
一种基于节点局部相似度的标签传播算法
2020-10-28 09:50:26孙美琪梁家瑞
西安工程大学学报 2020年5期
孙美琪,薛 涛,梁家瑞
(1.西安工程大学 计算机科学学院,陕西 西安 710048;太原理工大学 软件学院,山西 晋中 030600)
0 引 言
随着信息技术的高速发展,各种社会媒体产生了庞大的网络数据,很多现实世界的问题被抽象成了复杂网络,如生物网络、社交网络等。社区结构[1]作为一种数据组织形式,存在于各种复杂网络之中[2],是揭示复杂网络结构特性的一个重要指标,发现社区结构并提取其内在规律对研究复杂网络具有重要意义。如在疾病传播网络中,根据病人之间的关系网络,采取有效的隔离和治疗措施以杜绝疾病的传播;在犯罪网络中,借助社区结构可以更加精准快速地找到犯罪成员及其关键人物,为公安部门快速破案提供技术支持。
早期的社区发现研究都认为节点之间是互相独立的,最经典的GN算法[3],通过连续的网络分解获得最终的社区结构。然而,随着研究的不断深入,网络中出现了越来越多的重叠社区。文献[4-5]都是通过网络拓扑结构以及节点属性研究重叠社区,缺点是效率较低。文献[6]的MISAGA(mining interesting subgraphs in attributed graph algorithm)通过计算节点之间的关联度,来衡量顶点对子图的隶属程度,从而发现社区结构。文献[7]提出的MOGA-OCD(multi-objective genetic algorithm)基于边缘编码以及优化的适应度函数可提高社区内部的连通性,但是算法复杂度较高。对于大型网络,可以借助大数据计算引擎实现社区发现算法,如Canopy-K-means[8]算法的并行化就可用于大型网络的节点预处理环节。
在众多社区发现算法中,标签传播算法(label propagation algorithm,LPA)[9]因其简单高效而受到广泛关注。但该算法随机性强,易导致结果不稳定,学者们由此提出很多相关的改进算法[10-13],但只专注于挖掘非重叠社区。GREGORY提出了COPRA(community overlap propagation algorithm),但其社区划分结果不稳定[14]。文献[15]的LPPB(label-propagation-probability-based)根据节点的属性特征计算其在更新过程中标签的传播概率,以此来提高结果的准确性。NI-LPA(node importance-label propagation algorithm)[16]基于节点的重要性,在LPA的基础上仅仅使用网络拓扑结构,将算法改进后用于非重叠社区发现。OMKLP(overlapping community detection in complex networks based on multi kernel label propagation)[17]根据识别出的核心局部节点优化了异步传播策略,从而可以快速识别社区的内部节点以及边界节点。文献[18]的LRMLPA,首先使用LeaderRank对节点的重要性进行度量,之后通过对节点进行团扩展得到粗糙团再开始传播标签。文献[19]提出的算法通过让节点按照PageRank值更新标签,达到了稳定社区结构的效果。但是大多数算法还是忽略了相邻节点之间的局部相似性,因为同一社区中的个体通常会具有相似的属性特征。基于此,本文提出基于节点局部相似度的标签传播算法COPRALS。首先以搜索到的极小完全子图作为初始社区开始标签传播;其次在传播和更新标签时,将节点局部相似度的排序作为依据,以此来保证算法的稳定性。
1 COPRA算法
1.1 算法基本思想
COPRA算法是在LPA算法上的扩展。该算法引入从属系数b,用于衡量节点对社区的隶属程度,节点可以拥有的最多的标签数目由v决定,v表示每个节点最多可以归属的社区数目。从属系数的计算式为
