
基于机器学习的网络舆情分析
2020-10-09 11:07盖赟宿培成
科技智囊 2020年9期
盖赟 宿培成


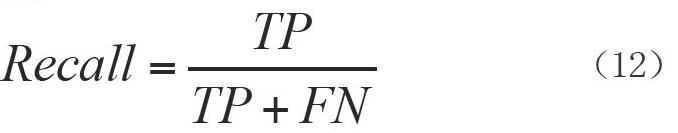
摘 要:在网络数据爆炸式增长的今天,使用机器学习技术进行数据分析和数据处理是当前研究和应用的重点关注领域。文章针对网络舆情分析问题,介绍使用机器学习分析网络舆情的方法和改进方式。通过计算文本中情感词的情感权重,提高机器学习模型的分析效率和分析准度。通过对酒店评论数据的验证,证明了文章提出的改进方法的有效性,进一步分析了机器学习方法的改进方向。
关键词:大数据;机器学习;深度学习;网络舆情;情感分析
中图分类号:GB251 文献标识码:A
DOI:10.19881/j.cnki.1006-3676.2020.09.12
Abstract:With the explosive growth of network data,the use of machine learning technology for data analysis and data processing is the focus of current research and application. Aiming at the problem of network public opinion analysis,this paper introduces the method of using machine learning method to analyze network public opinion and the improvement method. It improves the analysis efficiency and accuracy of machine learning model by calculating the emotional weight of sentiment words in text. Through the verification of hotel review data,it proves the effectiveness of the improved method proposed in this paper,and further analyzes the improvement direction of machine learning method.
Key words:Big Data;Machine Learning;Deep Learning;Network Public Opinion;Sentiment Analysis
一、引言
情感分析是舆情分析的重要研究领域之一,该研究是指使用计算机技术分析人们对主题、对象、产品、服务和事件的意见、态度、情绪。近年来,用于消费评论的情感分析研究得到了学者的广泛关注和深入研究,涉及的研究领域有数据挖掘、自然语言处理等。人们希望通过对该问题的研究能够发现潜在的消费者和商业模式。消费者在购买某一产品前,希望知道其他消费者对该产品的意见,并以此为基础做出是否购买的决定;而商家希望根据消费者的评价发现问题、找出解决方案,并对自身的产品或服务做出相应的调整。随着参与在线评论的消费者人数增加,想通过人工的方式全面掌握每个消费者对不同商品的态度和意见,已经成为一件不可能的事情。对现有商品评论进行有效的分析和总结,能够帮助商家尽早地发现潜在用户。不仅如此,通过计算评论中包含情感的正负极性,商家还可以获知用户对产品的使用感受。随着互联网技术的快速发展,人们在网络平台发表的评论數量快速增长,建立一个可以自动分析用户情感状态和产品观点的方法是十分必要的。
目前文本情感分析方法主要有两类:基于情感词典的方法和基于机器学习的方法[1]。基于情感词典的方法是首先构建一个包含情感词的情感词典,然后以这个词典为基础对评论文本进行情感分类[2]。部分学者认为,提高情感分类的准确性需要让情感词典包含尽可能多的情感词,并投入到情感词典分析法的改进工作当中[3-5]。近年来,Wu等[6]提出了基于数据驱动的情感词典构建方法,该方法使用改进的互信息统计信息来检测信息中的词,从而使得情感词典质量得到大幅提升,覆盖范围进一步扩大,并在实验当中取得较好的结果。但是此类方法仍旧在很大程度上受语料环境影响,当用于语料库中的文本包含的词汇过于关注某一主题或包含某个情感极性,那么该语料库对其他主题或其他极性的分析准确性就会大幅降低。因此,随着机器学习研究的推进,基于机器学习的方法进行文本情感分析是当前研究的主流方向。
