
基于聚类和非对称自编码的低频攻击检测方法
2020-10-22 02:11聂俊珂马鹏苏旸王绪安
现代电子技术 2020年20期
聂俊珂 马鹏 苏旸 王绪安

摘 要: 针对传统网络入侵检测方法无法有效检测高维网络下的低频攻击问题,提出一种结合聚类方法与非对称堆叠去噪自动编码器(ASDA)进行改进的入侵检测方法。该方法首先利用非对称堆叠去噪自动编码器对网络入侵数据进行数据特征提取和降维的操作,将输出结果进行重构平衡。将平衡重构后的数据集作为输入,利用改进K均值和密度聚类 (DBSCAN)相结合的聚类分析技术进行特征选择,将选择后的特征数据作为输入,利用浅层学习分类器随机森林(RF)进行分类识别。实验结果证明,该文方法与传统入侵检测方法相比,提升了高维网络下低频攻击的检测准确率及效率,同时降低了误报率。
关键词: 低频攻击; 入侵检测; 高维网络; 聚类分析; 特征提取; 分类识别
中图分类号: TN752?34; TP393 文献标识码: A 文章编号: 1004?373X(2020)20?0087?05
Method of low?frequency attack detection based on clustering and
asymmetric autoencoding
NIE Junke1, MA Peng1, SU Yang1,2, WANG Xuan1,2
(1. College of Cryptographic Engineering, Engineering University of Armed Police Force, Xian 710086, China;
2. Key Laboratory of Network and Information Security of Armed Police Force, Engineering University of Armed Police Force, Xian 710086, China)
Abstract: In allusion to the problem that the traditional network intrusion detection method cannot effectively detect low?frequency attack in the high?dimensional networks, a improved intrusion detection method combing the clustering method with the asymmetric stacked denosing autoencoder (ASDA) is proposed. In this method, the ASDA is utilized to extract data features and reduce dimension of network intrusion data, and then the output results are reconstructed to balance dataset. The reconstructed equilibrium dataset is taken as the input, and the clustering analysis technology combing the improved K?Means and density?based spatial clustering of applications with noise (DBSCAN) is utilized to select the feature data. The selected feature data is used as input, and the shallow learning classifier random forests (RF) is used to conduct the classification and identification. The experimental results show that, in comparison with the traditional intrusion detection method, this method can promote the accuracy and efficiency of low?frequency attacks detection in high?dimensional networks, and reduce the false alarm rate.
