
具有通信约束的反馈辅助PD型量化迭代学习控制
2020-10-12 14:42周楠,王森,王晶,沈栋
控制理论与应用 2020年9期
周 楠,王 森,王 晶,沈 栋
(北京化工大学信息科学与技术学院,北京 100029)
1 引言
迭代学习控制是根据其环境获得知识或经验的过程,并参考知识或经验对环境采取行动,从而改善下一次的性能表现.1984年,日本学者Arimoto提出了迭代学习控制理论[1],自此便引起了人们的广泛研究.它是一种模仿人类学习能力的先进智能控制方式,具有严格的数学描述,适用于有限时间区间上重复运动的被控对象,最早起源于工业机器人控制问题[2–3].迭代学习控制需要较少的系统先验知识,方式简单,因此可用于具有不确定性、非线性和复杂性的系统[4],例如机器人系统、无缝钢管张减过程壁厚控制系统以及诸多工业过程控制系统[5].
为获得良好的控制性能,大多数有关迭代学习控制的研究,都依赖于对整个系统信息和运行数据的获取和利用,即假设学习算法所需数据的测量或传输,是以无限精度执行的.在实际情况下,通过共享通信网络来交换控制器和执行器、传感器之间信息的网络化控制系统已经成为国际自动控制领域的一个热点研究课题[6].在过去10年中,网络系统成功应用于控制、故障诊断、信号处理、信息融合等领域,已经有许多关于控制和稳定性问题的可用结果[7].对比传统的点对点控制模式,网络化控制系统具有易安装和易设置、少布线和低维护成本、可实现资源共享等优点.
随着通信,电子技术和计算机的快速发展与广泛应用,网络通信被引入计算机控制领域[8].在实际应用中,需考虑通信网络带来的影响.由通信约束导致不完备信息的因素很多,既有客观因素,也有主观因素.沈栋等将不完备信息场景分为两类[9]:被动不完备信息和主动不完备信息.被动不完备信息的迭代学习控制重点研究随机数据包丢失、通信延迟、容量限制以及迭代变长度,它们的信息丢失均是由实际条件和现场环境,或其他硬件限制(传感器/执行器饱和)造成[10].在研究数据包丢失时,有两种主要的迭代学习算法设计方案,一种是事件触发,另一种是迭代触发,不同之处在于学习更新时如何处理丢失的数据,对丢失数据进行充分补偿可以有效提高跟踪性能.因此,针对具体问题制定具体的补偿机制具有重要意义,但相关研究成果较少.在研究通信延迟时,用伯努利随机变量描述随机时滞,在收敛性分析中采用期望值消除随机性.迭代变长问题目前取得了一些进展,大多数文献考虑离散时间系统,系统被限制为线性或全局利普希茨非线性,基于平均算子的迭代学习控制器设计被广泛研究.在主动不完备信息场景下,考虑了两种降低数据量的措施,即采样数据迭代学习控制和量化迭代学习控制.与采样数据迭代学习控制相关联的主要问题有两个:采样瞬间的行为和采样间隔性能如何.具体来说,前者的目标是构造适当的学习算法以保证在采样时刻收敛,而后者则侧重于定量分析不同采样时刻之间的跟踪性能和可能的解决方案,以减少采样间隔内的跟踪误差.与传统的量化控制相比,量化迭代学习控制还处于初级阶段.由于网络的传输容量有限,被控对象与控制器之间的通讯能力往往有限,传输的数据应在发送到下一个网络节点之前进行量化[11–12].即把采样得到的信号进行幅度离散,可有效地降低传输数据量,从而满足系统的带宽要求,这是减少传输负担的必要条件,量化器为此提供了极大的优势[13].因此,研究其对控制性能的影响以及如何克服影响并提高系统的鲁棒性非常重要,但在迭代学习控制领域,基于数据量化、数据包丢失设计控制器以及相关跟踪性能的分析还处于起步阶段.
卜旭辉等[14]给出了量化迭代学习控制的早期尝试,输出测量值由对数量化器量化后,传输到控制器以更新控制律.通过使用扇形界和传统的压缩映射方法,表明跟踪误差收敛到一个小范围,其上限取决于量化密度.为实现零误差跟踪性能,沈栋等又提出量化跟踪误差的方法[15–16],使用P型迭代学习律可以保证零误差收敛.卜旭辉等人提出量化控制输入更新信号,采用二维模型理论给出了系统渐近稳定性条件[17].除此之外还扩展到了随机系统[18].在数据包丢失情况下,提出间歇性和连续性迭代学习律,如果未接收到信息,前者将停止控制律的更新,而后者将根据最新的可用信息继续进行更新[19].沈栋等[20]探讨了数据丢包迭代学习控制的通用情况,允许数据丢失在测量端和执行器端随机发生,提出了针对计算输入和实际输入的更新机制,并将这两个更新过程转化为马尔可夫链模型.上述方法仅借助前一批次的跟踪误差信息来修正当前批次控制信号,是典型的开环学习方式,但实际上还可以利用当前批次所获信息来构造学习算法,形成闭环学习过程.相较而言,闭环学习比开环学习修正及时,通过较少的迭代次数即可改善系统稳定性能.但由于因果性,无法准确获得当前误差的导数信号[21].
本文讨论迭代学习控制在网络环境中执行,且同时存在量化和数据包丢失的情况.方便起见,仅考虑输出测量端存在通信信道的情况.将数据包丢失描述为一个概率已知的伯努利序列,采用对数量化器,将量化的跟踪误差传送回控制器.基于反馈辅助PD型迭代学习律,利用前一批次和当前批次产生的跟踪误差信号来更新控制输入.当初始状态精确重置时,能保证零误差收敛,并加快系统的收敛速度.而对于初态偏移情况,则证明了跟踪误差与初始状态偏差的界成正比,且反馈辅助PD型迭代学习控制算法仍然保持稳健的性能,同时可以发现,较大的初始偏差会导致较大的跟踪误差范围.通过数值仿真,对比了反馈辅助PD型学习律与开环P型、PD型学习律的收敛性能,验证了所提学习算法的有效性及优越性.本文贡献如下:1)在具有通信约束的环境下,提出了反馈辅助PD型迭代学习控制律,采用压缩映射法分析证明了同时存在数据量化和数据包丢失时,所提控制算法依然可以保证跟踪误差渐近收敛到零;2)通过数值仿真对比反馈辅助PD型学习律与P型、PD型学习律的控制效果,验证了所提方法可以很好地提高学习过程的收敛速度;3)讨论了存在初态偏移时反馈辅助PD型迭代学习控制的理论分析与仿真结果.
2 问题提出
考虑如下离散线性时不变系统

