
基于配对排序损失的文本多标签学习算法
2020-10-21 00:57顾天飞彭敦陆
小型微型计算机系统 2020年10期
顾天飞,彭敦陆
(上海理工大学 光电信息与计算机工程学院,上海200093)
1 引 言
文本分类是自然语言处理领域中的一项重要任务,是构建信息检索、对话机器人等复杂系统的基础.多分类假设类别之间是互斥的,即一篇文档有且只能归属于单个类别.而事实上,对象是多语义的,比如一篇新闻能同时标注上“体育”和“足球”标签.所以,多标签更适合用来对现实问题进行建模,并有其实际的应用背景和学术价值.
多标签学习存在多标签分类和标签排序两类任务[11],前者将标签集划分为与样本相关和不相关两部分,后者则预测标签之间的前后关系.上述两项任务存在共通性,多标签分类和标签排序之间是可以相互转换的,文献引入校准标签对排序的标签进行划分[14],而采用判别模型完成多标签分类时,样本对标签的后验概率天然具有可排序性[5].故而,学界和业界开始尝试将两项任务联合起来进行解决,并运用于不同的应用领域[6,9,16].大体上,这类方法基于以下思想,得分较高的标签更能体现样本的语义,模型应使正标签集排在负标签集之前,这样筛选出来的标签也更加精准[16],从这一角度看,标签排序考虑到了标签的相对关系.
对于文本处理,过去的研究普遍采用文本特征手工提取的方式[19,20].得益于深度学习的发展,端到端的深度表征模型已成为当今的主流[1-5,7,8,15].与此同时,深度模型的性能受到标注数据缺失和语义提取不足的限制.为此,本研究引入迁移学习,将BERT[1]作为模型的特征提取部分,将多标签分类和排序共同纳入考虑,利用标签之间的相对关系来增强多标签预测的有效性.文献普遍采用错误排序统计[10]和铰链损失[9]刻画多标签排序误差,但这些损失函数通常难以优化,尤其在深度模型的背景下.故本文采用一种替代的配对排序损失,该损失函数在实数域上可微,同时也是铰链损失的边界.此外,为了更准确地获得文本实例对应的标签集,标签的筛选被看作为一项二值分类,用一个辅助网络构建筛选标签的阈值.
本文的贡献如下:1)将迁移模型BERT运用于文本多标签学习;2)提出配对排序目标函数对标签排序任务进行建模,并给出了相应的理论分析.最后,为了决断出精准的标签集,算法引入额外的辅助网络进行阈值预测.
2 相关工作
一般地,解决多标签任务存在两类思路,问题转换和算法适应[11].前者将多标签学习转化为二值分类[11]、多分类[12]或标签排序[14],后者则修改现有的学习算法以适应多标签领域[13].上述技术主要集中于传统机器学习,往往存在严重的性能瓶颈,计算规模和标签空间呈正比[10-14].如今,神经网络在模式识别领域获得了巨大的成功,其中很大一部分运用到了多标签学习中[3,5-9].
传统的文本分类算法受限于语义和句法信息提取能力的不足,深度模型已经成为了该领域的主流.文献[15]率先采用词向量word2vec[17]进行词嵌入和卷积神经网络作为特征提取器,获得了显著的性能提升.该模型奠定了深度文本分类的一种范式,即模型一般由词嵌入层、衔接模型和分类器三部分组成.如何通过海量的语料库无监督学习到词的表示是一项热门研究,Word2vec[17]通过对词语上下文和语义关系进行建模,将词语嵌入到稠密的欧式空间中.BERT[1]由多层Transformer[4]构建而成,能解析出更深层的语义,并能适用于各项下游任务.
文本多标签学习需要考虑到两方面,文本信息的提取和标签之间的相关性,现有的研究基本上是围绕这两方面展开的.一部分研究构建了基于卷积神经网络的模型[5,7,8],文献[3]采用了二值交叉损失对多标签进行建模,文献[8]引入指示神经元对标签共现进行建模,以利用标签的信息,文献[5]将标签预测看作为序列生成,引入循环神经网络构建标签之间的关系.文本序列的各个位置对标签的影响是不同的,SGM[3]利用注意力机制加强模型的关注性.
