
汉语连续语音切分技术研究∗
2020-10-14 11:49王宇琛张二华
计算机与数字工程 2020年8期
王宇琛 张二华
(南京理工大学 南京 210094)
1 引言
语音切分是语音识别的重要步骤之一,其准确性会直接影响到语音的识别率。语音切分的方式分为人工切分和自动切分两种[1]。人工切分方法能够保持较高的准确率,但也存在诸多弊端,一是工作量太大,对于大型语料库不太适合;二是缺少一致性,对同一种语音现象的判断,不同的人会有不同观点,即便同一个人,在不同的时间也不一定能保证作同样的判断[2]。随着语音识别技术的发展,大规模语料库的音节标注如果完全采用人工切分,将会消耗大量的时间及劳动力,因此自动切分技术的研究显得尤为重要。
语音的自动切分包含两个步骤,一是语音信号的端点检测,二是语音段基元的切分[3]。
端点检测技术用于提取原始信号中语音段的起始点与结束点,剔除无声段与噪声段[4]。该步骤用于保证后续的语音处理在语音段的基础上进行,排除掉非语音段的干扰,减少了运算量,节省处理时间,也增加了准确性。
汉字是单音节字,声学上汉语的一个字对应一个音节。在语音切分和识别的过程中,音节经常作为汉语语音切分与识别的基元。对于汉语语音段的音节切分一直是语音识别中的研究热点,然而至今并没有完全准确有效的切分方法[5]。本文通过对语谱图以及基音周期轨迹的分析,研究了一种音节切分的算法,能够有效提高汉语语音切分的准确率。
2 端点检测技术
语音的端点检测是指从一段原始信号中准确地找出语音信号的起始点和结束点[6]。它的目的是为了使有用的语音信号和无用的无声段与噪声信号相分离,增加后续语音处理的有效性[7]。目前广泛采用的端点检测方法是双门限端点检测技术[8]。本文基于对传统双门限检测法理论的研究,研究了一种多阈值检测方法,有效提高了端点检测的准确率。
2.1 双门限端点检测
双门限端点检测技术的基本思想是利用短时能量和短时平均过零率这两个时域特征参数对语音信号进行切分[9]。在汉语语音中,浊音部分短时能量较高,短时平均过零率较低,而清音部分短时平均过零率较高,短时能量较低。所以在双门限算法中,短时能量可以较好地检测出浊音段,而短时平均过零率可以将清音段从无声以及噪声段中提取出来[10]。首先,统计浊音部分和背景噪声的短时能量,设定一个较高的门限参数EH,使得语音信号的能量包络大部分都在此门限之上,根据背景噪声能量确定一个较低的阈值参数EL;再统计清音和无声段的短时平均过零率,确定短时平均过零率门限ZS。具体的双门限端点检测技术步骤如下。
1)对语音信号进行预处理,求语音信号的短时能量E和短时平均过零率Z。
2)寻找符合E>EH 的语音段记为N1N2,N1、N2 表示初判语音段的起始和终止位置,这部分语音主要为主音段和过渡段。
3)从N1 往左搜索,寻找E>EL 的语音段,确定左侧的起始位置N3;同理确定右侧的终止位置N4。
4)从N3 往左和N4 往右搜索,找到Z>ZS 的语音段,确定新的起始点N5 和终止点N6,N5N6 就是检测到的语音段。
然而,实验发现,清辅音在起始阶段能量较强,尾部接近元音时短时平过零率可能会迅速下降,因此可能导致该处的短时平均过零率小于设定的阈值,从而将它误判为无声段。
同时,双门限端点检测技术在检测清辅音部分时更多的侧重短时平均过零率参数,忽视了辅音段的短时能量,只要满足Z ≥ZS就判断为辅音段。而且一些突发性的随机噪声或背景噪声往往会引起短时能量或短时过零率的数值过高,造成误判[11]。