其中:k=1,2,···表示迭代次数;t=0,1,···N表示在一次迭代过程中的不同时间;N是迭代长度;xk(t),uk(t),yk(t)分别是状态、输入和输出;A,B,C是适当维数的矩阵.本文虽考虑时不变系统,但下述结果可以平推至时变系统情形.假设CB是列满秩的.CB列满秩是迭代学习算法收敛的一个充分必要条件.为了判断在所提出的控制结构下是否存在收敛学习法则,仅需要检查输出输入耦合矩阵是否为列满秩.该假设的物理意义是系统的相对阶数为1,在实际中可以满足[22–24].
定义参考轨迹yd(t),t=0,1,···,N.
控制目标是找到一个输入序列{uk(t)},使得对于任意t当k →∞时,输出yk(t)收敛到yd(t).为了后续分析,需要如下假设条件.
假设1参考轨迹yd(t)可实现,即存在唯一的输入ud(t)使得
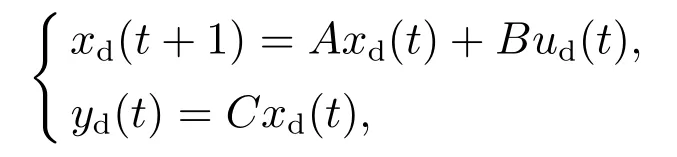
其中存在一个合适的初始状态xd(0).
假设2满足相同初始条件,即对于所有批次,xk(0)=xd(0),xd(0)是期望的初始状态.
假设3初始状态从xd(0)偏移,但应该是有界的,即‖xd(0)−xk(0)‖ε,其中ε是正常数.
在本文中,对于任何确定的跟踪轨迹,在操作之前首先传输到系统,产生跟踪误差,再将其量化和传输回控制器.在这个过程中,数据包丢失情况经常发生.假设控制器具有智能检测功能,它可以确定数据是否丢失[25].本文将讨论对于系统(1)和期望轨迹yd(t),在数据量化和随机数据包丢失的情况下,如何设计控制律使得系统的鲁棒性增强.
定义Q(·)为所选量化器.本文使用对数量化器[26].

