
具有关系敏感嵌入的知识库错误检测
2020-10-28 04:53:00杨昕悦
网络安全与数据管理 2020年10期
缪 琦,杨昕悦
(辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105)
0 引言
如今,知识库已经成为各种研究和应用越来越重要的和常用的数据源,如语义搜索、实体链接、问答系统和自然语言处理等。为了使庞大数据库更易于操作,研究者提出了一种新的研究方向——知识库嵌入。 关键思想是嵌入 KB(Knowledge Base)组件,包括将实体和关系转化为连续的向量空间,从而简化操作,同时保留 KB 原有的结构。 实体和关系嵌入能进一步应用于各种任务中,如KB 补全、关系提取、实体分类和实体解析。 虽然庞大的知识库中有数以亿计的事实,但是在信息爆炸的时代远远不够。 大部分的研究工作聚焦知识库对缺失边的扩充,很少有人考虑到其中过时的、不正确的信息[1-3]。许多扩充知识库研究将事实投射到k 维向量空间,通过聚类来找到关系的相关性,很难实现高效有效处理。
1 关系敏感知识库错误检测
知识库错误的检测仍然是一个艰巨的挑战:(1)知识库的知识具有离散性,因此通过传统嵌入方法[4-6]难以在知识库中进行广泛推理和检测;(2)知识库中的关系几乎没有上下文可以捕获其语义的相关性,所以大部分著作都是对实体和实体进行研究,忽略了关系和关系之间的相关性;(3)对于纠错大部分是建立在实体-实体或者建立在字符成本上的。
为了解决上述挑战,提出嵌入一个新颖简单的关系敏感方法(NSIL),该函数由 RSEA[7]方法的思想启发产生,但是性能更高。 该函数计算了主体与客体之间的相关性,能在大规模的知识库中准确地对三元组进行识别和错误检查,并且对纠正三元组的错误具有较高精准性。
图1 中,对于关系“家人近期病史”,可以对应的不同主体是离散的,主体可以是“市民 A”、“市民B”等,客体也是离散的,可以是“SARS-COV 病毒”、“COVID-19 病毒”等,彼此之间没有必然的关系。但是对于关系对而言,它们会产生局部相交,如同对于三元组(“市民 A”,“患病”,“COVID-19 病毒(Corona Virus Disease 2019)”)和(“市民 A”,“家人近期病史”,“COVID-19 病毒”)之间,它们不仅有相同的主体集合(“市民 A”)和客体集合(“COVID-19 病毒”),而且有与“家人近期病史”和“患病”的主体和客体都有内在直接关系的共同实体“市民C”,即“市民 A”的“客体”,“COVID-19 病毒”的“主体”。于是认为关系“家人近期病史”和“患病”相关。 从关系的主客体集合和与主客体关联的实体集出发,使得发现关系之间的相关性具有可能。就像上文中说的那样,如果在一定程度上认定“家人近期病史”≈“患病”,那么对于三元组(“市民 B”,“家人近期病史”,“SARS-COV 病毒(SARS-associated coronavirus)”),可以得出市民 B 最可能患病的事实是SARS-COV 病毒。 如果认定“市民 B 有家人近期病史是 SARS-COV 病毒”, 如果给了需要判定的三元组是(“市民 B”,“患病”,“COVID-19 病 毒 ”),那 么 会 判断它是错的。 如果它的客体需要纠正,它最有可能被纠正为“SARS-COV 病毒”。