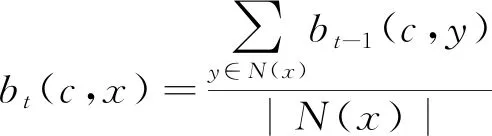
(1)
式中:c为社区;N(x)为节点x的邻节点集;bt(c,x)为在第t次迭代时x对c的从属系数。从式(1)可以看出,COPRA采用同步更新方式,即当前节点的标签更新只能由其余节点上一轮更新的标签来决定。本文采用的是Raghavan[9]等人提出的异步更新方式,即
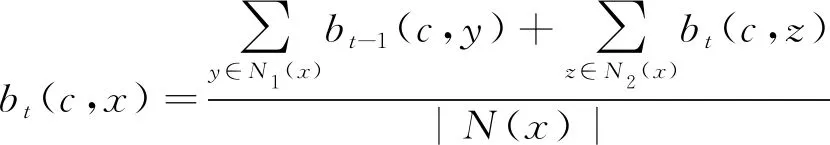
(2)
式中:N1(x)为节点x的未更新邻节点集;N2(x)为节点x已更新的邻节点集;N(x)=N1(x)+N2(x)。节点x在第t次的标签更新取决于2部分:一是节点x的未更新邻居节点的上次更新结果,二是节点x的已更新邻居节点的本次更新结果。
1.2 算法步骤
1) 在初始化期间,网络中的每个节点都有一个标签(x,1),它表示该节点的社区号。
2) 在网络中,以随机的顺序迭代更新节点标签,每个节点从直接连接的节点标签中,选取从属系数大于1/v前v个标签作为本轮更新结果;若情况不唯一,则随机选择一组节点标签作为该节点标签。
3) 反复操作2)直至所有标签趋于稳定。
4) 标签相同的被划分至同一社区。
2 COPRALS算法
从上节可以得出COPRA算法存在以下缺陷:①初始化时会为网络中每个节点分配唯一的标签,这样会导致后续的每轮标签更新迭代时耗费很多时间;②标签传播的开始会随机选择1个节点进行,在节点更新自身标签时,若从属系数一样大时,会随机选择一组标签赋予当前节点。这样,强的随机性会降低算法的稳定性,从而影响社区结构的质量。因此,本文以多标签传播算法COPRA为基础,在标签初始化阶段时,先计算网络中所有节点的度数,只为节点度数大于阈值的节点赋予标签。然后寻找网络中的极小完全子图,以这些子图作为标签传播的开始。并依据本文提出的局部相似度对节点进行排序,利用异步更新策略不断迭代更新每个节点标签,直至所有节点标签趋于稳定。
2.1 标签初始化
在标签传播算法思想中,网络中每个节点依据其邻居所携带的标签来更新自身的标签,而网络中那些度数很小甚至为0的节点,拥有的标签往往直接由其邻居决定。由此可知,COPRA算法初始化时为每个节点赋予标签,并以此作为后续迭代更新的依据,这样会耗费大量时间。因此,本文在初始化标签时不会为度数小于等于阈值dth(本文中dth取1)的节点分配标签,这样既减少了节点标签的初始化数目,又减少了更新此类节点的成本,时间复杂度将会降低。
其次,以CPM(cliqne percolation method)算法[20]思想为基础,采用以网络中若干个连接紧密的极小完全子图作为标签传播的原始社区,其中一个极小完全子图代表网络中一个相互连通的三角形。在标签传播初期,每个节点接收到的邻居节点的标签比较分散,因此在局部范围内若已有紧密连接的社区,使其携带相同的标签,那么迭代更新过程中会收敛更快,算法效率也会得到提升。
2.2 标签选择
COPRA算法的标签选择阶段会为当前节点可能拥有的所有标签的隶属度进行排序,选择隶属度最大的一组标签赋予该节点,若情况不唯一则会随机选择一组标签赋予节点。从分析得知,在此过程中,如果先选择了重要性较小的节点,那么这些节点又会反过来影响重要性较大的节点,从而导致 “标签回流”,这样会造成社区结构的不稳定,影响社区发现的质量。因此,本文以局部相似度指数来为节点进行排序,选择与当前节点更相似的邻居所携带的标签来保证算法的稳定性,进而达到提高社区发现质量的效果。
在社交网络中,节点之间的相似性可以很好地反映它们之间的相关性以及紧密程度。如果节点a有b和c等2个邻接节点,若a与b的相似性越高,a就越容易接受到来自b的标签信息,即a与b更可能来自于同一社区中。为此,本文提出局部相似度指数(S)计算方式,即
(j∈N(i))
(3)

