
基于云平台的压砖设备健康状态分析方法设计*
2020-10-28 04:53:04李晓昌徐哲壮谢仁栩王宏飞夏玉雄
网络安全与数据管理 2020年10期
李晓昌 ,徐哲壮 ,谢仁栩 ,王 毅 ,刘 兴 ,王宏飞 ,夏玉雄
(1.福州大学 电气工程与自动化学院,福建 福州 350108;2.福建华鼎智造技术有限公司,福建 福州350003)
0 引言
工业设备的健康状态对于生产流程的稳定性与可靠性具有重要作用,单个设备故障会导致整条生产线停产,造成巨大的经济损失。 因此,基于运行数据对工业设备健康状态进行分析,对于降低设备故障率、提升产品质量具有重要意义[1-3]。目前我国压砖产业已具备较大规模,新型压砖设备已能够通过工业物联网模块采集设备运行数据。但现有数据主要限于售后维护时使用,大量实时累计的运行数据并没有得到有效利用。 另一方面, 现有数据分析方案大多仍局限于离线人工分析,实时性差且推广效率低。 因此,利用云平台[4-5]和机器学习技术[6-7]对设备健康状态进行在线分析已成为迫切需求[8]。
针对上述需求,本文基于阿里云机器学习平台设计了压砖设备健康状态分析方法,构建了压砖设备数据聚类分析模型,在无需专家先验知识的情况下,完成了压砖设备的工作、待机、异常等健康状态的建模。 进一步地,通过将训练好的压砖设备健康状态模型部署至 DataWorks 平台, 同时周期性地从保存压砖设备实时运行数据的MySQL 数据库导出数据至该平台进行分析计算,实现了对压砖设备健康状态的在线分析。 最后,本文通过实例证明了该方法的有效性。
1 压砖设备数据说明
压砖设备数据来自福建某压砖设备公司的设备监测平台,该平台通过工业物联网模块连接压砖设备生产线与本地服务器,实时采集压砖设备的数据至 MySQL 数据库中。 每个制砖周期中都包含启动、振动压砖、待机等过程。 在压砖过程中,需要通过两台振动电机的同步振动,才能保证压砖过程完成后砖块密度紧实。 如果频繁出现振动电机振动不同步,则会导致电机故障、设备损坏、压砖成品均为无效等问题。
MySQL 数据库上存储的压砖设备数据中包含多个变量,涵盖了压砖设备振动电机1 电流、振动电机2 电流、油泵电流、三相电压等多个维度。本文分析所用数据的时间跨度从2017 年12 月初到2018 年10 月中旬,包含有近 600 万条压砖设备的运行状态记录。
2 基于云平台的压砖设备健康状态数据分析
本文采用阿里云机器学习平台PAI(Platform of Artificial Intelligence)对压砖设备数据进行分析。 压砖设备健康状态的数据分析流程主要由导入数据、数据预处理、特征分析、聚类分析和模型评估5 个步骤组成,具体内容如下。
2.1 数据导入与预处理
在进入PAI 平台并选择新建试验后,可以通过读数据表插件将离线数据加载到数据分析模块中。实时在线导入数据将在下文第3.2 节详细介绍。