Keywords: low?frequency attack; intrusion detection; high?dimensional network; clustering analysis; feature extraction; classification recognition
0 引 言
随着现代网络技术的发展,计算机网络安全问题变得更加复杂,需要加以解决。异常检测综合利用聚类分析和人工智能等方法,从正常模式中识别恶意行为,具有检测未知攻击的优点。尽管所有这些方法都可以单独使用来提高入侵检测系统的性能,但采用混合学习方法可以获得最佳的检测精度和检测率。
文献[1]改进了K均值算法,实现了对非常规行为的识别。首先,对数据集中的离群点和错误点进行过滤,然后计算出相关数据点之间的度量,并使用一个动态和迭代的过程获取K簇的中心,实验证明该聚类方法检测率有所提升和误差率有所降低。文献[2]为了解决现有方法无法探测网络中复杂的攻击问题,提出了一种K均值聚类和贝叶斯分类相结合的方法。首先对数据进行聚类,然后对其进行分类。文献[3]使用神经网络的组合方法来进行网络入侵检测研究。首先利用自动编码器对攻击特征进行约简,然后用DBN学习方法对攻击进行识别。该文献提出的神经网络的组合方法是在不同的重复情况下进行的,与使用单一神经网络方法相比,重复次数越多,该组合模型对网络攻击的检测精度越高。
大多数研究人员在试验各种算法的结合,以及为特定数据集生成最精确和最有效解决方案的分层方法。尽管上述方法已经取得了较高的检测精度,但也存在一些问题。以前的异常检测技术无法有效检测低频攻击,包括人工智能方法。该问题源于训练数据集的不平衡,这意味着当面对这些类型的低频攻击时,NIDS提供了较弱的检测精度。同时高维网络中存储和通过网络的数据量持续增加,实际应用中要高速处理大量网络数据包,确保令人满意的精确度、有效性和效率也是NIDS的一个重大挑战。
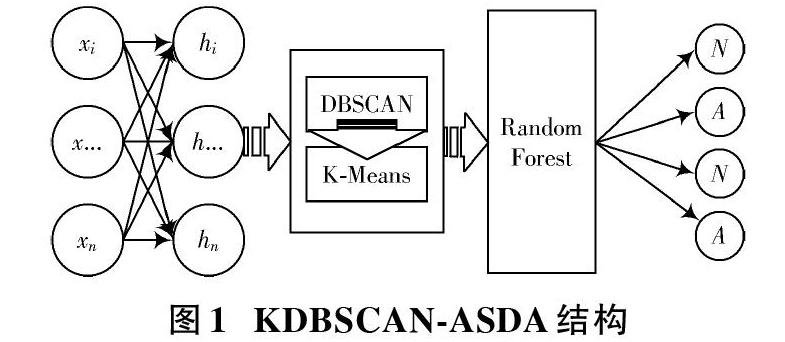
针对高维网络下处理大量数据效率低、低频攻击检测精度低等问题,本文设计了一种采用聚类分析技术与非对称堆叠去噪自编码网络结合的入侵检测分类模型KDBSCAN?ASDA(Asymmetric Stacked Denosing Autoencoder),该模型使用随机森林作为分类器,将深度学习方法与浅层分类器结合起来。该分类模型采用分级非对称自编码结构,适用于处理高维网络的数据输入,对数据集进行平衡处理,增大低频攻击贡献度,同时结合K均值和DBSCAN(Density?Based Spatial Clustering of Applications with Noise)两种聚类方法提升准确度以及检测效率。本文使用ISCX 2012数据集对该模型的有效性进行了实验评估,证明了在检测高维网络下低频攻击的任务上,该方案的检测准确度以及检测效率优于传统检测方法。
1 改进的K均值与DBSCAN结合算法
DBSCAN算法使用参数(ε,MinPts)邻域来描述样本集的相似性。其中,ε是某一样本的邻域距离度量,MinPts是上述度量邻域中样本个数的阈值。假设样本集是D,则相关定义如下[4]:
定义1(ε?邻域):对于xj∈D,其中ε?邻域包含样本集D中以xj为圆心,半径为ε范围内的子样本,这个子样本的个数记为:
[Nε(xj)=xj∈D|distance(xi,xj)≤ε] (1)
定义2(核心对象):对于任一样本xj,如果[Nε(xj)≥MinPts],则xj是核心对象。
K均值算法采用欧氏距离来评价相似性,它是求初始聚类中心向量[V=(v1,v2,…,vk)T] 的最优分类,使得聚类准则函数[Jc]最小。聚类准则函数[Jc]定义为:
[Jc=i=1kp∈Cip-Mi2] (2)
式中,[Mi],p是类[Ci]中数据对象的均值与空间点。
DBSCAN算法能根据数据集的密度分布自动聚类,而K均值算法一般只适用于凸样本集的聚类,DBSCAN算法两者都可适用,但类别数目可能达不到预期目标。因此本文将DBSCAN算法聚类后的结果输入K均值算法进行聚类,加快收敛速度,达到预期目标数目。
输入数据集D,给定邻域距离阈值ε及邻域中样本个数的阈值MinPts,改进后的算法步骤如下:
1) 初始化核心对象集合[Π]为空集, 初始化聚类簇数k=0,初始化未访问样本集合[Γ]=D, 簇划分C为空集。
2) 对于j=1,2,…,m, 按下面的步骤找出所有的中心对象:
① 通过距离度量方式,找到样本xj的ε?邻域子样本集Nε(xj);
② 如果子樣本集样本个数满足[Nε(xj)≥MinPts],将xi加入中心对象集:[Π=Π?xi]。
3) 如果中心对象集合[Π]为空,则算法结束,输出簇划分C={C1,C2,…,Ck};否则转入步骤4)。
4) 在中心样本集中,随机选取中心对象[o],初始中心对象队列[Πr], 初始类号k=k+1,初始化对象集合Ck={o}, 更新未读集合[Γ=Γ-o]。
