
乳腺癌病理文本的结构化信息提取
2020-10-27 06:31:34王逸飞胡华宇徐洪丽郑一琼
解放军医学院学报 2020年7期
关键词:皮肤
吴 欢,应 俊,王逸飞,胡华宇,徐洪丽,郑一琼
1 解放军总医院 医学大数据研究中心,北京 100853 ;2 南开大学医学院,天津 300071 ;3 解放军总医院第一医学中心 普外科,北京 100853
组织病理学诊断是乳腺癌确诊的金标准,能够向临床医师提供包括癌症类型、分化程度、免疫组化信息在内的完整临床病理学报告,标准规范的病理学报告,对临床医生进行疾病诊断、分析和治疗等具有重要参考意义[1]。自2007 年起,中国抗癌协会开始颁布《乳腺癌诊治指南与规范》,公布了乳腺癌病理学诊断技术标准与规范[2]。但病理报告依然是非结构化的文本描述,在开展临床科研统计分析时,需要根据研究主题由临床研究人员从报告文本中人工整理出相应的研究指标及其对应值。这种方法不仅效率低、耗时,而且准确率难以得到保证。随着医学大数据分析和数据挖掘的不断发展,对非结构化文本的结构化处理需求日益增长[3]。模式匹配是数据结构中字符串的一种基本运算,其功能是根据给定的子串,找出某个字符串中包含的所有该子串,主要包括基于规则的模式匹配和基于统计的模式匹配两种方法[4-6]。基于规则的模式匹配采用正则表达式表示需要匹配的字符串模式,对于自然语言文本具有较好的灵活性,在抽取过程中简单易操作,但抽取效果高度依赖制订的规则( 字符串模式),适用于表达规范的文本。在该方法中,正则表达式指用于描述正则集的代数表达式,是由普通字符和通配符等特殊字符组成的文字模式,常用于文本内容的搜索,可根据一定的算法匹配文本,实现从字符串中提取子字符串的功能,是基于规则的模式匹配文本信息提取方法的基础[7-9]。基于统计的抽取模型,依靠实际文本训练学习以建立识别模型,虽然可以得到较高的精确度,但训练过程复杂、耗时较长[10-11]。由于解放军总医院第一医学中心的乳腺癌病理报告为单病种报告且具有一定的规范性,可快速整理得到其文本结构和数据特点,适宜采用基于规则的模式匹配方法对乳腺病理文本进行结构化处理,实现对非结构化文本的结构化信息提取,以辅助临床科研人员进行下一步医学研究。
资料和方法
1 资料来源 本文处理的病理文本来自解放军总医院第一医学中心2005 - 2017 年共计10 590 份去隐私的乳腺癌病理报告,由病理科医生采用自然语言描述书写。乳腺病理报告内容主要包括病理号、申请科室、报告日期、报告类型、检查所见、病理诊断等内容。其中,检查所见为医生根据送检标本肉眼所见,主要包括标本类型、标本大小、质地、边界等。病理诊断为医生根据镜下所见对患者病理给予的诊断,主要包括肿瘤类型、SBR 分级、肿瘤大小、肿瘤累及范围、淋巴结状态和免疫组化检测内容(ER、PR、Ki-67、HER-2、FISH 结果) 等。病理报告部分内容如表1 所示。
2 病理诊断报告结构 从表1 可知,病理诊断可以提取出 “侧别”、“肿瘤类型”、“分化分级”、“大小”、“侵犯部位”、“淋巴结转移数”、“免疫组化指标” 等分别以描述和数值表达的结构化字段。其中,侧别和肿瘤类型常一起描述;浸润性癌常用SBR 分级或分化程度描述肿瘤的成熟程度;原位癌以高、中、低等级别描述肿瘤细胞核分级;肿瘤大小以三径表示或只记录最大径;侵犯部位主要以部位是否累及或是否侵犯部位的形式描述;淋巴结转移以部位及转移情况表示,转移情况以分数形式表现,分子为淋巴结转移数,分母为淋巴结检出数;免疫组化信息以指标名称和结果的形式出现,结果常用括号括起来,指标结果包括染色程度和阳性细胞所占的百分比。
3 结构化方法 根据基于规则的模式匹配方法,病理文本结构化步骤主要包括:1) 输入语料:病理诊断描述。2) 按算法提取:①根据研究目标构建字段词典和规则集;②根据指标关键词定位目标语句;③对目标语句利用正则表达式匹配提取指标对应的结果描述部分。3)输出标准化结果[12-13]。结构化流程见图1,具体包括字段配置、拆分断句、定位候选句、字段值抽取、反馈修改五个部分。
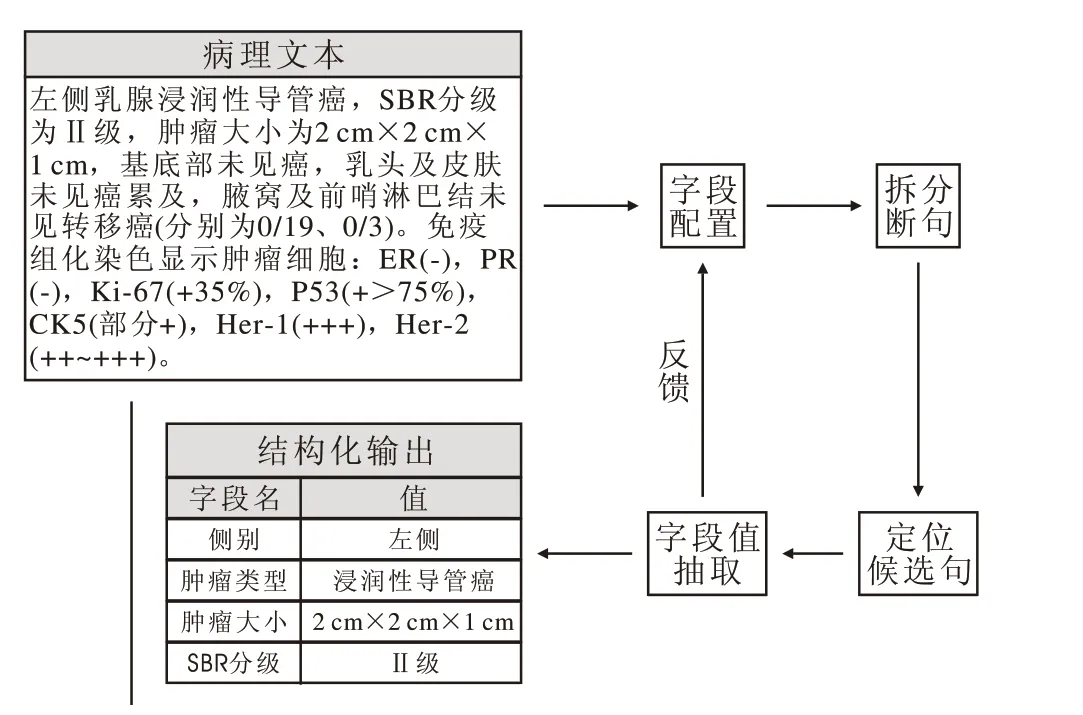
图 1 病理文本结构化流程
3.1 字段配置 病理提取字段信息由临床医生根据研究所需和病理文本内容进行总结,同时结合病理科提供的表达习惯对提取字段及其可能的描述进行整理得到字段描述词典,并对字段值可能出现的描述进行整理归纳,同时设置其输出格式及归一化值。
3.2 拆分断句 因乳腺包含左右两侧,首先根据侧别将病理文本进行拆分重组,如遇“左乳”、“右乳”、“左侧”、“右侧” 等信息时,根据关键词将病理诊断描述文本进行拆分,确保拆分后的内容为同一侧别的病理信息。其次,根据主谓宾关系和标点符号提示,对拆分后的病理信息进行更细致的断句。

