
基于数据融合的生物毒素及生物调节剂快速识别研究
2020-10-22 02:28:00南迪娜刘卫卫傅文翔李宝强孔景临
分析化学 2020年10期
南迪娜 刘卫卫 傅文翔 李宝强 孔景临
(国民核生化灾害防护国家重点实验室, 北京 102205)
1 引 言
近年来,使用生物毒素(Biotoxin)制造恐怖活动的事件时有发生[1,2]。很多生物毒素外观都是白色粉末,人眼难以分辨其与面粉、食盐等常见白色物质的差异。随着物流、人流快速大范围流动,白色粉末更易被散布。海关安检、口岸防控、重大活动安保、处置化学及生物恐怖活动等均迫切需要快速准确识别不明白色粉末的技术。然而,生物毒素来源广泛、结构种类繁多、性质差异大,快速识别难度高。目前, 现场快速检测主要是基于免疫学、核酸适配体等生物传感方法[3~8],上述方法虽具有高通量、高灵敏、高特异的优势,但广谱性不足,且存在一定的误报,无法满足现场对不明白色粉末快速高准确率识别的需求[9,10]。针对这些不足,近年来基于物理原理的广谱检测方法发展迅速。
离子迁移谱(Ion mobility spectrometry, IMS)、拉曼光谱(Raman spectroscopy)结合化学计量学方法在公共安全快速检测领域应用广泛[11~13]。其中, 以拉曼光谱结合协同区间偏最小二乘(Synergy interval partial least squares, SiPLS)、蚁群优化偏最小二乘(Ant colony optimization partial least squares, ACO-PLS)和SiPLS-ACO等多元算法构建回归模型可检测玉米中真菌毒素玉米赤霉烯酮[14]; 空间偏移拉曼光谱(Spatially offset raman spectroscopy, SORS)结合自建模混合物分析(Self-modeling mixture analysis, SMA)方法可对包装内不明白色粉末进行识别[15]; 还有研究将离子迁移谱和拉曼光谱谱图的数据融合,结合主成分分析(Principal component analysis, PCA)和支持向量机(Support vector machine, SVM)算法鉴别毒品[16]。但对离子迁移谱和拉曼光谱数据融合快速识别生物毒素的研究目前鲜有报道,生物毒素的拉曼光谱、离子迁移谱数据库还不完备,在此基础上的谱图模型和识别算法有待深入研究。