
边缘计算下面向位置隐私保护的中继分流模型
2020-10-21 03:14:42林文敏刘加邦
应用科学学报 2020年5期
林文敏,张 松,刘加邦
1.杭州师范大学阿里巴巴商学院,杭州311121
2.南京大学计算机科学与技术系,南京210023
随着无线通信技术及全球定位系统(global positioning system,GPS)技术的广泛应用,涌现出较多基于地理位置的服务(location-based services,LBS).基于地理位置的服务执行过程一般包括两个步骤:首先,用户向位置服务提供商(location service provider,LSP)发送一条包含其自身地理位置和所需服务的请求;然后,位置服务提供商返回给用户相应的结果.例如用户在使用美团点评时,首先选择自身的地理位置,然后选择需要查询的内容,接着将上述信息发送给美团点评服务提供商后,其服务器经过一系列计算返回给用户相应的查询结果.
在实际应用中,基于地理位置的服务为人们日常生活和工作提供了极大的便利.然而,用户在享受这种便利的同时,也面临着一定程度的隐私泄露风险.例如,一些LSP 或研究机构具有对用户的地理位置及用户请求进行分析的潜在可能性[1].LSP通过收集用户的请求,分析用户请求中的位置属性及内容属性,可以推测出用户的个人信息、行为偏好、身体状况[2].例如,某些用户发送的服务请求中经常包含某医院地点,那么LSP 就可以推测出用户的身体状况.
关于隐私问题的研究通常包括隐私挖掘和隐私保护两个方面.1)隐私挖掘是指对用户的请求进行数据分析,根据用户社会属性的不同可以将隐私挖掘分成两类:一类是面向具有危害性社会属性的用户(如犯罪分子),如在案件侦破过程中需要对用户隐私进行挖掘分析,从而快速地侦破案件.Iqbal等[3]提出了利用数据挖掘分析犯罪分子的数据请求,从而协助警方更快地侦破案件.另一类是面向社会中正常生活的用户,此类隐私挖掘的应用通常指通过收集用户的请求来挖掘用户隐私信息,进而利用用户的隐私信息进行金融诈骗或者勒索敲诈[4].2)隐私保护是从为用户提供更好服务的角度,通过挖掘用户的位置隐私属性获取用户的个性化需求,从而提高服务质量.Chatzidimitris 等[5]提出了对用户历史请求记录进行挖掘分析获得用户的位置隐私属性,进而为用户提供智能个性化的推荐.
本文主要考虑正常用户的位置隐私保护需求,常见的位置隐私研究工作也是以此为立足点.为了解决位置隐私保护的问题,大量研究工作[6-13]普遍采用引入第三方服务器的k-匿名方法[14]及一系列基于k-匿名方法的变种.在这些工作中,基于假人的方法是最流行的方法之一[15].该方法通过产生一组虚假的位置且与真实的位置混合在一起发送给位置服务提供商的云服务器,在云服务器返回结果后,用户本地客户端筛选出用户需要的结果.通过这种方法将用户的真实位置藏匿在一组位置数据中,因此用户的真实位置只有一定概率被识别,从而保护用户的位置隐私信息.本文基于该方法在之前的工作中也做了一些完善工作[16-17].
然而,现有基于假人的方法大多忽略了常规的云服务器离用户距离较远的情况,同时云服务器也需要传输大量数据包给用户,导致用户得到结果的时延可能是传输一条真实数据的k倍,这样会影响用户的位置服务体验.新兴的边缘计算正是为了解决云计算服务器离用户距离过远导致的时延问题,因此我们将以往在云服务器环境中使用基于假人的隐私保护方法迁移到现有的边缘服务器环境中,在满足用户位置隐私保护需求的情况下,尽可能的减少用户得到结果的时延.
本文的主要工作包括以下3 点:
1)分析了云环境下位置隐私保护方法存在的不足之处,如在某些情况下会造成用户的时延大幅上升.
2)针对上述问题,将位置隐私保护方法从云计算场景迁移到边缘计算场景下进行部署,并针对边缘计算的特点:资源有上限、覆盖范围有局限性,设计了面向位置隐私保护的中继分流模型.
3)在真实数据集上对中继分流模型中的假位置产生算法与分流算法进行了实验验证,并与相关论文中的算法做分析对比.
1 背景介绍
用户发送的位置服务请求中通常包含多种内容:用户的位置信息、服务请求内容、其他信息(如设备的IP 地址等),如式(1)所示.

为了达到保护位置隐私的目的,现有基于假人的方法是为用户生成k −1 个假位置,并将这k −1 个假位置连同用户的真实位置信息一同发送给云服务器,具体执行流程如图1所示.

图1 基于假人方法的位置隐私保护流程(云服务器)Figure 1 Location privacy protection process of dummy-based method (deployed in cloud servers)
现有方法在理论上可以达到1/k的保护效果,但面临着用户获得结果的高时延问题.通常情况下用户距离云服务器较远,当使用现有位置隐私保护方法后,用户需要给云服务器发送大量数据,因此用户获得结果的时延理论上是之前的k倍.
边缘计算概念的提出,为解决云服务器距离用户较远导致的用户时延问题提供了可行的技术途径。鉴于此,针对上述位置隐私保护方法中的用户时延问题,提出将现有位置隐私保护方法迁移到边缘计算环境下进行部署的方案,执行流程如图2所示.类似地,用户首先需要基于假人方法生成k −1 个假位置,之后再将这k −1 个假位置连同用户的真实位置信息一同发送给边缘服务器.