排序学习的目的是通过机器学习算法对项目进行排序,在信息检索、推荐系统中运用极为广泛.多标签学习存在以下假设,与样本相关的标签在排序上高于不相关的标签,所以排序任务能很好的刻画这种标签关系.文献[16]最早将文本多标签分类看作为一项排序任务,并利用配对排序损失刻画误差,但文献仅在多层感知机模型上验证了损失函数的有效性.配对排序损失也可以应用于图像检测领域[6,9],但研究中普遍采用的铰链损失存在训练困难的问题.为了弥补上述缺点,本研究在深度文本多标签学习背景下,尝试了语言模型的迁移学习,并着重了探讨了配对损失的使用.
3 本文工作
本章将首先给出问题的定义,然后提出结合BERT的文本特征提取模型,最后给出配对排序和标签阈值预测的设计,以及相关的目标函数.
3.1 问题描述
定义1.多标签排序任务,给定样本x,若s*为理想的映射函数,则需满足以下性质:
(1)

3.2 多标签文本学习模型
在深度自然语言处理中,一个端到端模型一般由以下几个步骤组成,首先将原始文本序列嵌入至稠密的表征词嵌入h1,h2,…,hl,其次通过衔接模型将词嵌入序列转化为定长的表征向量,最终输入到文本分类器中.对词嵌入表征的研究和应用向来受到学界和业界的广泛关注,通过预训练词向量使词嵌入涵盖语义和语法信息.然而,类似于Word2vec词向量模型存在无法解析一词多义,上下文信息缺失等缺点,往往对性能的提升并不明显.BERT作为一种语言迁移模型,可以较好地弥补上述缺陷.
在词嵌入阶段,bert(·)将原始文本序列x中的每个元素映射到固定尺寸的嵌入,映射方式如下:
h1,h2,…,hl=bert(w1,w2,…,wl)
(2)
这里,h∈d,d>L的维度由bert(·)决定.衔接模型用于对嵌入进行整合,文献中,通常会垒砌大量模型[5,15],对于这一环节本研究不做过多地复杂化,采用均值操作mean(·)将嵌入序列转化为d维的特征向量f:
(3)
接下来,考虑标签相关性得分的建模,由d维特征向量向L维向量映射,形式化为:
s=relu(Wsf+bs)
(4)
其中,Ws∈L×d为权重矩阵,bs∈L为偏置向量.式(4)中的relu(·)为神经网络的激活函数.至此,对某个输入样本x,便能得到模型对各个类别的打分s,即为类别对样本的相关性.多标签和多类别分类在判决函数上存在一定差异.多类别假设类别之间是相互独立的,故而往往取得分最大的类别作为输出标签.在多标签分类中,每个实例对应的标签数是不同的.简单的做法是取前k最大得分或设置全局阈值(将得分大于某一阈值的标签筛选出来),这些方法会造成额外的预测误差.本研究将采取一种更灵活的做法,即让g(·)作为一项可学习的函数,为每个标签自动地学习得到适应于样本特征f的阈值.阈值建模类似于标签相关性得分模型:
θ=relu(Wthrf+bthr)
(5)
模型的预测同时依赖于式(4)和式(5):
(6)
上式中,si,k表示样本与标签的相关性得分si的第k分量,θi,k表示阈值的第k分量.图1为模型的整体框架.
3.3 多标签配对排序损失
上节介绍了结合语言迁移模型的多标签分类模型,本节将引出如何对模型参数进行优化.形式上,需要解决如下优化问题:
(7)
这里,l为每个样本上的损失项,R为模型参数的正则项,Φs=[Ws,bs]为标签相关性得分模型的参数.在训练式(7)时,解冻bert,对其进行参数微调.由定义1可得,属于Y的标签得分需尽可能地大,反之亦然.借鉴三元损失,易对损失进行建模:

图1 算法框架Fig.1 Architecture of algorithm
(8)
式(8)采用了铰链损失,α是一项超参数,用来设定相关与不相关标签之间的边界.该损失函数是非光滑的,在x=0处不可微,从而造成了优化的困难.为解决上述问题,本研究考虑引入替代损失:
(9)
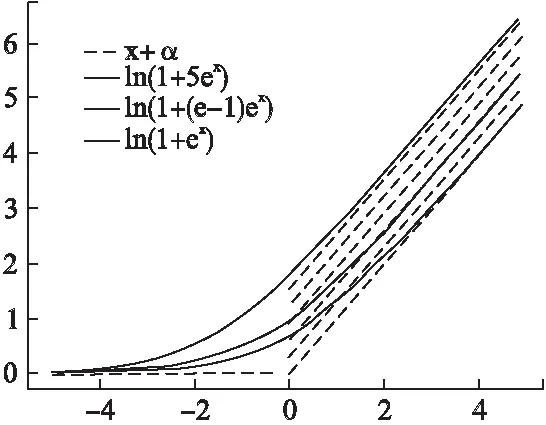
图2 损失函数ls的性质Fig.2 Property of loss function ls
上式中,β是常系数.替代损失式(9)是式(8)光滑的近似.由图2中实线可见,该损失函数为实数域上处处可微的凸函数,在+上为铰链损失的边界,当且仅当,β=ea-1.此外,β值越小,则实线越接近y=0.章节4给出了相应的梯度求解,并且从经验误差最小化和贝叶斯最优预测角度进行理论分析.
