
基于分布式计算的农机运营效率分析
2020-10-17 03:10:12赵国发陈竞平孟志军
农机化研究 2020年1期
赵国发,刘 卉,肖 敬,陈竞平,孟志军
(1.首都师范大学 信息工程学院,北京 100048;2.国家农业智能装备工程技术研究中心,北京 100097)
0 引言
农机深松整地作业是在不打乱土壤层结构的前提下,打破犁底层、增加土壤的透水性和透气性、改善农作物根系生长条件从而达到增产增收的一项重要举措。针对深松整地作业的监管需求,国家农业智能装备工程技术研究中心研制了农机深松作业监管服务系统,有效地保障了作业数据的完整性、实时性和有效性,极大地降低了人工抽检强度,加强了监管力度。
农机深松作业监管服务系统获取了海量农机运动轨迹数据。目前,国内外针对轨迹数据的挖掘研究主要集中在道路路网提取更新[1-3]、用户出行分析[4]、商圈热区推荐[5]及城市交通拥堵识别[6-7]等方面,针对农机运动轨迹数据的研究分析较少。
本文针对海量的农机轨迹数据,运用Spark分布式集群技术[8],从运营时间、作业时间、时间利用率及班次利用率等多方面对农机运营效率进行评估,有助于测算和客观评价农机运营效率,进一步提升平台服务应用价值,为农机智能管理与科学调度研究提供数据支持。
1 农机运动轨迹的数据处理方法
1.1 农机深松作业监管服务系统
基于物联网技术思想开发的农机深松作业监管服务系统,设计为4层架构:①感知层为安装在农机上的车载智能终端设备,用来获取农机作业状态数据[9];②网络层主要包括安装在终端上的通用分组无线服务网络(GPRS)和移动3G网络,通过Internet公网上传采集到的作业轨迹数据;③支撑层主要由中心服务器、应用服务器、数据服务器、数据库管理系统、基础地理信息管理软件和安全监控设备等组成;④应用层是基于Web浏览器的农机深松监管与服务软件系统,协助监管部门对深松作业进行综合管理与数据分析。农机深松作业监管系统感知层的车载智能终端设备集成了GNSS定位模块、GPRS数传模块及作业参数传感器等,通过解析GNSS模块的NMEA-0183语句及传感器输出语句,获取农机作业时间、经度、纬度、速度及作业深度等时空数据及作业属性数据。GPRS数据传输模块每隔4s将上述监测信息回传到远程服务器,由此产生了海量的农机运动轨迹时空数据。
1.2 农机运动轨迹数据