(4)
式中:N(i)为节点i的邻居节点集;N(j)为节点j的邻居节点集;t为节点i和j的公共邻居;CCi为节点i的聚类系数;ei为节点i的所有邻居之间的连边;ki为节点i的度。
提出的节点之间的局部相似度指数是Jaccard系数以及局部聚类系数[21]的组合。Jaccard系数反映的是节点之间的相似性,通常情况下,2个节点之间的公共邻居越多,节点之间的相似度就越大。聚类系数CCi可以度量网络中节点间的聚类程度,它代表了相邻节点之间的关系紧密程度。本文采用的是局部聚类系数,即公共邻居聚集程度的累积,该值反映了节点之间的公共邻居的聚集程度,由2方面决定:第一,2个节点之间公共邻居的数量;第二,每个公共邻居的聚类系数。因为2个节点之间的公共邻居越多,其关系越密切,公共邻居就是节点之间的纽带。由此可得,在标签选择的过程中,节点应该选择与自己最为相似的邻居的标签,其最相似节点定义为
j=arg maxSij,j∈N(i)
(5)
节点局部相似度的计算步骤为
Input:Undirected unweighted graphG(V,E)
Output:Max-neighbors-list(Vi,Vj,Sij)
1) Initialization undirected unweighted graphG(V,E)
2) ForVi(i=1→N) inG(V,E) do
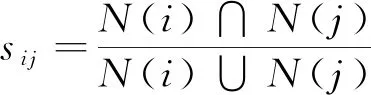
4) End for
5) ForVi(i=1→N) inG(V,E) do
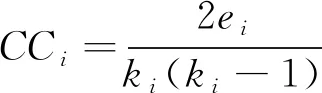
7) End for
8) ForVi(i=1→N) inG(V,E) do
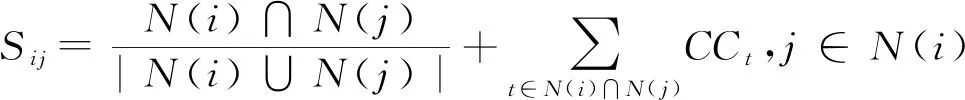
10) End for
11) ForVi(i=1→N) inG(V,E) do
12) According to Eq(7) traverse Similarity-list(Vi,Vj,Sij) and found maxSij
13) Complete Max-neighbors-list←(Vi,Vj,Simij)
14) End for
15) End
2.3 算法描述
步骤1 输入网络G(V,E),计算网络中节点的度,为度数大于dth的节点分配标签(Cx,1)。
步骤2 根据式(4)计算网络中节点的S值,并按降序排列。
步骤3 搜索网络中以度较高节点为中心的极小完全子图,为完全子图内的所有节点赋予相同标签(Cy,1)。
步骤4 当前节点接收来自邻居节点的从属系数大于1/v前v个标签。
步骤5 若选择标签情况不唯一,则选择S值大的节点所拥有的标签,并将从属系数归一化。
步骤6 重复步骤4~5,直至所有节点标签不再改变或算法达到最大迭代次数。
步骤7 输出所有节点标签集合,标签相同的为同一社区。
3 实验及分析
3.1 扩展模块度
本文使用扩展模块度(EQ)作为评价社区结构质量的指标,即

(6)
式中:m为网络中边的个数;Oi为节点i属于社区的数量;di为节点i的度;δ(Ci,Cj)为如果节点i和节点j在同一个社团,则值为1,否则为0。
3.2 标准互信息
标准互信息(INM)可以评估算法生成的社区结构与标准社区结构的相似度。即
H(y|x)norm]
(7)
式中:x和y分别为真实的社区结构和算法生成的社区结构。
3.3 实验分析
为了验证本文算法的有效性和可行性,分别在真实网络和人工合成网络中进行测试。
3.3.1 真实网络数据集 数据集一是Zachary Karate Club[22],包含34个节点和78条边,个体表示每位成员,边表示成员之间的社交关系,其社区划分结果如图1所示。
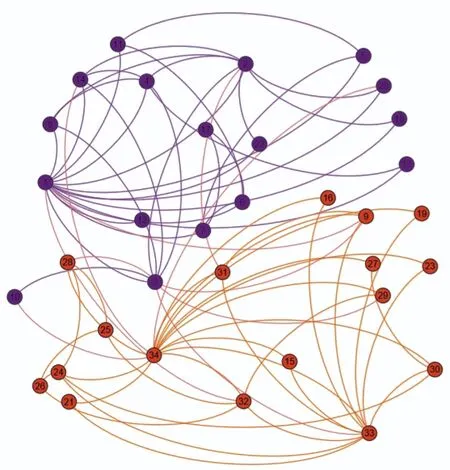