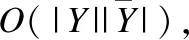
(10)
3.4 阈值模型损失
式(5)为阈值回归模型,根据样本特征为每个标签学习筛选阈值θ,并通过式(6)得到最终的预测标签集.对某个标签来说,预测可以转换为一项二值问题,得分大于阈值为正样本,反之作为负样本.于是,阈值参数的目标函数可以写成以下形式:
(11)
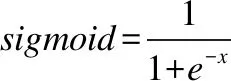
4 理论分析
本章首先对优化目标函数进行梯度计算,考虑式(10)对sm和sn的梯度为:
(12)
(13)
整合式(12)和式(13)可以得到:
(14)
这里,ξn,m为L维向量,其中第n项为+1,第m项为-1,其余项为0,以上计算结果说明说明了目标函数在实数域上式处处可微的.文献[18]从经验误差最小化和贝叶斯最优预测角度,证明了排序统计的有效性.相同地,对损失函数式(9)进行理论分析,式(10)作为简化版本同理可得.考虑贝叶斯预测准则:
sk(x)=p(k∈Y|x)=∑Y∈y,k∈Yp(Y|x)
(15)
上式决定了标签λk的得分即相应的排序,p(k∈Y|x)为标签域中所有可能的标签集的边际分布.
定理1.采用损失函数式(9)能达到经验损失最小化.
证明:考虑损失函数经验误差最小化:
R(s)=[ls(s(x),Y)]
(16)
将式(16)改写成条件经验损失的形式:
R(s|x)=[ls(s(x),Y)|x]
(17)
这里,γm,n=ln (1+esTξm,n).现需找到使经验损失最小化的得分函数s*,即尽可能满足定义1.计算式(17)的一阶和二阶导:
(18)
(19)
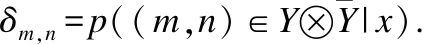
(20)
(21)
替换式(21)中的(n,m),得到:
(22)
(23)
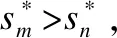
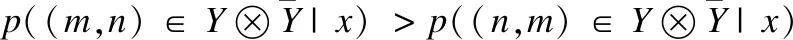
(24)
式(24)易得p(m∈Y|x)>p(n∈Y|x),基本满足贝叶斯预测准则.综上,以式(9)作为排序损失,能达到经验损失最小化.
5 实验评估
本章节将在真实的中文文本数据集上验证本文所提算法的性能,实验首先对比了不同的标签决断方法和损失函数的表现,最后与一些主流的方法进行比较.
5.1 实验数据
本实验选用了法研杯比赛CAIL2018(1)https://github.com/thunlp/CAIL罪名预测任务,来进行算法验证.为减少训练时间,选取了187100份样本,并根据8∶1∶1的比例将数据集划分为训练集,测试集和验证集.多标签数据集存在额外的性质,表1给出相关的信息.在文献中,Card和Dens分别表示样本所属标签平均数量和标签密度.标签集数量较大说明存在大量标签共现的情况,如何利用上标签的关系显得额外重要.

表1 多标签信息Table 1 Data set information
5.2 实验设置
1)实验平台:本研究中所有的代码都由Python编写,模型基于Tensorflow搭建.采用哈工大提供的BERT(2)https://github.com/ymcui/Chinese-BERT-wwm预训练模型,该版本在海量的中文语料库上完成训练,并在各项中文任务验证了其有效性.设备系统为Ubuntu16.04,配备两块NVIDIA GeForce 1080Ti显卡,内存为64G.