5) 如果当前中心对象队列[Πr]为空,则该聚类簇Ck生成完毕, 更新簇划分C={C1,C2,…,Ck},更新中心对象集合[Π=Π-Ck], 转入步骤3)。
6) 在该核心队列中取出一个核心对象[o′],通过ε找出该邻域子集[Nε(o′)],令[Δ=Nε(o′)?Γ], 更新当前簇样本集合[Ck=Ck?Δ],更新未访问样本集合[Γ=Γ-Δ],更新[Πr=Πr?(Δ?Π)-o′],转入步骤5)。
7) 令DBSCAN的输出簇C={C1,C2,…,Ck}作为K均值初始聚类中心[Zj(I)],[j=1,2,…,k]。
8) 若C>2,则用K均值对均值漂移做C-2次聚类,并使用Silhouette判断评分最高的2个聚类,算法结束。否则转入步骤9)。
9) 计算该点与DBSCAN聚类簇的距离[D(xi,Zj(I))],[i=1,2,…,n],[j=1,2,…,k];如果满足[D(xi,Zj(I))=minD(xi,Zj(I)),j=1,2,…,n],则[xi∈wk]。
10) 计算聚类准则函数[Jc]。
11) 判断:若[Jc(I)-Jc(I-1)<ε],则算法结束;否则[I=I+1],计算新的聚类中心,转入步骤8)。
从上述步骤可以看出,当条件满足时,该算法将收敛到此点附近的对应值。
2 KDBSCAN?ASDA入侵检测分类模型
2.1 模型设计
该入侵检测分类模型包含4个阶段: 数据处理阶段、基于ASDA的特征提取和数据集重构阶段,聚类分析阶段和基于RF(Random Forests)分类器的识别。数据集预处理阶段:在此将数据集分割成网络流文件,并进行不正确和重复记录的标签移除,详见第3.1节。基于ASDA的特征提取和数据集重构阶段:文献[5]和文献[6]详细研究了网络深度、节点数等参数对入侵检测性能的影响。本文综合采用4层非对称结构,即输入层节点数为41,隐含层依次为14,28,和14。聚类分析阶段:这一阶段将DBSCAN算法聚类后的输出簇作为K均值算法的初始聚类中心进行分析,增加了对噪声的鲁棒性同时满足所需要的聚类数目。基于RF的入侵识别:与RF判别模型相比,由于其具有典型Soft?Max层的堆叠式自动编码器的分类能力相对较弱,因此将ASDA的深度学习能力与浅层分类器RF结合起来。
2.2 模型训练
特征提取模块采用无解码器的非对称结构,它采用类似于经典的自动编码器训练策略来学习非平凡特性,训练后的输出不再进行解码,而是作为聚类分析模块的输入进行聚类分析,最终将聚类后的结果作为分类器的输入进行训练。本文提出的入侵检测模型采用输入向量x∈Rd,并使用如式(3)所示的确定性函数逐步映射到其潜在的表示hi∈Rd,这里d表示向量的维数。
[hi=σ(Wi?hi-1+bi), i=1,2,…,n] (3)
式中,h0=x;σ是一个激活函数,在此使用sigmod函数;n为隐含层数。
与传统的自动编码器不同,提出的堆叠去噪自编码器不包含解码器,其输出向量由与式(4)相似的公式计算,作为潜在的表示。
[y=σ(Wn+1·hn+bn+1)] (4)
模型的估计量可以通过最小化m个训练样本上的平方重建误差来获得,如下:
[E(θ)=i=1m(x(i)-y(i))2] (5)
ASDA提供了一种分层的无监督学习算法,具有提取复杂特征的功能,因此它能够通过对贡献度最大特征进行排序来细化模型。然而,具有典型Soft?Max层的堆叠式自动编码器的分类能力相对较弱。因此,将ASDA的深度学习能力与浅层学习分类器RF结合起来。RF是一种集成学习方法,可以认为是这些未经修剪的决策树的包装(记录是随机选择的,从原始数据中替换),在每次分割时随机选择特征。它具有低偏差、对异常点的鲁棒性和过度拟合校正等优点,所有这些优点在入侵检测场景中都有较好的适用性。在深度学习研究中,入侵检测模型的精确结构决定了它的成功。通过对多种结构成分的实验,得到了该分类模型的精确结构,如图1所示,取得了较好的分类效果。这些精确的参数(即神经元和隐含层的数目)是通过交叉验证许多组合,直到确定最有效的组合为止,避免过度适应的风险。
3 实验结果与分析
3.1 实验数据集预处理
目前,研究方法大多采用人工设计的网络流量特征,因此大多数公共入侵检测数据集,如NSL?KDD和KDD?CUP 1999,都不包含原始流量数据。为了验证所提出的网络安全入侵检测框架的时间效率和有效性,在少数几个包含原始流量数据的公共数据集中,选择ISCX 2012作为实验数据集。此数据集包含7天的原始网络流量数据,包括正常流量和4种类型的攻击流量:暴力破解SSH攻击(BruteForce SSH)、分布式拒绝服务攻击(DDoS)、HTTP拒绝服务攻击(HTTP DoS)以及渗透攻击(Infiltrating)。此外,攻击流量的百分比约为2.8%,这使得ISCX 2012与实际情况相似,并且这些数据集所包含的发布时间和恶意软件流量类型差别很大。因此,它们可以有效地评估本文所提方法的有效性。