本文所采用的轨迹数据源于农机深松作业监管服务系统数据库。每条农机轨迹数据包含车辆编号、经度、纬度、深度和速度等10个字段,具体说明如表1所示。作业状态是指农机开机状态正常情况下的田间深松作业状态。深松系统标准规定,农机作业深度值应大于300mm。
1.3 数据预处理
1.3.1 数据丢失处理
引起数据缺失的主要原因有信号屏蔽、信号不良、终端设备故障和机手操作不当等,导致整条数据记录丢失。此外,由于复杂环境的影响和设备自身故障,也可能导致数据在获取、存储、传输过程中出现轨迹点的重要属性缺失,如经纬度、设备ID、时间信息或作业深度等,本文记录丢失数据位置,对重要属性缺失数据采取了删除处理并写入异常数据表。

表1 轨迹数据字段说明Table 1 Track data field description
1.3.2 数据重复处理
轨迹数据在上传与存储过程中可能造成数据重复,这些重复数据不仅会浪费存储资源也会造成后续数据处理的错误,通过比较设备ID与GNSS时间,删除设备ID与GNSS时间均相同的重复数据。
1.3.3 数据漂移处理
由于定位设备接收信号问题引起的轨迹点位置坐标偏离真实位置,产生数据漂移。由于农机轨迹点的真实位置不可知,漂移数据不容易被发现,本研究通过计算时序相邻的两个轨迹点Pk、Pk+1之间的运动速度v(Pk,Pk+1)来检测数据漂移,即
(1)

1.3.4 停歇点识别
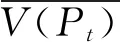
(2)
1.4 农机运营效率评定指标
1.4.1 运营时间
农机运营是指农机开机条件下的各种营运状态,包括道路行驶、田间作业及维修检查等。运营时间很好地反映了机手的工作状态和工作量,本文给出农机运营时间、日均运营时间等指标定义。农机运营时间Toperation定义为
Toperation=N·tinterval
(3)

(4)
其中,m为农机运营的天数,Ni为第i天农机运营总轨迹点数。
1.4.2 作业时间
作业时间是农机田间深松作业效率的主要评定指标,可以直观地反映农机作业的状态和工作强度。本文分别给出作业时间、日均作业时间等指标定义。农机作业时间Twork定义为
Twork=M·tinterval
(5)
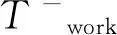