近年来,机器学习方法在情感分析工作中起着非常重要的作用,并取得了迄今为止最好的分类效果。一部分机器学习方法通过大量训练神经网络来获得高质量的情感特征和良好的模型泛化能力。该方法的不足之处在于:训练前需要准备大量的已标记样本,其所需的实践和资源是惊人的。另外一部分机器学习方法建立在数学推论之上,如支撑向量机。前两类方法都需要人工设计目标特征,特征设计的准确性直接影响到模型训练的结果。长短时记忆网络和卷积神经网络是当前情感识别领域应用最为广泛、效果最好的方法。通常情况下,这些方法需要大量的数据作为训练基础,并且词嵌入向量的准确性也会影响模型训练的准确性。笔者首先采用TF-IDF方法计算情感词在句子中的权重,然后将权重值和原词向量进行加权,最后将加权的词向量投入到模型中进行训练,并得到最后的结果。
二、情感分析模型
笔者提出的情感分析模型首先使用TF-IDF方法得到情感词的权重,然后将权重值和词向量结果进行融合,并最终完成分析工作。
(一)TF-IDF
TF-TDF是一种统计方法,用于计算句子每个词语的重要性[7]。该方法认为:如果某个词语或短语在一篇文章中出现的频率较高,同时在其他文章中出现的频率较低,则认为该词语能够代表这篇文章,也就是这些词语具有较好的类别区分能力。TF-IDF中TF表示词频,是指一个词语在当前文章中出现的次数,这个数字通常会被归一化,以防止它偏向篇幅长的文档。同一个词语在长文档中出现的次数可能比短文档中更多,但它不是该长文档中的重要词汇。IDF表示逆向文件频率。在有些情况下,一些通用的词语对于主题的表达没有太大的作用,而一些出现频率较少的词语更能够表达文档的主题,所以有些学者对单纯使用词频来分析词语的重要性持反对观点。他们认为,越能反映主题词语,权重应该越大,反之权重应该越小。如果一个词在属于某个主题的文档中出现的次数越多,则认为它对该主题的表达就越重要,这个词的权重应该设计较大。
逆向文件频率(inverse document frequency,IDF)的主要思想是:如果一个词被包含的文档数量越小,则该词的文本分类能力就越强,那么IDF值也就越大。它的计算方式为文档总数除以包含该词的文档数,再对此结果取对数就可以得到IDF值。
基于随着词w在当前文档中的词频和该词在文档集中出现的文档次数即可以得到该词的TF-IDF值,常见的计算公式为:
(二)词向量
使用计算机进行情感分析需要首先将文本信息转换为计算机可以识别的形式,然后再基于数字化后的结果进行相应的分析和处理。早期词向量采用的方法是词袋模型。词袋模型首先从输入文档集中提取所有的词,然后基于这些词构建一个集合,并按照一定的规则对这些词进行排序和编码,最后以建立好的词集合为基础对输入的文档进行编码。词袋模型不能体现出词在句子中的先后顺序,只能体现出它们在词典中的编码,所以词袋模型在表达文档语义方面存在不足。
Word2Vec是一种可以体现词语相关性的词向量模型,它被广泛地应用于词向量工作当中。Word2Vec主要有两种实现模型:CBOW和Skip-Gram。CBOW模型是通过周围的词来预测中间的词是什么的模型。训练时通过不断调整周围词的词向量完成模型的训练。训练完成后,周围词的词向量形态就是文本里所有词的词向量的最终表示形式。Skip-Gram模型是根据中心词来预测周围词的模型。训练时通过不断调整中心词的词向量来完成模型的训练。当词集数量比较少时或生僻词出现次数较少时,使用Skip-Gram模型获取的词向量更加准确。因此Skip-Gram是目前采用频率最高的模型。Skip-Gram建模过程和自编码器的思想很相似,即先基于训练数据构建一个神经网络。当这个模型训练好之后,就可以使用该模型获取输入数据对应的隐藏层状态。所以,训练模型的真正目的是获取模型的隐藏层权重。
(三)LSTM分析模型
长短时记忆网络(Long Short Term,LSTM)是循环卷积神经网络的一种变体,该模型通过特殊的设置避免了RNN网络长时依赖的问题[8]。它通过一种叫门的机制实现短时记忆和长时记忆的结合,这在一定程度上缓解了梯度消失的问题。
简单来说,RNN网络是卷積神经网络的一种循环模式。在这种模式的约束下,卷积神经网络的输出被再一次投入到网络的输入流中。这就涉及一个问题:如何处理新的输入信息和已有输出之间的关系。目前比较通用的做法是设计一个选择机制,让新输入和旧输出在概率选择的机制下进行融合,并形成最终的输入。标准RNN网络采用的融合方法是tanh层,LSTM的信息融合结构和tanh结构类似,不同之处在于它拥有四个融合结构。LSTM通过三个门来实现信息的保存和传输,它们分别是忘记门、输入门和输出门。每个门都是由一个Sigmoid函数和一个点乘操作组成。Sigmoid层输出为0到1之间的数值,0代表任何量通过,1代表允许任意量通过。下图是标准的LSTM结构模型。