ISCX 2012的流量格式是非拆分的PCAP,必须分割成多个网络流文件。此外,标签文件还包含一些问题,如重复的记录和不正确的标签。
1) 使用PKT2FLOW工具将原始网络流量数据拆分为多个网络流。
2) 檢查每个标签文件,所有重复的记录和不正确的标签移除。
3) 将每个网络流文件与处理后的标签文件进行匹配。这里使用60%和40%的比例将ISCX 2012分为训练集和测试集,这个比率由于最近被许多研究人员使用,因此简化了本文方法与其他方法的比较。图2显示了ISCX 2012数据集的预处理结果。
3.2 实验设计与分析
为验证本文提出的入侵检测模型的有效性,设计以下实验:
1) 测试数据集规模大小对模型检测率影响的对比分析;
2) 分析单独聚类算法和结合后对检测性能的影响,以及与其他模型的对比。
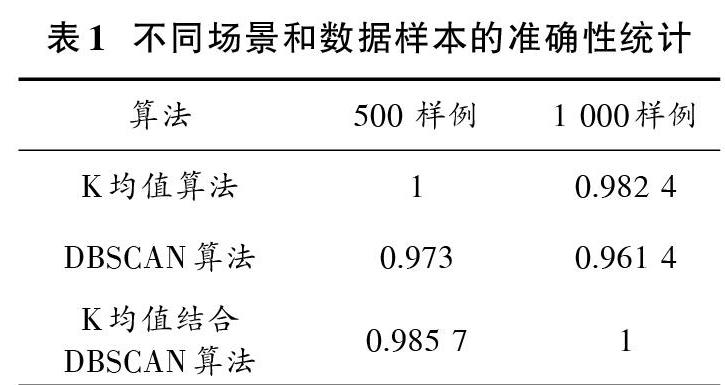
由于许多研究人员已经验证过单一K均值(K?means)和DBSCAN算法的检测效果,本文采用同样的测试样例数量,即500测试样例和1 000测试样例,来进行两者结合的检测效果对比。表1显示,在结合2种聚类方法,随着测试样例数量的上升,检测准确率有了提升,这种优势是单一聚类方法所不具备的,验证了本文提出的模型在高维网络中大量数据输入情况下的入侵检测性能。
由于本文使用的数据集为ISCX 2012,数据集的标签对检测结果的性能有一定影响,因此本文的实验分析只对使用ISCX 2012数据集的入侵检测模型进行比较。此数据集发布的时间较晚,因此可获得的实验结果相对较少。从图3可以看出,本文提出的模型在低频攻击如渗透攻击(Infiltrating)、暴力破解SSH攻击(BFFSSH),以及HTTP拒绝服务攻击(HTTP DoS)上具有很好的表现,虽然相对于其他类型的攻击数据检测精确率较低,但这是由于数据集预处理后仍然具有不平衡的特性导致的。
其次在可获得的实验结果基础上,以正常流量检测率、攻击流量检测率、准确性和总体误报率作为评价指标,图4显示了本文提出的方法与已经公布的方法在ISCX 2012数据集上实验结果的比较。从图4可以看出,KDBSCAN?ASDA在实验评价标准以及总体上具有最佳性能。
在训练和测试时间方面,KDBSCAN?ASDA的输入数据由原始网络流量组成。因此,该方法的训练和测试时间包括特征提取和特征选择所需的时间。相反,前面提到的方法直接使用人工设计的特征,并且不需要时间来进行特征提取和选择。因此,直接比较它们的训练和测试时间是不合适的。然而,本文列出一些方法在文献中存在的训练和测试时间。图5显示了ISCX 2012数据集的培训和测试时间的比较。
其他公布方法的比较
图5显示了KDBSCAN?ASDA与其他方法在ISCX2012数据集的训练和测试时间的比较结果。从图中可以看出,虽然KDBSCAN?ASDA所提方法的时间包含特征提取和选择阶段,但它仍然达到了最低的训练和测试时间,这清楚地表明了本文提出的入侵检测方法的高效率。
4 结 语
本文首先介绍K?means和DBSCAN算法的相关知识以及结合两者进行改进的聚类算法步骤。其次,又针对传统的异常检测技术在高维网络下并不能有效地检测到低频攻击、训练时间过长等问题,提出了使用非对称去噪自编码网络结构处理高维网络数据,结合聚类分析技术与浅层学习分类器RF的低频攻击检测方法。该方法首先对原始数据集ISCX进行平衡处理,同时结合改进的K?Means和DBSCAN两种聚类方法加快收敛速度,减少训练时间。本文也为如何检测高维网络下的低频攻击,提高检测效率与准确度提供了一种新的研究思路,下一步将结合无监督学习等方法研究如何在高维动态网络下实时检测未知攻击的相关问题。
注:本文通讯作者为苏旸。
参考文献
[1] HAN L. Using a dynamic k?means algorithm to detect anomaly activities [C]// Seventh International Conference on Computational Intelligence & Security. Hainan: IEEE, 2012: 1049?1052.
[2] MUDA Z, YASSIN W, SULAIMAN M N, et al. Intrusion detection based on K?means clustering and OneR classification [C]// 7th International Conference on Information Assurance and Security. Melacca: IEEE, 2011: 1?6.