图 1 Karate社区划分结果Fig.1 Division result of Karate community
表1是基于本文提出的算法在dth=1,v=2时,重复运行10 次后取平均值得到的结果,由于COPRA算法存在很强的随机性,所以实验时将COPRA算法重复运行30次。将本文算法与COPRA、OMKLP、LRMLPA算法进行对比,可发现本文算法的EQ值有所提升,说明使用此算法发现的社区结构质量较高。但是,由于此算法初始时搜索了极小完全子图,计算了节点之间的局部相似度,因此本文算法执行时耗时间稍多。

表 1 Karate数据集实验结果Tab.1 Experimental results of Karate dataset
数据集二是Dolphin Social Betwork[23]。 网络有62个节点,159条边。其社区划分结果如图2所示。

图 2 Dolphin社区划分结果Fig.2 Result of Dolphin community division
由于网络规模并不大,因此本实验设置dth=1,v=2 时,同样重复执行本算法10次后取平均值得到的结果。表2为本文算法与COPRA、OMKLP、LRMLPA算法的模块度和运行时间的对比分析,依然可以看出算法的模块度有所提高。

表 2 Dolphin数据集实验结果Tab.2 Experimental results of Dolphin dataset
3.3.2 人工合成网络 LFR基准网络是由Lancichinetti等提出的人工网络,LFR benchmark是用于生成人工网络的基准程序,可以根据个人需求生成网络图,生成的网络具有真实网络的特性。利用基准程序生成了4种网络,如表3所示。
表3中N为节点数目;k为网络中的平均度数;cmin为规模最小的社区节点数;cmax为规模最大的社区的节点数;kmax为网络中的最大度数;um为节点在社区外部的度数与该节点总度数的比值,比值越小说明社区结构越清晰;on为网络中重叠节点数目;om为重叠节点所隶属的社区数目。人工合成网络的实验结果如图3~6所示。
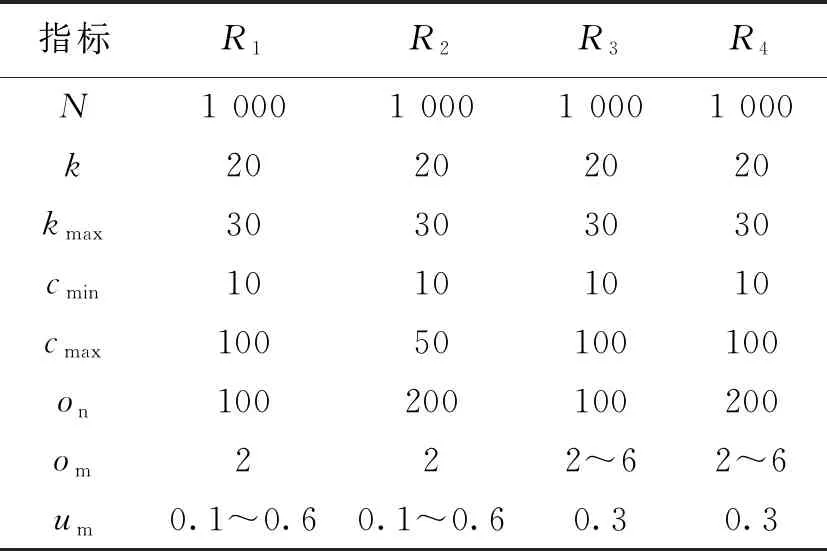
表 3 4种人工网络参数设置Tab.3 Parameter settings of four kinds of artificial network
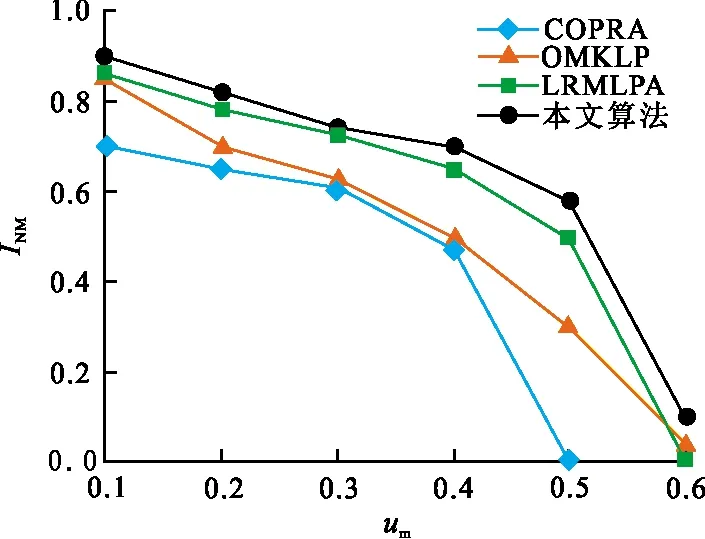
图 3 R1网络的INM值Fig.3 INM value of R1 network

图 4 R2网络的INM值Fig.4 INM value of R2 network
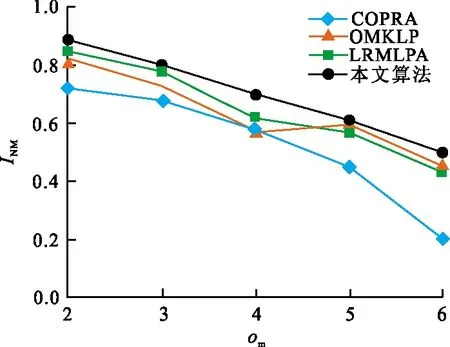
图 5 R3网络的INM值Fig.5 INM value of R3 network
R1网络中重叠节点数为100,属于小规模重叠程度的重叠网络,R2网络重叠节点数为200,属于较大规模重叠的网络。从图3可以看出,COPRA在um=0.5以及LRMLPA、OMKLP在um=0.6时几乎已获取不到社区结构,但是本文算法在um=0.6时,此时社区结构变得模糊,依然可以获取到重叠社区结构。从图4可知,在网络中重叠节点增多的情况下,随着um的逐渐增大,本文算法效果依然较好。

图 6 R4网络的INM值Fig.6 INM value of R4 network
R3网络以及R4网络的um取值相同,即2个网络的社区结构清晰程度相同。R3网络的重叠节点数为100,属于较小规模重叠程度的网络,R4网络的重叠节点数是R3网络的2倍,属于重叠程度较大的网络。从图5以及图6可以看出,本文算法的INM均高于其他算法,说明本文算法的结果更符合真实情况。
4 结 语