图2 基于假人方法的位置隐私保护流程(边缘服务器)Figure 2 Location privacy protection process of dummy-based method (deployed in edge servers)
理论上而言,该方案可在为用户提供k匿名的同时,保证用户请求的低时延.然而,在现实情况下,不同地区的用户分布是不同的,因此不同地区的边缘服务器的负载也存在很大差异.当一个用户(称之为目标用户)所在区域的边缘服务器恰好处在高负载或满负荷运行的状态难以提供正常的服务时,用户便难以向边缘服务器发送匿名请求.如图3所示,当边缘服务器的用户过多时造成服务器满载(红色),其余该区域的用户便无法向此边缘服务器发送请求.

图3 边缘服务器无法完成基于假人方法的位置隐私保护的情况示例图Figure 3 Case where an edge server is unable to complete dummy-based location privacy protection
为了解决上述问题,本文考虑不同边缘服务器的负载情况,在满足用户匿名需求的前提下,通过分流技术实现边缘服务器的负载均衡,以尽可能降低用户的时延.本文构建了面向位置隐私保护的中继分流模型并对模型中的分流方法进行求解.
2 相关工作
2.1 位置隐私保护
近年来,许多研究人员关注位置隐私保护问题并提出了一系列解决方法.在这些方法中,基于假位置的方法是最流行的方法之一.早期工作中,Kido 等[18]将假人方法引入位置隐私保护中,利用随机行走模型在用户端为每个请求生成一组符合真实世界请求频率的假位置,而将上述假位置与真实位置混合后一起发送给服务器.上述真假位置混合的策略使服务器无法直接识别用户的真实位置.Lu等[19]提出了CirDummy 和GridDummy 两种虚拟位置生成方案,实现了考虑隐私区域的k-匿名.
然而,上述方法忽略了对手可能具有侧信息的问题.若这些方法产生的假人位于湖泊或崎岖的山区,那么攻击者会直接识别出这些假位置,从而降低假人方法为用户提供的匿名保护效果.Niu等[20]则在考虑到对手可能拥有侧信息的情况下谨慎地选择虚拟位置,该方法根据熵度量选择这些假位置,然后使被选择的假位置分布得尽可能远.此外,为了进一步降低隐私泄露的风险,Niu 等[21]将查询获得的服务数据进行缓存,并利用缓存的数据来应答未来的查询,从而减少发送到LBS 服务器的查询.通过这种方式,减少了发送到LBS 服务器的请求数据量,从而保护用户的位置隐私.
此外,研究人员逐渐开始考虑到用户移动时的时间和空间连续性对位置隐私保护的作用.例如,Liu等[9]提出了基于用户移动的时间和空间连续性的位置隐私保护策略,首先使用基础方案来生成初始假位置候选集合,然后从时间可达性、方向相似度、出/入度这三个方面分析了相邻位置集之间的时空相关性.
2.2 边缘计算中的计算分流
边缘服务器的服务能力与覆盖范围有限,计算分流则是通过将用户的请求分流至邻近空闲边缘服务器中执行,以实现边缘服务器的负载均衡和用户请求的及时响应.针对计算分流问题,研究人员提出了一系列分流策略.基于这些分流策略,移动云计算为移动设备提供了执行计算密集型应用程序的环境支撑.例如,Guo 等[22]提出了一种节能的动态分流和资源调度策略,以减少能源消耗和缩短应用完成时间.Chen 等[23]提出了一种高效的三步算法,联合优化所有用户任务的分流决策,最小化所有用户的总能量、计算和延迟成本.Wang 等[24]研究了移动用户在未配备强大计算设备的遗留车辆中的计算卸载问题.
上述计算分流方法适用于静态场景下的计算分流.当涉及动态场景时,在何处运行用户的移动请求及如何分配计算资源的决策也引起了研究人员的关注.例如,Hu 等[25]设计了一个称为最大效率优先排序算法的任务分流算法,以实现接近最优的计算分流效率.Tang 等[26]提出了一种具有截流意识和成本效益的分流算法,该算法在考虑雾服务器分布的情况下提高计算分流效率.Zhang 等[27]提出了将车辆云与基于基础设施的云相结合,扩展当前可用的资源,用于智能手机的任务请求.Josilo 等[28]提出了一种新颖的方法来解决边缘计算系统中向一组自主无线设备分配无线和计算资源的问题.
在实际应用中,考虑到边缘计算环境下的位置隐私保护问题时,还需要考虑每个边缘服务器对服务的覆盖都是有限的,从而会导致现有的位置隐私保护算法无法为用户提供位置隐私保护的服务.在这种情况下,现有的位置隐私保护算法的效果可能面临失效的技术挑战.
3 建模预备知识
为了解决第1 节背景介绍中描述的问题,本文提出基于中继的计算分流方法.具体而言,当一个目标用户所在区域的边缘服务器处于高负载或满负荷运行状态而难以提供正常的服务时,其附近的区域仍可能存在可以正常提供服务的边缘服务器.本文通过选用处在可用服务器服务范围中的用户作为中继,利用近程通信技术[29]使目标用户可以选用负载低的边缘服务器获取基于位置的服务.目前,已有相关研究[30]证实了这种基于中继辅助的分流方法的可行性.图4中通过一个具体的例子来展示基于中继的计算分流方法在位置隐私保护中的应用.红色边缘服务器因服务范围内用户众多而处于满载状态,因此该边缘服务器难以处理目标用户的请求.为了获取边缘服务器的服务,目标用户通过中继将服务请求发送至可以正常运行的低负载边缘服务器中进行计算处理.
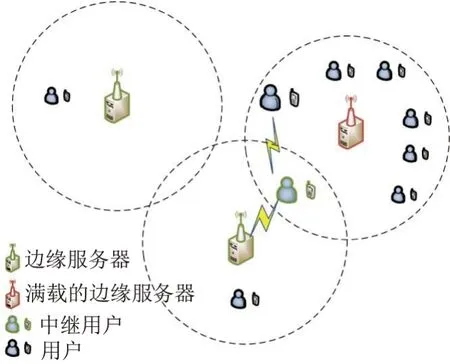
图4 基于中继的分流方法在位置隐私保护中的应用示例Figure 4 Application example of relay-assisted offloading approach in location privacy protection
本文所提出的基于中继的分流方法适用于准静态环境中计算分流问题,即用户在该过程中的位置不会出现较大的变化.在未来的工作中会进一步讨论关于动态环境中基于中继的分流方法在位置隐私保护中的应用问题.
本文中,k表示基于假人方法(下文简称假人方法)的匿名度,它表示假人方法为用户生成了k −1 个假位置.更高的匿名度意味着更强的隐私保护能力,当用户需要的匿名度过高时,受限于接受设备的处理能力,以及目标设备的网络状况和设备性能,存在目标服务器服务能力不匹配的潜在问题.在实际情况中,假设接收设备能接受kre个请求,其中kre −1 个请求包含的是假位置.基于kre与k的数量关系,本文给出如下定义:
定义1强数量请求(Strong Quantity Request):当krek时,称终端设备发出的请求为强数量请求,数量为k.
定义2弱数量请求(Weak Quantity Request):当kre < k时,称终端设备发出请求为弱数量请求,数量上限为kre.
由于不同用户对匿名度的要求不同,对强、弱数量请求的划分标准也不同.本文目标用户需要发送min(kre,k)个请求到中继.考虑到目标用户所持设备的性能和网络状况,以及被选作中继的不同用户,其所持有的终端设备的请求处理能力也是不同的,因此kre的值也需要发生相应的变化.本文使用us表示目标用户所持设备的当前状态,rs表示作为中继的用户的所持设备的状态,es表示边缘服务器的状态.假设这个3 个变量的取值集合均为{−1,0,1}.–1表示终端设备或边缘服务器处于宕机状态,即不能处理任何请求;0 表示终端设备或者边缘服务器仅能处理少量请求,处于该状态时终端设备或边缘服务器仅能发出或接受弱数量请求;1则表示终端设备或服务器状态良好,可以处理高匿名度的请求且能够发出或接受强数量请求.本文目标用户所处区域的边缘服务器一定满足es −1.基于上述对目标用户、中继及边缘服务器的状态讨论,本文给出如下定义:
定义3边缘服务状态(Edge Service Status)
边缘服务状态s=min{rs,es}表示中继及其所在区域的边缘服务器组成的整体所处的状态.
定义4强保护状态(Strong Protection Status)
目标用户处于强保护状态是指目标用户状态满足us=1,目标用户选择的中继与中继所在区域的边缘服务器的边缘服务状态满足s=1.
强保护状态的示意图如图5(a)所示.处于强保护状态时,目标用户可以向外发出强数量请求,中继接收到目标用户的强数量请求后将其发送至边缘服务器.边缘服务器处理完请求后将结果按原路径返回.
定义5弱保护状态(Weak Protection Status)
目标用户处于弱保护状态是指目标用户状态满足us=0,目标用户选择的中继与中继所在区域的边缘服务器的边缘服务状态满足s≥0.
弱保护状态的示意图如图5(b)所示.处于弱保护状态时,目标用户仅能向外发出弱数量请求,中继接收到目标用户的弱数量请求后将其发送至边缘服务器.边缘服务器处理完请求后将结果按原路径返回.
定义6联合保护状态(Union Protection Status)
目标用户处于联合保护状态是指目标用户状态满足us=0,目标用户选择的中继与中继所在区域的边缘服务器的联合服务状态满足s=1.
联合保护状态的示意图如图5(c)所示.处于联合保护状态时,目标设备自身仅能发出弱数量请求,但中继可在目标设备发出请求的基础上加入新的假位置,进而构成强数量请求.之后,中继会将强数量请求发送给边缘服务器,边缘服务器处理完请求后将结果按原路径返回.
定义7极限保护状态(Limit Protection Status)
目标设备满足us=1 且目标设备可以选择多个处于不同边缘服务器服务范围的中继,这些中继与其所在区域的边缘服务器的联合服务状态均满足s=0.

