
智能混肥控制系统水肥浓度控制策略研究
2020-10-17 03:13:26赵景波张文彬朱敬旭辉邱腾飞刘信潮
农机化研究 2020年5期
赵景波,张文彬,朱敬旭辉,邱腾飞,刘信潮
(青岛理工大学 信息与控制工程学院,山东 青岛 266520)
0 引言
我国每年的化肥使用量约占全球1/3以上,目前施肥模式仍以粗放型为主,灌溉施肥过程中忽略了水肥的浓度比,使得农作物对肥料的吸收率降低,造成了大量的水资源、劳动力的浪费。落后的施肥模式一方面造成了资源的浪费,增加了环境压力,另一方面也极大地限制了农作物的产量[6]。中国工程院院士孟伟认为:“人们不断从土地索取,然后注入各种“营养”,为了防治病虫害还使用了大量农药,土地功能被破坏,过度使用和土壤透支是中国土地环境的现状”。为了实现农业持续发展和资源永续利用,从大水大肥的粗放型向精细调控的集约型转变是现代农业发展的必然趋势[1]。水肥一体机技术可将水和可溶性肥混合成液体肥料直达作物根部,节水、节肥效果明显。
在资源环境日益趋紧的背景下,生态文明建设已经纳入到国家总体战略布局“五位一体”,转变农业发展方式、实现农业绿色化也更加迫切。2016年,中央发布的第1号文件中明确提出,实现农业的绿色化就是对生态环境的保护。在保证农业高速发展的同时,确保生态环境不受破坏的模式就是现在研究人员提出的绿色农业[10],实现绿色农业的关键技术就是通过精细化的管理模式实现配方施肥和农业节水灌溉。对农业资源进行细致规划、保护生态环境、防止过度污染,不仅提高了产品的质量,也留下了祖国的绿水青山。使用云计算,通过专家系统进行调度工作,能够确保水肥精准控制、农业综合治理、农业生产环境治理等,从而力争实现生态保护和资源保障的双赢[2]。
1 智能水肥一体机控制系统存在的问题
近年来,国家高度重视设施农业,投入大量研发和资金支持,制定了相应的优惠政策,鼓励设施农业发展,智能设备在技术上也得到了提升,但还存在一些问题需要继续研究。
1)智能化程度低。传感器可将土壤温湿度、空气温湿度数据通过物联网通信技术上传至服务器,但没有对数据进行深度的挖掘和分析及通过数据判断作物生长周期和生长环境,因此无法制定控制策略,普遍性不强,特别是对大规模作物的水肥管理,缺少统一管理系统。
2)控制精度差。虽然市面上文丘里吸肥器能够做到对肥液进行浓度监测和调控,但由于结构因素,只能在一定压差下实现定量吸肥,且吸肥管道的水压是不断变化的,控制精度存在很大误差。
2 智能水肥一体机浓度控制过程模型
2.1 混肥浓度模型建立
灌溉施肥是根据种植作物种类、时空分布的差异实行不同的施肥计划,因此在智能水肥一体机作业过程中,施肥任务是一直变化的,混肥过程更需要适应环境的变化,及时做出调整。为了更好地研究混肥过程中浓度变化情况,首先应该了解被控对象的特点,分析被控对象的本质[3]。
由于在非理想的混肥过程中会有复杂的干扰因素,所以建立出准确无误的数学模型相当困难。基于以上问题,通过对混肥机理进行研究,仅建立一个简单的混肥浓度动态模型,分析浓度变化的特点[4]。假设混肥过程中,混肥罐内液位不随混肥过程发生变化,固体肥料充分溶解且与清水混合后,混肥罐上下浓度一致;三路吸肥管道的吸肥流量相等,不考虑水温变化对浓度的影响。根据混合物料平衡原则,混合前后系统肥料守恒和总体积守恒,则有