本研究选取澳大利亚集团(The Australia Group, AG)清单[17]中包含的河豚毒素(Tetrodotoxin, TTX)等剧毒生物碱、芋螺毒素(Conotoxin, CTX)、生物调节剂(Biological modifiers)、《禁止化学武器公约》(Chemical Weapons Convention, CWC)附表[18]中的蓖麻毒素(Ricin)等多种结构类型多样、分子量差异大的生物毒素进行数据融合快速识别研究。为提高识别难度、检验方法的有效性,还设计了组成相同仅氨基酸序列不同的同分异构多肽。在获得上述白色粉末离子迁移谱和拉曼光谱的基础上,将散射光谱中包含的分子中化学键的振动信息与离子迁移时间反映的分子质量、空间结构及带电荷信息关联,增加表征化合物结构的维度,进行模式识别研究并实现了有效区分。
2 实验部分
2.1 仪器与试剂
LabRAM HR Evolution显微共焦拉曼光谱仪(日本HORIBA公司),配有532、633和785 nm等激光器; GA2200高分辨率电喷雾离子迁移谱仪(Electrospray ionization-ion mobility spectrometry,ESI-IMS)(美国Excellims公司); ALLIA-3高纯氮气发生器(法国FDGSi公司),产生的氮气用作离子迁移谱的迁移气体; MS105电子天平(瑞士Mettler Toledo公司),精确至0.01 mg。
HPLC级甲醇购自Sigma公司,实验用纯水为娃哈哈纯净水。分析物包括23种生物毒素、生物调节剂以及面粉、食盐、蛋白粉3种常见白色粉末物质,详细信息见表1。生物碱类样品乌头碱、次乌头碱和河豚毒素均为标准品,购自Sigma公司。多肽类样品包括8种芋螺毒素、6种缓激肽及其片段、P物质及其同分异构体均由上海吉尔生化有限公司采用Fmoc固相合成的方法制备,经液相色谱-质谱分析纯度>95%。合成的多肽样品的氨基酸序列及二硫键连接方式见表2。α-银环蛇毒素(纯度98%)购自广州威佳科技有限公司。蛋白质类生物毒素样品蓖麻毒素、蓖麻凝集素由本研究组从蓖麻籽中分离得到,蓖麻毒素B链拆分自蓖麻毒素,经基质辅助激光解吸电离飞行时间质谱(Matrix-assisted laser desorption/ionization time-of-flight mass spectrometry,MALDI-TOF-MS)分析为纯品。面粉、食盐购自当地超市。蛋白粉为牛血清白蛋白(纯度98%),购自北京百灵威科技有限公司。上述样品外观均为白色粉末。
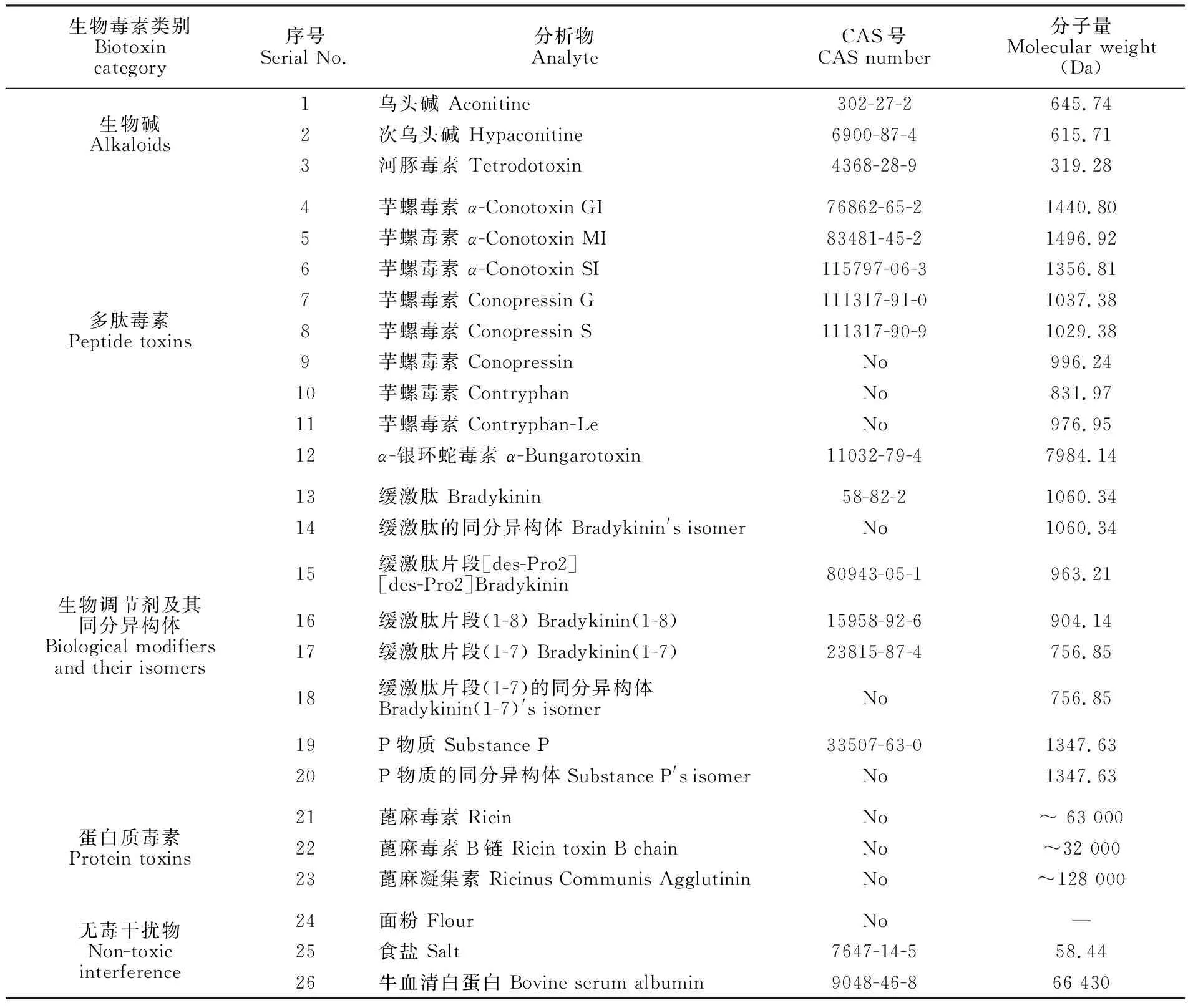
表1 用于模式识别的生物毒素、生物调节剂及常见干扰物

表2 合成的多肽类样品的结构