其中µ是量化密度,相应的量化器Q(·)如下:
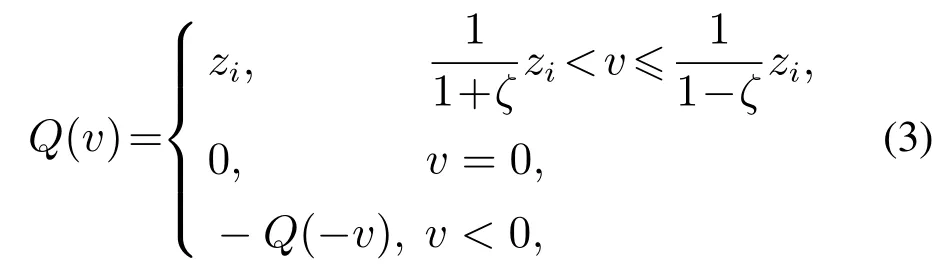
其中ζ=(1 −µ)/(1+µ).很明显量化器Q(·)对称且时不变.
对数量化器的量化误差满足下述扇形界性质[27]:

将数据包丢失模型描述为具有已知概率的伯努利二进制序列[28].定义随机参数αk(t)是0–1伯努利序列,即αk(t)∈{0,1}. αk(t)=0表示数据丢失,否则未丢失,且满足

现给出引理1用于之后的证明过程[29]:
引理1定义η为伯努利二进制随机变量,P{η=1}=,P{η=0}=1 −M是正定矩阵.那么当且仅当满足如下条件之一时,等式E‖I −ηM‖=‖I −M‖成立:

针对以上控制目标,本文利用前次迭代产生的输出信号ek(t)与ek(t+1)和当前次迭代产生的输出反馈信号,构成控制输入的修正项,从而提高学习过程的收敛速度,提出反馈辅助PD型量化迭代学习控制律
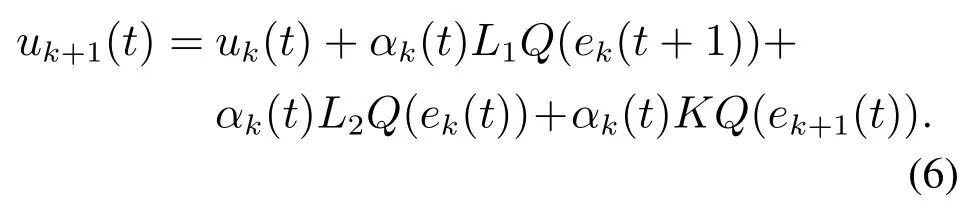
控制结构图如图1所示.

图1 反馈辅助PD型量化迭代学习控制系统结构图Fig.1 Structure of the feedback-assisted PD-type quantized iterative learning control system
如果控制器增益L2=0,K=0,则控制律为P型迭代学习律

如果控制器增益K=0,则控制律为PD型迭代学习律
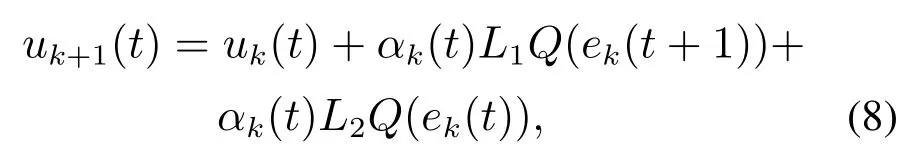
其中:ek(t)=yd(t)−yk(t)为跟踪误差信号,L1,L2,K为学习增益矩阵.
“村委会这儿一共安了几个喇叭?”“8个。”“都是哪些部门给安的?”“我也说不清,都是上面来人说安就安了。”
3 主要结论
在此节,如下定理刻画了算法(6)的收敛性质.
定理1考虑存在量化误差的系统(1)和更新律(6),假设1–2成立.如果增益矩阵L1满足那么随着k →∞,系统的跟踪误差收敛到零.
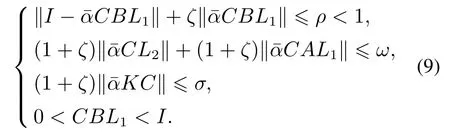
证记δuk(t)=ud(t)−uk(t), δxk(t)=xd(t)−xk(t).用ud(t)两边同时减去式(6),结合式(4),可以得到