(6)
其中,m为农机作业的天数,Mi为第i天具有深度作业属性值的轨迹点数。
1.4.3 时间利用率
时间利用率可以客观地表示农机深松作业时间与农机运营时间的比例关系,从而体现出农机转移时间的消耗及农机深松作业的趋势变化。农机时间利用率τ定义为
(7)
其中,Twork为农机作业时间,Toperation为农机运营时间。
1.4.4 班次利用率
运营班次是指某段时间内运营农机数量的总和,作业班次是指某段时间内作业农机数量的总和。班次利用率定义为
(8)
其中,m为有农机运营的天数,Ki为第i天具有作业属性的作业农机数量,Nj为第j天具有轨迹信息的运营农机数量。农机班次利用率能够反映出农机深松作业的应用需求。
2 基于Spark的分布式集群试验系统
2.1 分布式计算技术
Hadoop是将一个任务分解为多个并行计算的小任务,通过大量的计算节点对多个小任务的并行计算[10]。Hadoop由分布式文件系统(HDFS)、集群资源管理系统(YARN)及分布式并行计算 (MapReduce)等生态系统组成。Spark是与 Hadoop 相似的开源集群计算环境,主要由SparkSQL、SparkStreaming、MLlib 等生态系统组成,Spark 在某些工作负载方面表现得更加优越。Hadoop更多作为一个数据存储的基础设施,将海量的数据分配到一个由廉价的计算机组成的集群中进行存储和管理[11];Spark则多用于作为专门处理海量数据分布式计算的工具,其生态系统没有提供分布式数据的存储的组件,但能在内存中对数据进行分析和运算[12]。
Python是一款结合解释性、编译性、互动性和面向对象的脚本语言,能将其他语言制作的各种模块结合在一起,提供了丰富和强大的第三方库[13],本研究采用Python的Matplotlib库绘制了各种农机轨迹分析图。
2.2 搭建分布式集群试验系统
为了更高效地分析农机运营效率,本文搭建了基于Spark分布式集群技术的试验系统。分布式集群硬件系统网络拓扑(见图1),包括3台计算机,通过一个路由器相连接,使3台机器处于同一局域网的IP中。其中,IP:192.168.1.103的计算机为分布式集群master,另外2台分别为slave1和slave2。