
基于深度神经网络和支持向量机的海底管线水合物生成预测模型
2020-10-27 14:05郑秋梅商振浩王风华
中国石油大学学报(自然科学版) 2020年5期
郑秋梅, 商振浩, 王风华, 林 超
(1.中国石油大学(华东)计算机科学与技术学院, 山东青岛 266580; 2.中国石油大学(华东)信息化建设处,山东青岛 266580)
海底管线所处的高压、低温环境以及复杂的多相流动运行工况,极易形成天然气水合物,导致海管输量下降甚至出现堵塞[1]。传统的水合物生成预测方法主要有图解法、半经验模型、相平衡理论模型和统计热力学模型[2]。图解法及半经验模型计算简单,但使用范围狭窄,计算精度不高;相平衡理论模型具有很强的理论基础,但计算复杂,难以掌握;热力学模型虽然使用范围广泛,但参数较多,计算误差较大,难以满足海底管线生产运行需求。近年来, 支持向量机[3-4]、神经网络[5]等机器学习方法越来越多地应用到油气储运行业[6-8],使用支持向量机、神经网络等方法预测天然气水合物已成为实现海底管线智能化运行管理的重要手段。卞小强等[6]建立基于支持向量机的回归预测模型,在实验数据上取得了较高的拟合精度。马贵阳等[9]利用支持向量机结合遗传算法建立水合物生成回归预测模型,在实验数据上预测效果较好。彭远进等[10]利用仅有一层隐藏层的BP神经网络,在小规模数据集上取得了比较满意的预测效果。但上述模型的测试数据皆是实验数据而非生产现场的真实数据。生产数据规模较大,并且由于海管运行工况复杂、天然气组分变化小等因素影响,导致数据区分度不大,基于支持向量机的回归预测模型无法取得令人满意的预测效果;BP神经网络模型在较大数据集上进行预测时,由于网络深度太浅,预测精度不高。针对上述问题,为提高实际生产数据的水合物生成预测精度,笔者基于深度神经网络和支持向量机建立一种新的天然气水合物生成分类预测模型FDNN_SVM(features of deep neural network for svm),并采用东海CXB至CX平台混输海管近6年的生产数据进行实验。
1 FDNN_SVM分类预测模型的建立
支持向量机(SVM)是一种有坚实理论基础的机器学习算法[4], SVM主要应用于分类和逻辑回归问题,在分类问题中,SVM分为线性SVM和非线性SVM。线性SVM对复杂的数据集分类精度不高,而非线性SVM将数据映射到高维空间后再进行分类,对复杂数据有较好的预测效果。SVM回归预测模型受数据影响较大,对实际生产数据预测效果不理想,因此选用非线性SVM分类预测模型。实际生产数据中天然气组分变化小,数据间区分度不大,影响了模型的预测精度,故仅用该模型无法满足实际工程要求。本文中采用深度神经网络提取数据中包含判别信息的网络特征[11],将网络特征与原始数据相融合来增加数据区分度。
1.1 FDNN_SVM模型的基本原理
深度神经网络(deep neural network, DNN)是一种具有较大网络深度的全连接神经网络,具有强大的非线性映射能力,可以提取数据的网络特征,这些特征中包含大量判别信息,能够增加数据的区分度。DNN的主要思想是使用神经网络算法建立非线性映射模型,利用较大规模的数据集来训练模型,并根据模型进行预测。训练过程中采用误差反向传播(error back propagation,BP)算法[12-13]更新权值,使DNN提取更加有效的网络特征值。支持向量机通过核函数将非线性问题转为线性问题,其决策边界是对样本求解最大边距超平面。本文中采用DNN对样本进行训练,训练完成后提取最后一层隐藏层的网络特征值与样本数据进行串联融合,然后利用非线性SVM对融合数据进行分类预测。非线性SVM的核函数为非线性函数,本文中采用对样本数据映射效果最好的径向基核函数。FDNN_SVM模型的结构示意图见图 1。
1.2 FDNN_SVM模型的实现方法
FDNN_SVM分类预测模型的第一步是利用DNN网络提取样本数据中包含判别信息的隐藏层特征。本文中DNN网络的训练过程如下:
(1)初始化。对DNN中权值向量赋予服从标准正态分布的随机值,输入样本为xn(n=1,2,…,n,n为样本个数)。
(2)数据归一化处理。归一化数据的寻优过程会变的平缓,更容易收敛到正确的最优解。本文中用最小-最大归一化方法将数据映射到[0,1]之间。归一化公式为
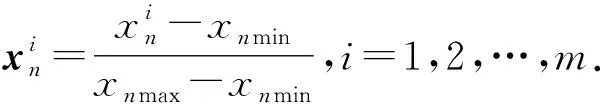
(1)
式中,xnmin为xn的最小值分量;xnmax为xn的最大值分量;m为xn的分量个数。
(3)更新权值。在前向传播过程中向量xn经过各隐藏层映射并使用LeakyReLu激活函数[14]进行激活得到各层输出值,最后使用Softmax分类函数对隐藏层h4的输出值进行预测。
f(u)=max(au,u).