表1 病理报告示例
3.3 定位候选句 根据字段词典设置关键词,利用正则匹配从语料中定位候选句,同时可设置限制条件对包含关键词但非候选的语句进行排除。如关键词所在语句中包含如除外、怀疑、疑似、建议明确诊断等非肯定用语的情况时,则将该候选语句排除。
3.4 字段值抽取 把字段值可能的描述转换为以正则表达式书写的候选项,在定位的候选语句中进行字符串匹配,并根据设置的归一化值输出结果信息。
3.5 反馈修改 评估抽取结果,根据存在的问题反馈修改字段配置,直到提取结果的评价指标达到研究预设要求。
4 评价指标 本研究采用的评价指标包括召回率和准确率。其中,召回率指所有正确提取字段值的数量与所有待抽取信息数量之比;准确率指所有正确提取字段值的数量与所有提取到信息的字段值数量之比。
结 果
1 字段配置和字段描述词 根据临床医生整理得到的字段描述词典如表2 所示,第一列为待抽取字段名称,第二列为病理报告中可能出现的描述。如皮肤侵犯在病理报告中可能以 “癌组织累及皮肤”、“皮肤未见癌”、“癌组织侵犯皮肤” 等形式出现,另因书写错误可能会出现错别字的情况,如将“浸润” 写成“侵润”。因此,在整理字段描述词典时,同时考虑了错别字可能出现的情况。此外,为解决同一医学概念不同术语表述的问题,需要进行归一化设置。根据构建的字段词典和字段值可能出现的描述,对字段值格式和归一化值进行设定,见表3。如将累及皮肤、侵犯皮肤、浸润皮肤、皮肤见癌等归一化为累及皮肤;将未累及皮肤、未侵犯皮肤、未浸润皮肤、皮肤未见癌等归一化为未累及皮肤。
2 拆分断句 以表1 中的病理诊断为例,由于本条病理诊断只涉及一个侧别信息,可直接根据主谓宾关系和标点符号,将病理诊断进行断句为“左侧乳腺浸润性导管癌,SBR 分级为Ⅱ级,肿瘤大小为2 cm×2 cm×1 cm, 基底切缘未见癌累及, 乳头及皮肤未见癌, 腋窝及前哨淋巴结未见转移癌( 分别为0/19、0/3)。 免疫组化染色 显 示 肿 瘤 细 胞 :ER(-),PR(-),Ki-67(+35%),P53(+ >75%),CK5( 部 分+),Her-1(+++),Her-2(++~+++)。 ”,其中 表示换行符为断句点。