搭建基于Hadoop的Spark分布式集群的开发环境主要包括:部署基于Hadoop的HDFS集群、把Spark集群部署到Hadoop上、搭建基于Spark集群的应用开发环境[14]。本文搭建的分布式集群采用如下软硬件配置: Hadoop2.7、spark2.1.1、Ubuntu 14操作系统、3.6GHz、8核CPU、16GB内存、128GB的SSD,以及1TB硬盘。

图1 分布集群网络拓扑图Fig.1 Distributed cluster network topology
2.3 集群性能测试
为了验证分布式集群试验系统性能,按照表1中的轨迹数据字段格式生成不同量级的仿真轨迹数据,进行集群性能测试实验。采用HDFS存储数据[15],分别启动Hadoop、Spark、Hive,执行groupby语句对农机的作业时间进行统计。Hadoop和Spark的处理轨迹时间消耗对比如图2所示。Hadoop在启动时需要初始化耗时,而Spark基于内存计算,启动过程较快,数据处理时间优于Hadoop。由于集群任务初始化、数据加载、数据交换等常规事务的处理影响,分布式集群计算轨迹数据的平均耗时随着数据量的增加呈现先减小后稳定的趋势,如图3所示。
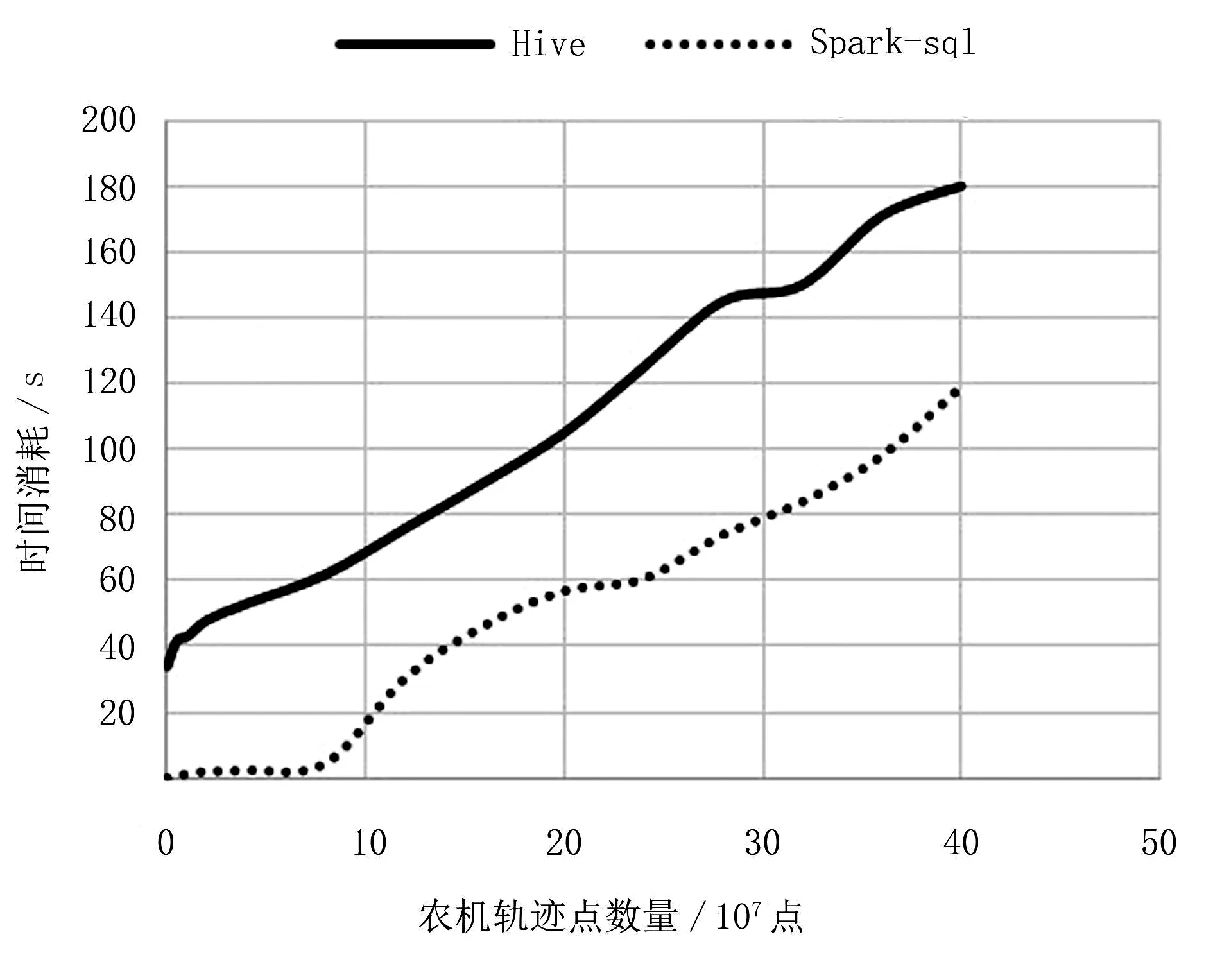
图2 Hadoop与Spark处理轨迹耗时对比Fig.2 Time lapse comparison between Hadoop and spark processing trajectories
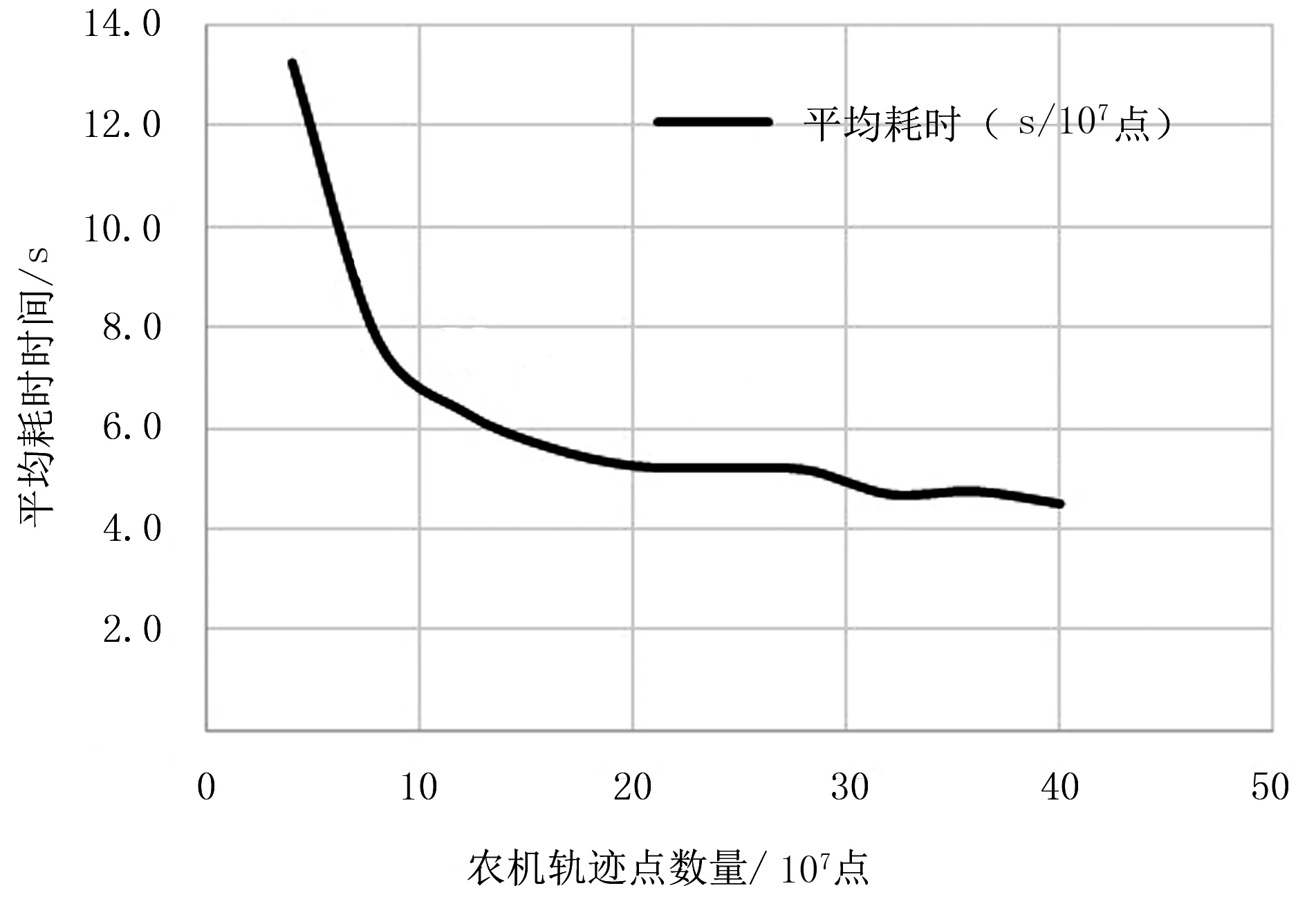
图3 集群轨迹数据处理平均耗时趋势Fig.3 Average time consumption trend of cluster trajectory data processing
3 农机运营效率分析
本文选取2015年8-12月期间新疆塔城3个典型地区14辆农机的作业轨迹数据进行分析,轨迹点总数约943万个,包括停歇点约212万个,作业轨迹点约363万个,道路行驶轨迹点约368万个。
3.1 农机作业时间数据处理与分析
3.1.1 农机总作业时间分析
图4为2015年8-12月期间农机总作业时间分布图。从图4可以看出:农机总作业时间呈现先升高后下降趋势,5个月的月均作业时间为387h,8、9、10月的作业时间均大于均值,10月为波峰值。

