
面向轴承早期故障检测的多尺度残差注意力深度领域适配模型
2020-10-18 12:57:20毛文涛刘亚敏田思雨
计算机应用 2020年10期
毛文涛,杨 超,刘亚敏,田思雨
(1.河南师范大学计算机与信息工程学院,河南新乡 453007;2.智慧商务与物联网技术河南省工程实验室(河南师范大学),河南新乡 453007)
(*通信作者电子邮箱maowt@htu.edu.cn)
0 引言
随着现代工业的迅速发展,各类机械设备的工作环境变得越来越复杂。轴承作为机械设备的关键支承部件,长期在大载荷、强冲击等复杂工况下工作,且受冲击能力较差,是机械设备中最易受损的零件之一,一旦轴承发生意外失效,将造成重大安全事故和人员财产损失。因此,对轴承早期故障及时进行有效的检测极为重要,是故障预测与健康管理(Prognostic and Health Management,PHM)[1]的关键技术环节。近年来,随着传感技术的发展,基于数据驱动的早期故障检测技术开始受到关注。从状态监控数据中提取早期故障信息,提高异常检测结果的准确性和实时性,具有明确的学术价值和应用需求。
由于振动信号可以直接反映出其工作状态,现有的早期故障检测方法较多采用振动信号进行研究。传统的早期故障检测方法通常包括两个步骤:1)从时域、频域、时频域提取手工特征;2)建立机器学习检测模型。对于传统手工特征提取方法,Yan等[2]通过提取时域信号中的近似熵并将其作为中结构缺陷严重程度的指标,当近似熵值增加时表示机器的可靠性正在下降,从而实现对机器设备的健康状态诊断;Qiu 等[3]通过使用最小化香农熵来优化Morlet 小波变换因子,并利用基于奇异值分解的周期检测方法来选择适合小波变换的尺度,最终实现对机械设备的故障检测;对于建立机器学习检测模型,Liu 等[4]针对故障振动信号的多分量特征和故障特征,建立冲击时间频率字典,然后使用短时信号来匹配字典,最后提取与原始信号最相关的原子分量作为支持向量机(Support Vector Machine,SVM)的输入,从而构建故障检测模型;杨洪柏等[5]使用轮廓图对多维特征可视化后,去除聚类性弱、对故障区分无益的冗余特征维度,并采用反向传播神经网络算法进行故障诊断。但是,这类方法的不足在于提取特征时较依赖于对象的先验知识,且模型多为浅层结构,判别能力存在一定的局限性;同时,此类方法默认训练数据与目标数据属于同一特征分布空间内,当目标数据处于异工况下时,其数据分布往往也不同,从而限制检测模型的性能。
近年来,深度学习的迅速发展为早期故障检测提供了新方法[6]。如Wen 等[7]提出了一种将轴承振动信号转换为二维图像的转换方法,该方法可以提取转换后的二维图像的特征,并消除手工特征的影响,最终基于LeNet-5实现对轴承的故障检测;Akcay等[8]提出了一种基于条件学习对抗网络的故障检测模型,该模型通过在生成器网络中使用编码器-解码器-编码器,使模型将输入映射到较低维向量,然后将其用于重建生成的输出向量,最终通过对比生成的数据与原始数据的差异性实现故障检测。上述基于深度学习方法的故障检测模型的优势在于:利用多层神经网络,深度学习可从原始数据中自适应性地提取特征,具有判别能力强和较少依赖先验信息的优点[9],因此可用来提取表征能力良好的早期故障特征,并构建端到端的检测模型。然而,此类方法的不足在于,深度网络的训练依赖于一定的数据量,但在实际应用中,受复杂工况所限,目标轴承的状态监测数据通常难以大量采集,因此限制了深度学习的建模效果。而引入历史积累的同型号轴承数据,由于工作环境和设备状态的不同,数据分布可能存在一定的差异,所训练的模型并不完全适用于目标轴承,导致检测结果准确度下降。
