
拖拉机装配车间调度系统设计—基于粗糙集理论和大数据挖掘
2020-10-17 01:03郅芬香王留芳
农机化研究 2020年6期
郅芬香,王留芳,梁 硕
(1.鹤壁汽车工程职业学院,河南 鹤壁 458030;2.河南工业职业技术学院,河南 南阳 473000)
0 引言
粗糙集理论是由波兰数学家Z.Pawlak 在20世纪80年代初提出的一种处理模糊和不精确性问题的新型数学工具,利用粗糙集理论进行数据挖掘,最重要的就是基于粗糙集理论的属性约简。通过约简操作降低属性的纬数,总结出适用于决策支持的知识规则,是粗糙集理论最重要的应用之一。数据挖掘是从大量的、不完整的、有噪声的、模糊的、随机的大型数据中提取隐含在其中的、人们事先未知的、具有潜在价值的信息和知识的过程,在拖拉机装配方案的选择过程中,调度系统为了快速选择合理的工艺方案,可以采用数据挖掘的方法从多套方案中进行关联规则的挖掘,指定合理的工艺方案评价方法,提高车间调度系统的作业效率具有重要的意义。
1 粗糙集与数据挖掘在拖拉机装配工艺中的应用
在确定拖拉机装配工艺路线时,由于可供备选的工艺路线有多种,最好采用数据挖掘的方法对工艺路线进行优选,确定出最佳的评价方法。粗糙集是数据挖掘算法的一种,在进行数据挖掘时可以对信息数据进行属性简约,将粗糙集和其他算法进行结合,还可以明显地提高数据挖掘的效果,如采用遗传算法。其主要流程是首先对提供的数据缺失的部分进行补充,然后根据数据的特点利用已经定义的可辨识矩阵,通过属性简约算法进行简约和知识发现,最后对知识发现的规则利用遗传算法进行优化,得到主要的规则。
在进行数据挖掘之前,首先要对待处理的数据进行采样和整理,因为很多数据是冗余的,要通过数据处理去掉一部分无效的信息,然后是数据的离散化和缺损信息的补充。粗糙集数据挖掘方法在进行数据处理时只能处理离散数据,因此还要对数据进行离散化。在进行离散化时必须选择合适的断点,才能进行有效的离散化,断点的选取可以根据数据的属性特点,数据的补齐可以通过经验进行填补,或者利用均值处理和频率统计等方法进行填补。