图4 农机作业时间分布Fig.4 Agricultural machinery operation time distribution
3.1.2 农机日均作业时间分析
图5为农机日均作业时间占比统计图。从图5可以看出:作业时间小于1.5h占13.8%,超过9.5h占比为17.8%,大部分作业时间分布在1.5~9.5h之间,占比接近70%。其中,作业时间在5.5~6.5h区间所占比例较大。
3.2 农机时间利用率分析
图6为2015年8-12月农机时间使用率对比。结合图4发现,虽然农机10月的作业时间最多,但时间利用率并不是最高。出现这种结果的原因是由于农忙开始时,农机手会首先选择离机库较近的地块进行作业,随着时间的推移,较近的地块多已完成作业,机手不得不花费更多时间进行道路行驶转移,所以时间利用率越来越低。
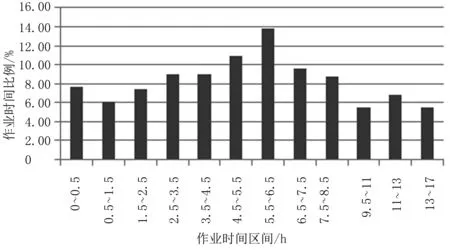
图5 日均作业时间占比统计Fig.5 Daily average working time ratio statistics

图6 农机时间使用率对比Fig.6 Agricultural machinery time usage comparison
14辆农机各自的时间利用率对比如图7所示。
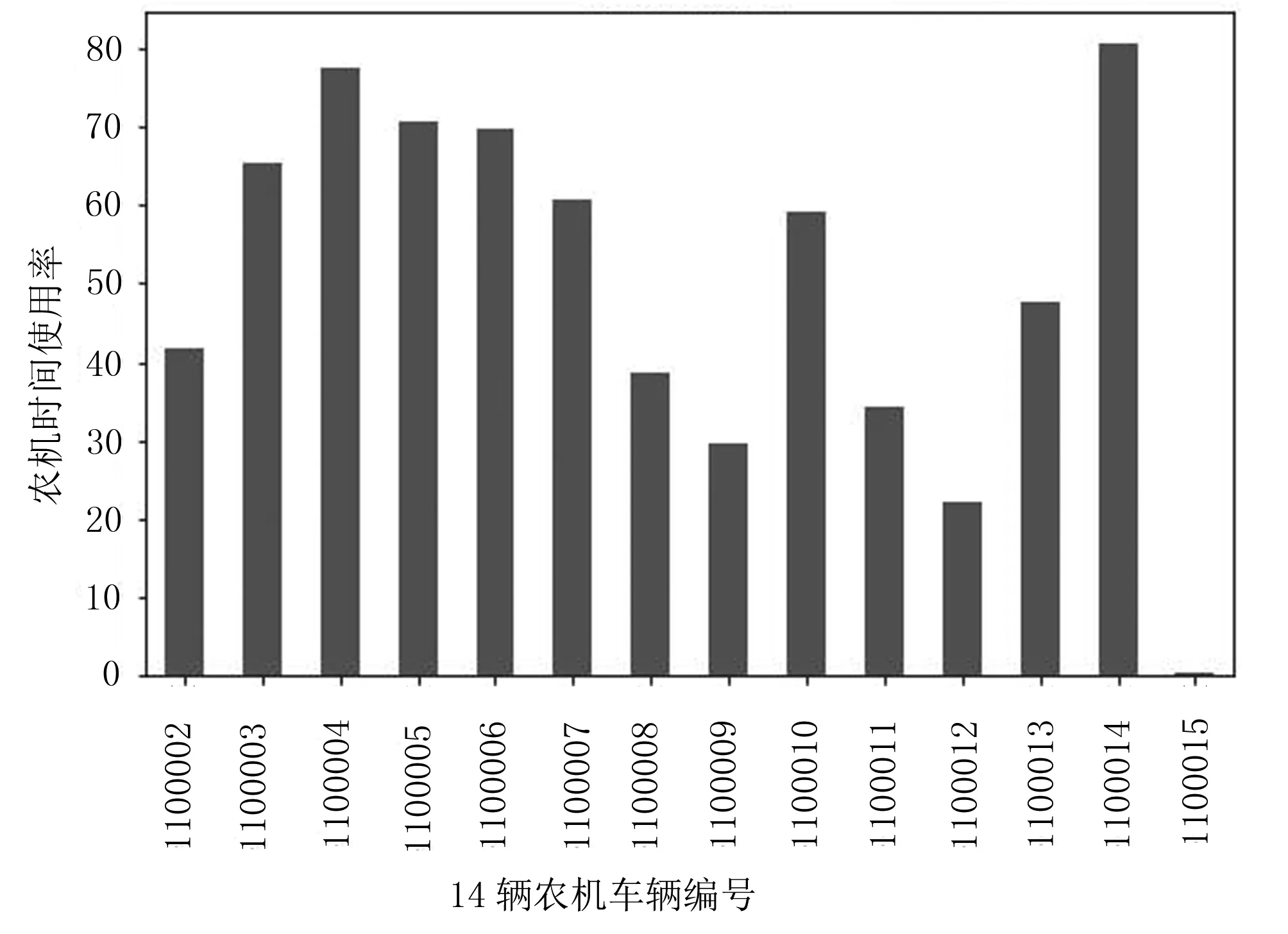
图7 14辆农机各自的时间使用率Fig.7 14 agricultural machinery respective time usage rates
从图7可以看出:每辆农机的时间利用率大部分超过40%,其中编号为1100014的农机时间利用率最高,达到了80%以上,说明农机在运营时较少进行道路转移。但是,个别农机的时间利用率低,如编号为1100012和1100015。不同作业农机的时间利用率统计数据能够为农机合作组织的作业监管与调动提供数据支持。
3.3 农机班次利用率分析
图8是14辆农机班次利用率分布情况。从图8可以看出:不同农机的深松班次利用率差别较大,编号为1100006的农机深松班次利用率达到了90%以上,说明该农机在这期间主要从事深松作业;编号为1100015的农机深松班次利用率不到10%,说明该农机这期间主要从事其它农业生产活动。