2.2 实验方法
2.2.1 拉曼光谱实验取微量白色粉末样品置于载玻片上,在显微镜下调节载物台选取采样点。选择放大倍数为50或100倍的物镜、300 gr/mm(600 nm)的光栅刻线密度(中心波长),设置激光功率(满值100 mW)为1%~100%,共焦孔径为100~300 μm,采样范围为50~4000 cm-1。在532、633和785 nm中切换激光波长,设置积分时间1~180 s,积分累加次数为1~20次,根据谱图的信噪比情况调节仪器参数,采集优化条件下的拉曼光谱并保存数据。
2.2.2 离子迁移谱实验称取适量样品,分别用水或甲醇溶解, 配成浓溶液,再用50%~80%(V/V)甲醇-水逐级稀释,配制成10~100 μg/mL的溶液。设置电离源电压为2000 V,迁移管电压为8000 V,进样口和迁移管温度为180℃,离子栅门的门极电压为70 V,脉冲宽度为300 μs,迁移气流速为1.38 L/min,排气泵流速为1.26 L/min,进样针流速为1.26 μL/min,谱图采集时间为10 s,谱图采集范围为0~50 ms。各样品进样体积30 μL,正离子模式下分析。每个样品采集20~25个IMS谱图样本。
2.2.3 数据预处理及融合分析使用Matlab R2019a进行数据分析。截取150~2000 cm-1范围的拉曼谱图,以1 cm-1间隔等距线性插值采样得到11851维样本数据; 设置扫描窗口为50,以移动平均值方式扫描样本中异常点数据并用最近点值替代; 设置窗口5,以高斯加权平均滤波3次的方式对光谱进行去噪; 设置归一化后光谱的30步长导数阈值为910-4,以25为窗口扫描进行基线点选取后,通过分段三次Hermite插值多项式对光谱进行基线校正; 对光谱离差标准化处理,完成拉曼光谱样本预处理过程。将0~50 ms全范围离子迁移谱图数据以0.005 ms等间隔线性插值采样得到110001维样本数据, 然后进行数据融合。将0.025~50 ms范围离子迁移谱图数据以0.025 ms等间隔线性插值采样后进行离差标准化处理,得到1×2000维样本数据。
融合1×2000维离子迁移谱样本数据和预处理后的1×1851维拉曼光谱样本数据,并以此作为总数据集样本。采用主成分分析方法对谱图数据进行降维压缩,选择覆盖原始数据80%以上信息的主成分作为数据集样本。各样品分配70%谱图为训练集数据,其余归入测试集。利用训练集数据训练多分类模式识别模型,再用训练好的模型对测试集数据进行识别归类。
3 结果与讨论
3.1 样品的拉曼光谱


