
基于近红外光谱技术的小米产地溯源研究
2020-10-19 00:32杨春杰
食品与机械 2020年9期
李 楠 杨春杰
(1. 运城学院生命科学系,山西 运城 044000;2. 运城学院机电工程系,山西 运城 044000)
小米又称粟(米),禾本科狗尾草属[1]。在中国,作为五谷之一的小米有着悠久的食用历史,数千年来一直作为传统主食养育了中国北方文明,在现代仍是主要杂粮之一[2]。小米的产地来源与其品质密切相关,地域特色小米具有反映该区域自然环境的特有品质,中国已出现许多名优原产地域小米产品群落。假冒产地不仅损害消费者和企业利益,同时也增加了食品安全问题追溯与风险管理难度[3]。农产品产地溯源方法主要包括特定化学成分(如矿物元素、同位素、多酚、糖、氨基酸等)差异分析的破坏性溯源方法和光谱、仿生(电子鼻、电子舌)、介电特性、核磁共振检测等无损溯源方法[4]。其中,近红外光谱技术因其高效、无损、环保等优点已成为近几十年来发展最迅速的无损检测技术之一,也被认为是当前经济性最高的食品溯源技术[4-8]。近红外光谱技术已被应用于茶叶[9-10]、橄榄油[11]、肉类[12-14]、酒类[15-17]等食品的产地溯源研究,显现出较好的应用前景。目前,采用近红外、高光谱、拉曼光谱等光谱技术的小米产地溯源研究较少,同时这些研究多存在样本数量较少[18-20]、样本产地来源偏少[18-22]、模型预测准确率偏低[18]等问题。此外,相关研究多使用体积大、价格高的精密型近红外光谱仪,在实际应用方面存在一定局限。因此,研究拟以来源于11个主产省份的150份小米样品为研究对象,采用便携式近红外光谱仪检测样品,同时为了提高模型准确率和泛化能力,采用鲁棒主成分分析(rPCA)识别异常数据,并采用DUPLEX方法划分样本集,进而比较主成分分析、线性判别、人工神经网络等模式识别方法的分类结果,为利用近红外光谱技术实现小米产地溯源提供参考。
1 材料与方法
1.1 材料
小米样品:采集于中国11个省份,涵盖所有国内小米主产地(见表1)。小米采集后铝箔袋真空密封,4 ℃保存。
1.2 仪器与设备
便携式近红外谷物分析仪:ZX-50IQ型,美国Zeltex公司;
真空封口机:RS-BZ11A型,合肥荣事达电子电器集团有限公司;
电子天平:FA1604型,上海舜宇恒平科学仪器公司。
1.3 方法
1.3.1 光谱采集 样品预先放置于25 ℃环境自然升温至室温。近红外分析仪开机预热30 min后校准。每次测量时,称取50.0 g样品,均匀置于样品杯,然后放于样品室关闭遮光罩进行测量。每个样品测量3次,取平均值作为最终分析光谱值。