图5 4 种不同保护状态Figure 5 Four different protection status
极限保护状态的示意图见图5(d)所示.处于极限保护状态时,目标用户会选中多个中继,然后将强数量请求分成多个弱数量请求分别发送给中继.中继接收到目标用户的请求后,会将请求发送给自己所在区域的边缘服务器.边缘服务器处理完请求后,会将结果按原路径返回.
从上述定义可以看出,强保护状态对目标用户、中继和边缘服务器均有较高的要求,要求三者的状态值均为1.联合保护状态则允许目标设备在自身能力不足的情况下也可以利用中继发出强数量请求,进而获得较高的安全性.极限保护状态则是在目标用户所持设备性能充足的前提下,利用多个中继发出强数量请求.弱保护状态则是一种极为特殊情况,即目标用户自身性能不足且附近没有可以发出强数量请求的中继.
4 面向位置隐私保护的中继分流模型
基于上文中定义的4 种保护状态,建立面向位置隐私保护的中继分流模型.需要注意的是,本文不考虑状态值us=−1 的情形,是因为此时目标设备已经处于宕机状态,无法发出任何请求.图5展示了上述不同保护状态下目标用户与中继和边缘服务器的交互情况.
假设每个目标用户都是理性的,即总是希望找到使得自身获利最大的分流方法.据此,建立如下模型:
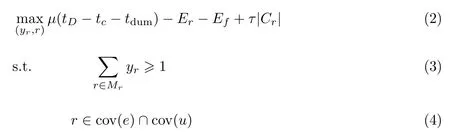
式(2)为模型的优化目标,即使目标用户获得最大效用;式(3)表示在该模型中至少会使用一个中继;式(4)则是对中继的约束条件,表示中继需要既能与目标用户通信获取目标用户发出的位置服务请求,又能与边缘服务器通信进行数据交互.下文对模型内的各部分进行详细解释,重要符号如表1所示.