(1)
(2)
(3)
q1(t)=q2(t)=…=qn(t)=qin(t)
(4)
将式(2)~式(4)代入式(1)合并整理后可以得到混肥浓度动态平衡方程,即

(5)
其中,Fs(t)表示在灌溉过程中,纯水经田间管路输出的总流量;Cs表示灌溉清水相比于肥液的比例浓度;Fout(t)表示灌溉过程中,肥液经田间管网总输出流量;Cout(t)表示混肥结束后,肥液经管路输出的质量浓度;qj(t)表示吸肥阀管路的吸肥流量,j=1,2,3,…,n;V(t)表示混肥罐内液体总体积;n为实际吸肥通道数。
2.2 模型分析
分析式(5)动态平衡方程,在动态方程中系统的输入实际吸肥流量qin(t)与系统输出混肥总浓度Cout(t)存在非线性项。混肥罐内肥液混合过程中,由于水与肥液不能瞬间稀释,所以浓度存在混合延迟,时滞时间τ可以代表水肥融合过程中的延迟时间。
分析模型的过程中首先假设混肥罐内液体体积为一个固定值,对于母液总浓度,灌溉清水浓度可以忽略不计。作为系统的输出,混肥输出浓度为关键参数,不能忽略,混肥输出浓度的变化相当于给系统增加了阶跃扰动,其数值随灌溉输出总流量的变化而变化[4]。
综上分析,在实际混肥过程中,因为浓度变化并不是线性变化,给系统产生非线性干扰。水和肥液的混合过程具有延迟时间,给系统产生滞后影响,而灌溉施肥计划的变化又给系统增加了时变扰动。此外,系统本身硬件部分具有固有的非线性,如执行器件的死区特性,传统控制器控制效果很难达到预期的指标。
3 变论域模糊PID算法设计方案
混肥系统是智能水肥一体机控制系统的核心之一,具有滞后大、时变强、非线性大的特点,理想的动态品质和准确的稳态精度是控制系统的关键指标。传统的控制方法难以解决这种矛盾,采用PID和自适应模糊的复合控制方法[5]是一种理想的控制方法,具有模糊控制鲁棒性强的优点,又具有PID控制精度高、响应速度快的特点[6]。给定施肥浓度与实际施肥浓度之间的差为误差e,将误差分为3段,表示为:误差非常大,即|e|≥e1,e1是一个较大的误差值;误差很大,即e1≥|e|≥e2,e2为较小的一个误差值;误差较小,即|e|≥e2。模糊控制器会根据不一样的误差段[7](误差很大、误差较大、误差较小),通过模糊控制规则在线自整定ΔKp、ΔKi、ΔKd的参数。当误差很大|e|≥e1)时(模糊控制器会适当的增加ΔKp,这时P的权重很大,I参数权重很小,目的是使混肥浓度最快接近目标值;当误差较大(e1≥|e|≥e2)时,控制器会同时改变ΔKp、ΔKi、ΔKd的参数大小,目的是使混肥浓度慢慢逼近目标值;当误差较小(|e|≤e2)时,控制器会适当增加ΔKi,这时I的参数权重很大,P的参数权重会很小,目的是使混肥浓度达到稳定的目标值。除了在线自整定PID参数外,还可以引入变论域思想方法[8],通过云模型推理规则,实现定量与定性之间的转换,最后在线修改模糊控制表,提高系统自适应。
通过这样设计的控制器,混肥系统既具有快速性又具有稳定性。也就是说,混肥系统考虑了初期的快速性及混肥中段的稳定性和快速性,也考虑了混肥末段的稳定性[9]。该控制器有效解决了快速不能稳定和稳定不能快速的矛盾。变论域模糊PID控制器的结构框图如图1所示。