1.3.2 数据分析 采用鲁棒主成分分析(rPCA)方法剔除样品光谱数据异常值后,使用DUPLEX方法将数据按3∶1划分为训练集和预测集,最后对数据进行主成分分析(PCA)、费舍尔线性判别分析(LDA)及多层感知器神经网络(MLP-NN)建模识别分析。建模分析采用SPSS20软件;异常值检测、训练集及预测集划分采用Matlab R2015b软件。
2 结果与分析
2.1 样品近红外光谱
由图1可知,不同样本的光谱形状具有相似性,但吸收峰的位置均存在一定的差异性,说明不同产地小米的组成成分存在差异,这些差异通过近红外光对含氢基团(C—H、N—H、O—H、S—H等)振动的倍频和组合频吸收不同而生成差异化的红外光谱图。为保证光谱数据具有代表性,每个样品测量3次,取平均值作为最终分析光谱值。由于试验使用的便携式近红外分析仪只有14个近红外波长,且小米样品在不同波长下的吸光值均有差异,因此将全部波长数据用于后续分析。
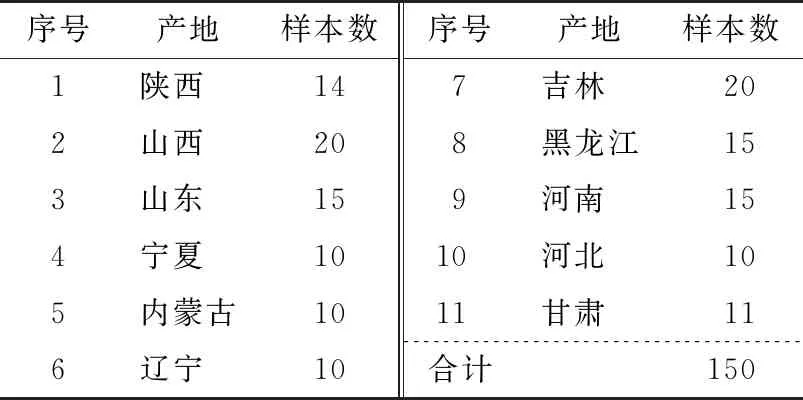
表1 小米样品产地及数量
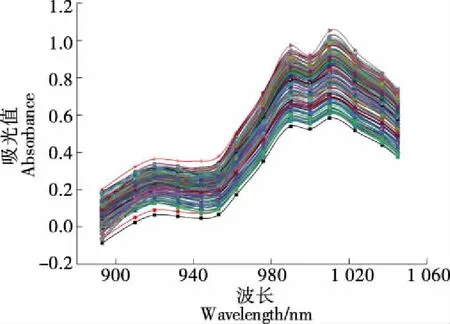
图1 不同产地小米近红外光谱图Figure 1 Near infrared spectra of millet samples from different origins
2.2 异常值检测
异常值会影响模型的可靠性,甚至会导致模型严重失真,因此在模型建立前需要识别并剔除异常值。鲁棒主成分分析(rPCA)被用于识别异常值,该方法能够高效识别出异常值[23]。首先计算每个样品的主成分得分距离(SD)和正交距离(OD),然后将样品分为4组:常规组(低SD低OD)、良好主成分转换组(高SD低OD)、正交异常值组(低SD高OD)、不良主成分转换组(高SD高OD),后两组样品不利于模型分析,被识别为异常值。如图2所示,产自陕西的14个样品中,2、7、9、13号共4个样品异常值被检出。同样的方法识别其余样品组异常值,最终得到131组数据用于进一步分析。
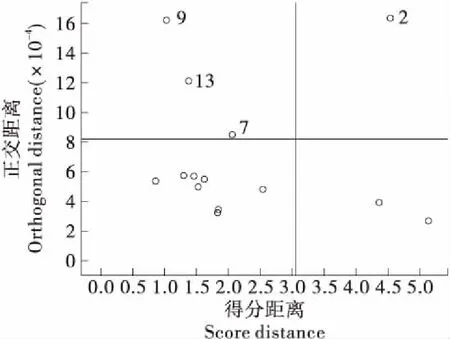
图2 小米样品鲁棒主成分分析检测异常值Figure 2 The outlier diagnosis obtained by rPCA for millet samples
2.3 主成分分析(PCA)