本文提出了一种新的关系敏感函数NSIL,该方法从关系的角度出发,能有效识别关系库中关系的相关性,该关系在多对多、一对一、一对多、多对一的实体中具有不错的识别效率。
2 知识库嵌入技术的发展
近来,提出了许多知识库嵌入技术来将离散知识图编码为连续向量空间。 首先介绍一些常用的符号 。知识库中的事实三元组(h,r,t),即 (主 体 ,关系,客体)。 其对应关系的矢量表示表示为(h,r,t),分数函数f(h,t)对于属于知识库的正三元组将自动获得较高的分数,而对于负三元组[8]将自动生成较低的分数。
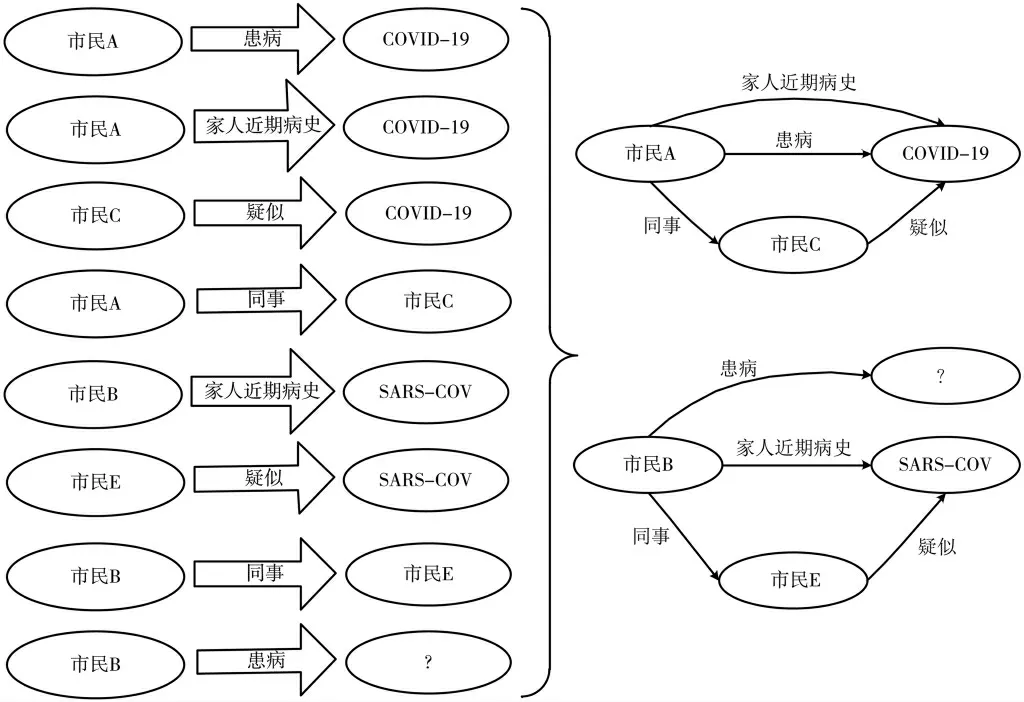
图1
表1 为在相同的 k 维嵌入空间Rk×k中,得分函数、参数数量和时间复杂度的模型比较。

表1 模型比较
(1)TransE[9]:TransE 是基于实体和关系的分布式向量表示,由 Bordes 等人于 2013 年提出,受 word2vec启发,利用了词向量的平移不变现象。例如:C(king)_C(queen)≈C(man)_C(woman)。 其中,C(w)就是 word2vec学习到的词向量表示。 TransE 定义了一个距离函数d(h+r,t),它用来衡量 h+r 和 t 之间的距离。
(2)TransH[10]:为了解决TransE 在面对自反关系,以及多对一、一对多、多对多关系的不足,2014 年WANG Z 等[10]提出了 TransH 模型,其核心思想是对每一个关系定义一个超平面Wr和一个关系向量dr。 h⊥、t⊥h 是 h、t 在 Wr上的投影,这里要求正确的三元组需要满足 hr+dr=tr。 这样能够使得同一个实体在不同关系中的意义不同,同时不同实体在同一关系中的意义也可以相同。
(3)TransR[11]:TransR 是 在 TranE的基础上的改进,在数学上的描述看起来会更加直观:对于每一类关系,不光有一个向量r 来描述它自身,还有一个映射矩阵Mr来描述这个关系所处的关系空间,即对于一个三元组(h,r,t),需要满足 d(h,r,t)=TransR 等方法无法很好地解决非一对一关系,而且受限于知识图谱的数据稀疏问题。
(4) 其他方法。 2019 年 9 月 由KIM S 提出一种基于概率的知识库的新型检测方法, 也是通过研究关系与关系之间的相关性来检错,其主要算法是通过计算两个关系的共同前后节点关系和各个节点的前后关系来得到相关性的。 本文受该方法启发,但是准确率更高。
3 基于NSIL 函数的知识库错误检测方法总览
本节主要介绍知识库的基本模型,给出问题定义和工作流程。
3.1 知识库
知识库的常用表现形式是 RDF , 以(subject ,predicate,object)的三元组形式表示实体之间的许多复杂联系。
3.2 问题描述
正如前文介绍的那样,知识库中有很多过时的不正确的事实,但是大量的研究都在不断发现知识库中缺失的边来填充缺失的成分而忽略了对错误事实的检测。 因此,旨在利用关系(谓词)之间的关联性来对不断扩充的知识库进行准确的错误检测。
定义 1关系关联:在给定知识库 KB 中将各关系(谓词)通过关系函数关联到同一个组别。