注意到,Γ,L,H均为下三角矩阵,H对角线元素为I,Γ对角线元素为ρ<1.因此,当k →∞时,Vk→0,或者等价的,对于任意时间,k→∞,‖δuk(t)‖→0.由式(15)和时间的有限性可知,对于任意时间,k →∞, ‖δxk(t)‖→0,因此有k →∞,‖ek(t)‖→0.系统的零误差跟踪性能得证. 证毕.
推论1对于离散线性时不变系统(1),同时考虑数据量化与数据包丢失,采用P型学习律

假设1–2成立.如果增益矩阵L1满足
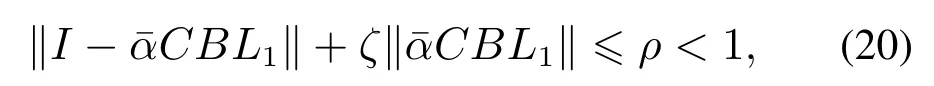
那么随着k →∞,系统的跟踪误差收敛到零.
推论2对于离散线性时不变系统(1),同时考虑数据量化与数据包丢失,采用PD型学习律

假设1–2成立.如果增益矩阵L1满足

那么随着k →∞,系统的跟踪误差收敛到零.
注1上述推论与定理1的证明过程类似,此处略.
定理2考虑存在量化误差的系统(1)和更新律(6),假设1和假设3成立.如果增益矩阵L1满足

那么当迭代次数k →∞时,跟踪误差收敛到小范围内,其界限与偏差ε成正比,即
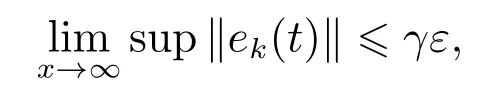
其中γ是一个适当的常数.
证该证明过程沿着定理1,式(10)–(14)的推导保持不变,但式(15)变化为



4 数值仿真
考虑如下线性系统:

期望参考轨迹
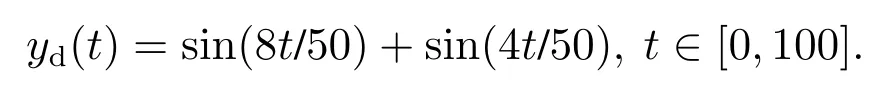
初始状态设定为对于所有k,xk(0)=xd(0)=0,初始输入选为u0(t)=0.给定量化器参数z0=2,µ=0.85,则ζ=0.08.分别选择学习增益L1=0.8,L2=0.3,K=0.2.该算法执行20次迭代,考虑系统在反馈辅助PD型学习律、PD型学习律、P型学习律下的收敛性能.考虑3种数据包丢失的情况:
情况1无数据包丢失,即=1;
情况210%的数据包丢失,即=0.9;
情况340%的数据包丢失,即=0.6.
具体仿真结果如下:
情况1无数据丢失情况下,图2(a)–2(c)分别描述在第2次、第3次、第5次、第20次迭代时,反馈辅助PD型学习律、PD型学习律、P型学习律的跟踪性能.图2(d)对比了不同学习律下系统沿迭代轴的跟踪误差.图2(e)–2(f)描述了第3和5次迭代时,3种学习律的跟踪效果.
可以看出,在无数据丢失情况下,反馈辅助PD型学习律、PD型学习律、P型学习律均可保证零误差收敛.但反馈辅助PD型学习律效果最好,在第3次迭代时几乎收敛到期望轨迹.
情况210%数据丢失情况下,图3(a)–3(c)分别描述在第2次、第3次、第5次、第20次迭代时,反馈辅助PD型学习律、PD型学习律、P型学习律的跟踪性能.图3(d)对比了不同学习律下系统沿迭代轴的跟踪误差.图3(e)–3(f)描述了第3和5次迭代时,3种学习律的跟踪效果.
可以看出,在10%数据丢失情况下,反馈辅助PD型学习律、PD型学习律、P型学习律均可保证零误差收敛.但反馈辅助PD型学习律效果最好、收敛速度最快.
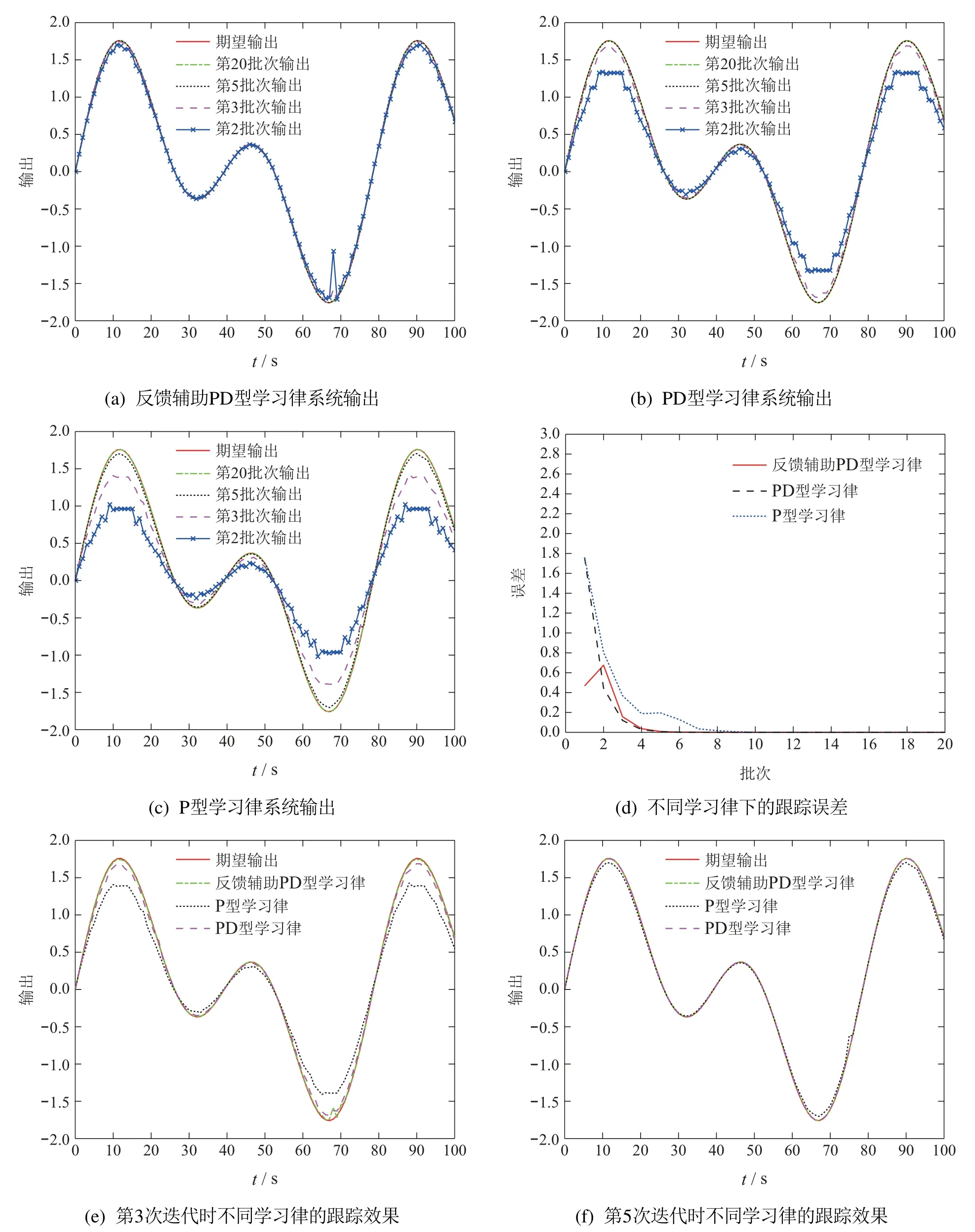
图2 无数据丢失情况下Fig.2 No data loss
