
公路隧道视频预处理和病害识别算法
2020-10-09 08:05胡珉周显威高新闻
华侨大学学报(自然科学版) 2020年5期
胡珉,周显威,高新闻
(1. 上海大学 悉尼工商学院,上海 201800;2. 上海大学 上海城建集团建筑产业化研究中心,上海 200072;3. 上海大学 机电工程与自动化学院,上海 200444)
目前,公路隧道的病害检测主要依赖人工巡检,这种检测方式耗时、耗力、低效,而且恶劣的巡检环境增加巡检难度[1-2],存在遗漏病害的情况[3-11].用自动化的巡检设备代替人工采集病害,结合图像处理方法识别病害是目前的主要研究方向[12-23],但基于图像的检测需要对图像进行合适的预处理.在基于图像处理的病害检测方法中,目前效果最好的是基于深度神经网络的方法,为了能够精确计算病害严重程度,主要使用全卷积网络(FCN)[24]对图像进行语义分割[23].FCN能够对每个像素点进行分类.在病害检测研究中,FCN存在两个问题:1) 结果不够精细[25],处理结果过于模糊,对细节不敏感;2) 没有考虑像素之间的关系,忽略了空间规整的步骤[26].问题1)主要通过多重上采样解决[24],问题2)可以结合随机场改善[25-26].
针对上述问题,本文设计合理的图像预处理方法,建立基于FCN的病害识别模型.结合FCN模型与马尔可夫随机场(MRF),完善FCN的空间规整的步骤.
1 基于MRF-FCN的病害检测方法
1.1 病害检测流程

图1 病害检测流程Fig.1 Defect detection procedure
隧道病害检测主要是从图像中获取特征,再通过模式识别的方法判断是否存在病害.在病害检测的方法中,深度神经网络能够全面提取图像特征,又能够快速进行模式识别,因此,使用深度学习方法作为病害检测的主要模型.考虑到在数据采集的过程中,数据的采集方式、采样频率及噪声干扰会影响数据质量,需要在病害检测之前先对数据进行预处理.
病害检测的整体流程,如图1所示.深度学习病害检测模型的设计考虑到模型需要进行训练,因此,应用的过程可以分为模型训练和模型应用.由于数据采集过程中存在问题,首先,需要根据采集数据的特点,对图像进行一系列数据预处理,构建隧道病害数据并进行标记;然后,再训练病害检测模型.由于初始采集的病害数量较少,故使用数据增强技术扩充数据集,获得足够的数据用于模型训练.模型应用处理日常巡检中产生的数据,完成数据预处理,接下来直接进行病害检测.由于无需对模型参数进行优化,没有数据增强的步骤.

图2 数据预处理流程Fig.2 Data preprocess procedure
在数据预处理过程中,由于所采集的视频图像存在数据冗余、镜头畸变、噪声等问题,需要进行适当的预处理后才能应用.考虑到冗余数据的存在,若先进行畸变矫正则会导致预处理时间增加.而先截取关键帧不仅能够大幅提高预处理效率,还能在截取关键帧的步骤同时先消除噪声,防止噪声对后续步骤的影响.因此,将视频数据的预处理分为4个步骤:采集数据、关键帧截取、畸变校正和数据增强.数据预处理流程,如图2所示.图2中:数据增强步骤仅用于训练数据集的扩充,而在模型的实际使用中不存在此步骤.
1.2 数据预处理
1.2.1 采集数据 借助自主研发的巡检机器采集的视频数据来自上海市大连路隧道,适用于自动化的采集模式,在数据采集的过程中,为了获取完整的图像信息,往往采用视频录制的方式.另外,从数据特征的角度,视频相当于图像数据的特征增加了时间步长,获取时间维度的数据可以更好地应用于离线定位,更加符合工业应用的需要.
视频的录制是以视频帧的方式记录信息,视频的录制帧率一般是24帧·s-1,有巨大信息冗余.为了提高检测效率,避免重复的数据处理,需要从视频中截取特定位置的图像,将其作为检测模型的输入图像,也就是关键帧.关键帧并非指含有病害的帧,而是从视频中挑选特定位置的帧,关键帧之间应当在地理上近似等距,这样既减少了不必要的数据处理,又利于确定病害的空间位置,其作为病害的定位依据,满足了工程需求.
1.2.2 关键帧截取 视频关键帧截取是为了从视频中提取重要信息,排除冗余数据.目前广泛使用的关键帧提取算法主要是基于信息熵[27]和图像熵[28]分类方法,这些方法将关键帧视为异常,计算不同镜头的信息熵,结合静态的局部处理,以异常检测的方式区分冗余帧和关键帧.基于复杂特征和信息熵的方法需要进行大量的图像比对和特征距离计算,处理效率不高,因而在实际应用中,需要结合应用场景,选择显著的、高效的特征提取方法和特征距离计算方法.
由于隧道由环组成,环面在视频中宽度一致,排列有序,因此,每个环面是最合适的关键帧,可以将环面边缘作为识别的特征,通过对比不同图像中的边缘特征,计算特征距离以判断是否存在病害.由于Canny算子在边缘检测中检测效率高、效果好且应用广泛[29],因此,文中使用Canny算子作为环面边缘特征提取的模板.该方法仅适用于边缘特征明显的关键帧截取,但处理效率和效果较好,对于应用场景是最合适的方法.关键帧截取有以下3个步骤.
步骤1选择标准图作为关键帧的模板,将标准图中的环面边缘特征作为匹配关键帧的依据,因此,需要从视频帧中选择一组包含完整且不重复环面的图像作为标准图.标准图符合以下特点:1) 同一环的4个边缘线均完整地显示在图像中;2) 环面边缘的中心位于或者邻近图像的中心点;3) 边缘线没有病害和干扰物,环面几乎没有病害和干扰物.
步骤2提取特征点集.灰度化标准图后使用Canny滤波提取环面特征点集P,用T表示特征点总数.将特征点的灰度值Gn,n∈[1,T]按位置顺序排列,形成新的特征点集P′,并记录每个点的位置坐标Ln=(Xn,Yn),n∈[1,T].