定义 2检测错误:在给定的知识库 KB 中将找到最不可能的事实三元组 F,F 可能是放错的边或者客体或者主体。
定义3缺失三元组: 在给定的知识库中对缺失的三元组(客体或者主体缺失)进行预测缺失的实体。
定义4可信三元组: 忽略落单的①谓词②主体,客体。
3.3 工作流程
如图2 所示,工作流程主要有三个部分:给定KB,然后通过相关函数来测定各个三元组中关系的关联程度,得到关系间相关性分值并进行划分,最后给定一个知识库,找到其中最不可能的事实三元组,即通过NSIL 判定的错误事实,对于判定的错误事实,进行预测三元组客体与主体。
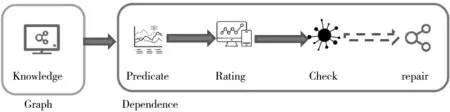
图2 NSIL 方法工作流程
4 NSIL 关系相关函数
在直觉上,如果两个关系在知识库中拥有更多关联的共同节点(即与主体的关联节点,与主体和客体关联的节点),那么两个关系相关性也越高。 在图1 的例子中,对于关系“市民 C”和“患病”,它们都有共同的关联性实例“市民 C”,即它们的主体都能够通过另一个相同的实例“市民C”和它们的客体相连接,并且都拥有两个相同的实例“市民 A”和“COVID-19 病毒”。 如果两个关系之间共性越多,就越相信这两个关系相关。
4.1 函数算法
首先介绍符号:H(ri)表示 ri主体作为客体时其前置主体的集合,R(ri)表示对于事实三元组(hi,ri,ti)的事实三元组(hj,rj,tj)的集合,其中存在关系 rx、ry构成事实三元组(hi,rx,hj)、(tj,rx,ti),将该三元称为伴生三元组。
两个关系的关联前置主体集合:

两个关系共同的关联的伴生三元组:

直接关联集合是两个联系相同的直接关联的主体-客体集合:
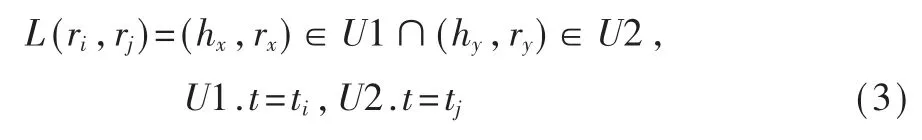
定义 SIL 分数函数:
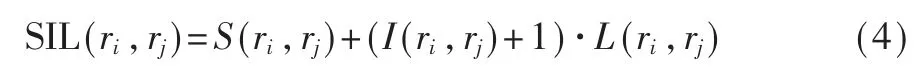
归一化[12]:
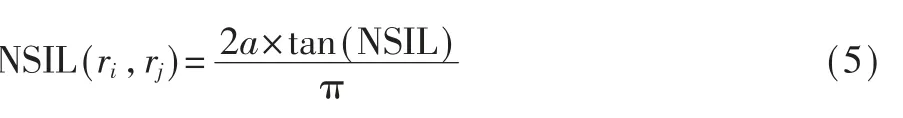
4.2 NSIL 应用示例
对于图1:如果加上三元组(“野味市场”,“逗留过”,“市民 A”),那么对于“家人近期病史”和“患病”就有共同的前置节点 S(“家人近期病史”,“患病”)={“野味市场”},共同伴生三元组为 I(“家人近期病史”,“患病”)={“市民 C”},直接关系集合为 L(“家人近期病史”,“患病”)={(“市民 A”,“COVID-19病毒”)},所以:而对于关系“同事”和“患病”,可见“家人近期病史”比“有同事”对于“患病”的相关性更高,对“患病”的影响力更大。 如果一个人家人近期病史为MERS病毒(Middle East Respiratory Syndrome Coronavirus),那么从他的家人近期病史出发推测出他很有可能患上了 MERS。
5 实验
5.1 实验环境
(1)数据集:在实验中,采用了一个基准数据集,即从 Freebase[13]生成的 “FB15K”。 Freebase 是最大的知识库之一,对应用户构建的现实真实情况如表2所示。

表2 基准数据集的详细信息
(2)评估:对于两个数据集进行广泛的错误检测和预测纠错。 错误检测将用最新的算法与 NSIR 判断三元组(h,r,t)对错,比较其性能。 预测纠错则会用缺失的三元组,即主体或者客体残缺的三元组来进行预测缺失部分。