图1 各样品的拉曼光谱图图中横坐标序号代表物为:1. 乌头碱; 2. 次乌头碱; 3. 河豚毒素; 4. 芋螺毒素α-Conotoxin GI; 5. 芋螺毒素α-Conotoxin MI; 6. 芋螺毒素α-Conotoxin SI; 7. 芋螺毒素Conopressin G; 8. 芋螺毒素Conopressin S; 9. 芋螺毒素Conopressin; 10. 芋螺毒素Contryphan; 11. 芋螺毒素Contryphan-Le; 12. α-银环蛇毒素; 13. 缓激肽; 14. 缓激肽的同分异构体; 15. 缓激肽片段[des-Pro2]; 16. 缓激肽片段(1-8); 17. 缓激肽片段(1-7); 18. 缓激肽片段(1-7)的同分异构体; 19. P物质; 20. P物质的同分异构体; 21. 蓖麻毒素; 22. 蓖麻毒素B链; 23. 蓖麻凝集素; 24. 面粉; 25. 食盐; 26. 牛血清白蛋白Fig.1 Raman spectra of different samplesThe compounds of the serial number of the abscissa in the figure are: 1. Aconitine; 2. Hypaconitine; 3. Tetrodotoxin; 4. α-Conotoxin GI; 5. α-Conotoxin MI; 6. α-Conotoxin SI; 7. Conopressin G; 8. Conopressin S; 9. Conopressin; 10. Contryphan; 11. Contryphan-Le; 12. α-Bungarotoxin; 13. Bradykinin; 14. Bradykinin′s isomer; 15. [des-Pro2]bradykinin; 16. Bradykinin(1-8); 17. Bradykinin(1-7); 18. Bradykinin(1-7)′s isomer; 19. Substance P; 20. Substance P′s isomer; 21. Ricin; 22. Ricin toxin B chain; 23. Ricinus communis agglutinin; 24. Flour; 25. Salt; 26. Bovine serum albumin.
3.2 样品的离子迁移谱