本文提出了一种基于标签传播思想的改进的重叠社区发现算法,即基于节点局部相似度的标签传播算法COPRALS。避免了随机选择标签带来的算法稳定性差的缺陷。通过在真实网络和人工网络中的实验测试,表明:本文提出的COPRALS比同类算法发现的社区结构质量更高,且更接近于真实的社区结构。如何将本文算法扩展到分布式环境中,用于发现大规模复杂网络社区结构将是下一阶段工作的重点。
参考文献(References):
[1]FORTUNATOS.Communitydetectioningraphs[J].PhysicsReports,2010,486(3/4/5):75-174.
[2]MATH,WANGY,TANGML,etal.LED:Afastoverlappingcommunitiesdetectionalgorithmbasedonstructuralclustering[J].Neurocomputing,2016,207:488-500.
[3]GIRVANM,NEWMANMEJ.Communitystructureinsocialandbiologicalnetworks[J].ProceedingsoftheNationalAcademyofSciencesoftheUSA,2002,99(12):7821-7826.
[4]WANGMM,ZUOWL,WANGY.Animproveddensitypeaks-basedclusteringmethodforsocialcirclediscoveryinsocialnetworks[J].Neurocomputing,2016,179:219-227.
[5] 杜航原,裴希亚,王文剑.面向属性网络的重叠社区发现算法[J].计算机应用,2019,39(11):3151-3157.
DUHY,PEIXY,WANGWJ.Overlappingcommunitydetectionalgorithmforattributednetworks[J].JournalofComputerApplications,2019,39(11):3151-3157.(inChinese)
[6]HETT,CHANKCC.MISAGA:Analgorithmformininginterestingsubgraphsinattributedgraphs[J].IEEETransactionsonCybernetics,2018,48(5):1369-1382.
[7]BELLO-ORGAZG,SALCEDO-SANZS,CAMACHOD.Amulti-objectivegeneticalgorithmforoverlappingcommunitydetectionbasedonedgeencoding[J].InformationSciences,2018,462:290-314.
[8] 郭卫霞,薛涛,李婷.基于Hadoop的Canopy-K-means并行算法的学生成绩与毕业流向关系分析[J].西安工程大学学报,2018,32(6):705-712.
GUOWX,XUET,LIT.AnalysisofstudentscoreandgraduationdestinationbasedonHadoop′sCanopy-K-meansparallelalgorithm[J].JournalofXi’anPolytechnicUniversity,2018,32(6):705-712.(inChinese)
[9]RAGHAVANUN,ALBERTR,KUMARAS.Nearlineartimealgorithmtodetectcommunitystructuresinlarge-scalenetworks[J].PhysicalReviewEStatalNonlinear&SoftMatterPhysics,2007,76(3):036106.