2.2 多阈值端点检测
为了解决上述短时平均过零率参数造成的误差,本文在双门限端点检测技术的基础上,增设辅音段短时能量参数,研究了多阈值端点检测技术。多阈值端点检测算法的基本思想与双门限基本一致,其中增设辅音段的短时能量参数:EC 表示辅音段能量阈值;ES 表示疑似辅音段阈值。算法的搜索过程与双门限端点检测算法一致,经历多次遍历,分别找出满足条件的语音段。
多阈值端点检测技术的步骤如下:
1)对语音信号进行预处理,求语音信号的短时能量E和短时平均过零率Z。
2)寻找符合E ≥EH 的语音段记为N1N2,N1、N2 表示初判语音段的起始和终止位置,这部分语音主要为主音段。
3)从N1往左搜索,寻找EL ≤E<EH的语音段,确定左侧的起始位置N3;同理确定右侧的终止位置N4。
4)从N3 往左和N4 往右搜索,找到EC ≤E<EL的语音段,确定新的起始点N5 和终止点N6,N5N6就是检测到的语音段,新增部分主要为辅音段。
5)从N5 往左和N6 往右搜索,找到EC ≤E<EL且Z>ZS 的语音段,确定新的起始点N7 和终止点N8。
6)对检测到的有声段N7N8 进行整合,使之成为完整的连续语音段。
多阈值端点检测能够完成最初步的语音切分。原始信号被分为语音信号与非语音信号的两部分。同时,根据语音信号的特征可以得出结论,语音信号的起始点必然是某个汉语音节的起始点,非语音信号的起始点必然是某个汉语音节的结束点,这些分界点可以用于汉语语音段音节的切分。
3 汉语语音音节切分
汉语语音段的音节切分是指从连续的汉语语音段中提取出每一个音节,即每一个字所对应的语音段的起始点与结束点。前述部分已经实现了端点检测,该步骤处理的都是有声段,所以只需提取出起始点即可,因为起始点的前一帧,若存在语音段,则必然是上一个音节的结束点。
汉语语音的音节切分一直是汉语语音识别的技术难点之一[12]。目前并没有完全成熟的音节切分算法,本文将基音周期轨迹以及语谱图的分析相结合,研究一种汉语语音音节切分的方法,具有较高的准确率。
3.1 基音周期轨迹分析
基音周期是指发浊音时声带振动频率的倒数[13]。汉语中,大部分的元音都是浊音,大部分的辅音都是清音[14]。基音周期轨迹图可以更好地显示语音信号的基音周期随着时间的演化过程,并确定元音段的开始和结束位置。基音周期轨迹反映了元音信号的基音周期随时间的变化。
语音信号具有短时平稳性,任何语音信号的分析和处理都必须建立在“短时”的基础上,即进行“短时”分析,将语音信号分为一段一段来分析其特征参数,其中每一段称为一帧[10]。
基音周期轨迹的绘制步骤如下。
1)对语音信号进行分帧处理,帧长512 个采样点,帧移32 个采样点。对每一帧计算语音信号的倒谱数据,得到{ω1,ω2,…,ωn},其中ωn表示第n 帧的倒谱数据。
2)将倒谱数据从小到大排序,前50%的数据灰度置为255,高于99%的数据灰度置为0,取余下49%的数据的最小值ωmin和最大值ωmax。
3)利用公式:

将剩余49%的倒谱数据映射到灰度值。
4)以横轴代表时间,纵轴代表倒谱域频率,将灰度数据沿时间轴从前向后,沿频率轴从低向高绘制每一个像素点,得到基音周期轨迹图。
图1 为语音段“那年正月新春”的基音周期轨迹图。
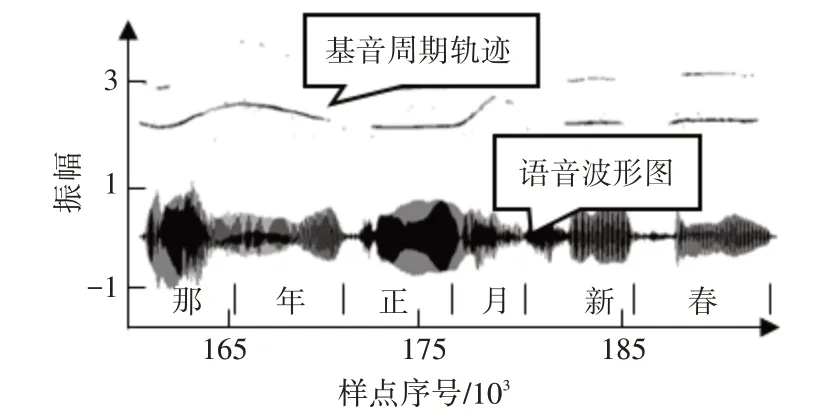
图1 “那年正月新春”的基音周期轨迹图
