网址,发现“pos”的值不同,第二页中的pos 值为20,第三页为40......由此可知,第一页pos 值为0,每翻一页,pos 值自增20。所以可以将得到的真实网址url 分解为2 部分:
url_1 = 'https://user.qzone.qq.com......&pos='
url_2 = '&num=20&c......282c2d39d'
通过循环可以循环遍历到每一页。
使用json.loads()函数,进行查看,可以得知,每条说说的的信息都在'msglist'中,其中,说说内容为“content”,发表时间为“creatTime”。内容的信息如图12 所示:
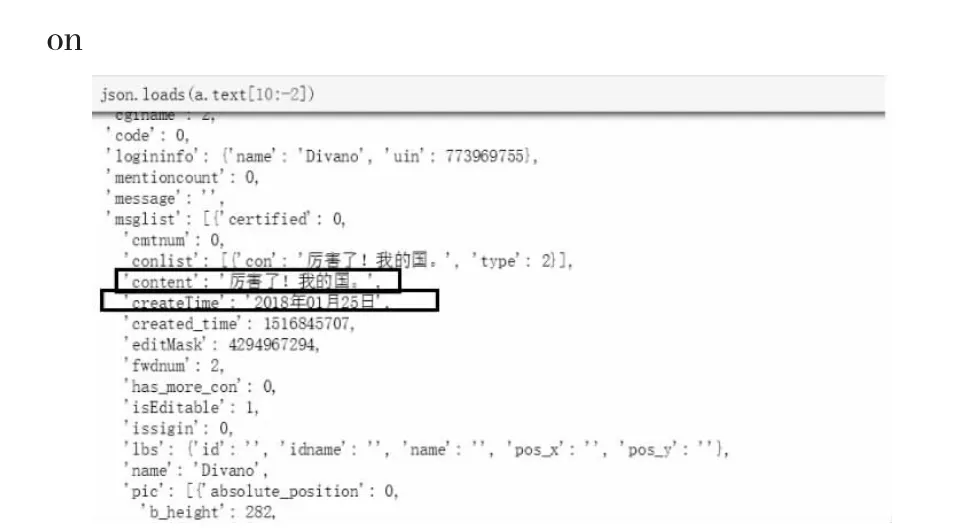
图12 JS 信息
现在需要讨论何时终止循环,不难发现,当pos 的值超出可读取的网页时,'msglist'=None。
由此,'msglist' = none 作为停止循环的条件是可行的。如图13 所示:
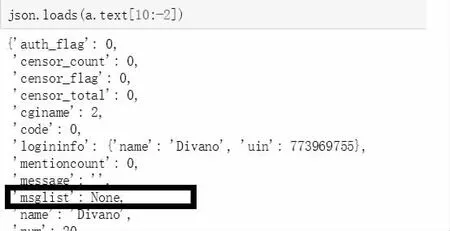
图13 停止循环条件
2.5 信息的爬取
定义函数,遍历输出每一页说说的内容,当‘msglist’为空时,返回‘1’,不为空时,将其中的内容“content”,发表时间“creatTime”打印输出到文件,并返回‘0’。函数代码如图14 所示:
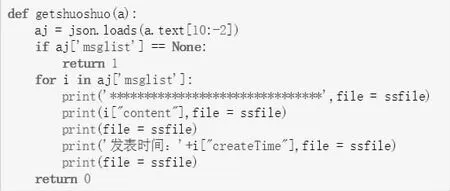
图14 定义获取说说函数
调用上述函数,函数返回“1”时,停止循环,返回'0'时,进行“翻页”操作。当所有操作完成后,打印出“Down”,表明程序运行结束。如图15 所示:
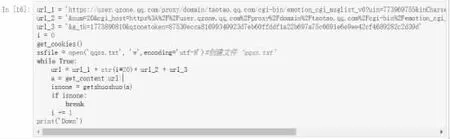
图15 程序代码
3 程序运行结果
依次运行程序后,见到打印出的“Down”。如图16 所示:
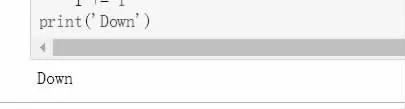
图16 运行完毕
最后,打开在python 工作目录中生成的“qqss.txt”文件,可以看到爬取的说说内容及发表时间。如图17 所示:
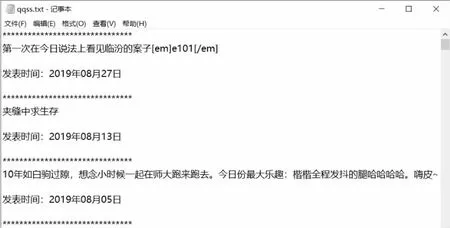
图17 爬取结果
4 结论
利用Python 语言进行爬虫程序设计是大数据时代下实现数据采集的重要渠道。本文以爬取QQ 空间说说为例,介绍了一种爬取说说数据的爬虫程序设计,为用户对说说条目进行聚类、筛选或获得目标数据提供便利。设计过程中对于满足用户,快速访问的QQ 空间问题仍有进一步改进空间。例如:在实现模拟登录时,需要人工手动拖拽拼图验证,这样无法彻底实现自动化验证码识别,速度较慢。可以采用设置被拖拽拼图的CSS 属性或模拟拖动的方法,全程自动化无需人工参与进而提升爬取速度。同样,还可以利用此技术在互联网络爬取其他目标数据,缩短查询信息的时间,获取相关有价值数据,提高工作效率。
猜你喜欢
中国中西医结合皮肤性病学杂志(2022年2期)2022-11-25
房地产导刊(2022年10期)2022-10-18
中华肩肘外科电子杂志(2021年2期)2021-11-30
现代信息科技(2021年21期)2021-05-07
电脑爱好者(2019年5期)2019-10-30
中国计算机报(2019年12期)2019-06-21
电子制作(2019年10期)2019-06-17
电子制作(2018年2期)2018-04-18
电子制作(2017年9期)2017-04-17
软件(2017年1期)2017-02-27