由于深度学习理论模型通常要求训练数据与测试数据属于独立同分布,即要求其处于同一特征分布空间,而在许多实际场景下,由于目标数据与训练数据通常存在着一定的分布差异,从而限制了模型的性能。基于此,国内外学者开始将注意力转移至深度迁移学习方法,迁移学习的最大特点是能通过大量已有数据、提升在少量且数据分布不同的目标域数据上的建模效果。如借助最大均值差异(Maximum Mean Discrepancy,MMD)、联合分布适配(Joint Distribution Adaptation,JDA)等迁移学习方法[10-11],在已有的大量训练数据集上构建迁移故障检测模型,提升在少量目标数据集上的检测结果。例如,Lu 等[12]通过在多层自编码器的训练过程中添加MMD领域适配正则化约束,来提高不同工况下轴承数据的检测精确度;雷亚国等[13]提出机械装备故障的深度迁移诊断方法,将实验室环境中积累的故障诊断知识迁移应用于工程实际装备。Mao 等[14]对轴承信号进行三通道重构,并对预训练好的VGG-16 模型进行微调适配,实现对目标轴承的早期故障检测。上述方法的本质是将源域的故障机理信息迁移到目标领域,以此提升目标对象的诊断或检测效果。但对于早期故障检测,从强噪声背景下的弱信号中提取特征难度较大,特征区分度不明显。尤其需要注意的是,受环境、装配条件等因素影响,正常状态信号不可避免地出现不规则波动,上述模型容易将此类正常状态样本检测为故障,从而导致较高的误报警。综合上述分析,提升早期故障检测效果的关键在于:1)缩小因工况不同等因素产生的数据分布差异,使得不同工况数据训练得到的检测模型能够有效应用于目标轴承数据;2)提高强噪声背景下正常样本与早期故障样本的差异性,放大弱信号特征区分度,使得处于早期故障状态的样本与因不规则波动引起的伪故障样本尽可能区分开,从而降低误报警率。
由于检测模型无法有效识别故障样本与伪故障样本,从而引起较高的误报警率,为解决此问题,本文拟通过放大或缩小早期故障样本与伪故障样本的异常程度,使得检测模型能够更容易识别正常样本与异常样本,从而降低误报警率。据文献调研发现,注意力机制为上述问题提供了解决思路。注意力机制的本质是对数据进行加权学习,在深度学习模型中,通常使用sigmoid 函数对数据进行加权处理。不同的权重表示数据的不同的重要程度。该技术在图像识别[15]、语音识别[16]等领域都已取得良好的效果。而在PHM 领域内,也有学者尝试通过引入注意力机制解决相关问题。如孔子迁等[17]通过使用注意力结构对不同时间点的特征自适应地动态加权融合,最终通过分类器进行识别,实现行星齿轮箱的端对端故障诊断;吴静然等[18]利用全卷积神经网络提取深度特征,并采用注意力机制将特征进行融合,最后利用多分类函数实现旋转机械故障诊断。上述方法的优势都在于:注意力机制能够通过自适应性学习对数据进行加权处理,放大数据的区分度,从而提升模型效果。
针对以上问题,本文提出一个多尺度注意力深度领域适配模型,将早期故障信息在不同工况数据之间的迁移,来提高检测效果。该方法通过在残差注意力网络[15]中增加不同尺寸的滤波器,并使用卷积-反卷积来重构输入信息,通过自适应性学习来放大或者缩小早期故障样本和伪故障样本的异常程度,从而获取表征能力更强的多尺度注意力特征,使得早期故障样本与伪故障样本的区分度更高。同时,在注意力模型的损失函数中引入最大均值差异MMD正则化约束,在多尺度注意力特征基础上寻找对早期故障更敏感的公共特征表示,使得模型能够在从源域到目标域进行数据迁移的同时,有效区分正常状态样本与早期故障样本,降低误报警率。
本文的主要工作如下:
1)提出了一种基于残差注意力网络的多尺度注意力网络框架。相比原始的残差注意力网络结构,本文通过在残差注意力网络中增加不同尺寸的滤波器,并使用卷积-反卷积来重构输入信息并获得数据的权重信息,即注意力信息,通过将注意力信息与多尺度深度特征融合,从而提取区分度更强的多尺度注意力特征,放大早期故障样本与伪故障样本的差异性,使得提取的注意力特征更有利于异工况下的数据迁移,因此更适用于早期故障检测。