表2 字段描述词典

表3 字段值格式及归一化值
3 定位候选句 以提取字段“皮肤侵犯” 为例,设置关键词为“皮肤”,同时设置限制条件对包含“Paget's 病/ 派杰氏病” 的语句进行排除,以排除病理诊断中描述皮肤派杰氏病或皮肤呈派杰氏病改变的语句。以表1 中的病理诊断为例,利用正则表达式匹配定位到关键词“皮肤” 对应的候选语句为 “乳头及皮肤未见癌”。
4 字段值抽取 同样地,以提取 “皮肤侵犯” 为例,基于JavaScript 语言利用正则表达式表示字段值可能的描述如图2 中options 所示,字段的归一化值放在每个可能结果的第一位,包括“未累及皮肤” 和 “累及皮肤” 两种。根据关键词“皮肤”定位的目标候选语句为“乳头及皮肤未见癌,”,与图2 中黑色框内的候选项匹配,因此得到“皮肤侵犯” 的抽取结果为 “未累及皮肤”。
5 结果展示 根据表3 设置的格式及归一化要求得到病理诊断的文本结构化结果如表4 所示,字段名称及其结果一一对应,若根据关键词对应的候选句为空或根据关键词对应的候选句中没有与候选项相匹配的结果,则以NA 表示。
6 结果评价 为便于对方法效果进行评价,从10 590 条病理诊断中随机抽取200 条病理诊断,其中有2 条病理诊断因无侧别信息未能提取到信息,实际提取到结构化信息的病理诊断共计198条。根据评价指标得到:1) 基于随机抽样进行效果评估得到的结构化字段的召回率和准确率均高于90% ;2) 对文本结构及特点分析越详细,提取信息的召回率和准确率越高;3) 字段及其值在文本中的表现方式越简单,则其召回率和准确率越高,如皮肤、切缘侵犯情况和免疫组化信息等字段的召回率和准确率均高于浸润癌大小。见表5。

表4 病理提取结果样例

表5 部分字段的评价指标
讨 论

图 2 字段值抽取代码
目前,自然语言处理技术在医学领域的应用主要体现在病历文本数据挖掘、医疗知识图谱构建等方面,使得非结构化的文本数据成为可分析的结构化数据,便于临床知识发现与应用研究。医学自然语言处理过程主要包括分词、词性标注、实体识别、实体关系抽取等任务[15]。针对以上任务分别提出基于词典、基于规则、基于机器学习或深度学习的文本信息处理技术[16-19]。
通过本研究得到如下一些思考:1) 针对乳腺癌病理报告这样的单病种且书写规范程度较高的文本信息,不存在较难理解的语义分析,基于词典和规则方法可实现分词和实体识别,同时结合正则表达式匹配即可提取实体间的修饰或关系信息,因此基于规则的模式匹配信息提取方法具有一定适用性。2) 与基于机器学习或深度学习的处理方法相比较,针对语义简单、结构规范的文本,虽然基于规则的模式匹配方法的信息提取技术更简单、快速、易实现,但前期需要根据临床经验或实际数据情况进行大量的归纳总结以完成字段配置,字段配置的情况直接影响抽取结果。3) 此方法是针对特定语料制订的抽取规则,因此也限制了该成果在其他领域或者语料中的通用性。4) 虽然我国已经对不同疾病的病理书写规范进行了规定,但不同的医生具有不同的依从性和书写习惯,通过文本的结构化处理和结果评估,可反向推动病理报告描述用语的规范化,最终进一步提高病理报告的结构化能力。
综上,本文根据乳腺病理文本的数据结构及特点,采取了一种简单易操作的基于规则的模式匹配文本结构化处理方法,实现病理文本快速、准确的结构化处理,对其他单病种病理文本数据转换为结构化数据提供了一定的参考。同时,本项研究在一定程度上对解放军总医院第一医学中心病理报告书写规范起到了推动作用。
猜你喜欢
现代装饰(2022年3期)2022-07-05 05:56:36
中老年保健(2021年10期)2021-11-30 09:34:06
基层中医药(2021年8期)2021-11-02 06:24:46
中老年保健(2021年4期)2021-08-22 07:07:28
皮肤病与性病(2021年3期)2021-07-30 08:07:40
家教世界(2019年25期)2019-10-08 11:02:52
妈妈宝宝(2017年3期)2017-02-21 01:22:32
少儿科学周刊·儿童版(2016年2期)2016-03-19 11:54:12
中国医疗美容(2015年4期)2015-04-27 02:23:59
新作文(小学中高年级版)(2015年5期)2015-04-12 06:28:00