属性简约是粗糙集数据挖掘的重要步骤,通过属性简约可以用最少的属性区分不同的决策,得到约减集合。经过粗糙集减约后,属性的个数会减少很多,但得到的规则数量可能还是比较大的,因此还要根据数据的共性来进行关联规则的提取,这就是数据挖掘过程中数据的优化问题。数据优化可以使用遗传算法进行优化,其主要步骤如图1所示。
在数据挖掘过程中,为了得到最佳的关联规则,采用了遗传算法。首先是数据的编码,可以根据拖拉机工艺方案的性质和需求,对其评价的关联规则进行编码处理,采用二进制数字编码对关联属性进行编码。编码完成后,便可以进行遗传算法操作:首先选取初试种群,可以用工艺方案的任何一个个体作为初始种群;遗传算法实现过程中一个非常重要的步骤是确定评价函数,评价函数可以将关联规则中联系最多的进行匹配;最后便是遗传操作,包括交叉和变异,交叉是对编码数据进行位置变换,变异是对编码数据进行取反,经过评价函数确定最优后,得到拖拉机装配工艺方案选取的最佳评价方法。
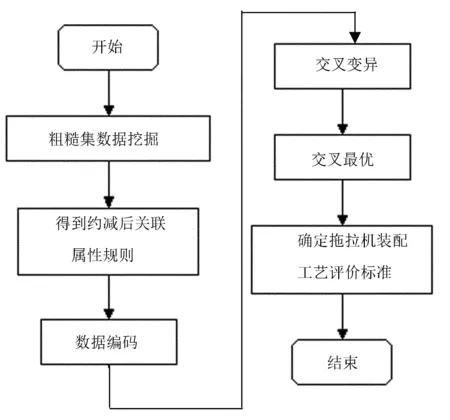
图1 关联规则遗传算法处理步骤
2 拖拉机装配车间调度工艺设计
在先进的现代化装配车间,生产管理调度是非常重要的。为了实现车间生产部门大量的业务处理工作,必须使用计算机进行现代化的调度管理。在拖拉机装配车间调度系统功能设计时,需要设计车间装配的作业计划、作业拆解、任务排序与自动分配管理等几个方面的功能,实现全面化的计算机管理。其基本功能框架如图2所示。
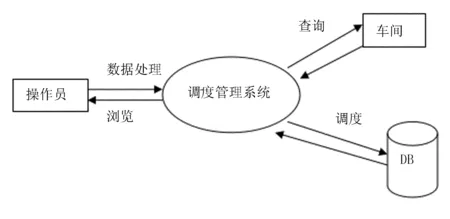
图2 拖拉机装配车间调度系统基本功能框架
拖拉机装配车间调度系统总体的功能主要分为查询、调度和数据处理等。其中,数据处理包括前边介绍的粗糙集数据挖掘算法,处理数据包括设备属性和工艺属性等。设备属性框架如图3所示。

图3 设备属性功能框架
设备属性包括设备的类别编号、类别名称、使用年限、数量和备注等。设备选用之前,可以利用数据挖掘算法对设备进行筛选,得到最佳的设备类型。
工艺路线信息如图4所示。拖拉机装配工艺的路线信息较多,包括一些产品图号和名称、工序编号和名称,还包括标准工时、人工数量、使用设备等,其类型、主键和长度信息如表1所示。