数据预处理主要分为删除缺失值、异常值处理、数据离散化、归一化处理等。 在本文所获取的压砖设备数据中,存在数据的畸变值、缺失值等问题,会增加算法模型的复杂度,严重影响数据分析的精准性。 本文采用了PAI 平台的过滤与映射组件、缺失值填充组件,能够根据设置参数自动对数据集的成分进行筛选,处理掉缺失值与异常值。
2.2 特征分析
将数据导入平台的数据集中,包含有振动电机电流、三相电压、油泵电流等各种特征量。 利用PAI平台的统计分析模块先对输入数据集中数据情况进行简单的统计分析,利用皮尔森系数分析各特征之间的相关性,在保证数据具有完整解释性的情况下,再对数据特征量进行筛选,有助于降低分析的复杂度。
(1)统计分析
数据预处理完成后,通过全表统计组件对压砖设备数据进行统计分析,得到了初始数据量为1 437 148(行)×6(列)的矩阵。具体各变量统计区间如下:时间跨度(time)从 2017 年 12 月初到 2018 年10 月中旬;振动电机 1 电流(i1,单位 A)的范围为[0,38.7];振动电机2电流 (i2, 单 位 A) 的 范 围 为[0,39.1];油泵电流(oil_pump,单位 A)的范围为[0.1,114.4];三相电压(voltage,单位 V)的范围为[2,816]。
(2)皮尔森相关性分析
通过给定压砖设备数据矩阵X,计算X 中两个特征列 i 和 j 的皮尔逊积矩(样本)相关系数的公式如式(1)所示:
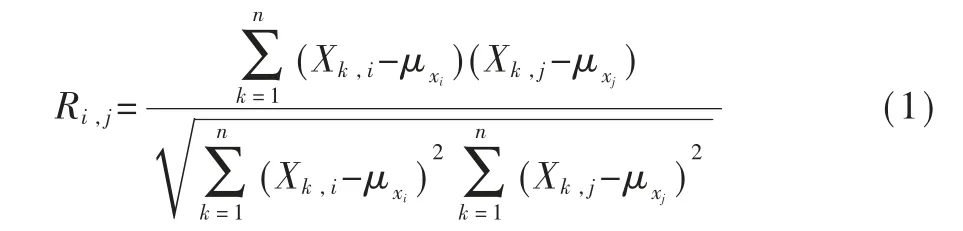
其中,k为变量,n为X的总行数 ,μxi为 i 列数据的标准差,μxj
为j列数据的标准差。Ri,j值的范围为[1,-1]。其中,1表示具有强的正线性关系,-1表示具有强的负线性相关,0 表示两变量之间没有线性关系。 系数绝对值越趋于1,相关性越大。
对压砖设备数据集i1、i2、oil_pump、voltage 四 个特征列进行相关性分析,得到如表1 所示结果。 由此可知,振动电机 1 电流变化情况与振动电机 2 电流变化情况基本一致,其相关系数约为0.998,结合压砖设备的工艺特性可知,设备在制砖过程中需要两台振动电机的振动情况保持一致,这也是两者相关性大的主要原因。

表1 原始数据的皮尔森相关系数
根 据 |Ri,j|>0.8确定两数据量为强相关性的规则,结合砖机特征量的皮尔森相关系数表将线性相关性较强的数据特征量进行剔除,只保留i1,但是又因为要通过振动电流的变化情况来判断电机的运行情况,因此本文通过特征之间的变换来创造特征量。
通过以上分析,最终确定了振动电机1 电流(i1)、电流差(i_dif)、三相电压(voltage)三个特征量来进行模型训练。
2.3 聚类分析
由于缺乏先验知识,在压砖设备上获取的数据是无标签的数据,因此本文采用K-means 聚类算法对其进行分析处理[9-10]。 PAI 平台提供以多种距离的远近作为相似度测量值,包括euclidean 距离、cosine距离、cityblock 距离等,它通过不断迭代求得与初始聚类中心点的最优分类,使得评价指标达到预期。
