
基于矩阵分解的属性网络表示学习
2020-10-16 06:33卢光跃吕少卿赵雪莉
计算机工程 2020年10期
张 潘,卢光跃,吕少卿,赵雪莉
(1.西安邮电大学 通信与信息工程学院,西安 710121; 2.陕西省信息通信网络及安全重点实验室,西安 710121)
0 概述
随着互联网络科技的快速发展,网络已成为人们获取信息、互动交流的重要途径。在现实世界中,很多复杂系统都可以表示为社交网络、引文网络、生物网络和信息网络[1-3]等网络形式,而以Facebook、Twitter、微信和微博为代表的社交网络给人们的生活带来了巨大变化,人们在社交网络中的活动产生了大量数据,而这些数据通常蕴涵着丰富的可用信息。此外,引文网络、移动互联网络和生物网络由于结构复杂,并且隐含其中的深层信息通常具有重要的研究意义,因此也受到了学术界的广泛关注。
机器学习是人工智能的重要研究方向,近年来已有越来越多的机器学习算法被提出,其性能远超传统算法,但由于网络是一种特殊的数据结构,其不能直接作为机器学习算法的输入进而实现网络分析任务,因此网络表示学习技术应运而生[3]。网络表示学习旨在将网络中的节点表示为低维实值向量,在一定程度上保留了原始网络信息。在学习并得到节点表示向量后,可使用机器学习算法进行节点分类[4]和链路预测[5]等网络分析任务。基于局部线性嵌入(Locally Linear Embedding,LLE)[6]和拉普拉斯特征映射(Laplacian Eigenmaps,LE)[7]的传统网络表示学习算法通常依赖于求解亲和度矩阵的主导特征向量,且时间复杂度较高,因此很难将其应用于大规模网络。
Word2vec是Google于2013年推出的一个用于获取词向量的开源工具[8],在词向量表示方面取得了良好的性能。受到Word2vec的启发,PEROZZI于2014年提出DeepWalk算法[9],创造性地将深度学习技术引入网络表示学习领域,通过随机游走生成一系列节点序列,然后将这些序列作为Word2vec算法的输入得到节点的表示向量,在节点分类、链路预测等网络分析任务中取得了较好的效果。文献[10]提出LINE算法且定义网络节点间的一阶相似性和二阶相似性并对其进行概率建模,通过最小化概率分布和经验分布的KL散度,得到最终的节点表示向量。文献[11]提出Node2vec算法,其在DeepWalk算法的基础上设计广度优先游走和深度优先游走两种采样策略,并挖掘出网络局部特性和全局特性,最终得到节点的表示向量。
然而,上述算法仅考虑了网络拓扑结构信息,并未有效利用网络节点的属性信息,而现实世界中的网络包含性别、爱好、职业和文本信息等节点属性信息。因此,如何将这些属性信息有效融合到网络表示学习算法中是近年来急需解决的问题。为此,研究人员提出TADW[12]、AANE[13]等算法。文献[12]证明了DeepWalk算法与矩阵分解的等价性,并对网络文本信息加以利用,使得TADW算法能得到质量更高的节点表示。AANE算法融合了网络结构信息和节点属性信息,并将建模和优化过程分解为多个子问题,通过分布式方式进行联合学习,大幅提升了训练速度。但TADW算法针对的节点属性信息为文本信息,忽略了文本中词的词序信息及网络结构的一阶相似性,难以有效挖掘出深层语义信息[14]且解释性不强,而AANE算法虽然保留了网络结构的一阶相似性,却忽略了网络结构的二阶相似性。