2)提出了一种新的基于深度领域适配的早期故障检测模型。与现有迁移诊断方法不同,该方法将注意力机制与迁移学习机制结合,一方面引入注意力机制获取区分度高的早期故障特征,然后构建基于交叉熵和最大均值差异正则化约束的损失函数,实现领域适配,从而提取对早期故障更为敏感的领域共享注意力特征,降低误报警率。根据本文文献调研,目前采用注意力迁移学习策略的早期故障检测工作尚不多见。
1 相关工作
1.1 深度残差网络
在计算机视觉领域,对于传统的深度神经网络模型,国内外学者普遍认为网络的层数越深,网络的非线性表达能力就越强,同时也意味着该网络所能学习到数据的潜在信息也就越多。如从经典的LetNet-5[19],一个5 层的神经网络模型,到AlexNet[20](8 层)以至于GoogleNet[21](22 层)。神经网络模型的层数对于模型的性能的确至关重要,但是当网络层数增加至一定数量后,性能反而会下降。这是因为当网络层数过深时,由于神经网络模型的参数是通过链式求导的方式得到,所以会出现梯度消失或者梯度爆炸现象,导致在较深层时梯度很难优化,这使得网络模型难以训练,从而影响着网络的性能。
为解决此问题,He 等[22]提出了深度残差网络(deep Residual Network,ResNet)模型。主要思想是:对于一个由几层堆积而成的堆积层结构,当其输入信息为x时将通过网络学习到的特征记作H(x),网络模型希望可以学习的目标是残差F(x)=H(x) -x,这样使得原始的学习特征其实是H(x)。当残差为F(x)=0时,此时堆积层相当于是一个恒等映射,至少网络性能不会下降。而实际上,学习目标F(x)仅仅会接近于0,并不会等于0,这就使得堆积层在输入特征的基础上仍然可以学习到新的特征,从而使得网络模型拥有更好的性能。残差网络的单元结构如图1所示。

图1 残差网络结构Fig.1 Residual network structure
残差单元可以表示为:

其中:h(xl)代表第l个残差单元的输入;F是残差函数,代表学习到的残差;xl+1=f(yl)表示恒等映射,f代表修正线性单元(Rectified Linear Unit,ReLU)激活函数。基于式(1)~(2),可以求得从浅层l到深层L的深度特征:

对于梯度消失或者梯度爆炸现象,在ResNet 中,相较于直接堆叠网络层数的网络模型,因为捷径连接的存在,梯度的计算方法由乘法变为了加法。损失函数用loss表示,则有:
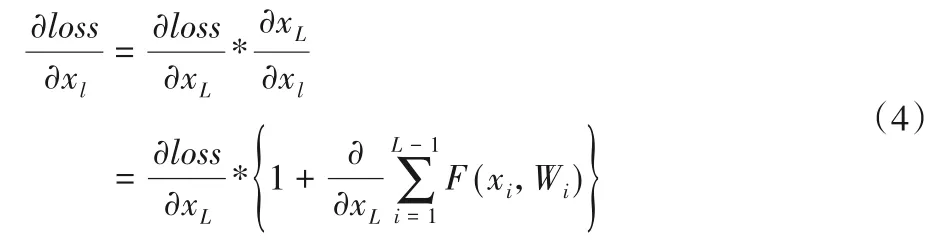
1.2 残差注意力网络
注意力机制借鉴了人类视觉所特有的大脑信号处理机制,当人类快速扫描一幅图像时,大脑的注意力总是会集中在人所想要重点关注的目标区域,进而获取更多所需要关注的目标的细节信息,同时抑制其他无关信息。注意力机制的本质是对数据进行加权学习,在深度学习模型中,通常使用sigmoid 函数对数据进行加权处理,不同的权重表示数据的不同的重要程度。该技术在图像识别、语音识别等领域都已取得良好的效果。
常见的注意力机制常应用于语音识别等领域,文献[16]将注意力机制融入至深度残差网络结构中,构建一种残差注意力网络结构,达到了较好的图像分类效果。残差注意力网络模块的结构如图2 所示,主要分为两个分支:Trunk Branch和Soft Mask Branch。
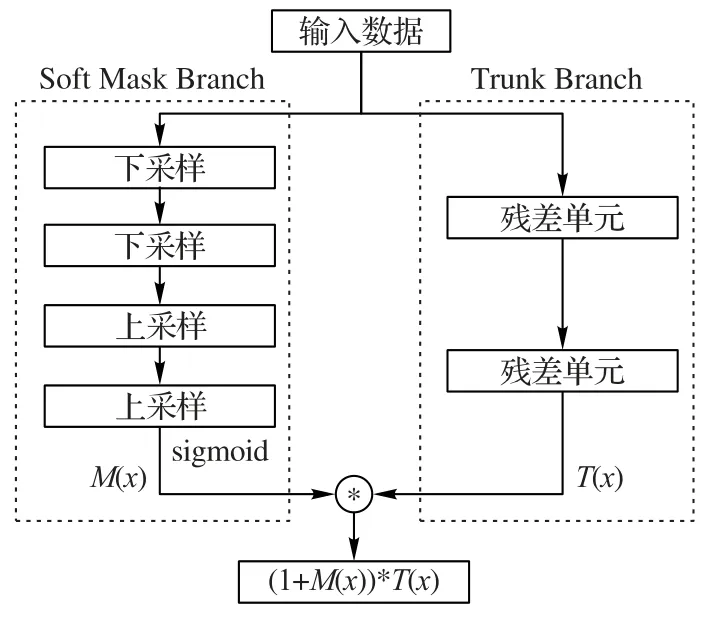
图2 残差注意力网络Fig.2 Residual attention network
其中:Trunk Branch 由两个残差单元组成,用于提取深度特征T(x);Soft Mask Branch 由两个线性插值下采样和两个双线性插值上采样顺序组成,用于重构原始输入信息,并将重构后的输出经过sigmoid 函数映射到0~1 范围内,用以表征注意力信息。最终的输出特征H(x)定义为:

其中:M(x)作为特征选择器,用来增强特征表示能力,并抑制来自Soft Mask Branch 特征的噪声。当M(x)趋于0时,T(x)的值接近T(x),这意味着当注意力信息为0时,由残差注意力网络模型提取的特征等价于由残差网络提取的特征。由于Soft Mask Branch 的存在,经过残差注意力网络模型提取的特征比由残差网络提取的特征更具备表征能力。
2 多尺度注意力深度领域适配模型
在实际场景中,从强噪声背景下的弱信号中提取特征难度较大,特征区分度不明显;同时,受环境、装配条件等因素影响,待检测的目标轴承数据与历史积累的训练数据存在分布差异,且正常状态信号不可避免地出现不规则波动,导致检测模型将此类正常状态样本检测为故障,从而导致较高的误报警。为解决此问题,本文提出了一种基于多尺度注意力机制的深度领域适配模型,包括三通道预处理、多尺度注意力网络以及领域适配模块。最终利用提取到的多尺度注意力早期故障公共特征,构建基于多尺度注意力深度领域适配的早期故障检测模型,使得基于源域数据训练的检测模型能够有效识别目标域数据的健康状况,降低误报警率。
2.1 数据预处理
由于本文所使用的注意力残差网络模型的原始输入为三通道形式的图像数据,因此,本文首先将轴承的一维振动信号变换为三通道形式,分别为原始振动信号通道、边际谱通道以及频谱通道。预处理流程如图3所示。
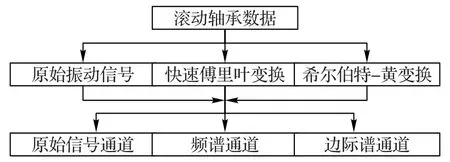
图3 数据预处理Fig.3 Data pre-processing
1)原始振动信号通道:由加速度传感器采集到的振动信号。
2)边际谱通道:对原始振动信号进行希尔伯特-黄变换(Hilbert-Huang Transform,HHT)[23]。使用经验模态分解对原始振动信号分解如式(6)所示:

其中:x(t)表示原始信号;ci(t)表示第i个本征模态函数(Intrinsic Mode Function,IMF)分量;k表示IMF 分量总数;rk(t)表示原始信号剩下的余项。对每个IMF分量进行HHT:

其中τ是对t的取值。
且构建解析信号:


对希尔伯特谱积分得到最终边际谱:

其中:w=,代表瞬时频率。
3)频谱通道:对原始振动信号x(t)进行快速傅里叶变换(Fast Fourier Transform,FFT)[24]。利用式(11)将x(t)变换为频谱数据X(k)。
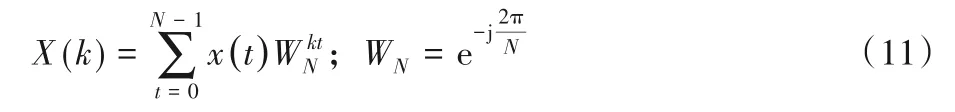
其中:t代表时间;N代表信号的长度。
将得到的原始振动信号、边际谱数据以及频谱数据合并为三通道数据,作为网络模型的输入。
2.2 多尺度注意力深度领域适配模型
本节在残差注意力网络的基础上,引入多尺度的注意力机制,对模型结构和损失函数进一步改进,从而提取有效表示早期故障的多尺度注意力领域共享特征。具体而言,本文在图2 中Soft Mask Branch 模块引入卷积和反卷积,代替了残差注意力网络中Soft Mask Branch 的线性插值和双线性插值,使得模型可以更好地还原输入信息,从而有利于注意力信息的提取;同时,在Trunk Branch 中,由于数据尺寸大小的限制,本文只设置了一个残差单元,且在残差单元后添加了两个不同尺寸的卷积核,然后再进行拼接,以提取更丰富的深度特征。最终,将注意力信息与深度特征融合,提取表征能力更强的多尺度注意力特征。多尺度注意力模块如图4所示。
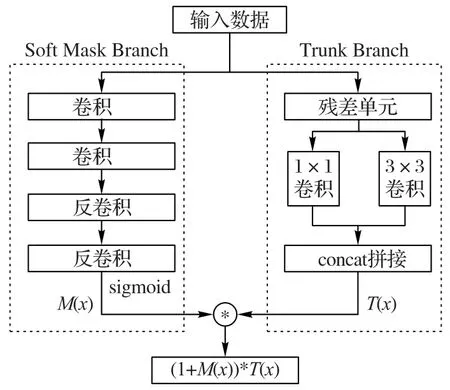
图4 多尺度注意力模块Fig.4 Multi-scale attention module