表1 主要符号及其含义Table 1 Key terms and notation
在本文中,假设每条位置服务请求p的大小为mp;目标用户发出的请求数量为,这些请求构成的集合为Cu;中继所持设备发出的请求数量为,请求所构成的集合为Cr;中继所构成的集合为Mr;yr表示中继集合中的待选中继r是否被选中为中继,则yr={0,1}.在位置服务请求的传输过程中,中继用户所持的设备会依据边缘服务状态决定是否为目标用户发出的弱数量请求生成额外的假位置,因此会存在且满足Cu ⊆Cr.本文考虑如下5 个原子模块.
1)请求上行
目标用户的位置服务请求发送至边缘服务器的整个过程.位置服务请求首先由目标用户发出,在使用中继的情况下请求会先到达中继,再由中继发出到达边缘服务器.整个过程中,请求上行的时间tup满足
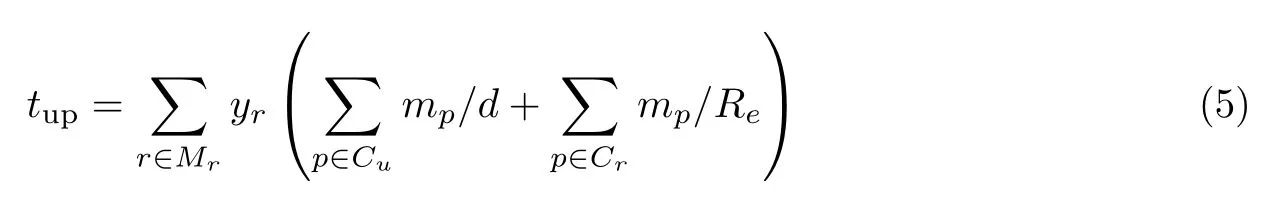
式中,d为中继的传输速率,Re为边缘服务器e的传输速率.
2)请求下行
边缘服务器将位置服务请求处理完成的结果发送给目标用户的过程.在使用中继的情况下,边缘服务器返回的结果会先到达中继,再由中继将结果发送给目标用户.整个过程中,请求下行的时间tdown满足
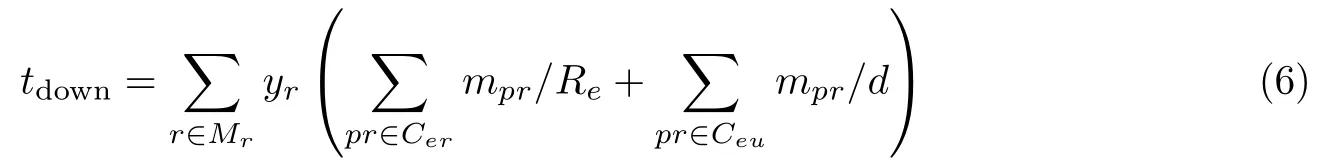
式中,pr表示来自边缘服务器的处理结果;Cer表示边缘服务器发出的结果集合;Ceu表示中继发出的结果集合.每个发出位置服务请求的设备内部会记录自己所生成的位置服务请求,当中继接收到来自边缘服务器的处理结果后,若在其中发现了自己生成的假位置服务请求则将这些结果过滤掉,之后再将结果返回给目标用户.因此,Cer和Ceu之间满足Cer ⊆Ceu.
3)请求处理
边缘服务器接收到目标用户的请求集合进行请求处理的过程.整个过程中请求处理的时间te满足

式中,qe表示边缘服务器e的处理能力;fp表示请求p的计算工作量.
4)假位置生成
目标用户或中继为位置服务请求依据假人方法生成假位置的过程.其中假位置生成所需的时间满足