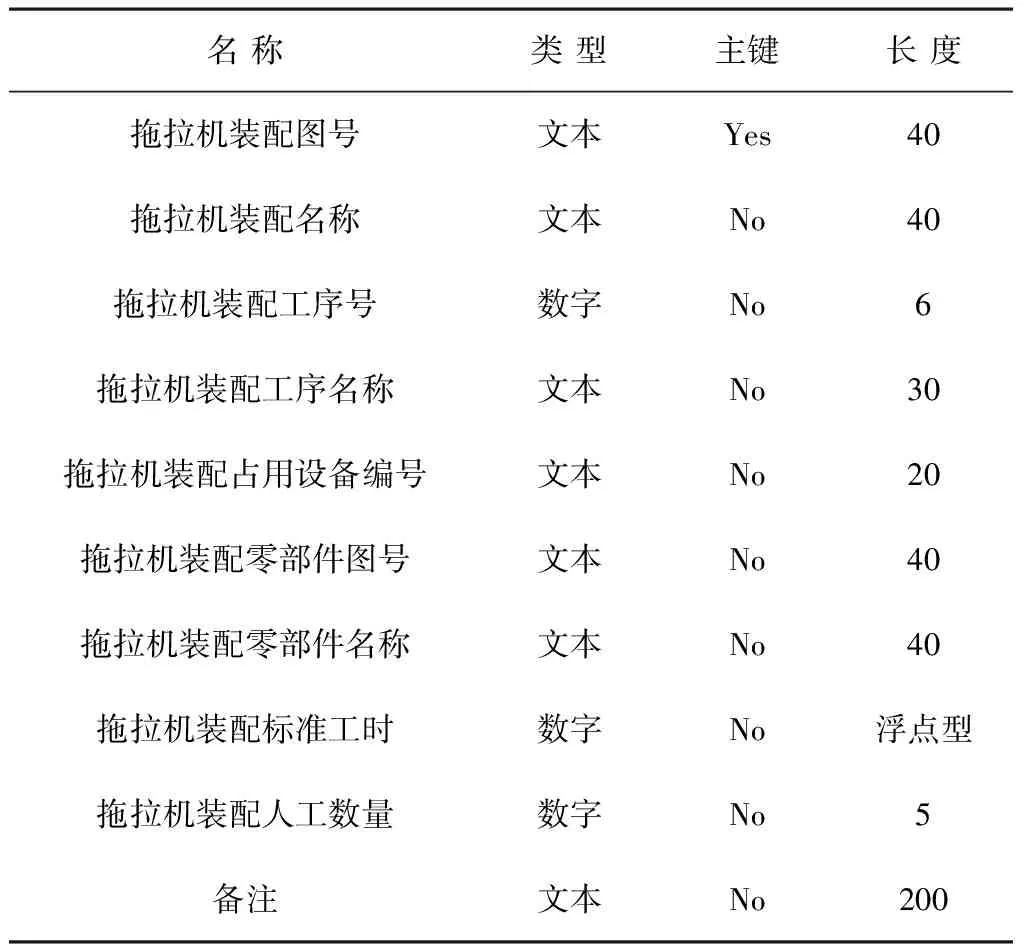
表1 工艺路线信息表
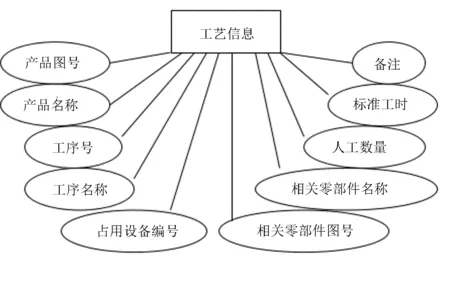
图4 工艺路线信息
拖拉机装配工艺路线包含的信息量非常大,在工艺路线方案确定时,可以采用数据挖掘方法对工艺路线所包含的信息属性进行约减,然后通过关联规则的提取确定最佳评价方案。
基于粗糙集和数据挖掘的调度系统优化如图5所示。粗糙集和数据挖掘主要是使用在拖拉机装配系统的数据处理模块优化设计上,基于粗糙集的数据信息关联规则挖掘主要分为3步:首先是数据的预处理,然后利用粗糙集对数据的属性进行约减,最后通过遗传算法优化,提取关联规则。通过优化处理后得到最佳的拖拉机装配工艺评价标准,以对备选的工艺方案进行筛选。

图5 基于粗糙集和数据挖掘的调度系统优化
3 拖拉机装配车间调度系统优化
为了验证基于粗糙集和数据挖掘关联规则在拖拉机装配工艺设计中使用的可行性,以拖拉机装配车间(见图6)调度系统的优化为例进行验证。在拖拉机进行装配时,其工艺流程中有许多要注意的问题,如装配误差、装配干涉及工序实现的难易等。为了使拖拉机的装配达到最优化,在工艺选择的过程中,需要以某几个需要注意的问题为重点来决定使用何种工艺方案。

图6 拖拉机装配车间示意图
在进行装配时,需要通过系统优化选择合理的装配工艺方案。在进行装配工艺设计时,设计企业一般会制定多种装配工艺方案。为了使装配工艺方案达到最优,可以制定一套统一的评价标准。在评价标准制定时,有以往的一些装配工艺方案进行借鉴,本次主要选取几种以往用过的方案进行评价,并利用粗糙集对属性进行简约,然后利用数据挖掘来最后决定使用何种方案,从而使装配工艺得到优化。
以往用过的8种装配方案如表2所示。其中“?”表示属性表中没有写明的情况。经过数据预处理后, 对缺失数据进行了填补及属性离散化后得到了表3所示的拖拉机装配工艺信息表。
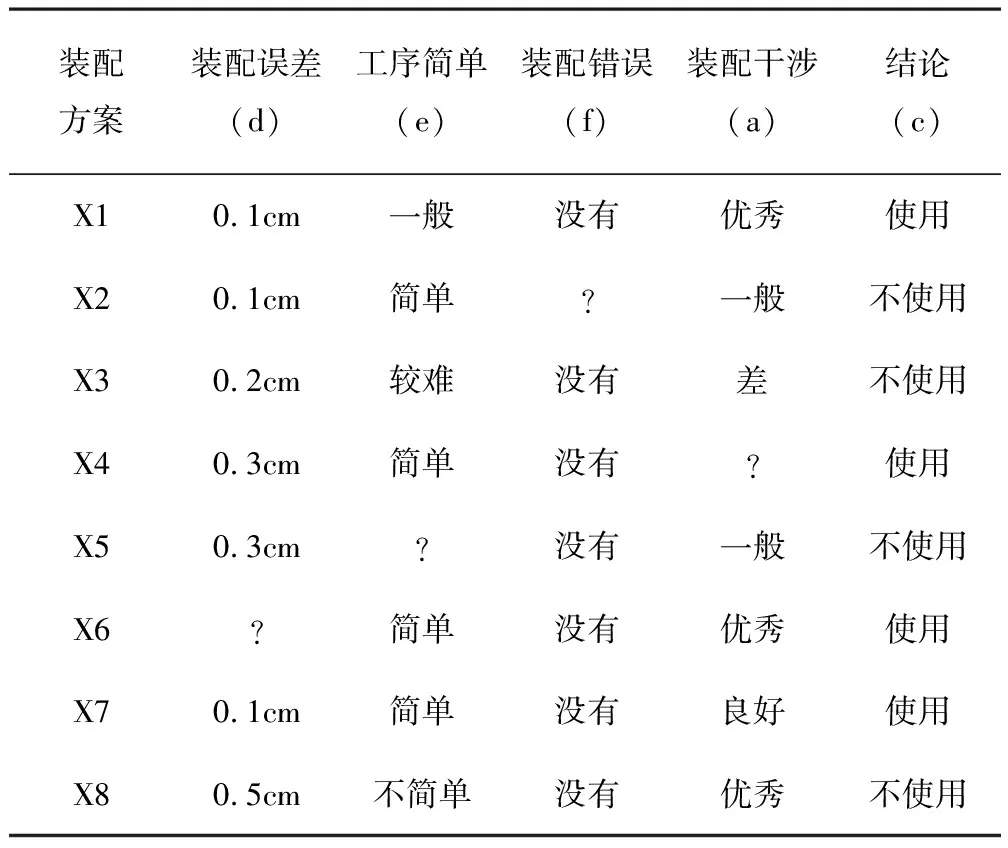
表2 拖拉机装配工艺属性表

表3 拖拉机装配工艺信息表