如图4 所示,本文对2.2 节的Soft Mask Branch 和Trunk Branch 进一步改进。其中Trunk Branch 使用一个ResNet 基础网络结构以及一个1×1 卷积和一个3×3 卷积,用于提取深度特征F(x);Soft Mask Branch 使用了两个3×3 卷积和两个反卷积来还原输入信息,并通过Sigmoid函数将重构后的输出T(x)映射到0~1,代表注意力信息。最终的注意力特征H(x)被定义为:

为了实现从源域到目标域的数据迁移,本文在提取的多尺度注意力特征的基础上,构建基于交叉熵和MMD正则化约束的损失函数,以缩小源域和目标域的数据分布差异性。MMD 是用来度量在再生希尔伯特空间中两个数据的分布距离。则源域与目标域数据的距离为:

其中:H 表示再生核希尔伯特空间;n表示样本数量;分别表示源域样本和目标域样本。式(13)表示两个域的样本在非线性映射φ(·)上的均值差异。通过寻找一个φ(·)使得式(9)最小化,即可诱导得到两个域之间的公共特征空间。
需要注意的是,式(13)是衡量两个域之间的分布差异。而在早期故障检测问题中,由于源域和目标域都存在正常和异常两种状态的样本。若直接将全寿命阶段数据进行领域最小化,则忽略了不同工况下数据之间的健康状况。因此,此处分别计算源域正常样本和目标域正常样本、源域异常样本和目标域异常样本之间的MMD距离,以适配不同健康状况下的数据分布,得到具有普适性的领域共享特征表示。具体表达如下:
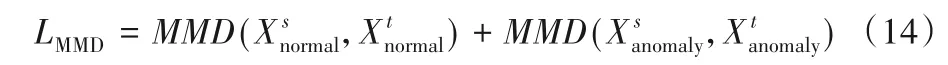
同时,二分类的交叉熵损失函数如式(15)所示:

其中:Ms为训练样本数量;是训练样本的健康状态标记;是训练样本的预测标记的概率分布。将这两部分损失函数集成在一起,最终得到深度迁移早期故障检测模型的目标函数:

其中:X=(T(x)+1)*F(x),代表源域数据和目标域数据的多尺度注意力特征。
本文所提出的多尺度注意力深度领域适配模型流程如图5 所示,它是在残差注意力网络模型框架的基础上进一步的改进,主要包括数据预处理模块、多尺度残差注意力模块和领域适配模块。数据预处理模块是将原始数据分解为原始信号-边际谱-频谱三通道形式。多尺度残差注意力模块是通过不同尺寸大小的卷积来提取表征能力更强的多尺度深度特征,同时利用反卷积结构来提取数据中的注意力信息,然后通过将注意力信息与多尺度深度特征融合,从而获得对早期故障更为敏感的多尺度注意力特征。将提取到的多尺度注意力特征通过领域适配模块,构建基于交叉熵损失和最大均值差异正则化约束的损失函数,从而使得基于源域数据训练的早期故障检测模型能够对异工况下目标数据进行有效的检测。
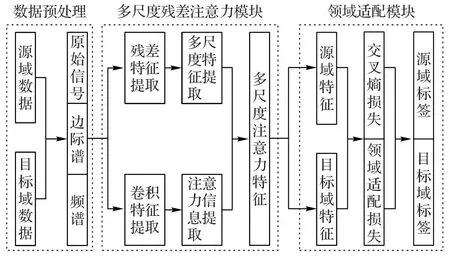
图5 多尺度注意力深度领域适配模型流程Fig.5 Flowchart of deep domain adaptation model with multi-scale attention
对于式(16)给出的目标函数,可采用小批量梯度下降法[25]反向逐层更新训练参数,具体优化步骤如下:
2)前向传播:①随机选取批量训练样本执行式(12),获取领域共享注意力特征。②根据式(13)计算源域数据与目标域数据之间的交叉熵损失值。③根据式(14)计算源域正常数据数据与目标域正常数据、源域异常数据与目标域异常数据之间MMD 值。④执行式(16)计算模型目标函数值,并进行迭代,如果迭代次数小于epoch 的值,则执行步骤3);否则就结束迭代,转至步骤4)。
3)反向传播:采用小批量梯度下降法,反向逐层更新训练参数W0、b0的值;返回步骤2)。
4)目标域数据健康状态识别:保存网络参数W0、b0,将待检测目标域数据输入至检测模型中,返回输出层的检测结果,即可预测目标域数据的健康状态分布。
3 实验与结果分析
3.1 数据集
为了验证所提方法的有效性,本文所使用的实验数据是IEEE PHM-2012 数据挑战提供的轴承加速寿命实验数据,实验数据来自PRONOSTIA 实验台[26]。该数据集包含了从正常到故障的整个生命周期。