从图1 中可以看到,“那年正月新春”各个汉字的元音段都有清晰的基音周期轨迹,不同汉字的元音段有明显的分界。如“新”和“春”的基音周期轨迹之间有明显的中断,因为“春”字的清辅音没有基音周期。根据这个规律,可以根据基音周期轨迹提取出语音段的元音部分。
然而,一条连续的基音周期轨迹可能包含多个汉字。如“正”和“月”,两者的基音周期轨迹相连,很难准确切分。仅依靠基音周期轨迹得到的切分结果无法满足汉语单音节切分的要求,需要与语谱图分析法相结合,才能完整地实现汉语音节切分。
3.2 语谱图分析
当元音激励经过声道时,会引发一组共振频率,即共振峰频率,简称共振峰。不同的汉字音节,其元音段的共振峰也存在较为明显的区别。语谱图能够反映连续语音段的频谱特性,所以需要结合语谱图切分同一条基音周期轨迹中的多个汉字,实现完整的音节切分。
本文实验语音的采样率为16000Hz,设置语音帧长512个采样点,帧移32个采样点。语谱图绘制的基本思想是在垂直方向上绘制一系列连续语音帧的频谱,横轴表示时间,纵轴表示频率[15]。语谱图中的像素点表示语音频谱数据的振幅,振幅值的大小与像素点的颜色深浅成正比,即振幅越大,颜色越深,反之亦然。
本文通过对语谱图中辅音段、元音段的频谱特征进行分析,论述汉语音节进一步切分的思路。
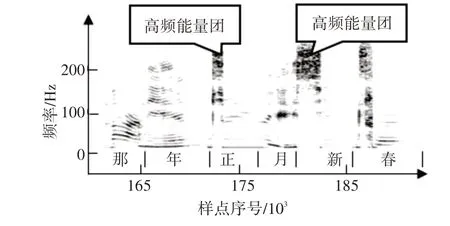
图2 “那年正月新春”的语谱图
图2 为“那年正月新春”的语谱图。语谱图的纵坐标是频率采样点序号,其中128~255 为高频部分。我们可以清楚地看到,“正”、“新”和“春”的清辅音段在高频部分存在能量团,“那”、“年”和“月”的高频部分没有明显特征,但低频部分的能量也有明显的区别。根据这两个特征,可以更加细致地对汉语语音段进行音节的切分。
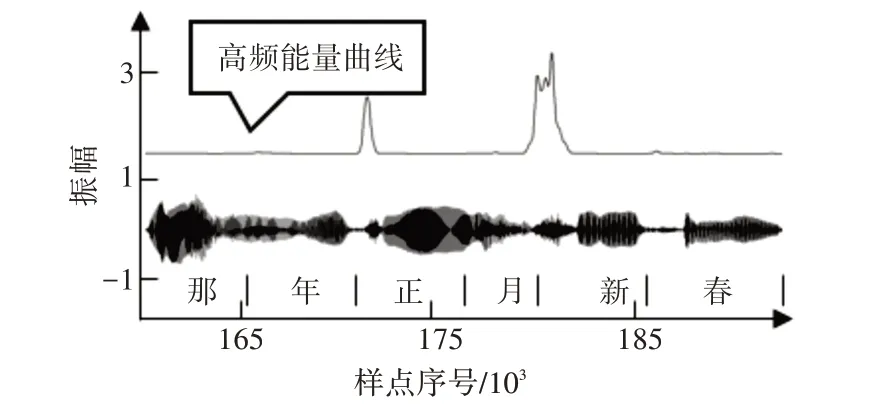
图3 “那年正月新春”的语谱图高频能量曲线
图3 是“那年正月新春”高频部分的能量曲线,根据能量的平均值设置阈值,可以提取出曲线中能量显著升高的部分。其中“正”和“新”的辅音段能量非常明显,“春”的辅音段由于相对能量不高,很难准确提取。
语谱图的纵坐标是频率采样点序号,其中0~127 为低频部分。由于不同元音段的语谱图特征分布在低频部分的不同频带内,本文采用多尺度分析法,即对于0~63、64~127、0~127 这三个频带分别依据公式:
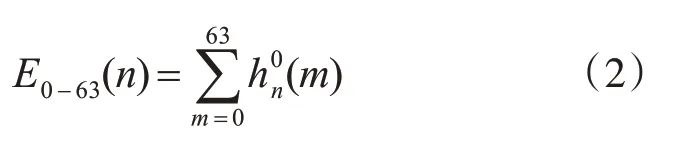

计算每一帧的能量值,其中hn(m)表示第n 帧的第m 个频谱样点的振幅值。对每个频段的能量数据依据公式:
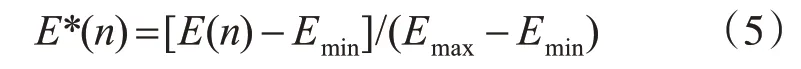
分别进行归一化处理后,绘制相应的能量曲线,如图4,确保能够显示所有频带的能量变化,减少分析时产生的误差。

图4 “那年正月新春”的语谱图低频能量曲线
通过图4可以清楚的看到,在0~63频带的能量曲线上没有显示的“正”和“月”的能量变化,在另外两个频带的能量曲线上十分明显。
在分析低频能量曲线时,需要对每一条曲线从左到右进行分析。低频能量比高频能量更加复杂,不能单纯以某一个阈值作为切分准则。本文对低频能量的变化采用双阈值进行检测,具体步骤如下。
1)根据大量样本统计,设置最短的音节帧数W1,能量上升阈值U1 和U2,能量下降阈值D1 和D2。其中U1 和D1 检测较为剧烈的能量变化,U2和D2检测较为缓慢的能量变化。