LSTM的第一步是决定哪些信息需要被丢掉,完成这个工作的结构被称为忘记门。隐藏层的前一状态和当前输入被送入忘记门,该门的输出结果是0~1之间的数值向量,向量中元素为0的位置对应信息被删除,元素为1的对应位置被删除。忘记门的公式为:
LSTM的第二步决定什么样的新信息被存储在隐藏层的单元中,完成这个工作的结构被称为输入门。这一结构由两部分组成:输入层和更新层。输入层使用Sigmoid层决定哪些值将会被更新,然后更新层使用tanh层创建一个新的候选值向量。
LSTM的第三步是更新隐藏层的单元状态信息,完成这个工作的结构被称为输出门。输出门将根据隐藏层前一状态和候选状态得出隐藏层的最新状态,计算的方式一般采用加权求和。
最终网络将根据最新的隐藏层状态得到最新的网络输出。更新完隐藏层状态后需要根据输入的和来判断输出哪些隐藏层单元,然后将输出的单元经过tanh处理得到一个-1~1之间的值向量。将该向量与输出门得到的判断条件相乘就得到了模型的最终输出。
(四)融合方法
不同的词在不同类别的文档中具有不同的影响作用,经典的Word2Vec方法只是根据词语之间的相关性来得到词向量的结果,并不能体现出词语在句子中的影响作用。如果根据每个词对文档情感的代表性进行加权,可以增加情感分析模型对重点词语的感知能力。笔者基于TF-IDF方法为每一个词向量计算对应的权重因子。标准的TF-IDF可以计算出每个词在文档中的权重,但是无法体现出该词在不同类别文档的概率分布。为了能够计算出词语在不同类别文档中的权重,笔者使用以下公式计算每个词语的情感权重值:
其中表示情感类别的数量,表示分词在类文档出现的频率。在得到分词的情感权重后,将其和值相乘,得到融合情感类别信息的分词权重值,计算方法如下所示:
在词向量和分词权重融合阶段,笔者同样采用简单加权的方式进行计算,即将每个分词的词向量和它的值相乘得到加权后的词向量,计算方法如下所示:
其中表示加权后的词向量,表示加权前的词向量。
BILSTM是对LSTM模型的一种改进,通过双向使用循环机制来发现网络当前状态与前驱输入和后继输入直接的关联性,捕获当前词与上下文之间的关联性。使用加权后的词向量进行模型训练,可以让模型更加关注权重大的向量,但是这种方式需要模型对文本中所有的词进行训练。为了进一步凸显权重词的重要性,挑选高权重值的分词进行文本分类研究是常用的研究思路。目前常用的挑选方法是选择前10个权重高的词进行模型训练,这前10个词的选择标准是通过实验确定的。
三、实验和评价
(一)实验设计
笔者选择哈尔滨工业大学谭松波教授建立的数据集:带标记的酒店评论数据。该数据集由10000条评论组成,为了研究方便,数据被分为四个语料子集:三个平衡子集和一个非平衡子集。ChnSenticop数据集结构如表1所示。
在進行计算之前,需要先将评论文本进行数据预处理操作,这些操作包括:异常符号清除、重复数据消除和停用词去除。经过处理后的数据将最大限度地保留有用信息并使用笔者提出的加权方法进行情感权重计算。在短文本情感评论中,用于表达特别情感或主题的词语是由一些特定的词语体现的。所以,在情感分类研究中,所需要的词汇应该只局限于文本中的词的一个子集。通过一定的方式获取这个子集,并以此为基础增加模型预测的准确性。基于能量原理,按照TF-IDF值从大到小的顺序选择文本中的代表性情感词,当所选单子的权重值大于总权重值的百分之八十时即停止采集,此时的情感词集即为文档情感特征。
(二)评价指标
为了验证笔者提出算法的有效性,采用Precision、Recall、F1-Score三种指标实验结果进行验证。Precision是针对预测结果而言的,它表示预测为正的样本有多少是真正的正例样本。令TP表示将正例样本预测为正的数量,FP表示将负例样本预测为正的数量。
召回率是针对训练样本而言的,它表示训练样本中有多少正例样本得到了正确的预测。这就说明训练集中的正例样本可能有两种预测结果:一种是把正例样本预测为正,表示为TP;一种是把原来的正例样本预测为负,表示FN。
这两个指标的差别仅在于分母不同,前者表示预测结果为正的样本总数,后者表示输入样本中正例样本的数量。Precision和Recall其实是相互矛盾的,在不同的应用场景下,它们的关注点是不同的。F1-Score是对二者的一种综合,该方式对类别数量不均衡的样本集具有比较好的评价。
(三)评价结果