[10]XINGY,MENGFR,ZHOUY,etal.Anodeinfluencebasedlabelpropagationalgorithmforcommunitydetectioninnetworks[J/OL].TheScientificWorldJournal,2014:1-13.http://downloads.hindawi.com/journals/tswi/2014/627581.pdf.
[11]HEM,LENGMW,LIF,etal.Anodeimportancebasedlabelpropagationapproachforcommunitydetection[M]//AdvancesinIntelligentSystemsandComputing.Heidelberg:Springer-Verlag,2013:249-257.
[12] 石梦雨,周勇,邢艳.基于LeaderRank的标签传播社区发现算法[J].计算机应用,2015,35(2):448-451.
SHIMY,ZHOUY,XINGY.CommunitydetectionbylabelpropagationwithLeaderRankmethod[J].JournalofComputerApplications,2015,35(2):448-451.(inChinese)
[13] 张蕾,钱峰,赵姝,等.基于边权的稳定标签传播社区发现算法[J].小型微型计算机系统,2019,40(2):314-319.
ZHANGL,QIANF,ZHAOS,etal.Stablelabelpropagationalgorithmbasedonedgeweightsforcommunitydetection[J].JournalofChineseComputerSystems,2019,40(2):314-319.(inChinese)
[14]GREGORYS.Findingoverlappingcommunitiesinnetworksbylabelpropagation[J].NewJournalofPhysics,2010,12(10):103018.
[15] 刘世超,朱福喜,甘琳.基于标签传播概率的重叠社区发现算法[J].计算机学报,2016,39(4):717-729.
LIUSC,ZHUFX,GANL.Alabel-propagation-probability-basedalgorithmforoverlappingcommunitydetection[J].ChineseJournalofComputers,2016,39(4):717-729.(inChinese)
[16]KOUNIIBE,KAROUIW,ROMDHANELB.Nodeimportancebasedlabelpropagationalgorithmforoverlappingcommunitydetectioninnetworks[J].ExpertSystemsWithApplications,2019:113020.
[17] 邓琨,李文平,余法红,等.基于多核心标签传播的复杂网络重叠社区识别方法[J].通信学报,2017,38(2):53-66.
DENGK,LIWP,YUFH,etal.Overlappingcommunitydetectionincomplexnetworksbasedonmultikernellabelpropagation[J].JournalonCommunications,2017,38(2):53-66.(inChinese)
[18] 龚宇,张智,顾进广.基于LeaderRank的多标签传播重叠社区发现算法[J].计算机应用研究,2018,35(6):1738-1741.
GONGY,ZHANGZ,GUJG.Multi-labelpropagationalgorithmforoverlappingcommunitydetectionbasedonLeaderRank[J].ApplicationResearchofComputers,2018,35(6):1738-1741.(inChinese)
[19] 马健,刘峰,李红辉,等.采用PageRank和节点聚类系数的标签传播重叠社区发现算法[J].国防科技大学学报,2019,41(1):183-190.
MAJ,LIUF,LIHH,etal.OverlappingcommunitydetectionalgorithmbylabelpropagationusingPageRankandnodeclusteringcoefficients[J].JournalofNationalUniversityofDefenseTechnology,2019,41(1):183-190.(inChinese)
[20]PALLAG,DERÉNYII,FARKASI,etal.Uncoveringtheoverlappingcommunitystructureofcomplexnetworksinnatureandsociety[J].Nature,2005,435(7043):814.
[21]PANXH,XUGQ,WANGB,etal.Anovelcommunitydetectionalgorithmbasedonlocalsimilarityofclusteringcoefficientinsocialnetworks[J].IEEEAccess,2019(7):121586-121598.
[22]ZACHARYWW.Aninformationflowmodelforconflictandfissioninsmallgroups[J].JournalofAnthropologicalResearch,1977,33(4):452-473.
[23]LUSSEAUD,SCHNEIDERK,BOISSEAUOJ,etal.ThebottlenoseDolphincommunityofoubtfulsoundfeaturesalargeproportionoflong-lastingassociations[J].BehavioralEcohgyandSociobiology,2003,54(4):396-405.
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-22 22:13:22
数学物理学报(2021年2期)2021-06-09 08:54:42
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
电子科技大学学报(2016年2期)2016-08-31 02:50:00
发明与创新(2016年38期)2016-08-22 03:02:50
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31 19:42:13
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