式中,tp表示单个请求p的生成时间;C表示生成的请求集合;则表示请求集合C中的所有请求所耗费的时间.
5)激励模块
在实际应用中,服务请求者需要为其请求的基于位置服务支付一定的费用,以从中继和边缘服务器处获得更好的服务,为此本文提出了针对中继和边缘服务器的激励模块.
为了激励更多的用户自发充当中继,需要依据中继在服务请求过程中做出的贡献为中继用户付出一定的报酬.这里,本文使用ϕup表示在请求上行阶段,用户单位时间需要为中继用户付出的报酬;ϕdown表示在请求下行阶段,用户单位时间需要为中继用户付出的报酬.同时在联合保护状态下,中继需要为用户额外生成假位置.假设在此过程中,中继每生成一条额外的假位置服务请求,目标用户就需要支付报酬ϕ,则在位置服务请求的整个过程中,中继所获得激励满足
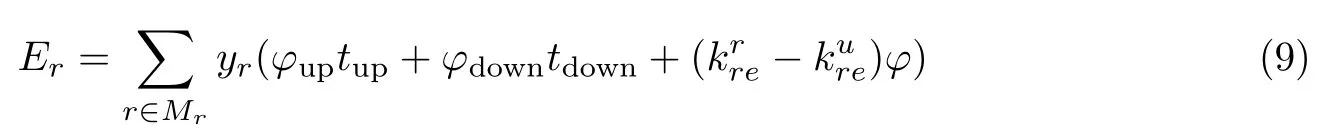
此外,用户还需要为从边缘服务器获取的资源付费.ρe表示单位时间内使用边缘服务器e所需支付的费用.则边缘服务器所获得的激励满足

当目标用户向边缘服务器发出位置服务请求时,具体的执行过程可以分为两个部分.一是假位置生成部分,二是请求传输和处理部分.
具体的假位置生成算法见下文5.1 节算法1,该算法可能在两个环节运行:一是基于目标用户的位置信息,在目标用户的设备上生成假位置的过程;二是在联合保护状态时,中继设备还会为用户生成一次假位置.则假位置生成所耗费的时间tdum满足
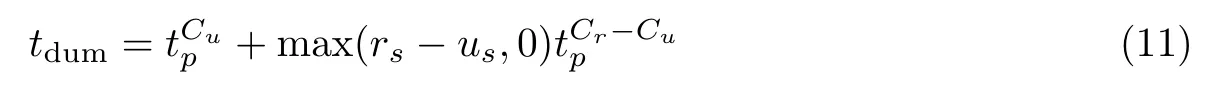
式中,表示目标设备生成请求所耗费的时间,表示中继生成请求所耗费的时间.
在请求传输和处理部分涉及请求上行模块、请求处理模块以及请求下行模块.该过程所耗费的时间tc满足

根据以上模型的原子部分,组成式(2)中表示的面向位置隐私保护的中继分流模型.
5 基于中继的服务请求分流方法
第4 节提出了面向位置隐私保护的中继分流模型,本节将给出基于中继的服务请求分流方法.首先,针对上述问题,图6中给出了问题求解的执行流程图.

图6 面向位置隐私保护的中继分流方法执行流程图Figure 6 Flowchart of the relay-assisted offloading method for location privacy protection
目标用户需要请求基于位置的服务时,会将自己的位置信息和请求内容作为输入交给假人方法.假人方法根据用户的位置信息生成若干个假位置构成请求集合.为了让用户体验更好的服务,需要将请求集合上传到边缘服务器.在本文的场景下,目标用户需要先选择合适的中继,将请求集合通过中继上传到边缘服务器进行处理,最后得到请求结果.
5.1 假位置生成方法
信息熵作为信息度量的有效工具,在通信领域已展现出重要的贡献.隐私作为一种信息,可以考虑用熵来量化.本文用熵表示从所有位置中识别出真实位置的概率,选择与Niu等[20]相同的熵的定义,将地图划分为N ×N个单元格.每个单元格都有1 个历史查询概率(称为查询概率),用变量qi表示,且对于查询中包含的k个位置(即单元格),其中包含一个真实位置和k −1 个假位置,每个位置都有一个成为实际位置的条件概率.设pi(i=1,2,···,k)表示第i个位置为真实位置的概率,则基于上述分析,得出熵H的定义为

算法1 描述了基于k-匿名的假位置生成算法,其目标是使本文提出的位置隐私保护方法为用户生成的假位置集合的熵最小.首先对每个单元格被查询概率按照从大到小的顺序进行排序,接着在属于时间段T的多个区间RT中选择前2k/SIZE(RT)(SIZE (RT)为区间的个数)个单元格构成候选区间集合CellT;然后在CellT中随机挑选k个单元格计算由这k个单元格组成的假位置集合的熵,重复多次选择熵最小的集合.
算法1基于k-匿名的假位置生成算法
输入:每个区间的查询概率qi,真实位置lreal,保护等级k,用户历史查询区间Regionhistory迭代次数β
输出:一组最优的假位置集合Dummies

5.2 中继选择方法
目标用户所持设备的通信范围内的设备集合为cov(u),边缘服务器的通信范围内的设备集合为cov(e).作为中继,r必须满足r ∈cov(u)∩cov(e).满足此条件的中继用户可以同时和目标用户与边缘服务器通信.为了选择适合的中继,首先需要确定目标用户状态和边缘服务状态.目标用户可以依据自身的运行情况获得自身状态.为了获得周围设备的状态,目标用户会先向周围广播获取中继的请求,接收到请求的设备会将边缘服务状态返回给目标用户.目标用户周围可能分布着多个可能作为中继的用户,所以目标用户会得到一个边缘服务状态集合S={s1,s2,···,sn}.
同时,在边缘计算环境中边缘服务器大多采用密集部署,因此一个用户可连接到多个边缘服务器.假设用户总是选择状态最佳的边缘服务器,那么对于任意的si ∈S,si=min(rs,max()).这里,表示可以与用户i的设备通信的边缘服务器的服务状态.
得到周围设备的边缘服务状态集合后,目标用户会查询该集合并从中挑选出待选的中继集合.具体的算法流程如算法2 所示.
算法2中继选择算法
输入:目标用户的周围设备的边缘服务状态集合S,目标用户服务状态us
输出:可作为中继的用户的边缘状态集合SC
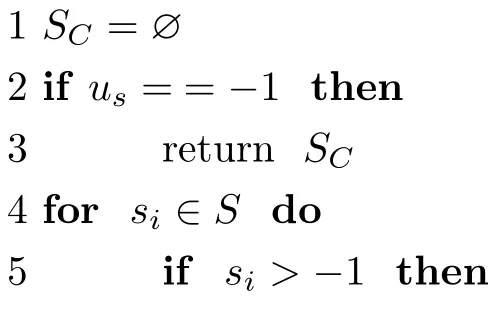