2)从曲线最左侧开始遍历,如果发现三条曲线中存在任意一条,其数据在6 帧之内相对上升值超过U1,或者在24 帧之内相对上升值超过U2,则判定语谱图中低频能量发生变化,标记为音节的起始点。
3)检测到音节的起始点后,不再考虑U1 与U2,如果发现三条曲线中存在任意一条,其数据在6 帧之内相对下降值超过D1 或者在24 帧之内相对下降值超过D2,则表明该音节即将结束,此时再进行步骤2),但如果在两个起始点之间的帧数小于W1,则不进行标记,继续遍历。
4)重复2)、3)步骤,完成该曲线的语音音节切分。
切分结束之后,得到了低频部分能量变化的切分点,这些切分点大部分是不同元音段之间的分界点,小部分是元音段与辅音段之间的分界点。
“正”和“月”的基音周期轨迹相连,但在图4 中64~127 频带存在较为激烈的能量变化,所以能够被成功切分。在高频能量中无法检测的“春”字的辅音段,在低频部分存在较为缓慢的能量变化,所以也能够被成功切分。
将语谱图分析和基音周期轨迹分析的结果进行综合,就可以得到完整的音节切分结果。
4 实验结果与分析
4.1 实验数据
实验数据来自南京理工大学NJUST603 语音库,库中含有423 人录音,男生210 人,女生213人。录制内容为文章《师恩难忘》。录制时同时采用麦克风,固定电话和手机信道分别录音。
4.2 结果与分析
通过实验,我们可以得到端点检测算法与音节切分算法的准确率。
表1 为传统的双门限检测法与改进后的多阈值检测法在麦克风、固定电话和手机三种信道下的准确率对比。
表1 端点检测方法对比
实验结果显示,传统的双门限检测法非常容易受到噪声信号的干扰而降低端点检测的正确率。改进后的多阈值检测法效果更好,抗干扰性更出色,在固定电话以及手机信道下的正确率更高,鲁棒性更强。
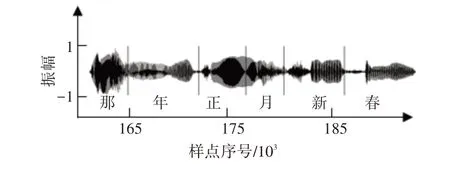
图5 “那年正月新春”的音节切分结果
将基音周期轨迹和语谱图综合分析得到的音节切分结果如图5,可见切分结果比较准确。
表2 为三种音节切分算法在麦克风环境下的准确率对比,可以看出本文研究的音节切分算法准确率更高。实验结果表明,在麦克风环境下,该算法的准确率较高,基本能实现汉语语音音节的自动切分。但在噪声信号较强的环境下,该算法的准确率仍有待提高,其根本原因在于,作为切分准则的语谱图能量曲线非常容易受到噪声的影响。

表2 多种音节切分算法对比
5 结语
在语音识别系统中,连续语音自动切分技术占据重要地位,该技术也一直是研究的难点之一[16]。本文研究的基于多阈值的端点检测技术,以及基于基音周期轨迹与语谱图的音节切分技术,经过大量数据测试,实验结果比较理想。在实际运用中,需要针对不同的环境,调整不同的阈值参数才能获得最佳实验结果。如何提取更有效的、抗噪性更强的语音特征参数,将是下一步工作研究的重点。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
考试与评价·七年级版(2020年6期)2020-11-02
语数外学习·高中版中旬(2020年8期)2020-09-10
兵器装备工程学报(2020年3期)2020-04-22
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
中学生数理化·教与学(2019年8期)2019-09-18
快乐作文(1.2年级)(2019年9期)2019-09-10
数学大王·中高年级(2018年7期)2018-08-29
作文周刊·小学一年级版(2018年32期)2018-01-15