数据集由三个不同工况下的轴承的全寿命数据组成:工况1 下发动机的转速为1 800 r/min,负载为4 000 N;工况2 下发动机转速为1 650 r/min,负载为4 200 N;工况3 下发动机转速为1 500 r/min,负载为5 000 N。每个工况下分别对7 个不同轴承进行数据采集实验。本文使用工况1 下数据作为源域数据,工况2下轴承数据作为目标域数据进行实验。
3.2 训练数据状态划分
在本实验中,训练数据由源域数据和少量目标域辅助数据组成,包括工况1下的1~4号四个源域轴承数据和工况2下的1 号轴承辅助数据,测试数据由工况2 下2、4 号两个轴承数据组成。这些轴承数据均包含了从正常到完全退化的全寿命周期信号。具体组成如表1所示。

表1 训练、测试数据划分表Tab.1 Training and testing data division table
为获得有效的早期故障数据,本文首先采用一种常用的早期故障检测方法——基于支持向量数据描述(Support Vector Data Description,SVDD)[27]的方法,对轴承运行状态进行状态划分。具体做法是:选取样本序列前500 个样本的HHT边际谱特征作为训练集,构建SVDD 模型,设定当不再出现正常样本的识别结果时,记为早期故障位置。其中SVDD正则化参数设为0.01,使用径向基核函数(Radial Basis Function,RBF),核参数设为0.1。在源域数据和辅助数据上的状态划分结果如图6 所示(为了合理展示检测结果,在图6和图9 中,设置标签“+1”表示正常状态,“-1”表示异常状态,由此对异常检测结果进行标识)。为了有效对比,图6 同时给出了相应轴承数据的均方根(Root Mean Square,RMS)值。SVDD 是目前常用的早期故障检测方法,而RMS 作为衡量信号能量高低的指标,通常也能用于早期故障检测。

图6 源域数据和辅助数据的SVDD状态划分结果Fig.6 SVDD state division results of source domain data and auxiliary data
分析图6 可知,所有子图中的检测结果在轴承的初始正常阶段均出现较多的误报警,这是由于在运行过程中受运行环境等因素的影响,采集到的振动信号出现不规则波动,即伪故障样本,检测模型若不具备一定的抗干扰能力,无法准确识别正常状态样本与伪故障样本,从而出现了较多的误报警。且从图6可以看出,由SVDD检测模型得到的状态划分结果与轴承振动信号的RMS 值大致相对应,当RMS 值明显增高时,检测结果显示轴承处于异常状态,即早期故障。然而RMS 值并不能作为衡量轴承运行健康状态的唯一指标,只能作为参考依据,这是因为RMS 值只是一种统计量,具有一定的滞后性。
简化起见,源域数据和辅助数据的状态划分结果如表2所示。
在本文中,Trunk Branch 中卷积核大小是3×3,stride 是1,使用ReLU 作为Trunk Branch 的激活函数;Soft Mask Branch 中卷积核大小是3×3,stride 是1,反卷积核大小是3×3,stride 是1,使用Sigmoid 激活函数将反卷积的结果归一化至0~1,flatten 层节点数是128。小批量梯度下降法中,学习率是0.000 1,batch_size 大小是50,keep_prob 是0.7,epoch 是1 000。实验所用电脑配置是Ubuntu 16.4,显卡Tesla K40m,64 GB内存,本文所使用的算法环境是Python 3.6。
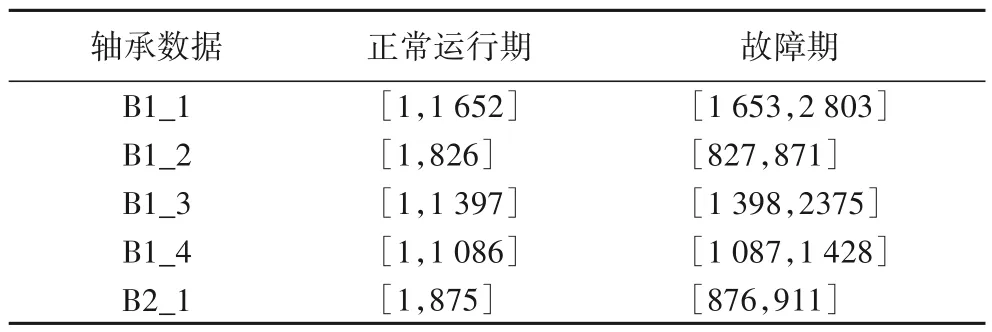
表2 状态划分结果Tab.2 State division results
3.3 实验结果与分析