各类样品在100 μg/mL浓度时的离子迁移谱如图2所示。 5~8 ms对应的强峰为甲醇-水溶剂峰,各样品信号在8 ms后出现。当样品浓度为10 μg/mL时,在采集谱图过程中可以观察到仅带单电荷的样品进样后,谱图很快达到稳定状态,峰形基本保持不变; 而在电喷雾过程中可能带上多个电荷的多肽类毒素或生物调节剂等,其谱图在1 min左右趋于稳定,这与气相分子中多电荷体系的电荷竞争过程有关。当样品浓度为100 μg/mL时,离子迁移谱信号明显增强。与其它样品相比,生物碱在相同浓度下信号强度高,这与其分子结构中碱性基团在正离子模式下极易带正电荷有关,而多肽类样品如芋螺毒素、生物调节剂等谱图中出现不止一个信号峰,表明其分子中有多个可质子化的位点,这与此类多肽氨基酸组成特点相符。离子迁移谱中, 离子迁移时间与其分子量、带电荷数量、分子碰撞截面积等结构特征相关[19],因此,同分异构体有可能因空间构型差异而被区分。由图2可见,P物质、缓激肽等生物调节剂与其同分异构体的迁移时间不同,这在数据融合分析时为拉曼光谱仅靠分子中化学键振动特征不能区分的物质提供了多维信息。

图2 各类样品100 μg/mL浓度时的离子迁移谱图图中横坐标序号代表物为: 01, 100%甲醇; 02, 80%(V/V)甲醇-水; 1~26物质名称同表1Fig.2 Ion mobility spectrometry (IMS) of different samples at the concentration of 100 μg/mLCompounds of the serial number of the abscissa in the figure: 01, 100% methanol; 02, 80% (V/V)methanol-water and substances corresponding to the numbers from 1 to 26 are the same as in Fig.1
3.3 谱图识别结果
单一谱图分析和数据融合后,前2个主成分分布如图3所示.虽然同类样品因分子组成相似具有相似的拉曼光谱和相近的离子迁移时间,但拉曼光谱数据和离子迁移谱数据具有完全不同的主成分分布,两者从不同的角度反映了样品结构信息。由图3C可见,数据融合后的主成分分布并不是单一谱图数据的简单叠加,数据融合具有使得样本特征更加显著的能力。