算法2 给出了中继设备的初步筛选方法.首先查询目标用户状态,若目标用户自身状态不佳,则难以发出基于位置的服务请求,因此也就不需要中继用户.之后,算法会在从目标用户周围的设备的边缘服务状态中筛选掉边缘服务状态为–1 的设备.本文称构成边缘状态集合的用户为待选中继,SC也称为待选中继边缘服务状态集合.
5.3 基于中继的服务请求分流方法
在基于位置的服务请求中,用户设备需要将所有请求上传到边缘服务器,交由边缘服务器处理,边缘服务器处理完请求后将请求结果返回给目标用户.在整个过程中,目标用户只需生成假位置信息,再将所有请求上传至边缘服务器.
目标用户设备将请求上传至边缘服务器之前需要先选择中继.执行完算法2 后,目标用户会得到边缘服务状态集合.集合中的边缘服务状态所关联的用户均可充当中继,但选择不同的中继可能会使目标用户处于不同的保护状态中.
本文中各种保护状态并没有优先级,目标用户可以依据式(2)选择合适的保护状态.不同保护状态会造成不同请求数量和不同中继数量.因此,在得到待选中继的边缘状态集合后,需要依据目标用户自身状态及待选中继的边缘状态选择合适的保护模式.根据保护状态的定义,可知共可能会出现以下4 种情况:
情形1(强保护) 目标用户处于强保护状态时,目标用户状态us=1 且边缘状态集合满足存在si ∈SC,且si=1.
情形2(弱保护) 目标用户处于弱保护状态时,目标用户状态us=0 且边缘状态集合满足存在si ∈SC,且si=0.
选中弱保护状态后,目标用户仅会发送弱数量请求,且中继仅发送弱数量请求就可以满足目标用户的要求.因此仅需一个中继就可以完成分流任务,与强保护类似,中继不会额外生成假位置,则有
情形3(联合保护) 目标用户处于联合保护状态时,目标用户状态us=0,边缘状态集合满足存在si ∈SC,且si=1.
处于联合保护状态时,目标用户发出弱数量请求后,中继需要为目标用户生成额外的假位置.此时
情形4(极限保护) 目标用户处于极限保护状态时,目标用户状态us=1,满足边缘状态集合,存在n个边缘状态s ∈SC,对于每个s,满足s=0.
在极限保护状态时,需要多个只能发出弱数量请求的中继来分担目标用户的强数量请求.因此由于在传输的过程中,中继并不会为目标用户生成额外的假位置,因此仍有
上述4 种情形是在实际的情形中可能遇到的情况.实际应用中需要依据实际过程中得到的边缘状态集合、用户状态、式(2)选择合适的保护状态.基于上述4 种情形,可以得到对应的分流方法,如算法3 所示.算法3 描述了基于中继的服务请求分流的过程.该算法先执行算法1 生成服务请求集合,再执行算法2 得到待选中继的边缘状态集合.之后,依据自身的状态及边缘状态集合中的各待选中继的情况,找到使式(2)最大的中继SR及请求的发送数量kr.
算法3基于中继的服务请求分流算法
输入:目标用户的周围设备的边缘服务状态集合S,目标用户服务状态us,α,匿名度k
输出:实际发送请求数量kr,中继集合SR
1 执行算法1 得到包含k −1 个假位置的服务请求集合
2 执行算法2 得到待选中继的边缘状态集合SC
3ifus=1then
4 遍历集合SC,找到边缘状态s=1 的中继,计算出情形1 时,式(2)的最大值,以及对应的请求发送数量kr,中继集合SR
5 遍历集合SC,找到边缘状态s=0 的中继,计算出情形4 时,式(2)的最大值,以及对应的请求发送数量k,中继集合SR
6ifus=0then
7 遍历集合SC,找到边缘状态s=0 的中继,计算出情形2 时,式(2)的最大值,以及对应的请求发送数量k,中继集合SR
8 遍历集合SC,找到边缘状态s=1 的中继,计算出情形3 时,式(2)的最大值,以及对应的请求发送数量kr,中继集合SR
9 找到使得式(11)最大的情形,得到对应的k,SR;
10returnk,SR
在实际应用场景中,边缘服务器通常无法提供云服务器完全等价的功能.边缘服务器通常仅拥有其所属片区的数据或缓存而无法拥有全量的数据库,一般情况下每一个边缘服务器只能服务特定的片区.在引入中继之后,可能会出现用户请求超出了边缘服务器所属片区的情形.本文对该情况做如下假设:当用户查询请求超出边缘服务器所属片区时,需要将用户请求转发至拥有中央数据库的云服务器进行处理.
6 性能分析
如第5 节所述,基于中继的服务请求分流方法主要包括3 个步骤:基于假人的位置选择、中继选择、服务请求分流.下面将从计算复杂度的角度结合上述3 个步骤对本文所提出的基于中继的服务请求分流方法进行性能分析.