根据表2 给出的状态划分结果,使用源域数据和辅助数据作为训练集,利用所提方法建立多尺度注意力深度领域适配早期故障检测模型,最终对目标轴承数据进行分类。需要注意的是,目标轴承数据同样需要采用3.1 节方法预处理为三通道数据形式。
本文以工况2 下2 号和4 号轴承为目标数据,分别采用HHT 边际谱和本文方法所提的128 维特征,并使用t-分布式随机邻域嵌入(t-distributed Stochastic Neighbor Embedding,t-SNE)法[28]进行特征可视化,如图7 所示。可明显看出,图7(a)、(c)中正常样本与异常样本虽然有较明显的区分度,但在图7(a)的异常样本内圈边缘处混杂着不少正常样本,图7(c)中正常样本外圈处同样混杂着不少异常样本,这也是导致检测模型出现误报警的原因。而在图7(b)、(d)中,本文方法所提的特征可视化效果较好,正常样本与异常样本区分度明显,且误报警数量较少。
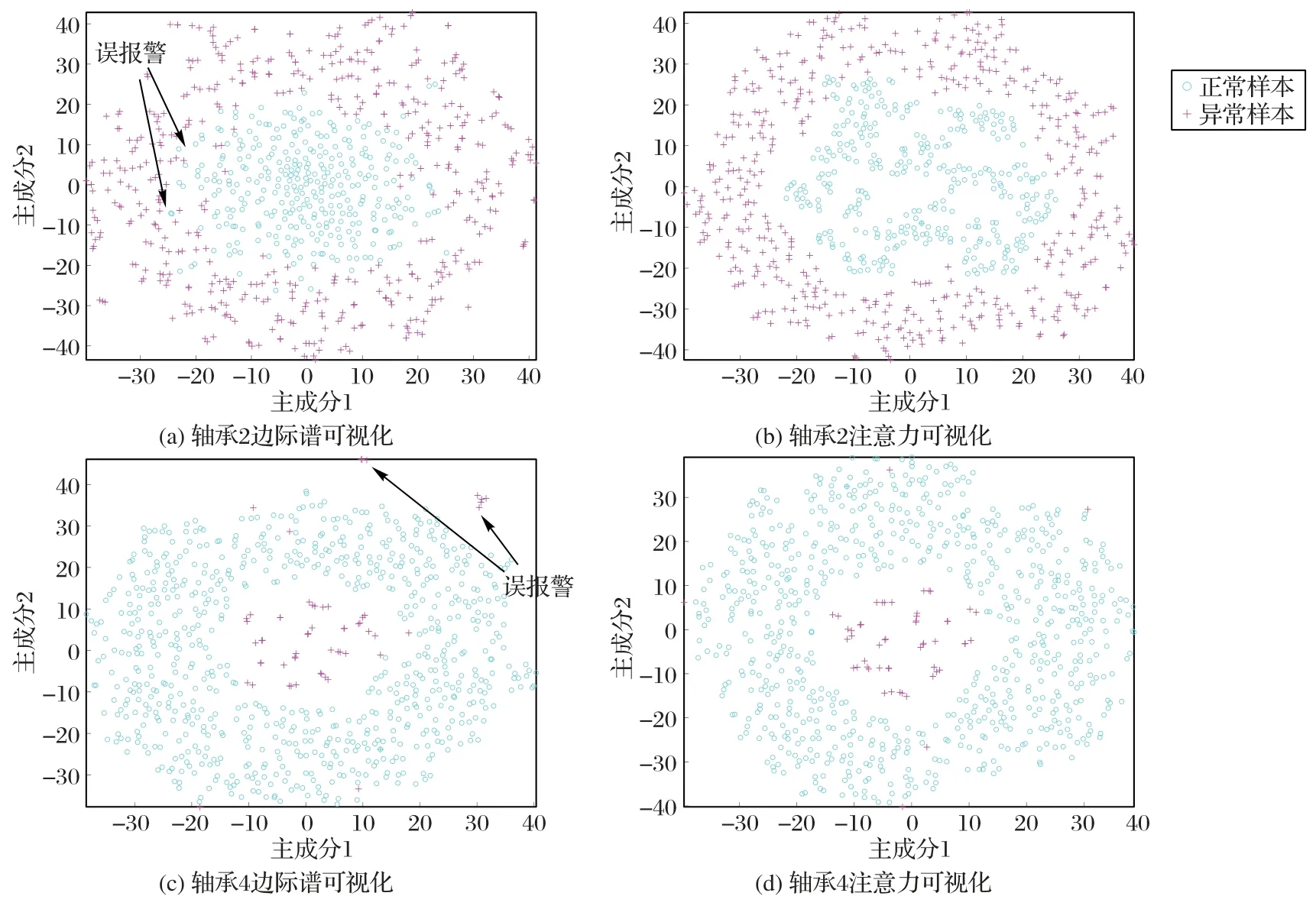
图7 工况2下的2号和4号轴承特征分布Fig.7 Feature distribution diagrams of No.2 and No.4 bearings under operating condition 2
为验证所提方法的可解释性,本文设置一组基础对照实验,即通过在原始残差注意力网络添加MMD 正则化约束项。训练过程loss值的下降过程如图8所示。
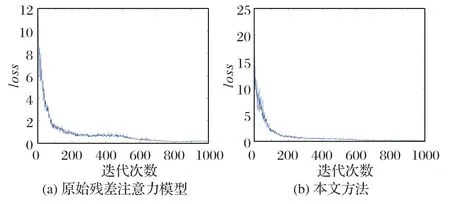
图8 loss下降过程Fig.8 loss decline process
分析图8可知,图8(a)中的对比方法在迭代至800轮左右时,loss值不再下降,模型达到收敛状态;而图8(b)中本文方法在迭代至400 轮左右时,loss已经基本上趋于平稳,即模型达到收敛状态。究其原因,本文方法的反卷积结构能够获取更丰富的注意力信息,且利用不同尺度大小的卷积提取深度特征表征能力更强,融合后的注意力特征对早期故障更敏感,因此模型会更快地达到收敛状态。
对于早期故障检测问题,由于其本质是流数据的异常检测,需要从贯序到达的监控数据中检测出异常状态,现有研究[29]多采用检测位置和误报警数来评价模型的可靠性。为了对检测模型的可靠性和准确性进行评价,本文采用退化过程的RMS 曲线进行验证。由于RMS 曲线是退化过程的一种广泛采用的特征表示,因此具有较好的参考价值。
以工况2 下2 号和4 号轴承为目标轴承,检测结果如图9所示。本文设定当正常样本消失、连续出现异常样本时,记为报警时间点。为对比起见,图9 中同样提供了目标轴承的RMS曲线和基于SVDD的检测结果。
由图9 和表2 可知,SVDD 的检测结果在轴承正常运行阶段出现了较多的误报警,同时,当RMS 值出现较为明显的波动时,误报警数也随之变多。这是因为检测模型不具备一定的抗干扰能力,无法识别伪故障样本,导致检测结果不够鲁棒。而本文所提方法的检测结果在正常样本与异常样本之间区分更为明显,能够在不延迟报警时间点的情况下,有效地降低误报警数。究其原因,注意力模块通过自适应性学习来放大或者缩小早期故障样本和伪故障样本的异常程度,使得早期故障样本与伪故障样本的区分度更高;同时通过引入MMD领域适配约束项,缩小源域样本与目标域样本的分布差异,使得模型能够在从源域到目标域进行数据迁移的同时,有效区分正常状态样本与早期故障样本,降低误报警率。