本文提出一种基于矩阵分解的属性网络表示学习算法(ANEMF)。该算法定义二阶结构相似度矩阵和属性相似度矩阵,通过对网络结构相似度和属性相似度损失函数进行联合优化,实现网络结构信息和节点属性信息的融合,从而得到节点的向量表示。
1 属性网络表示学习
为更好地描述本文提出的属性网络表示学习算法,表1列出了主要参数及其定义。

表1 主要参数及其定义Table 1 Main parameters and their definitions
1.1 相关概念
本节主要介绍与本文工作相关的一些定义和模型。

1.2 结构相似性
网络中直接相连的两个节点更可能具有相似的向量表示(具有较高权重的节点对在表示空间中的距离更近),即一阶相似性[10]。如果两个节点之间存在一条边,那么它们在低维向量空间中的表示应该相似。可以看出,一阶相似性是网络结构最为直接的表达形式,因此有必要将其保留。
本文将网络邻接矩阵A作为节点间的一阶相似度矩阵,为保留一阶结构相似性,定义以下损失函数来最小化连接节点之间的表示差异:
(1)
其中,‖·‖F表示矩阵的F范数。
(2)
其中,ai为邻接矩阵A的第i行,为保留二阶结构相似性,最小化以下损失函数:
(3)
基于以上分析,为同时保留网络结构的一阶相似性和二阶相似性,本文将最终网络拓扑结构信息的损失函数定义为:
(4)
其中,参数α>0为二阶结构相似性的权重系数,通过调节α的大小以适应不同网络。
1.3 属性相似性
(5)
其中,ti为属性矩阵T的第i行。为保留属性相似性,本文将属性信息的损失函数定义为:
(6)
1.4 网络表示联合学习
上文通过定义JS和JA两个损失函数完成对网络结构信息和节点属性信息的建模。为使得到的表示向量能够同时保留网络结构信息和节点属性信息,对上述两种信息进行联合建模,其联合损失函数如式(7)所示:
J=JS+βJA=
(7)
其中,β是调节节点属性信息贡献程度的一个非负参数,以适应不同网络和特定任务。具体而言,β越大,意味着节点属性对表示学习的影响越大。从式(7)可以看出,该模型的基本思想旨在使节点表示向量的内积接近结构相似度的同时也尽可能地接近属性相似度。
1.5 模型优化
本节先介绍损失函数的优化,即最小化式(7),再给出基于矩阵分解的属性网络表示学习算法的伪代码。由矩阵的F范数和迹之间的关系得到:
J=tr(ATA+αSTS+βMTM)-
2tr(AT+αST+βMT)YYT+
(1+α+β)tr(YYTYYT)
(8)
对Y求偏导得到:
2α(S+ST)Y-2β(M+MT)Y]ij=
[4(1+α+β)YYTY-4(A+αS+βM)Y]ij
(9)
因此,Y具有以下更新规则:
(10)
由文献[18]可得Y的乘法更新规则为:
(11)
根据以上分析可得基于矩阵分解的属性网络表示学习算法(ANEMF)的伪代码,如算法1所示:
算法1ANEMF算法
输入属性网络G=(V,E,T),迭代次数i,二阶结构相似性权重系数α,属性相似性权重系数β,表示向量维度d
输出网络节点表示矩阵Y,每一行对应节点的表示向量rv,v∈V
1.计算邻接矩阵A
2.根据式(2)计算二阶相似度矩阵S
3.根据式(5)计算属性相似度矩阵M