为了验证算法的有效性,笔者选择了五种词向量和LSTM相结合的方法,进行复杂度和准确率的比较分析。这几种方法都是用Word2vec对输入文本进行了词向量计算。因此,对比模型可以划分成4种不同的情况。从表2可以看出笔者提出的方法能够有效地区分准确率。
四、总结
笔者介绍了一种融合情感权重的机器学习网络文本情感分析方法,该方法以TF-IDF为基础对文本向量化的结果进行加权。通过加权系数将原本地位相同的分词赋予了不同的权重,从而实现了情感类别和关键词之间的关联。这样分类模型在学习时可以有效地感知到不同词的类别判断的重要性,并在网络隐藏层的状态中有所体现,从而实现情感分类准确率的提高。TF-IDF是目前常用的词语重要性的统计方法,但是该方法过于单一,在某些特定的语境下并不准确。所以笔者介绍的情感权重计算方法是在TF-IDF之上设计的权重算子和加权方法。机器学习方法是目前情感分析的主要研究路线,但是它在数据准备和模型训练方面仍旧面临巨大的挑战,如何优化网络模型和提高输入数据的准确性是当前研究的主要目标。
参考文献:
[1] Khan F H,Qamar U,Bashir S. eSAP:A decision support framework for enhanced sentiment analysis and polarity classification[J]. Information Sciences,2016(07):862-873.
[2] Medhat W,Hassan A,Korashy H. Sentiment analysis algorithms and applications:A survey[J]. Ain Shams Engineering Journal,2014(05):1093-1113.
[3] Miller G A,Beckwith R,Fellbaum C,et al. Introduction to wordnet:An on-line lexical database[J]. International Journal of Lexicography,1990(04):235-244.
[4] Strapparava C,Valitutti A. WordNet-Affect:an affective extension of WordNet[C]//Proceedings of the Fourth International Conference on Language Resources and Evaluation.Lisbon:ELRA,2004:1083-1086.
[5] Cho H,Kim S,Lee J. Data-driven integration of multiple sentiment dictionaries for lexicon-based sentiment classification of product reviews[J]. Knowledge Based Systems,2014(11):61-71.
[6] Wu F,Huang Y,Song Y,et al. Towards building a high-quality microblog-specific Chinese sentiment lexicon[J]. Decision Support Systems,2016(07):39-49.
[7] Salton G,Buckley C. Improving retrieval performance by relevance feedback[J]. Journal of the American Society for Information Science, 1990(04):288-297.
[8] Gers F A,Schmidhuber J,Cummins F. Learning to Forget:Continual Prediction with LSTM[J].Neural Computation,2000(10):2451-2471.
猜你喜欢
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
时代金融(2016年27期)2016-11-25
中国市场(2016年38期)2016-11-15
科教导刊(2016年26期)2016-11-15
经营者(2016年12期)2016-10-21
今传媒(2016年9期)2016-10-15
科学与财富(2016年28期)2016-10-14
企业导报(2016年13期)2016-07-19