(2)
式中,u为各网络层的输入值;a取0.01。公式(2)为LeakyReLu激活函数,该函数可避免训练过程中出现“神经元坏死”现象。

图1 FDNN_SVM预测模型网络结构Fig.1 Structure of FDNN_SVM prediction model
前向传播完成后,通过损失函数进行反向传播更新权值,本文中DNN网络的损失函数E为
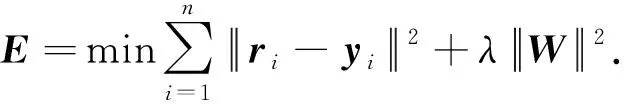
(3)
式中,yi为第i个样本的网络预测值;ri为真实类别值;W为本次迭代中所需更新的权值;λ为归一项所占比重。
通过对误差损失函数E的反向传播调整各网络层之间的连接权值:
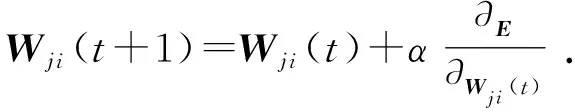
(4)
式中,α为学习率;t为训练次数;Wji为反向传播过程中神经元之间的需要更新的权值。
(4)数据融合。将包含判别信息的网络特征与样本数据融合,可增加数据间的区分度和维度,使模型更容易对数据进行正确分类。网络训练完毕后,提取样本向量xn在隐藏层h4的抽象特征xDNN,然后将归一化后的xn和xDNN串联获得新向量X。
FDNN_SVM预测模型的第二步是用非线性SVM对向量X进行分类预测。其主要思想是将X映射到更高维特征空间中,然后在特征空间建立具有最大间距的超平面进行预测,超平面的方程可以表示为
WTø(X)+b=0.
(5)
式中,WT为特征空间权向量;b∈R为偏置项;ø(X)为非线性映射函数。
为寻找最大间距,引入两个超平面WTø(X)+b=1和WTø(X)+b=-1,SVM的优化问题为求解两个超平面间距离m的最大值问题:
(6)
如图2所示,蓝色及红色点表示经非线性函数ø(X)映射后的样本,样本经非线性映射后在两个超平面上可能有部分离群点,导致SVM分类效果不佳。
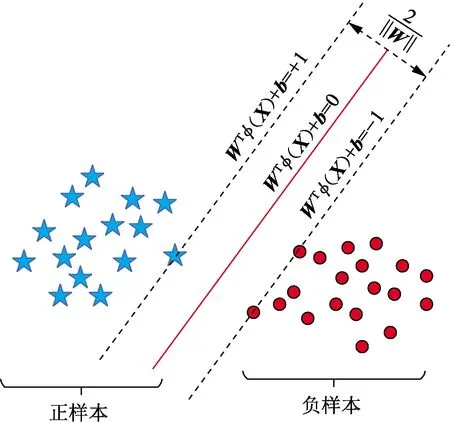
图2 支持向量机超平面分类原理图Fig.2 Schematic diagram of support vector machine hyperplane classification
为解决此问题,通过引入松弛变量来降低超平面对离群点的约束,使用惩罚因子对违反超平面约束的离群点进行惩罚,从而提高SVM分类效果。要使m最大,须使‖W‖最小,非线性SVM最终目标问题变为
(7)
式中,yi为数据的真实类别值;ei为误差松弛变量;C为惩罚系数;W和b为需要学习的权值和偏差值。
采用拉格朗日法求解,将上述待解问题转为拉格朗日函数的对偶问题,并使用核函数K代替复杂的非线性映射函数内积,如下式:
(8)
式中,a=[a1,a2,…,an]为拉格朗日乘子;n为样本数量。
对公式(8)求解后可得

(9)
通过上述步骤可知,将DNN网络特征与样本数据相融合来增加数据的区分度,然后使用SVM分类模型对融合数据进行预测。FDNN_SVM模型结构简单,计算方便,通过更改模型中DNN网络深度,可提取不同规模数据的网络特征来增加数据间的区分度,具有较好的推广性。
2 应用实例
2.1 样本数据选取
在实际生产中,海底管线形成天然气水合物受很多因素影响,如组分、温度、压力、流速等。搜集2014年9月至2019年3月东海CXB至CX平台混输海管的运行数据建立样本数据集,数据包括天然气组分、海管出入口温度压力、气液注入量,共11个影响因素。其中天然气组分为:CH4、C2H6、C3H8、CO2、CH2的物质的量分数[15]。样本数据集规模较大,共有1 600条,其中生成水合物的数据约700条。实验中对数据进行随机划分,其中用于训练的数据为1 200条,测试数据为400条。本文中非线性SVM模型使用sklearn机器学习库编程实现,DNN网络模型使用Tensorflow编程实现。