4.初始化节点表示矩阵Y
5.J=0
6.for iter=1 to i
7.根据式(7)计算损失函数J
8.if相邻两次损失函数J的差值小于阈值,跳出循环
9.根据式(11)更新Y
10.end
1.6 算法复杂度分析
由上文分析可以看出,算法时间复杂度主要取决于矩阵的乘法运算,每更新一次节点表示矩阵Y需要的时间复杂度为O(n2d),其中,n表示节点数量,d表示节点表示维数。由于实际应用中d远小于宏准确率(Macro-P),因此本文ANEMF算法的时间复杂度为宏召回率(Macro-R)。
2 实验结果与分析
2.1 实验数据集
本文选取3个公开的真实网络作为实验数据集进行实验仿真,其统计数据如表2所示。
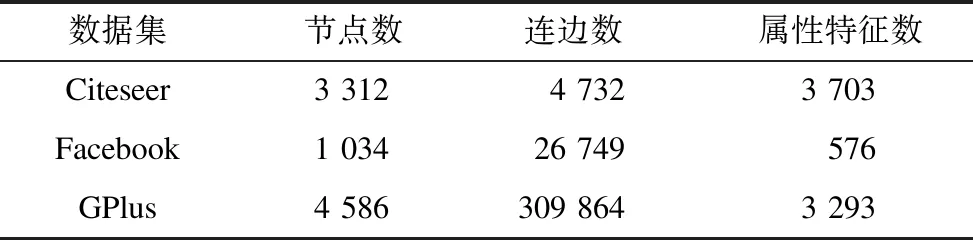
表2 实验数据集统计Table 2 Experimental datasets statistics
Citeseer数据集包含3 312个节点和4 732条边,以及6个类别标签,其中每个节点表示一篇论文,每条边代表两篇论文间的引用关系,每篇论文都由一个3 703维的二进制0/1向量进行描述。在本文中,将每个二值向量视为对应节点的属性信息。
Facebook数据集[19]包含1 034个节点和26 749条边,其来自一个Facebook用户的匿名ego-network,节点表示ego用户的朋友,边表示朋友之间的友谊关系。每个节点包含“生日”“工作”“性别”“教育”“语言”“地区”等10个匿名属性信息,使用一个576维的向量进行表示,并将性别作为类别标签。
GPlus数据集[19]包含4 586个节点和309 864条边,其来自一个Google Plus用户的匿名ego-network,节点表示ego用户的朋友,边表示朋友之间的友谊关系。每个节点包含“性别”“机构”“职业”“姓氏”“地区”“大学”6个属性信息,使用一个3 293维的向量进行表示,并将性别作为类别标签。
2.2 对比算法及参数设置
DeepWalk算法:基于Random Walk采样和SkipGram模型训练学习得到的节点表示向量,仅利用网络结构信息进行网络表示学习。实验中DeepWalk算法的参数设置具体为:节点序列长度为40,每个节点采样的序列数量为40,滑动窗口大小为10。
TADW算法:基于矩阵分解模型将结构信息矩阵分解为两个参数矩阵和一个属性信息矩阵,并将网络结构信息和节点属性信息相融合得到节点表示向量。实验中TADW算法的参数设置参考文献[12],其中λ=0.2。
为保证对比的公平性,实验中将节点的表示向量维度设置为d=100。另外,本文ANEMF算法的参数设置为α=3、β=1。
2.3 节点分类性能分析
本文将节点表示向量用于多分类任务以评价算法性能。由文献[20]可知,分类结果使用F1值作为算法评价指标,F1值是分类问题常用的衡量指标。对于有k个类别标签的数据集而言,假设将第i类数据预测为第i类的个数(真正例)表示为TP(i)、将第i类数据预测为非第i类的个数(假反例)表示为FN(i),将非第i类数据预测为第i类的个数(假正例)表示为FP(i),则F1值定义为:
(12)
其中,P为准确率,R为召回率,具体计算公式如下:
(13)
(14)