得到表3的拖拉机装配工艺信息表后,按粗糙集理论的属性简约的算法, 通过数据挖掘管理规则决策表的可辩识距阵, 可以得到算法第3步后的合取范式表达式为
F(d,e,f,a)=(e∨a)∧(d∨e∨a)
∧(d∨e)∧(e∨f∨a)∧(d∨e∨f)
∧(d∨e∨a)∧(d∨e∨a)∧(d∨e∨a)
∧(d∨a)∧(e)(e∨a)∧(d∨e∨f∨a)
∧(d∨e∨f)∧(d∨e∨f∨a)
∧(d∨e∨f)∧(d∨e∨a)
(1)
其中,可辨矩阵中的元素对应每个分析项,d、e、f、a分别对应属性装配误差、工序简单、装配错误、装配干涉。按算法简化后可得
F(d,e,f,a)=(e∧a)∨(e∧d)
(2)
由公式(2)可以看出:对于信息表中的数据,与决策相关的主要有d、e、a。通过粗糙集理论的属性简约,可以得到以往使用的拖拉机装配工艺的重要信息和属性,然后可以通过遗传算法得到主要的关联规则。如表2中某一个装配工艺上装配误差、工序简单、装配干涉值为201,其编码可以表示为10、00、01。假设初始种群的个体为8个,评价函数以可以匹配表中最多行属性为关联规则,定义8元组为
SGA=(C,E,P0,M,Φ,Γ,Ψ,T)
(3)
其中,C为对个体采用的二进制编码;评价遗传算法适应度函数f(x)用E表示;初始种群的个体8个规则为P0;比例选择算子为Φ;中间位单点交叉算子为Γ;变异算子为Ψ;迭代计算30次的停止符号为T。通过计算,最终得到了最佳的工艺方案个体为00、01、 01,即装配误差为0.1cm,工序简单,装配干涉一般为评价标准,通过此标准可以对提供的农机装配方案进行优化,进而对装配系统进行优化。
4 结论
为了提高拖拉机车间装配调度系统的作业效率,基于粗糙集理论和遗传算法。提出了一种新的调度系统数据处理挖掘算法。通过对工艺方案数据的属性约减和关联规则挖掘,可以快速得到工艺路线的评价参数。为了验证方案的可行性,以拖拉机装配工艺路线的选取为例,对其评价方案的制定进行了数据挖掘计算。通过计算最终得到了最佳的工艺方案个体为00、01、 01,即装配误差为0.1cm,工序简单,装配干涉一般为评价标准,为拖拉机装配车间调度系统工艺方案的选取提供了重要的数据依据。