本文采用欧式距离(euclidean 距离)算法,计算各特征量与中心点之间的距离:

设 D={x1,x2,…,xm}为压砖设备数据样本集,其中包含m 个未知运行状态的压砖设备数据特征。每个压砖数据样本 xi=(xi1,xi2,…,xin)是一个 n 维特征向量, 则聚类样本集 D 划分为 k 个不相交的类别{Cl|l=1,2,…,k},其 中 Cl′∩l′≠lCl=Ø 且相应地,用λi∈{1,2,…,k}表 示 样 本 xi的 “ 类 标记”,即 xi∈Cλi。 于是聚类的结果可用包含 m 个元素的类标记向量 λ=(λ1;λ2;…;λm)表示。 聚类完成后可保存模型,加载至DataWorks 中的算法节点实现在线数据分析,具体将在第3 节进行介绍。
2.4 模型评估
本文采用Calinski-Harabasz(CH)指标作为聚类模型的评估指标。 CH 指标又称方差比率准则(Variance Ratio Criterion,VRC),其定义为:

其中,SSB是整个聚类间的方差,SSW是整个聚类内的方差,N 是记录总数,k 是聚类中心点个数,mi是聚类 i 的中心点,m 是输入数据的均值,x 是数据点,ci是第 i 个聚类。
由式(3)可得,聚类簇间区分度大,聚类簇内区分度小,因此可得 VRC 的值应越大越好。 通过设定不同 k 值(聚类簇的数目)进行实验,得到了不同 k值下的 CH 指标值,如图1 所示。 可以看到,不同 k值下CH 指标值变化波动性较大,不容易确定k 的具体取值。 因此将 CH 指标值较大对应 k 值(k=12,16,21)的特征中心点结果导出,并结合压砖设备的工艺特性与 k 值尽可能小的原则,最终选定 k=16 作为聚类数量。

图1 CH 值与聚类簇数变化情况
2.5 基于聚类结果的压砖设备健康状态分析
本节根据聚类算法所获得的压砖设备聚类簇中心点模型(表2),结合压砖设备的工艺特征,对压砖设备的健康状态进行估计。
基于表2 所示聚类簇中心点数据,可将设备健康状态归类和分析如下:
(1)严重异常:类别 0、类别 1、类别 14 聚类簇中心点的i_dif 绝对值超过了10 A,两台电机的振动处于严重不同步的状态,将其定义为严重异常状态。在压砖过程中两台振动电机振动不同步,会影响压砖设备受力结构,并影响压砖成品质量。 在这组数据中,此类数据总数很少,说明该设备仍处于正常状态。
(2) 异常: 类别 2 和类别 13 聚类簇中心点的i_dif 绝对值小于 10 A,但超过了 2 A,将其定义为异常状态。
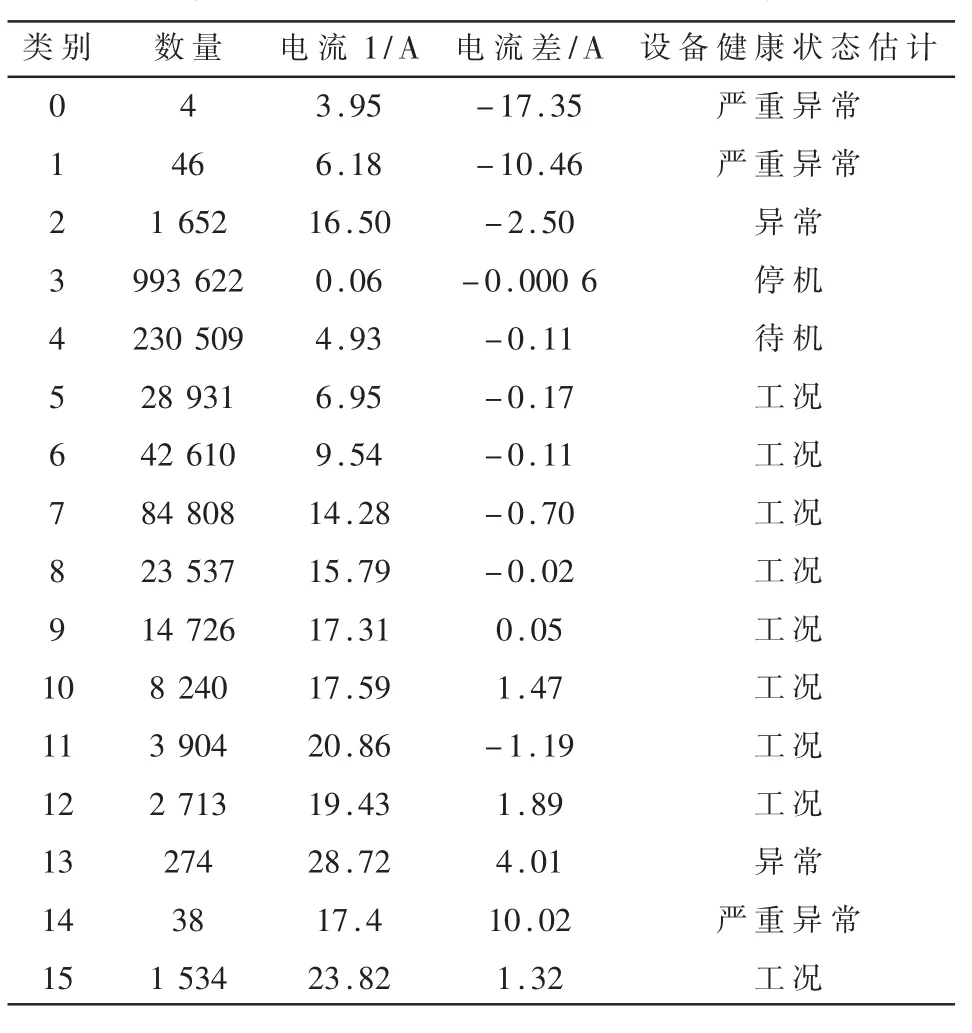
表2 压砖设备健康状态分析
(3)工况:类别 5、类别 6、类别 7、类别 8、类别9、类别 10、类别 11、类别 12、类别 15 聚类簇中心点的 i_dif 绝对值不超过 2 A,i1的值大于 5 A,判断两台电机处于振动状态,且同时性较好,可定义其为工况状态。