在通常情况下需要进行多次训练和测试同一数据集以客观评价模型优劣,因此会产生多个不同的TP(i)、FP(i)、FN(i)和TN(i),不妨假设得到n组不同值并对每组值分别计算P与R,从而得到n组P和R,再对其进行求平均得到宏准确率(Macro-P)、宏召回率(Macro-R)和宏F1值(Macro-F1)以及微准确率(Micro-P)、微召回率(Micro-R)和微F1值(Micro-F1)。
(15)
(16)
(17)
(18)
(19)
(20)
本文对每个数据集进行10次独立重复实验,取10次实验的Micro-F1值和Macro-F1值作为最终实验结果,其中训练率设置为2%、4%、6%、8%、10%、15%、20%、30%、40%。表3~表5分别记录了3个数据集在不同训练率下的节点分类实验结果,表中加粗数据表示对应训练率下的最大值。

表3 Citeseer数据集上的节点分类F1值Table 3 Node classification F1 value on Citeseer dataset %

表4 Facebook数据集上的节点分类F1值Table 4 Node classification F1 value on Facebook dataset %
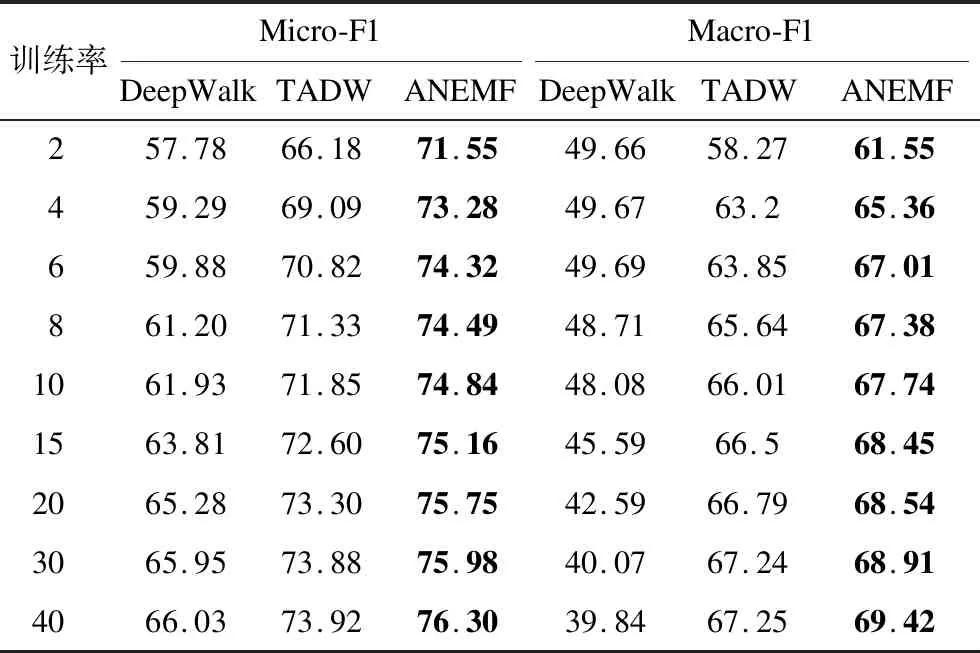
表5 GPlus数据集上的节点分类F1值Table 5 Node classification F1 value on GPlus dataset %
可以看出,仅利用网络结构信息的DeepWalk算法性能较差,而同时考虑网络结构信息和节点属性信息的TADW算法和本文ANEMF算法的性能相对较好,证明了节点属性信息对于网络表示学习质量的提升具有重要作用。在Facebook数据集和GPlus数据集上,本文ANEMF算法在节点分类实验中的优势较为明显,以Micro-F1为评价标准,在Facebook和GPlus数据集上,相比TADW算法的节点分类性能提高3.15%~5.11%和2.1%~5.37%;以Macro-F1为评价标准,在Facebook和GPlus数据集上,相比TADW算法的节点分类性能提高了0.17%~4.51%和1.73%~3.28%。在Citeseer数据集上,本文ANEMF算法的性能表现在训练率较低时有较大优势,随着训练率的提高,TADW算法的性能表现优于本文ANEMF算法,但优势并不明显(Micro-F1值的差值在0.5%以内),其原因为Citeseer数据集的节点属性信息为文本信息,而TADW算法的设计初衷就是融合节点的文本信息。总体而言,本文ANEMF算法在节点分类任务中的性能表现优于对比算法。
2.4 算法稳定性分析
本文ANEMF算法主要包括二阶结构相似性权重系数α、属性相似性权重系数β和节点表示向量的维数d3个参数。为研究这3个参数对本文ANEMF算法的影响,通过在Citeseer、Facebook和GPlus 3个数据集上的实验对这3个参数进行分析,其中训练率固定为10%。图1~图3分别为本文ANEMF算法在3个数据集上选择不同α和β时的节点分类F1值的变化情况,其中α和β的取值均为0.1、0.5、1.0、3.0、5.0。可以看出,对于节点表示维数d=100,性能指标Micro-F1值在Citeseer、Facebook和GPlus 3个数据集上的变化范围分别为3.0%、1.5%和1.6%。因此,整体上看ANEMF算法的性能更稳定。