图1 变论域模糊PID控制器结构框图
整个控制器包括5部分,即PID控制器、模糊控制器、论域调整、执行机构及被控对象(混肥浓度)。PID控制器作为整个系统的基本控制单元,其被控参数由初始值和整定值两部分构成。由控制结构框图可知,将控制过程进行离散处理后写成增量形式为
Δu(k)=(Kp0+ΔKp)[e(k+1)-e(k)]+
(kio+Δki)·e(k)+
(Kd0+ΔKd)·[e(k)-e(k-1)]
(6)
其中,比例系数、积分系数和微分系数的基础值可以由Kp0、Ki0和Kd0来表示,比例系数、积分系数和微分系数的修正值可以由ΔKp、ΔKi和ΔKd表示,e(k)用来表示目标值与测量值之间的偏差。
4 云模型设计
类语言的进化是人工智能的基础,是人类智慧的结晶,以自然语言为切入点研究人工智能,研究人工智能与自然语言的不确定性和形式化。
李德毅教授基于模糊控制中隶属函数的定义提出了云模型的概念,是一种崭新的隶属云概念。早期已经对模糊理论和随机理论进行了深入的研究,云模型的概念正是基于两大理论研究成果衍生出来的,其将两种理论结合起来形成一种定量与定性的映射。定量模型可以表示系统输入的被控参数,本设计指的是偏差及偏差的变化率。定性模型表示的具有一定控制规则的语言值,将语言值进行推理,最后形成具有规律性的控制规则表,这是本章的研究目标之一。 此方法依据人的经验、感受和逻辑判断而不需要依赖精确地数学模型,通过云模型和语言子集将自然语言表达的控制经验转换成语言控制规则[10],可以解决不确定性和非线性问题。
4.1 云和云滴
定量模型可以表示系统输入的被控参数,定性模型表示的是具有一定控制规则的语言值,它们可以通过云模型的推理机构实现不确定性转换,在智能水肥控制算法中可以表示“控制规律”与 “浓度误差变化”之间的不确定转换。云模型的基本单元是隶属云,其定义如下:设是U一个普通集合,U={x},称为论域。关于论域U中的模糊集合T,是指对于任意x都存在一个有稳定倾向的随机数μT(x),叫做x对T的隶属度。如果论域中的元素是简单有序的,则U可以看作是基础变量。隶属度在U上的分布叫做隶属云[11],(x,μT(x))称为云滴,若μT(x)服从正态分布则称此时的隶属云为正态云[4]。
云以自然语言中的基本语言值作为出发点,可以对定性概念的量化方法进行研究,具有普遍性和直观性。将定性概念转换成单个定量值过程中是离散的,具有偶然性[7]。利用概率分布函数可以描述[4]、选取的每个特定点,因为都是随机事件。云在论域空间是由大量云滴构成的,云可以自由伸缩、没有边沿、远看有形、近看无边,如同自然环境中的云,这也是利用“云”来描述数据之间的数学转换的原因。
4.2 云滴求解
正向云发生器算法是云滴求解过程的主要依据,正向云发生器不仅在一维空间论域可以发挥作用,在二维论域正态云发生器也同样适用[5]。此算法的关键在于复用关系的运用。输入:系统输入的数字特征包括期望(Ex)、熵(En)、超熵(He),它们之间可以通过随机分布函数生成n个云滴。输出:系统的输出为n个云滴,以及n个云滴模型下的确认度μ,表示为
drop(xi,μi),i=1,2,…,n
(7)
具体算法过程如下:
1)建立以En为期望(En表示论域中能够被语言值所接受元素的个数),He2为方差的正态随机数,即
(8)