(4)停机:类别 3 聚类簇中心点 i1和 i_dif 的值都几乎为0,且总数很多,可定义其为停机状态。
(5)待机:类别 4 聚类簇中心点 i_dif 的值很小,但i1在 5 A 左右,可定义其为待机状态。
3 压砖设备的在线健康状态分析
在通过聚类算法得到设备健康状态模型的基础上,可以进一步实现对压砖设备的在线健康状态分析。 本文通过阿里云 DataWorks 平台,以设定的调度周期将实时采集至MySQL 中的压砖设备数据同步至 MaxCompute 计算平台。 DataWorks 平台与 PAI平台互通,将PAI 平台上训练的模型部署至DataWorks平台,对在线数据进行健康状态分析,最后将分析结果导出至MySQL,用于显示设备健康状态分析结果。 完整工作流程如图2 所示。
3.1 数据源
阿里云DataWorks 支持多种数据源的接入,包括云数据库 RDS,对象存储 OSS、MySQL、Oracle 等。本文所用压砖设备数据存储在MySQL 数据库中并且提供了公网可达的数据接口,在DataWorks 工作空间的数据集成模块中添加MySQL 数据源,通过JDBC 连接串模式进行连接访问。 本文将压砖设备数据的分析结果也存储在该MySQL 数据库中。

图2 基于DataWorks 平台的在线健康数据处理流程
3.2 数据同步节点
将数据从MySQL 数据库接入MaxCompute 计算平台有两种方式,即离线接入和实时接入,本文采取离线接入的方式将压砖设备数据接入MaxCompute。MaxCompute 是一种快速、完全托管的EB 级数据仓库解决方案,以数据为中心,内建多种计算模型和服务接口,可以满足广泛的数据分析需求[11]。
在DataWorks 工作空间的数据开发模块中新建数据导入的数据同步节点,在MySQL 数据库选择存储压砖机设备数据的数据表,将其与MaxCompute 中接收接入数据的数据表对应起来,并将两个数据表的列逐一对应。 设置数据接入时的过滤条件,模型训练完成后,过滤条件可根据调度周期来设定,确保新数据接入。
数据同步节点支持的调度周期包括分钟、小时、日、周和月。本文实验所采用的调度周期设置为5 min。 调度时间段可以根据实际工作时间设置,本文将其设置为全天24 h。 配置好之后,每 5 min 内实时采集的压砖设备数据将从MySQL 数据库导入MaxCompute 进行分析计算。
3.3 数据算法节点
阿里云 DataWorks 平台与 PAI 平台互通,在 PAI平台上训练模型,生成的模型可以发布到DataWorks使用,实现对机器学习实验的周期性调度。 在DataWorks 工作空间的数据开发模块中新建压砖设备健康状态分析算法节点,将训练的压砖设备数据模型离线部署至该算法节点,模型的训练过程在第2 节已详细介绍。 压砖设备健康状态分析算法节点的调度周期配置与数据接入节点的调度周期配置相同,确保及时对新接入的数据进行预测。