使用线性判别分析(Linear discriminant analysis,LDA)、二次判别分析(Quadratic discriminant analysis,QDA)、k近邻(k-Nearest neighbor,KNN)、朴素贝叶斯(Naive bayesian,NB)模型、分类决策树(Classification tree,CT)、Sigmoid核函数支持向量机(SVM)6种模式识别算法,分别对离子迁移谱、拉曼光谱单一谱图以及二者融合后的测试集数据进行归类后,识别结果见表3,重复10次发现, 识别率结果稳定不变。数据融合后,线性判别分析、k近邻、支持向量机算法可有效识别生物毒素和非毒素样品并区分多肽毒素、生物调节剂; 而二次判别分析、分类决策树算法可能将蛋白质毒素误判为生物碱、多肽毒素或生物调节剂; 二次判别分析、朴素贝叶斯模型则存在将非毒素样品误判为生物毒素的情况。与其它5种算法支持向量机模型相比,融合数据具有最高识别准确率(97.2%),并能区分同分异构体。
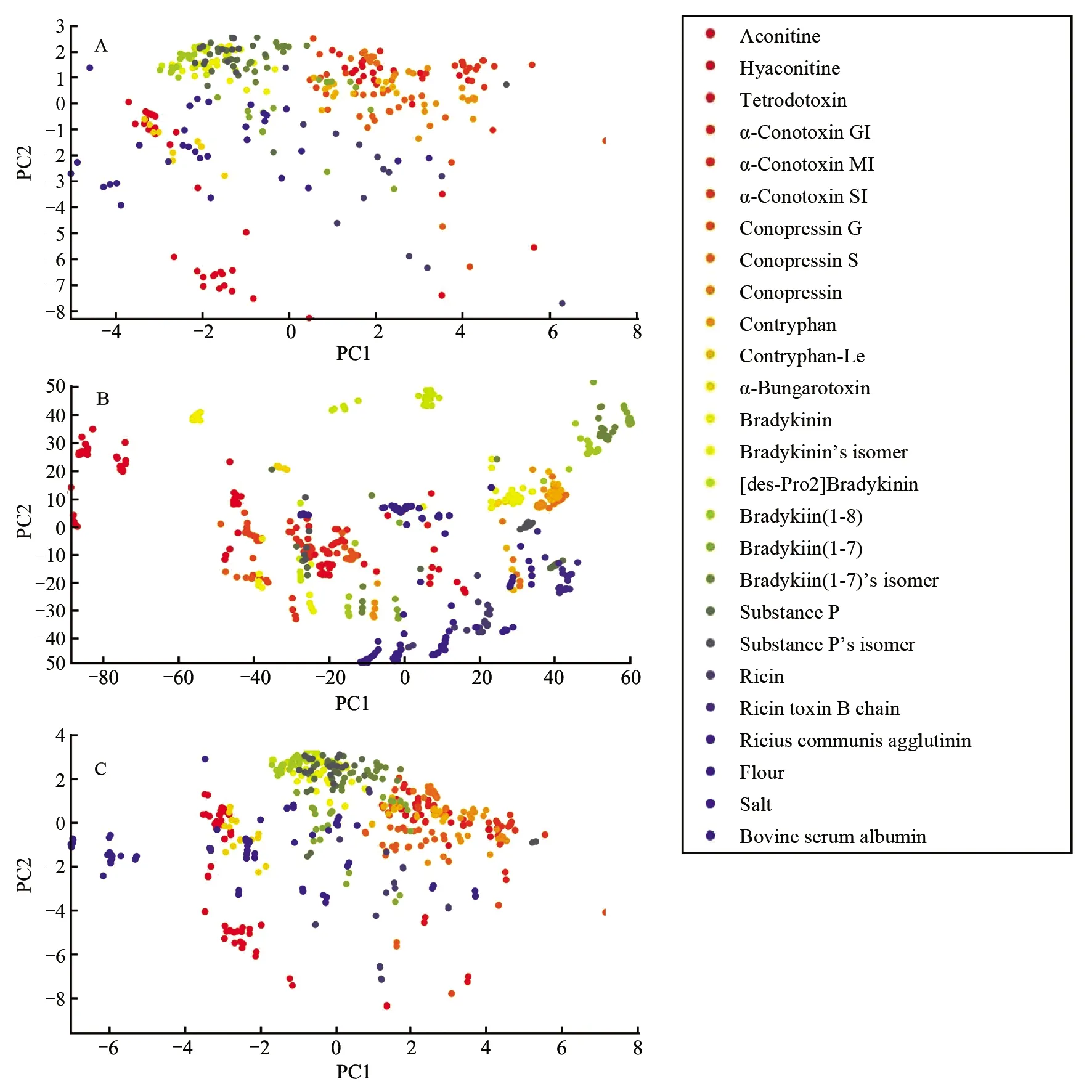
图3 各类样品谱图数据集的主成分分布: (A) 拉曼光谱主成分分布; (B) 离子迁移谱主成分分布; (C) 拉曼光谱、离子迁移谱数据融合后主成分分布Fig.3 Principal component distribution of various sample spectral data sets: (A) Principal component distribution of Raman spectrum; (B) IMS; (C) Raman spectroscopy and IMS fusion data (C)
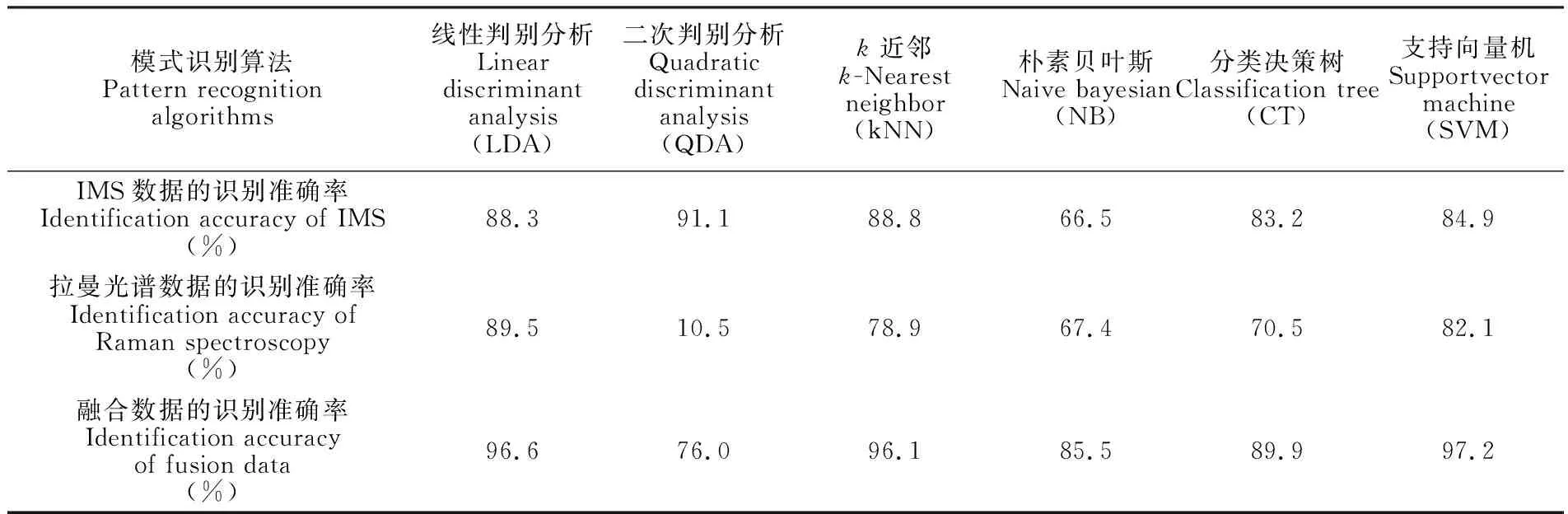
表3 6种模式识别方法对离子迁移谱、拉曼光谱及数据融合的识别准确率
为研究数据库中数据量多少对模式识别算法识别能力的影响,分别分配数据集的50%、60%、70%、80%和90%数据作为训练集训练6种模式识别算法模型,对数据融合后的测试集进行识别。训练集比例为70%及50%~90%时,融合数据测试集样本的识别结果对比情况见图4。
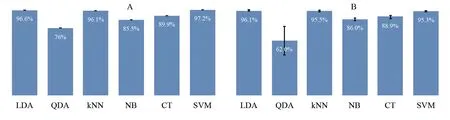
图4 6种模式识别方法对融合数据的识别结果: (A) 测试集比例为70%时的识别准确率; (B) 测试集比例为50%~90%时的平均识别准确率及标准差Fig.4 Recognition results of fusion data by 6 pattern recognition algorithms: (A) Recognition effect diagram when the test set ratio is 70%; (B) Recognition effect diagram when the test set ratios are 50%-90%