(9)
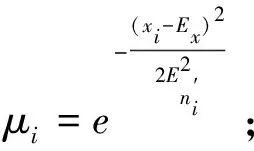
4)在论域中,云滴可以表示为拥有确认度ui的xi集合,用(xi,μi)表示生成的正态云滴;
5)只有生成n个云滴才能结束1)到4)的循环。
4.3 设计云模型推理机
云模型的数字特征可以描述事件发生的规律性,它作为正态云发生器的输入,经过随机函数处理,可以生成n个满足条件的云滴(xi,μi)。若输入条件xi已知,那么与xi成映射关系的云可以定义为X条件下的隶属云;同理,输入μi已知,那么与μi成映射关系的云可以定义为Y条件下的隶属云。通常云推理规则是由一个或几个前件与一个后件组成,依次定性规则可以分为单条件规则(ifAthenB), 前期推理过程由X条件下的隶属云计算,后期推理过程由Y条件下隶属云[4]计算。
对于多入多出的MIMO系统,它基于多变量控制可以根据推理要求设计多个MISO子系统,推理过程如下:
1)计算系统维输入向量,即
Input=(x1,…,xi,…,xm)
(10)
2)输入变量xi激活X条件隶属云,计算隶属度,即
Qij=F1(Enj,Hej)
(11)
(12)
其中,Qij表示服从正态分布的随机数,由xi论域上第j个云模型通过计算生成的;N表示云滴个数。
1)m个隶属度激活同一个推理规则F1,根据最小合成算法,计算推理前件的输出,得到激活强度,即
μ1=min(μj(xi))
(13)
2)每个规则的推理前件可以根据推理规则表,找到其推理后件满足映射关系的Y条件隶属云,计算推理输出,即
Qyl=F1(Enyl,Heyl)
(14)
(15)
其中,Qyl表示服从正态分布的随机数,是由y论域上第l个云模型通过计算生成的;N为生成的云滴个数。
3)通过上面的运算可以求出各规则推理输出,加权平均计算得到最终推理输出,即
(16)
综上分析,基于云模型原理,混肥过程中通过浓度误差变化情况,在线调整控制规则,实现定量表示与定性概念之间的转换。具体的流程如下:混肥浓度误差及误差变化率→正态云发生器→正态分布函数处理→n个云滴→云模型推理机→调整模糊规则。
5 变论域模糊控制设计
模糊控制器以模糊理论为基础,主要的控制过程包括模糊化和解模糊,在本设计的要求下,它是双输入双输出系统。输入为e和ec,e表示浓度控制过程中产生的偏差,基本论域为[-αeE,αeE];ec表示浓度控制过程中偏差的变化率,基本论域为[-αeEC,αeEC]。ΔKp、ΔKi和ΔKd是PID控制参数的修正值,作为模糊控制器的输出,基本论域分别表示为:[-βΔkpKp0,βΔkpKp0]、[-βΔkiKi0,βΔkiKi0]、[-βΔkdKd0,βΔkdKd0];αe、αec、βΔkp、βΔki、βΔkd分别为输入输出变量的整定因子[4],它们的整定变量由EC目标值决定,这里用比例函数求解过程如下:
(17)
(18)
(19)
根据实际经验和测试,a和b的取值均为0.8,各个输入输出变量的模糊论域可以调整为[-6,6],量化因子和比例因子为
(20)
(21)
整定因子具有变量伸缩性,它的变化可以调整量化因子的量化等级,还可以改变比例因子参数大小。分析可知,量化因子和比例因子随整定因子的变化而变化。在论域条件下,它们的模糊合集均可表示为{NB,NM,NS,ZS,PS,PM,PB}(NB为参数负大,NM为参数负中,NS为参数负小,ZS为参数归零,PS为参数正小,PM为参数正中,PB为参数正大),论域均为(-6,6)。两者的隶属函数均选择三角形型隶属函数[12],如图2所示。

图2 模糊控制器输入输出变量的隶属关系
模糊控制器采用的模糊规则语句形式为“if E isαand EC isβ, then U isγ”。其中,α、β、γ均表示各参数对应的模糊集。根据专家经验和去模糊处理后得到ΔKp、ΔKi和ΔKd的模糊控制规则,如表1~表3所示。