3.4 数据导出节点
本文将压砖设备的健康状态分析结果也存储在 MySQL 数据库中,在 DataWorks 工作空间的数据开发模块中新建分析结果导出数据同步节点,将分析结果从 MaxCompute 的数据表导入至 MySQL 的数据表中,该节点的调度周期配置与前两个节点一致,以确保预测结果及时导出。
需要说明的是,虽然数据导入节点、压砖设备健康状态分析算法节点、分析结果导出节点三者的调度周期都为5 min,但是根据需求,三个节点并不是同时开始执行,而应该按数据导入→压砖设备健康状态分析→分析结果导出的顺序来依次执行。 因此,将三个节点之间调度依赖的关系设置为:数据导入节点的输入为工作空间根节点,数据导入节点的输出为压砖设备健康状态分析算法节点的输入,压砖设备健康状态分析算法节点的输出为分析结果导出节点的输入。
3.5 压砖设备健康状态在线分析实例
基于上述方法,连续读取某压砖设备1 h 内的运行数据进行健康状态分析, 结果如图3 所示。 图3显示了振动电机 1 电流 i1和电流差 i_dif 的数据,同时每个数据所属的类别也进行了标记。 可以看出压砖设备在前半小时不间断地进行周期性压砖,且基本处于正常工况状态。 后半小时有部分时间段处于待机和停机状态。 监测期间出现了1 次严重异常记录,电流差i_dif 值很大,但很快就恢复了正常值。运维人员可以根据严重异常记录的统计频次,判断设备的健康状态。 在本实例中,此台压砖设备可判断为健康状态良好。
4 结论
本文基于阿里云机器学习平台设计了压砖设备健康状态分析方法,使用K-means 聚类分析方法构建了压砖设备数据聚类分析模型,在无需专家先验知识的情况下,完成了压砖设备的工作、待机、异常等健康状态的建模。 随后通过将训练好的压砖设备健康状态模型部署至DataWorks 平台,同时周期性地从保存压砖设备实时运行数据的MySQL 数据库导出数据至该平台进行分析计算,实现了对压砖设备健康状态的在线分析。 最后,本文通过实例证明了方法的有效性。
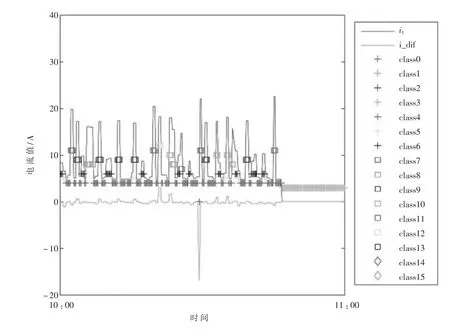
图3 某压砖设备1 h 内健康状态分析结果
猜你喜欢
科学大众(2023年17期)2023-10-26 07:39:14
天天爱科学(2020年6期)2020-09-10 07:22:44
数学物理学报(2017年6期)2018-01-22 02:26:40
电子测试(2017年15期)2017-12-18 07:19:27
新校长(2016年8期)2016-01-10 06:43:59
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
商事法论集(2014年1期)2014-06-27 01:20:42
计算物理(2014年2期)2014-03-11 17:01:44
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