基于假人的位置选择步骤中,首先需要对地图中的N ×N个单元格按照其被查询概率进行排序.本文拟采用快速排序的方法对上述N2个单元格进行排序,因此该操作需要的平均计算复杂度为O(N2lbN2).针对某一个特定查询请求Q,需要基于历史查询记录分别从与Q处在同一时间段T的查询区间RT中选择出前2k/SIZE(RT)个候选单元格.在上步操作中,各个单元格已按其被查询概率进行排序,因此该操作需要的平均计算复杂度为O(1);进一步地,从上述2k个候选单元格中随机选择k个单元格并进行熵计算,计算复杂度为O(k);同时,与目前的最大熵值进行比较从而得到最优位置集合Dummies,其计算复杂度为O(1).上述位置选择过程需要重复β次,因此基于假人的位置选择方法所需要的计算复杂度为O(N2lbN2+β×k)=O(N2lbN2)+β×(O(1)+O(k)+O(1)).
在中继选择步骤中,用户需要在其所处区域边缘服务器集合S中过滤掉服务状态为–1 的设备,生成候选中继边缘服务器集合SC,因此该步骤需要的计算复杂度为O(n)=O(|S|).
服务请求分流步骤则是用户在上述基于假人的位置选择和中继选择的基础上,根据其自身状态及待选中继的边缘状态选择合适的保护模式,并选择使式(2)效用值最大的中继SR和请求数目kr.根据用户选择保护模式的不同,该步骤所需的计算复杂度也有所不同.具体而言,在强保护、弱保护和联合保护模式下,目标用户仅需从候选集合中选择一个中继.因此,为使式(2)取得最大效用值,所需的计算复杂度为O(n)=O(|SC|).而在极限保护状态下,目标用户则需要选择x个(x>1)中继来实现服务请求分流.x的取值范围为[2,n],因此在极限保护状态下,计算复杂度为
综上所述,在强保护、弱保护和联合保护模式下,本文提出的基于中继的服务请求分流方法的计算复杂度为O(N2lbN2+β×k+n).而在极限保护模式下,上述基于中继的服务请求分流方法的计算复杂度为O(N2lbN2+β×k+2n).
7 实验评估
本节将介绍两种基准方法并通过大量实验对这两种方法与本文提出的方法进行对比分析,以验证本文提出方法的性能.所有实验均在配备Intel Core i5-8265U 处理器(8CPUs,1.60 GHz),8GB RAM 的Windows 机器上进行.
7.1 对比方法
本文首先提出了基于k-匿名的假人方法,在基于假人的方法中提出了基于中继的服务请求分流方法.为了证明该方法的性能,本文将基于中继的服务请求分流方法与以下两种方法进行对比,以证明基于中继的服务请求方法的性能.
1)边-云执行:目标用户生成假位置后,将位置服务请求传送给与其直连的边缘服务器进行执行.若直连的边缘服务器无法处理目标用户的请求,则将请求转发至云端进行处理.
2)边-边-云执行:目标用户生成假位置后,将位置服务请求传送给与其直连的边缘服务器进行执行,若直连的边缘服务器难以支持服务请求的计算,则将该请求转发给邻近的边缘服务器.在邻近的边缘服务器也无法执行时,将请求转发至云端进行处理.
7.2 实验设置
7.2.1 实验数据
本文用一个开源的实验数据集来证明所提出方法的有效性.澳大利亚通信和媒体管理局(ACMA)发布的无线通信许可证数据集包含了澳大利亚所有的蜂窝基站的地理位置(即边缘服务器部署的位置).本文用墨尔本蜂窝基站的位置数据EUA-dataset(https://github.com/swinedge/eua-dataset)作为测试数据集的方法,用来模拟边缘服务器的真实位置和用户分布.
7.2.2 实验参数
依据以往工作中的实验设置[26],本文设置µ=500,用户对于不同匿名度的收益参数设置为T=500,将每个边缘服务器的使用价格区间设置为[10,40],每个中继的价格区间设置为[3,10].在实际的实验过程中,假设用户期望时间tD=0.8×tcloud,这里tcloud表示服务请求上传至云端执行所耗费的时间.此外,实验中将云服务器的响应时间设置为1 s,将边缘服务器的响应时间设置为0.3 s.为验证本文提出的基于中继的分流模型能够有效缩短用户请求的执行时延,本文假设广播获得中继的时间与边缘服务器响应时间一致,均为0.3 s.
7.2.3 度量指标
本文设置了3 个度量指标:1)在接收用户相同请求任务条件下,任务的平均完成时间,该值越低越好;2)在期望时间tD之前完成的任务占总的任务个数的比例,该值越高越好;3)用户实际发送的服务请求个数kr,该值越高越好.
本节通过控制两个可能影响实验性能的变量来观察本文提出方法的性能变化情况.
1)匿名需求k
k反映了用户的匿名需求,k值越高说明隐私保护能力越好.实验中k的取值设置为:k=5,10,15,20,25,30,35,40,45,50.
2)活跃边缘服务器比例p
p反映了当前区域可以正常工作的边缘服务器占总的边缘服务器个数的比例.这些正常工作的边缘服务器的状态包括{0,1}.本实验中p的取值设置为:p ∈{0.55,0.60,0.65,0.70,0.75,0.80,0.85,0.90,0.95,1}.
基于上述实验配置,本节通过3 组实验分别对本文提出的方法及两个基准方法进行验证与对比分析,3 组实验的设置均采用控制变量法观察匿名需求k和活跃边缘服务器比例p对任务完成时间、任务完成比例、用户实际发送请求数目的影响,具体设置如表2所示.