为进一步验证本文方法的有效性,表3 给出了本文方法与8 种代表性的早期故障检测方法的实验结果。这8 种方法中,LOF(Local Outlier Factor)[30]和iForest[31]是两种典型的异常检测算法,其中LOF阈值为8,iForest树的数目为100。SRD(Sparse Residual Distance)[32]是一种代表性的基于统计指标分析的故障检测方法。BEMD-AMMA(Bandwidth EMD with Adaptive Multiscale Morphology Analysis)[33]被认为是最新的一种基于信号分析的早期故障检测方法。DAFD(Domain Adaptation for Fault Diagnosis)[12]是一种代表性的基于自编码器实现深度领域适配的迁移诊断方法,其中自编码器的网络结构设为[500,100,50],即提取的深度特征维度为50。SDFM(Self-adaptive Deep Feature Matching)[6]是一种基于深度学习的异常序列匹配的早期故障在线检测方法,所采用的自动编码器结构是[800,512,50],即提取的深度特征维度为50,滑动窗口大小为100。迁移成分分析(Transfer Component Analysis,TCA)[34]和测地线流式核(Geodesic Flow Kernel,GFK)方法[35]是两种典型的迁移学习算法,这两种算法的输入为HHT 边际谱,检测模型为SVDD。本文认为这八种方法可涵盖不同角度的对比。
由图9(b)中的RMS 曲线可知,4 号轴承的早期故障阶段持续时间极短,因此表3中对轴承4五种对比方法与本文方法的报警时间点均没有太大差异。定义误报警率计算公式为:误报警率=误报警数/总样本数。通过对轴承2 的检测结果计算可知,以上八种对比方法的平均误报警率为2.01%,本文方法误报警率为0.75%,误报警率相对降低了62.7%。轴承4对比方法的平均误报警率为1.73%,本文方法的误报警率为0.67%,误报警率相对降低了61.3%。
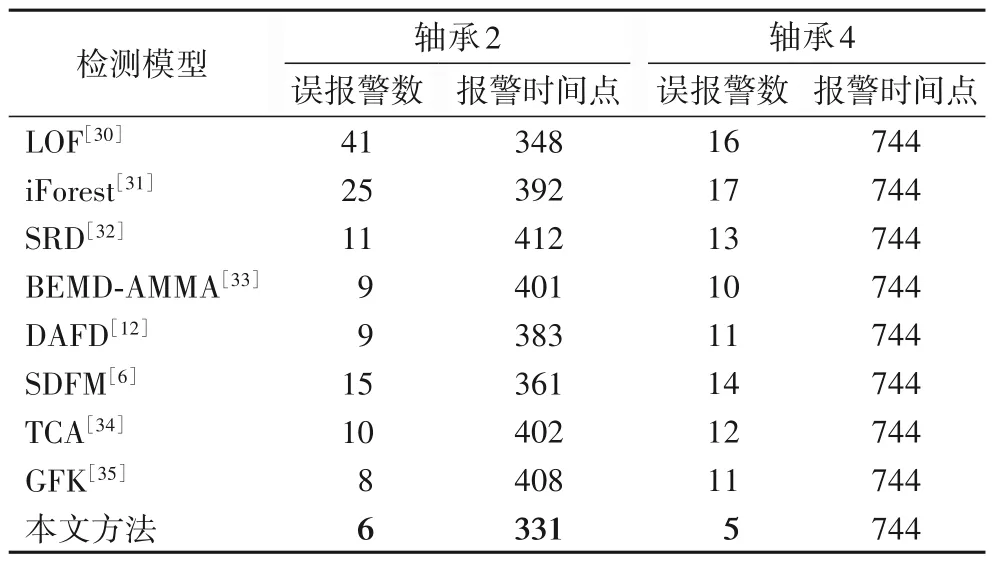
表3 PHM数据集工况二对比检测结果Tab.3 Comparative test results under operating condition 2 of PHM dataset
分析表3 的实验结果可知,与其他方法相比,本文方法能够在更少误报警的情况下,更早判断出轴承的异常状态。因此,本文方法可以被认为对早期故障更为敏感,以及有着更好的鲁棒性,更适用于早期故障检测。
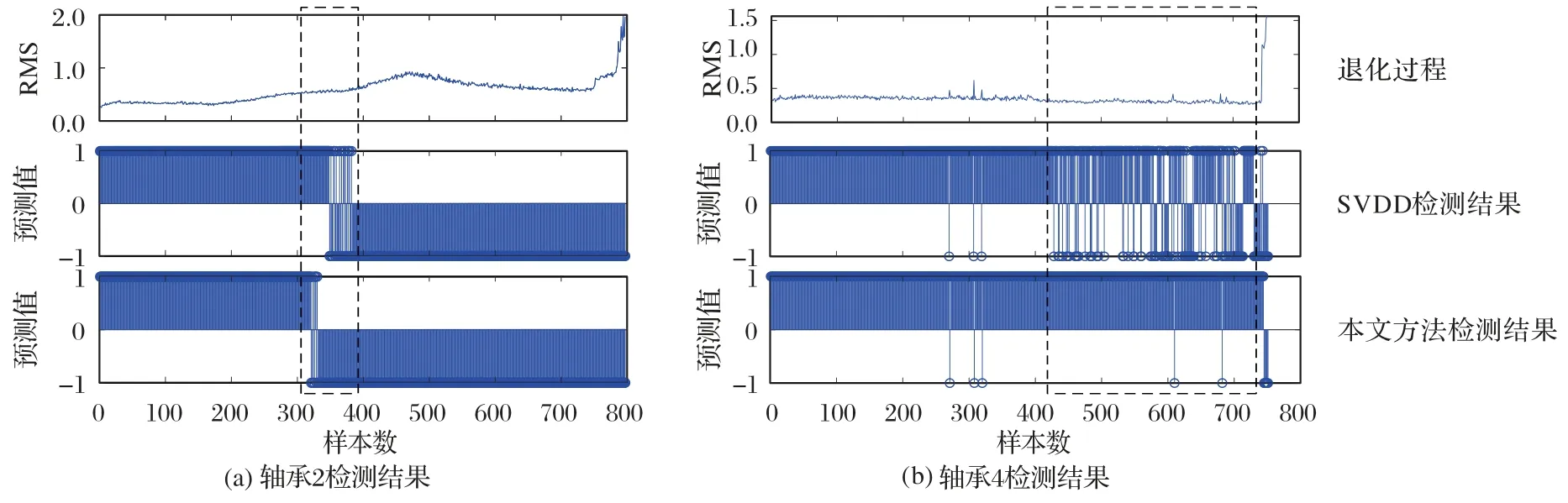
图9 目标轴承数据的检测结果Fig.9 Detection results of target bearing data
4 结语
本文针对早期故障检测的需求特点,提出了一种基于多尺度注意力机制的深度领域适配模型。该模型将多尺度注意力机制和迁移学习结合,既能提取对早期故障更为敏感的注意力特征,同时也可有效利用不同工况监测数据蕴含的故障机理信息。从实验结果来看,本文所提取的多尺度注意力特征,对早期故障与伪故障样本的区分度更明显,更具备表示性,有效增强了检测模型的鲁棒性,并显著降低误报警率。本文所使用的注意力机制是从计算机视觉领域移植而来的,尽管其在PHM 领域内虽然能够有效应用,但可解释较差。接下来将进一步探索适合一维信号使用的注意力机制,使其能够更有效地应用于早期故障检测。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22 06:39:32
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
哈尔滨轴承(2022年1期)2022-05-23 13:13:24
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
哈尔滨轴承(2021年2期)2021-08-12 06:11:46
哈尔滨轴承(2021年1期)2021-07-21 05:43:16
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