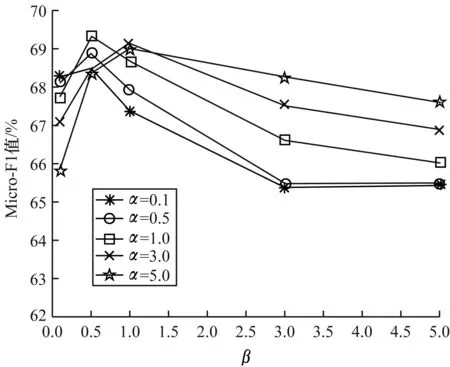
图1 ANEMF算法在Citeseer数据集上选择不同α和β时的Micro-F1值变化情况Fig.1 The change of Micro-F1 value when the ANEMF algorithm selects different α and β on Citeseer dataset
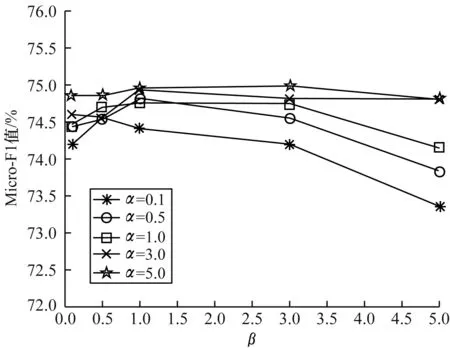
图3 ANEMF算法在GPlus数据集上选择不同α和β时的Micro-F1值变化情况Fig.3 The change of Micro-F1 value when the ANEMF algorithm selects different α and β on GPlus dataset
图4给出了本文ANEMF算法在3个数据集上的Micro-F1值随着表示维数d的变化情况,其中d的取值分别为25、50、100、150、200。可以看出,对于Citeseer数据集而言,随着d的增加,性能指标Micro-F1值也增大,当d=50时,实验结果更优,当d>100后,性能指标Micro-F1值开始下降,并慢慢趋于稳定;对于Facebook和Gplus数据集而言,随着表示维数d的增加,Micro-F1值稳步提升,最后趋于稳定。因此,本文实验中选用d的默认值为100维,在保证分类性能的同时具有较低的节点表示向量维数。综上所述,当参数α、β和d在合理的取值范围内变化时,本文ANEMF算法具有稳定的性能表现。
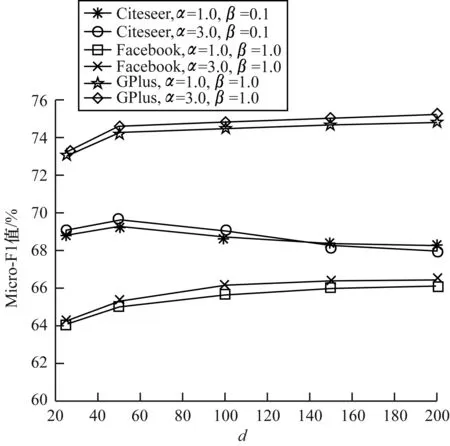
图4 ANEMF算法在3个数据集上Micro-F1值随d的变化情况Fig.4 The change of Micro-F1 value with d on three datasets of ANEMF algorithm
3 结束语
本文提出一种基于矩阵分解的属性网络表示学习算法(ANEMF),联合网络拓扑结构和节点属性信息进行网络表示学习,使得到的节点表示向量能够同时保留网络拓扑结构信息与节点属性信息。在3个真实公开数据集上进行节点分类和算法稳定性实验,结果表明本文ANEMF算法在3个数据集上的表现均优于DeepWalk和TADW算法,能够有效提升节点表示向量在节点分类任务中的性能。但由于现实中的网络存在明显的社区结构特性,因此后续可将网络社区结构信息融入网络表示学习算法中,进一步提升网络表示学习质量,使得到的节点表示能更精确地刻画原始网络特性。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
河北画报(2020年8期)2020-10-27
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
浙江大学学报(工学版)(2016年2期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