由计算结果可知,训练集分配比例越高,即数据库中的数据越完备和充足,线性判别分析具有更好的识别能力; 数据库不够完备时,支持向量机模型识别结果的均值更高,标准差相对较低,表现出更稳健的识别能力。6种模式识别算法中,判别分析算法通过计算比较多个判别函数值实现样本的分类;k近邻分类算法通过计算特征空间中最相似的样本进行分类; 朴素贝叶斯模型通过找出输出和输入的联合分布进行识别分类,算法直观、计算量较小,没有复杂的求导和矩阵运算,因此效率很高; 分类决策树算法易对训练集过拟合,导致泛化能力不强,这时需根据样本特征设置节点参数进行改进; 支持向量机算法则通过求解样本最大边距超平面进行分类。本研究中同类样品特征相似,二次判别分析、分类决策树算法识别正确率相对较低,可能是训练集样本数不大时过拟合导致。支持向量机算法则依据Sigmoid核函数模拟的阈值判别规则,将样本映射到合适的特征空间,具有较好的识别结果。综合比较后,本研究以支持向量机模型进行实际场景中不明白色粉末的识别归类。结果表明,此模型可将无毒样品(如面粉、食盐、蛋白粉等)与生物毒素明显分类,且可将生物碱类毒素与多肽毒素区分开,表明本方法可用于不明白色粉末的快速筛查。
4 结 论
以多类具有潜在或现实威胁的生物毒素及生物调节剂等作为研究对象,建立了电喷雾离子迁移谱、拉曼光谱的实验方法及数据融合识别生物毒素的模型。单独采用拉曼光谱或离子迁移谱检测此类毒物都容易出现低识别率的问题,两种不同原理的检测技术融合使用,采集的谱图从不同维度反映样品的空间结构、化学键组成、质荷比等特征,可明显降低错误识别率。本方法在反化生恐怖活动、事故应急救援等公共安全领域具有广阔的应用前景。
猜你喜欢
考试与评价·高二版(2021年3期)2021-09-10 07:22:44
数学物理学报(2020年5期)2020-11-26 06:06:28
天然产物研究与开发(2018年8期)2018-09-10 05:48:38
中学生数理化·高一版(2016年7期)2016-12-07 20:47:07
试题与研究·中考化学(2016年1期)2016-09-30 18:38:21
公民与法治(2016年14期)2016-05-17 04:15:03
浙江大学学报(农业与生命科学版)(2015年4期)2015-12-15 12:47:46
电源技术(2015年5期)2015-08-22 11:17:54
郑州大学学报(理学版)(2013年3期)2013-03-11 20:30:38
化学分析计量(2013年1期)2013-03-11 16:37:15