5.2 实验指标
(1)指标:通过相关得分排名列表,汇总总体测试采用两个评估指标:①Hits@10:排名前十位的实体中判断正确实体的比例,如图3 所示;②平均等级:正确实体的平均正确率。
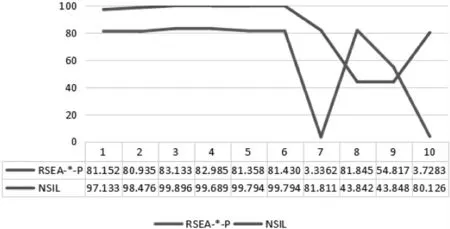
图3 Hits@10 各排名对应训练集中准确率
(2)准确率认定:
①公式

表示实体排名前 N 个的平均准确率,R 是给定的与前N 个实体相关的三元组的总个数, 破坏给定三元组的主体或客体,然后对各个三元组的真假性进行判断,δ 是对三元组真假性判断正确的个数。
②对于错误检测的准确率,遵循Hits@10 原则,即N=10。
③对于预测纠错的准确率,N 单独地作为横坐标,N=1~10。
5.3 实验结论
5.3.1 错误检测
对于每一个和其他三元组有纠集联系的关系,都会有一个和其他关系的相关得分,得分低的会被划分为独立关系,得分高的为高相关性关系。 对于FB15K 的错误检测的评估在图4 中示出。 在FB15K上错误检测性能最好的是NSIL, 准确率高达88.5%。 在实验中发现随着实体相关性排名的降低,预测精度出现不稳定与下降,另外对于NSIL 得分有着高分段密集的缺点(见表3),这些问题会将在未来的研究内进行克服与探讨。

图4 在数据集FB15K 上的实验结果
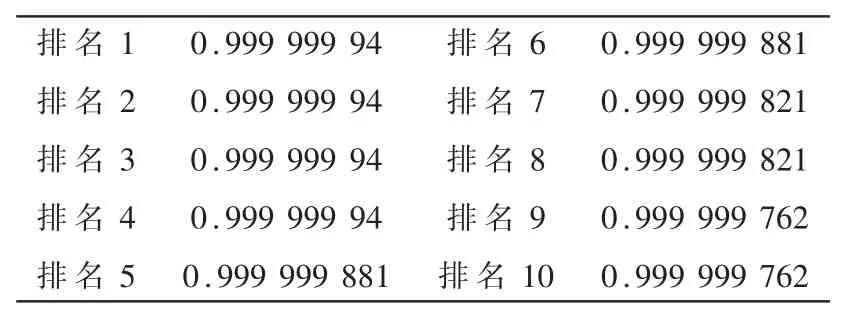
表4 NSIL 得分 Hits@10
5.3.2 预测纠错
在知识库中,也会出现缺失主体或者客体的情况。于是对识别出来的残缺相关实体进行主客体的预测,将预测值和真实值比较,从而判断预测纠错的性能。 从实体前两名的平均情况、前三名的平均情况, 到前十名的平均准确率情况如图4 所示。Hits@10 的准确率达到了 87.5%。 从实验看出,虽然预测纠错有很高的性能,但是其在非一对一关系问题上有着其局限性。
6 结束语
在本文中, 提出了一种关系敏感函数 NSIL,用于知识库的错误检测,并且对知识库残缺三元组进行纠错修复。 实验表明,该模型不仅可以有效地对知识库中的残缺三元组进行预测纠错,而且在大型知识库Freebase 数据集上的错误检测均优于现模型。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
中国毕业后医学教育(2021年2期)2021-12-06 06:09:20
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
中国毕业后医学教育(2020年6期)2020-12-06 07:30:02
智能计算机与应用(2019年4期)2019-09-12 10:41:42
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
制造技术与机床(2019年6期)2019-06-25 10:17:46
中国卫生(2016年9期)2016-11-12 13:28:06
中国交通信息化(2016年9期)2016-06-06 07:42:23
图书馆研究(2015年5期)2015-12-07 04:05:48