图8 14辆农机的班次利用率Fig.8 Shift utilization rate of 14 agricultural machinery
图9是14辆农机的时间与班次利用率对比图。由图9可看出:来农机的班次利用率和时间利用率的趋势基本一致,时间利用率高的班次利用率也比较高,班次利用率和时间利用率之差绝对值的均值为5.8%。其中,编号为1100006、1100013的农机班次利用率比时间利用率高出12%,这14辆农机中有71%的农机时间利用率大于班次利用率。
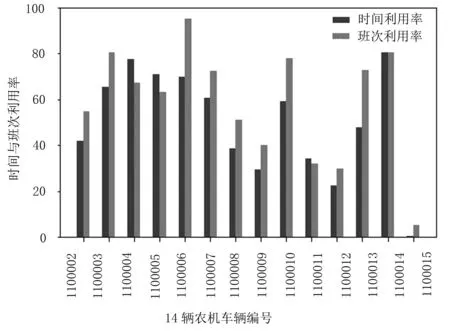
图9 14辆农机时间利用率和班次利用率对比Fig.9 Comparison of time utilization rate and shift utilization ratio of 14 agricultural machinery
4 结论
基于HDFS的大数据存储技术和Spark大数据运算技术,利用3台PC机搭建了Spark分布式集群轨迹处理试验平台,并对集群性能进行了测试试验。试验结果表明:分布式集群平台处理能力强、耗时少,能够更好地满足轨迹大数据的处理要求。基于分布式集群试验平台,针对运营时间、作业时间、时间利用率、班次利用率等多项指标,对2015年8-12月期间的新疆塔城地区14台农机深松作业轨迹数据进行了运营分析,有效地测算和评价了农机运营效率,能够为综合统计农机深松作业效率及作业特征规律提供数据支持。
猜你喜欢
计算机系统应用(2021年11期)2022-01-06 08:05:20
山东交通科技(2020年1期)2020-07-24 08:28:42
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
中国化肥信息(2019年6期)2019-01-19 13:10:42
经济技术协作信息(2018年5期)2019-01-19 08:39:16
电子制作(2018年11期)2018-08-04 03:25:40
消费导刊(2017年24期)2018-01-31 01:29:29
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
印制电路信息(2015年6期)2015-12-30 12:57:48