2)数据预处理:原始文本数据已经做了脱敏处理,本实验将作进一步地优化,去除了文档中的特殊符号,西文字符等.由于文书是存在格式的,其中有些子句实际上是无用的,比如“人民检察院指控”,“公诉机关指控”或者文书审理日期等,实验中将上述字符串从文档中剔除.为处理数据集存在的多标签不平衡问题,这里首先按照50:50的比例将标签集划分为多数类和少数类,并对少数类进行上采样处理.
3)实验参数设置:第一阶段对标签得分模型进行优化,该阶段解冻bert的参数,做参数微调.第二阶段冻结bert,仅对阈值模型进行优化.两个阶段皆采用ADAM优化器,学习率设置为0.001.BERT模型输入序列的尺寸上存在限制,最大输入为512,训练中将长文本按200字符为单位进行分割,模型预测过程中,将由各个划分的特征均值作为完整文本的特征.式(10)配对子采样的数量为120.由式(14)可知,超参数β是一项平滑参数,对梯度的尺度和训练的收敛性存在一定影响,与学习率的功能是相似的.β过大会使损失函数趋向于线性,过小则趋向于为零,在超参数调优过程中,尝试了区间0.1至2都能使训练收敛,故方便起见这里设置为1.
4)评价指标:本研究同时考虑到了多标签的分类和排序两方面,所以实验也将从这两方面对预测结果进行评估.下面所阐述的评价指标都参考自文献[11],采用宏观和微观F1得分衡量分类性能:
(25)
(26)
这里,eval=2·prec·recall/(prec+recall)为F1得分,用于调和准确率prec=TP/(TP+FP),召回率recall=TP/(TP+FN).在以上式子中,TP表示为真正样本,FP为假正样本,TN为真负样本,FN为假负样本.用排序误差衡量排序性能:
RankL=
(27)
排序损失RankL统计预测结果中的对误排标签对,数值越小越好.
5.3 实验结果分析
本章节将通过实验评估本文所提算法的有效性.
实验1.不同标签决断方法
在章节3.2中提到了其它两种标签决断方法,Top-k和全局阈值,在使用中,k值取1、3和5,阈值从0.05-0.95按照0.01为间隔,表2展示测试集上最优得分.值得注意的是,本文提出的得分模型其输出是映射到实数域上的,所以通过sigmoid将其约束到概率空间中.相对来说,宏观和微观指标衡量了模型的整体分类性能,对标签的误选较为敏感,Top-k和全局阈值是静态的刷选策略,而没有考虑到了样本特征本身所携带的信息,从而造成得分上的下滑.并且,在使用这些算法的时候往往会遇到超参的优化问题.表2中的结果说明在多标签领域,标签决断对最终预测结果的影响非常大.相比于全局阈值,阈值预测方法在分类指标上能提供2%的提升,排序指标上也是表现最优的.
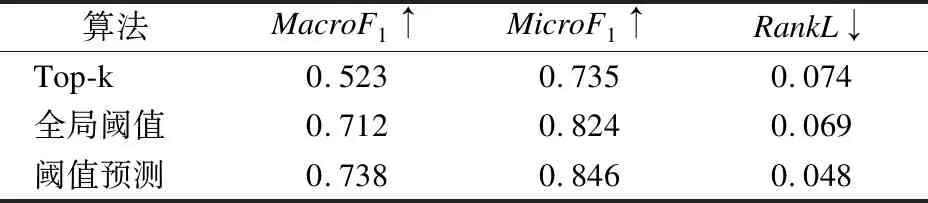
表2 标签决断技术的对比Table 2 Comparison of label decision
实验2.不同训练方式
本实验将配对排序损失和其它几种目标函数进行比较:
1)二值交叉损失[5](BCE):
(28)
BCE相当于标签转换,类似于参数共享的二值分类模型;
2)铰链损失式(8);
3)BP-MLL[8]基于指数损失.为了确保方法之间的可对比性,实验采用同一套数据预处理技术,并且默认采用阈值预测技术.表3展示了各种训练方式之间的性能对比.可以看到BCE在微观指标上的表现略微占有,但在其余指标上,文本的算法存在竞争性的优势.这是由于BCE注重整体的分类误差,配对排序损失则考虑错误的排序对.宏观指标是标签F1得分的平均,本文的算法在MacroF1上的优势也体现了数据不平衡对配对排序损失的影响较低.