主成分分析是一种无监督的分析方法,在尽可能保证原有信息的前提下将多元数据降维转化为少数新变量,减少数据冗余,进而方便理解和展示原有变量差异。依据前两个主成分得到的PCA得分图,可以直观地表现原始数据所代表的样本状态,样品点的聚集、离散程度反映出样品间的差异大小。如图3所示,第一主成分的方差贡献率为95.48%,第二主成分的方差贡献率为4.22%,合计为99.70%,因此前两个主成分可以充分反映原始数据信息。山西、河南、黑龙江3省内的样品点分布较为分散,其余省内样品点分布相对集中,说明来自于山西、河南、黑龙江3省样品的省内差异较大,其余省份样品的省内差异较小。同时,山西、河南、黑龙江3省样品点与其余8个省份样品点部分重叠,但8个省份样品点分布相对独立且界限清晰,说明除了山西、河南、黑龙江3省份样品与部分省份样品差异较小之外,其余省份样品省间差异明显。上述结果说明在主成分分析中,除山西、河南、黑龙江3省的样品省内差异较大导致难以区分省间差异外,其余省份的样品均能依据省间差异区分省份产地。
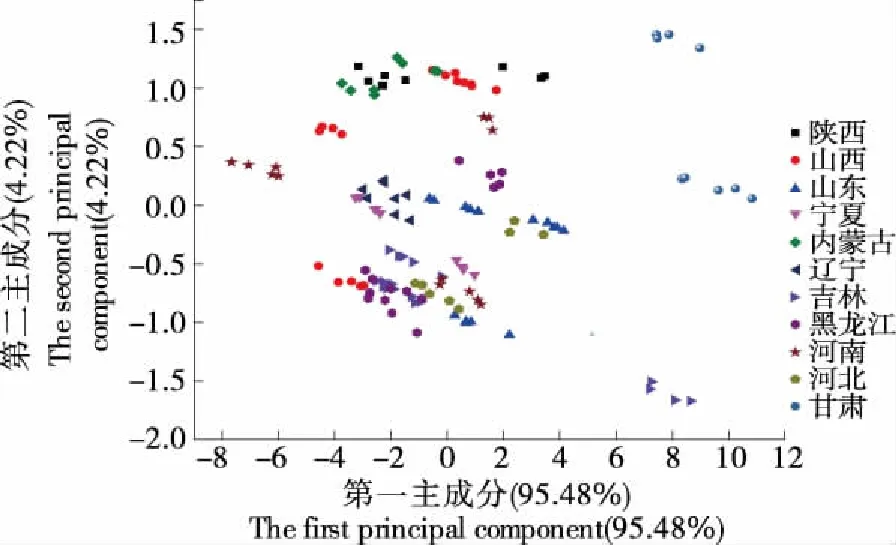
图3 不同产地小米样品主成分分析二维图Figure 3 PCA plot of millet samples with PC1 and PC2
2.4 模型建立
2.4.1 训练集及预测集划分 双向数据分组(DUPLEX)方法是一种计算机训练集识别方法,该方法能保证训练集中样本按照空间距离均匀分布,保证训练集样本的代表性[24]。该方法的选取过程:① 选择样本组中欧式距离最大的两个样本划入训练集;② 在余下的样本组中,选择欧式距离最大的两个样本划入预测集[25]。重复上述操作,直到满足预测集所需的样本数,余下的样本全部划入训练集。使用该方法最终由92个样品组成训练集,39个样品组成预测集,具体结果见表2。
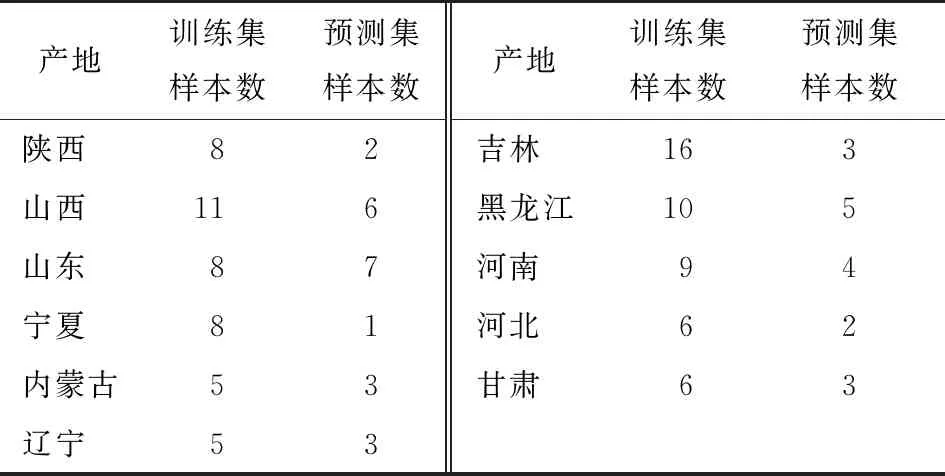
表2 利用DUPLEX方法的分组结果
2.4.2 费舍尔线性判别分析(FLDA) FLDA是一种有监督的线性分类方法,将高维模式样本投影到最佳鉴别矢量空间,降维的同时保证样本有最大的类间距离和最小的类内距离,使得各类样品能够更好的区分。在SPSS软件中,将训练集作为FLDA的变量输入,产地信息作为判别输出,利用Fisher函数、wilks'lambda变量选择,采用步进判别法进行分析,结果见表3。训练集中对不同样品产地溯源的平均正确率为100.0%,预测集中对不同样品产地溯源的平均正确率为84.6%,其中来源于内蒙古的3个样品产地预测全部错误。以上结果表明建立的FLDA模型在训练集上表现良好,但对测试集数据表现一般,模型的泛化能力较差,有可能是训练集样本数量不足或特征波长选择不合适导致了模型的过拟合。

表3 训练集和测试集的费舍尔线性判别分析结果