2.2 非线性SVM模型核函数对比实验
非线性SVM分类预测模型的主要思想是使用非线性映射函数将原始数据映射至更高维空间,从而将非线性问题转化为线性可分问题。由于映射函数形式复杂,难以计算其内积,因此可使用核方法代替,即定义映射函数的内积为核函数。常见的核函数见表1。

表1 常见核函数
为判断不同核函数对非线性SVM分类效果的影响,进行了对比实验。经多次实验确定非线性SVM模型最优参数为:错误惩罚系数C=1.0,训练次数为3 000。实验中发现改变核函数参数值对实验结果影响不大,故模型中核函数参数使用sklearn库默认值。实验结果如表2所示。

表2 不同核函数下支持向量机分类模型准确率Table 2 Support vector machine classification model accuracy under different kernel functions
实验结果表明,SVM模型选用RBF径向基核函数时,预测准确率最高。
2.3 FDNN_SVM分类预测模型实验结果
本文中提出的FDNN_SVM分类预测模型中DNN网络深度为6,其中隐藏层个数为4,每层神经元个数分别为10、20、20、5;输出层神经元个数为2,对应生成水合物和不生成水合物的预测概率值。经多次实验确定网络最优参数:学习率初始值为0.001,训练次数为15 000,训练精度为0.000 1。非线性SVM模型采用径向基核函数,惩罚系数C=1.0。为证明FDNN_SVM模型的有效性,本文中建立了多个水合物生成预测模型进行对比实验,包括BP神经网络分类预测模型[8]、深度神经网络分类预测模型、支持向量机分类预测模型(SVM),并且实现了热力学模型、BP神经网络回归预测模型和SVM回归预测模型。实验结果如表3所示。
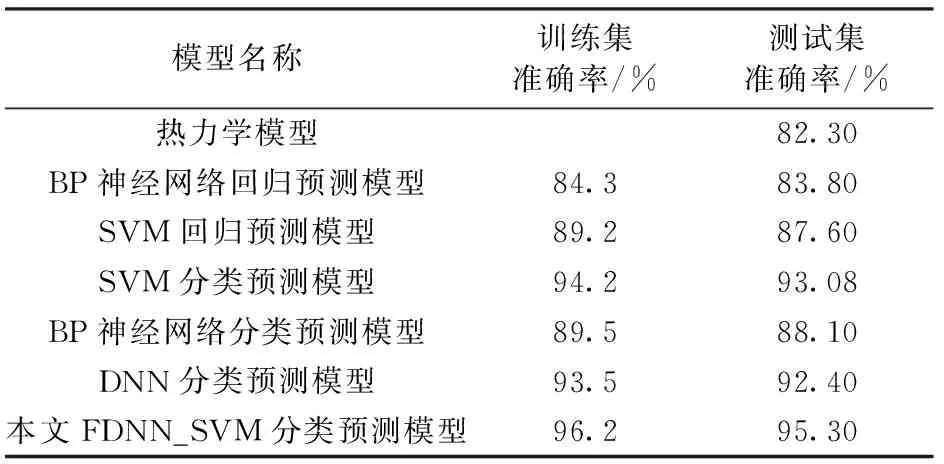
表3 不同水合物生成预测模型准确率Table 3 Accuracy of different hydrate formation prediction models
从表3可以看出,FDNN_SVM模型预测精度最高,满足实际工程要求。与单独使用SVM分类预测模型或DNN分类预测模型相比,测试集准确率分别提高了2.22%和2.9%,这是因为将网络特征和原始数据融合,增加了数据区分度和维度。与BP神经网络分类模型相比,DNN分类预测模型准确率大幅提升,这说明网络深度对于模型预测精度有重要影响。与回归预测模型及热力学模型对比,分类预测模型的预测精度明显提高,说明在实际生产中分类预测模型的预测效果更好。
3 结束语
采用支持向量机和深度神经网络建立FDNN_SVM模型预测海底管线水合物生成情况。FDNN_SVM模型将包含判别信息的DNN网络特征与生产数据相融合,提高了数据的区分度,然后使用非线性SVM分类预测模型对融合后数据进行水合物生成预测,实验表明FDNN_SVM模型具有令人满意的预测效果,满足海底管线生产运行需求。FDNN_SVM模型结构简单、预测精度高,具有较好的推广性,适合对天然气组分变化不明显、数据区分度小的海底管线进行水合物生成预测。但FDNN_SVM模型因结合深度神经网络和支持向量机进行预测,在提高预测精度的同时增加了一定的训练时间,如何提高模型训练速度,减少训练时间是下一步需要研究的问题。
猜你喜欢
化工管理(2022年13期)2022-12-02
油气藏评价与开发(2022年5期)2022-09-28
现代电力(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
海洋石油(2021年3期)2021-11-05
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
高中生学习·高三版(2016年9期)2016-05-14