表3 训练方式之间的对比Table 3 Comparison of training approaches
实验3.不同模型进行对比
前两项实验分别从标签决断和训练方式做了对比,本实验将选取一些常用的多标签算法进行完整的对比:
1)二值相关BR[11]为每个标签训练一个SVM分类器;
2)ML-KNN[13]将KNN拓展到多标签领域,是一种惰性学习器;
3)卷积神经网络CNN[5]是最常用的深度文本模型;
4)CNN-RNN[7]采用循环神经网络对标签之间的关系进行建模.
接下来将对上述算法的执行流程做一定阐述,对于词级模型,首先中文文书进行分词,算法1)2)采用TF-IDF算法进行特征提取,算法3)4)则将词嵌入至定长向量.
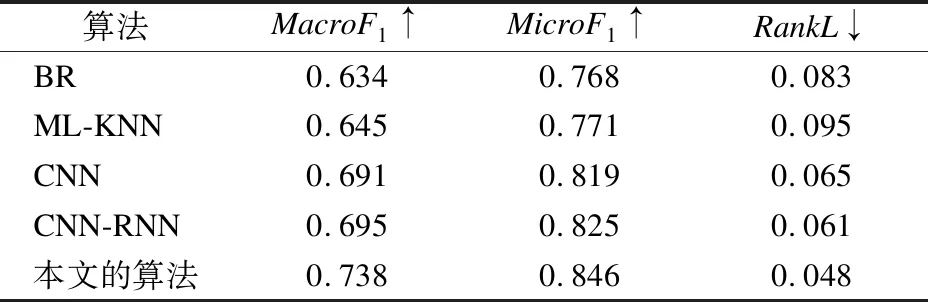
表4 不同算法性能对比Table 4 Performance comparison of different algorithms
表4展示了在全数据上,不同算法之间的性能比较.图3展示了在不同比例数据集上的分类性能.实验结果显示,随着数据规模的增大,深度学习算法能获得更好的表现.相比于另两种深度模型CNN和CNN-RNN,本文提出的算法的整体性能都较优.这是由于研究在文本特征提取和标签决断上都做了考虑.迁移的BERT模型能提供数据集之外的语义知识并且具有更多的参数量,由图3可见,模型表现受到数据集尺寸的波动较小.配对排序损失能铺捉到标签之间的排序关系,使相关度较高的标签能获得更大的得分,同时,自适应的标签阈值学习能帮助算法得到更精准的预测结果.
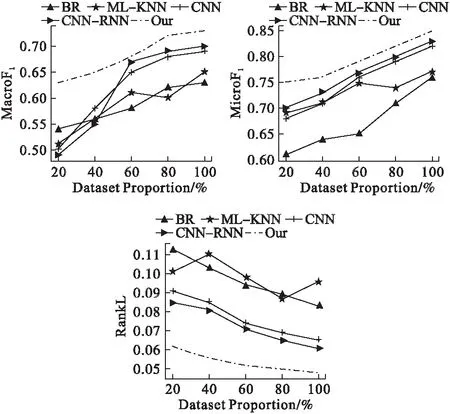
图3 不同比例数据集上的对比Fig.3 Comparison with different dataset proportion
6 总 结
多标签文本学习能帮助用户对文档进行有效管理,加强多媒体系统的可用性.传统的,基于机器学习的算法受限于特征提取和模型容量,存在严重性能瓶颈.本文提出的算法利用中文BERT预训练语言模型对文书进行特征提取,模型架构上更精炼且高.算法选用配对排序损失作为目标函数,以铺捉到标签之间的关系.此外,为了更精准地得到结果,引入辅助的阈值预测模型,对标签预测进行建模.实验在法条预测和罪名推荐两项任务上验证了算法的有效性.作为自然语言处理的一项子任务,BERT对多标签文本分类也是适用的,将阈值预测看作一项学习任务,相比Top-k和全局阈值,在测试集上表现更优异.未来我们将在更多的多标签数据集上对算法进行验证,并将对标签之间的相关性做进一步探讨.
猜你喜欢
今日农业(2022年15期)2022-09-20
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
名家名作(2021年4期)2021-05-12
智能计算机与应用(2020年4期)2020-08-31
科普童话·学霸日记(2020年1期)2020-05-08
小天使·二年级语数英综合(2019年10期)2019-11-08
小天使·一年级语数英综合(2019年2期)2019-01-10
读者·校园版(2015年19期)2015-05-14