2.4.3 多层感知器神经网络分析(MLP-NN) MLP-NN是一种前馈式有监督神经网络,由一个输入层、一个输出层以及一个或多个隐藏层组成。作为神经网络方法中最有影响的方法之一,MLP-NN具有从训练数据中学习复杂非线性映射的能力,能够发现数据间复杂的关系。利用训练集数据构建MLP-NN模型,隐藏层和输出层的激活函数分别为双曲正切和Softmax,隐藏层层数为1,单位数为50,优化算法为调整的共轭梯度。结果见表4,训练集中对样品产地溯源的平均正确为95.7%,预测集中对样品产地溯源的平均正确率为92.3%。以上结果表明建立的MLP-NN模型具有较高的准确度和可靠性,因此,相较于建立的FLDA判别模型,基于MLP-NN判别模型的近红外光谱技术可有效应用于小米的产地溯源。
3 结论
以产地相对全面的小米样品为研究对象,采用便携式近红外光谱仪检测样品,建立了基于近红外光谱技术的小米产地多层感知器神经网络、费舍尔线性判别模型。结果显示:多层感知器神经网络模型优于费舍尔线性判别模型,费舍尔线性判别模型准确度高,但泛化能力一般(测试集正确率为84.6%);多层感知器神经网络模型具有较高的准确度和可靠性(测试集正确率为92.3%)。因此,基于多层感知器神经网络模型的近红外光谱技术可有效应用于小米的产地溯源。
研究中检测近红外波长以及算法模型都较少,后续研究应该扩展近红外波长范围(780~2 500 nm),优选新的数据算法(数据预处理、特征波长选择、建模方法等),进而深入揭示小米近红外光谱数据、产地以及组成成分之间的关系。另外,小米的品质除了受地域环境(如气候、土壤等)影响外,还与基因(品种)、种植、管理和加工等因素相关,这些因素均能影响产地溯源的准确性。实际应用时需要考虑并克服这些因素,因此实际应用建模样本的数量及来源会远远超过研究中的样本,甚至需要建立规模庞大的样本数据库并持续完善以降低模型的预测风险。

表4 训练集和测试集的多层感知器神经网络分析结果
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
思维与智慧·下半月(2022年5期)2022-05-17
黑龙江大学自然科学学报(2022年1期)2022-03-29
今日农业(2021年4期)2021-06-09
空间科学学报(2021年1期)2021-05-22
海峡姐妹(2020年2期)2020-03-03
中国外汇(2019年22期)2019-05-21
读友·少年文学(清雅版)(2018年7期)2018-11-16
意林·全彩Color(2018年9期)2018-10-12
数学大王·低年级(2015年11期)2015-11-06