表2 实验设置Table 2 Experimental setting
7.3 实验结果
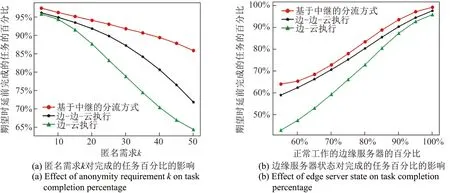
在实际实验中,目标用户需要依据自身状态决定发送的请求数目.当目标用户状态us=1时,目标用户发出的实际请求数目kr=k.否则,目标用户会随机生成kr个请求,且kr 图7 匿名需求k及边缘服务器状态对任务平均完成时间的影响Figure 7 Effect of anonymity requirement k and edge server state on task’s average time cost 第一组实验从任务平均完成时间的角度比较了3 种算法的性能.图7中的纵坐标展示了任务的平均完成时间.从图7(a)中可以看出,随着匿名需求k的数目增加,3 种算法的任务平均完成时间均在增加.但基于中继的服务请求分流方法的任务完成平均时间一直是最优的.图7(b)则展示了随着可用边缘服务器数量的增加,3 种算法对应的任务平均完成时间均有所下降,且基于中继的服务请求分流方法一直保持着更好的性能.上述结果的原因分析如下:对于边-边-云执行方法,目标用户的服务请求只能利用其直连边缘服务器,或直连服务器的邻居服务器进行服务请求的响应.在匿名需求高或可用边缘服务器数量较少的场合,人员密集区域的边缘服务器的负载较大,易造成大量用户的服务难以在边缘进行,因此需要频繁将用户请求上传至云端处理.而对于边-云的执行方式更是如此.但基于中继的服务请求分流方法却可以利用中继将任务分散给多个边缘服务器执行,因而性能最优. 第二组实验从期望时间之前任务完成比例的角度比较了3 种算法的性能.图8中的纵坐标展示了在期望时间之前完成的任务所占总任务的比例.从图8(a)中可以看出,随着匿名需求的数目增加,3 种算法在期望时间之前完成的任务比例都在下降.但基于中继的服务请求分流方法的性能一直是最优的.图8(b)中展示了随着可用边缘服务器的数量的增加,3 种算法在期望时间之前完成的任务比例都在上升.可以看出基于中继的服务请求分流方法总能保持较好的性能.上述结果的原因与第一组实验的分析过程相似:对于边-边-云执行方法,在匿名需求高或可用边缘服务器数量较少的场合,边缘服务器的负载较大,需要上传至云端处理.对于边-云的执行方式更是如此.但基于中继的服务请求分流方法却可以利用中继将任务分散给多个边缘服务器执行,因而性能最优. 图8 匿名需求k及边缘服务器状态对完成的任务百分比的影响Figure 8 Effect of anonymity requirement k and edge server state on task completion percentage 图9 匿名需求k及边缘服务器状态对请求数目的影响Figure 9 Effect of anonymity requirement k and edge server state on the number of requests 第三组实验主要从实际的请求发送数的角度比较3 种算法的性能.从图9(a)中可以看出,随着匿名需求的提升,3 种算法的实际发送的请求数都在上升,但基于中继的服务请求分流方法的实际发送请求数总是最多的.在图9(b)中,随着正常工作的边缘服务服务器的数量增长,3种算法的实际发送请求数也都在上升.但基于中继的服务请求分流方法的性能总是最优的.这是因为,目标用户会依据自身的状态和边缘服务状态来确定实际发送的请求数量.而在边-边-云执行和边-云执行的情形下,实际发送的请求数量会受到目标用户状态和边缘服务器的状态的制约,二者只要有一个状态值小于1,则目标用户只能发送出弱数量请求.但基于中继的服务请求分流方法可以利用多个中继实现极限保护,依然可以发出强数量请求.因此,基于中继的服务请求分流方法总是可以获得最优的性能. 本文针对云计算环境下,基于假人的位置隐私保护方法会造成用户获取结果的时延过高问题,提出将位置隐私保护方法迁移到边缘计算环境下的解决方案.针对边缘服务器的服务能力与覆盖范围具有上限的特点,本文提出了面向位置隐私保护的中继分流模型,实现了其中的分流方法,并在真实数据集中验证了本文所提出的方法.今后的研究工作将主要关注如何改善假位置的生成方法,在降低假位置生成算法的时间复杂度的同时提升匿名效果.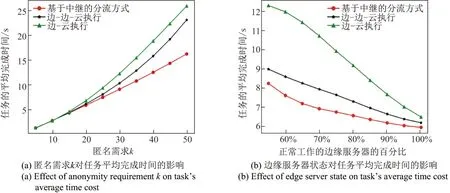

8 结 语
猜你喜欢
预防青少年犯罪研究(2022年1期)2022-08-15 00:35:32
电子技术与软件工程(2019年21期)2020-01-16 05:55:44
电信科学(2017年6期)2017-07-01 15:44:53
电信科学(2017年6期)2017-07-01 15:44:35
通信产业报(2016年44期)2017-03-13 08:41:45
航天器工程(2015年3期)2015-10-28 03:35:28
电子设计工程(2015年16期)2015-02-27 12:07:46
肝胆胰外科杂志(2015年1期)2015-02-27 11:11:30
电子设计工程(2012年9期)2012-02-15 03:29:22
雕塑(1999年2期)1999-06-28 05:01:42