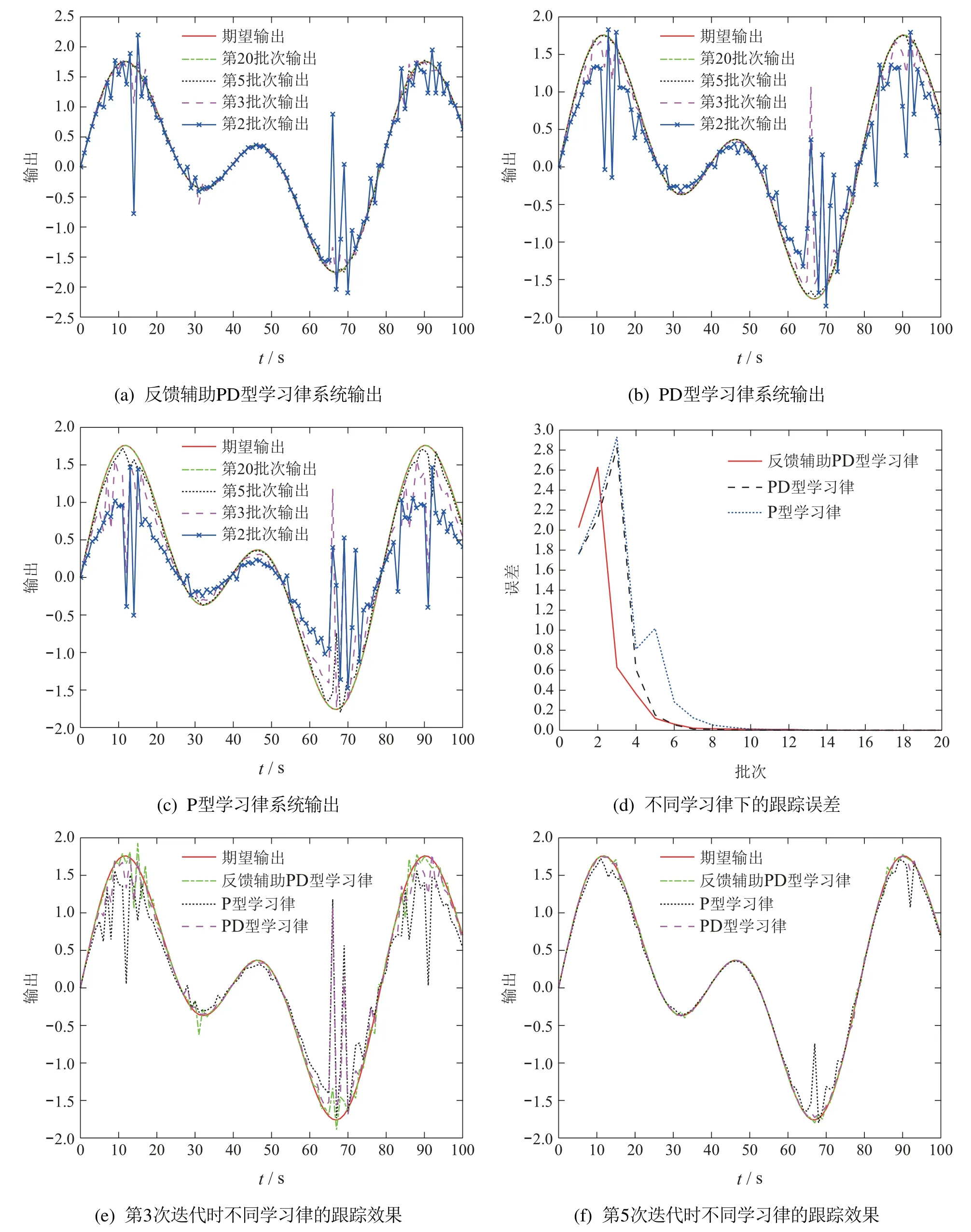
图3 10%数据丢失情况下Fig.3 10%data loss
情况340%数据丢失情况下,图4(a)–4(c)分别描述在第2次、第3次、第5次、第20次迭代时,反馈辅助PD型学习律、PD型学习律、P型学习律的跟踪性能.图4(d)对比了不同学习律下系统沿迭代轴的跟踪误差.图4(e)–4(f)描述了第5和20次迭代时,3种学习律的跟踪效果.
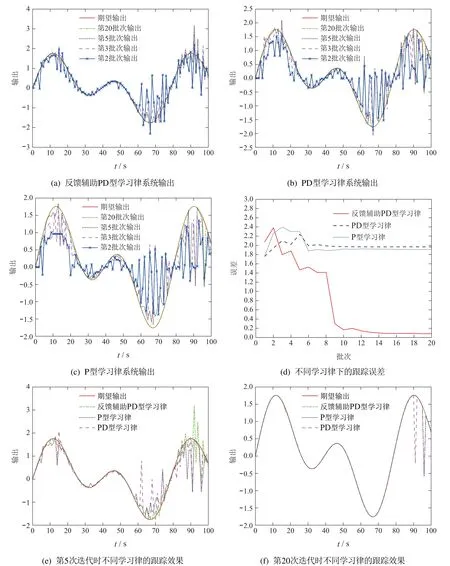
图4 40%数据丢失情况下Fig.4 40%data loss
可以看出,在40%数据丢失情况下,反馈辅助PD型学习律、PD型学习律、P型学习律均可保证零误差收敛.但反馈辅助PD型学习律效果最好,收敛速度最快.
数据包丢失的影响:图5(a)–5(f)分别在第3次迭代时,对比了0,10%,40%数据丢失情况下,反馈辅助PD型学习律、PD型学习律、P型学习律的跟踪性能.
可以看出,与情况1–2丢失0,10%数据相比,跟踪误差收敛速度变慢,这与数据丢失程度增加有关.但反馈辅助PD型迭代学习控制仍具有较好的收敛性能.
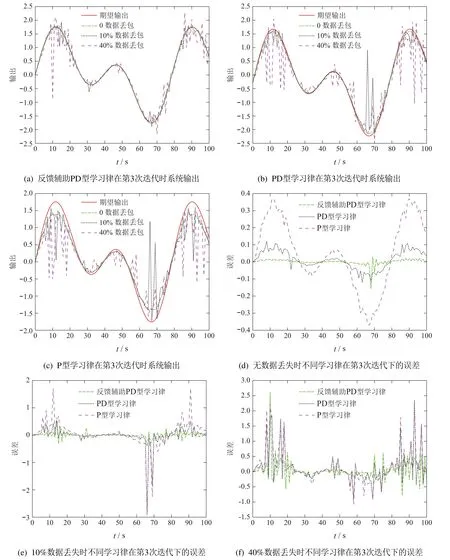
图5 数据包丢失对学习律的影响Fig.5 Impact of packet loss on learning law
初态偏移的影响:为了验证在不同初始状态下的收敛性,让初始状态在[−ε,ε]之间随机偏移,令ε=1,2.如下图所示,反馈辅助PD型迭代学习控制算法仍然保持稳健的性能,同时可以发现,较大的初始偏差会导致较大的跟踪误差范围.
情况1:分别令ε=1,2,10%的数据包丢失时,3种学习律的跟踪误差.
情况2:令ε=2