表1 ΔKp模糊控制规则表

表2 ΔKi模糊控制规则表

表 3 ΔKd模糊控制规则表
6 PID参数设计
PID参数的设计原则:通过计算实际混肥浓度与设定混肥浓度的误差e与误差变化率ec,e和ec通过模糊化、模糊推理及解模糊得到PID参数增量ΔKp、ΔKi和ΔKd,再与当前PID初值相加,得到下一时刻的PID控制量,即
Kp=Kp0+ΔKp
(22)
Ki=Ki0+ΔKi
(23)
Kd=Kd0+ΔKd
(24)
其中,Kp0、Ki0、Kd0为PID初值,Kp、Ki、Kd为PID下一时刻值。
本控制器根据专家长期的实践积累,建立合适的模糊规则表ΔKp、ΔKi、ΔKd,PID控制器根据模糊控制器的输出和PID的初值,自适应得出控制量,可控制电磁阀打开和关闭的时间比例,控制肥料原液的输入量,进而控制肥液混合浓度。
7 仿真结果
仿真之前需要确定模型结构,根据模型分析和离散方程,采用带延迟环节的一阶系统传递函数表示,即
(25)
由阶跃曲线的初端和末端确定初值和终值,计算出开环增益K。记录系统上升30%的时间t1和系统上升60%时间t2,根据t2-t1, 求到时间常数T;系统延时为时间τ,得到仿真模型为
(26)
1)测试阶跃响应。一阶保持器可以实现离散信号和连续信号的转换,传递函数在保持器的作用下进行离散化处理,规定采样时间Ts=2s。测试初期,将混肥EC值设定为0.4,系统输送到田间管网的灌溉流量设定为3,控制目标值可以设置多个,根据测试要求设计了4组浓度目标值,yd依次为1.3、2.3、1.8、2.2、1.6等5个值,控制器比例调节初值Kp0设定为46。基于VFPID控制算法调节曲线和基于PID控制算法调节曲线的对比仿真结果,如图3所示。

图3 测试阶跃响应仿真结果
2)随机工况跟踪试验。前面已经进行了阶跃响应下控制浓度的跟踪实验,为了测试系统在扰动作用下EC的变化情况,这里将目标值yd固定为1.5,系统输送到田间管网的初始流量固定为3,测试过程中将系统输出流量作为变量,随机进行4次变化,随机变量根据测试标准,其取值范围为2.3~9.5。VFPID控制算法和 PID控制算法的仿真结果如图4所示。

图4 测试抗干扰仿真结果
3)仿真结果分析。由图3和图4可以看出:VFPID控制和PID控制都属于闭环控制,在外界条件的变化下均能使系统最终稳定,测试过程中通过设置不同的设定值和不同的系统输出流量模拟外界条件的变化。通过仿真曲线可以发现:在适应环境变化方面VFPID控制算法优于PID控制算法,因为VFPID控制算法可以根据误差的变化实时校正控制参数,使浓度调节过程具有更小的超调量和更短的调节时间,仿真对比结果体现了VFPID控制算法的优越性。
8 结论
首先建立了混肥浓度模型,通过对模型的分析发现被控对象的性质是大滞后、强时变,常规控制器难以达到预期效果。本设计引入变论域模糊控制思想,基于正态云发生器算法将混肥浓度的变化情况转化成具有一定隶属度的云滴,在云模型推理机的推理下将具有隶属度的云滴转化成模糊规则,从而实现模糊规则的在线调整;并进行了两种不同条件下的仿真实验,验证了变论域模糊PID控制效果更好。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29 01:09:42
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:14
海峡科学(2021年12期)2021-02-23 09:43:28
成都信息工程大学学报(2021年6期)2021-02-12 03:00:52
小天使·六年级语数英综合(2019年6期)2019-06-27 06:42:53
测控技术(2018年10期)2018-11-25 09:35:52
Coco薇(2017年11期)2018-01-03 20:59:57
暨南学报(哲学社会科学版)(2016年9期)2017-01-15 13:52:02
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
地球环境学报(2016年1期)2016-03-06 11:55:09