[3] ARUN K S, GOVINDAN V K. A hybrid deep learning architecture for latent topic?based image retrieval [J]. Data science & engineering, 2018, 3(2): 166?195.
[4] 孙名松,韩群.基于LDA模型的海量APT通信日志特征研究[J].计算机工程,2017,43(2):194?200.
[5] 高妮,高岭,贺毅岳,等.基于自编码网络特征降维的轻量级入侵检测模型[J].电子学报,2017,45(3):730?739.
[6] SHONE N, NGOC T N, PHAI V D, et al. A deep learning approach to network intrusion detection [J]. IEEE transactions on emerging topics in computational intelligence, 2018, 2(1): 41?50.
[7] AKYOL A, HACIBEYO?LU M, KARLIK B. Design of multilevel hybrid classifier with variant feature sets for intrusion detection system [J]. IEICE transactions on information and systems, 2016, 99(7): 1810?1821.
[8] ANBAR M, ABDULLAH R, HASBULLAH I H, et al. Comparative performance analysis of classification algorithms for intrusion detection system [C]// Privacy, Security & Trust. Auckland: IEEE, 2017: 282?288.
[9] PATEL G K, DABHI V K, PRAJAPATI H B. Clustering using a combination of particle swarm optimization and K?means [J]. Journal of intelligent systems, 2016, 26 (3): 395?406.
[10] TAN Z, JAMDAGNI A, HE X, et al. Detection of denial?of?service attacks based on computer vision techniques [J]. IEEE transactions on computers, 2015, 64(9): 2519?2533.
[11] BATAGHVA M, WANG X, BEHNAD A, et al. On efficiency enhancement of the correlation?based feature selection for intrusion detection systems [C]// Information Technology, Electronics & Mobile Communication Conference. Vancouver: IEEE, 2016: 1?7.
[12] KATO K, KLYUEV V. Development of a network intrusion detection system using Apache Hadoop and Spark [C]// IEEE Conference on Dependable & Secure Computing. Taipei, China: IEEE, 2017: 416?423.
[13] 陈良臣,刘宝旭,高曙.网络攻击检测中流量数据抽样技术研究[J].信息网络安全,2019,19(8):22?28.
猜你喜欢
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
现代商贸工业(2016年28期)2016-12-27
电子技术与软件工程(2016年22期)2016-12-26
大经贸(2016年9期)2016-11-16
电脑知识与技术(2016年21期)2016-10-18
中国市场(2016年33期)2016-10-18
科技视界(2016年20期)2016-09-29
企业导报(2016年9期)2016-05-26
噪声与振动控制(2015年4期)2015-01-01