图6 初态偏差对学习律的影响Fig.6 Initial state shifts on learning law
1) 10%的数据包丢失时,在第3次迭代下,3种学习律的跟踪效果.
2) 第3次迭代时,3种学习律在无数据丢包、10%数据丢包、40%数据丢包下的跟踪效果.
5 结论
本文针对同时具有数据量化和数据包丢失的网络线性系统,设计反馈辅助PD型迭代学习控制算法.将数据包丢失描述为一个概率已知的伯努利过程,采用对数量化器,将量化的跟踪误差传送回控制器.利用前一批次和当前批次产生的跟踪误差信号来更新控制输入.当初始状态精确重置时,能保证零误差收敛,并加快系统的收敛速度.而对于初态偏移情况,则证明了跟踪误差与初始状态偏差的界成正比,且反馈辅助PD型迭代学习控制算法仍然保持稳健的性能,同时可以发现,较大的初始偏差会导致较大的跟踪误差范围.此外,反馈辅助PD型迭代学习控制引入了当前迭代次跟踪误差的反馈.客观上说,应该有助于提升控制器对非重复干扰等因素的鲁棒性.如何进一步从非重复干扰鲁棒性的角度分析反馈辅助PD型迭代学习算法的优势将是笔者未来工作的重点.
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
煤气与热力(2021年12期)2022-01-19
发明与创新(2021年39期)2021-11-05
民用飞机设计与研究(2020年4期)2021-01-21
电子制作(2019年13期)2020-01-14
物联网技术(2018年8期)2018-12-06
中学数学杂志(初中版)(2017年4期)2017-08-28
汽车文摘(2015年11期)2015-12-02
筑路机械与施工机械化(2014年4期)2014-03-01
汽车与新动力(2014年5期)2014-02-27