(1)
1.2.3 畸变矫正 通过相机拍摄所采集的数据会产生光学畸变,广角镜头的畸变尤其严重,但许多研究中往往会忽略畸变问题的处理.镜头畸变一般分为径向畸变和棱镜畸变,针对所使用相机的特点,采用实际应用广泛的多项式法.镜头畸变校正使用了r=0处的泰勒展开的前几项描述径向畸变,由于研究中需要校正的图片分辨率较大,因而采用了更为完整的多项式,对径向畸变进行详细描述,即
(3)
式(3)中:xdis和ydis是径向畸变点在原图上的位置坐标;xc和yc是该畸变点经过校正后坐标位置;k1~k6为径向畸变系数;r为透镜半径.切向畸变为
(4)
畸变参数模型需要考虑径向畸变和切向畸变,结合相机的小孔成像模型,以反向投影的角度反向思考,从畸变后的坐标点反推出未发生畸变的坐标点,畸变校正的模型描述为
(5)
式(5)中:k1~k6为径向畸变参数;p1,p2为切向畸变参数;xdis和ydis是畸变点在原图上的位置坐标(世界坐标系);x,y为相机坐标系的坐标;z为拍摄距离;R为旋转矩阵;xc和yc是该畸变点经过校正后的实际坐标位置(图像坐标系);u,v分别像素点在像素坐标系下的坐标;u0,v0为图像的原点坐标;f为相机焦距;dx,dy为每个像素在图像坐标系横、纵方向的尺寸.
将标准标定模板(棋盘格)作为参照物,使用需要标定的相机拍摄模板.通过Harris角点识别获取拍摄前后图像的网格角点,计算网格点的坐标差,选择特定的控制点,解出式(5)中的畸变参数,就可以明确畸变的变化关系.
标准的图像中某一点坐标(X,Y),且X,Y均为整数,但畸变后,在畸变图像上的位置基本上不是整数,所以需要用双线性内插法进行插值处理.设点p(i+u,j+v)为畸变前图像中落在畸变图像上的点,且该点不在畸变图坐标上,使用相邻4个畸变坐标点P(i,j),P(i+1,j),P(i,j+1),P(i+1,j+1)进行双线性内插值法计算,即
1.2.4 数据增强 对于深度学习神经网络而言,数据量不足、类别不均衡会导致训练不够充分,容易产生过拟合现象.而在隧道病害识别的研究领域,深度学习的应用处于起步阶段,没有合适的数据集可用于训练和测试,因此,在数据预处理之后,使用数据增强方法增加数据量.
一般来说,常用的用于增大图像数据集的方法有保留标记变换图像,变换包括以下5个方式:
1) 改变图像亮度、饱和度、对比度;
2) 随机重构目标大小;
3) 随机裁剪、拉伸、切片;
4) 旋转、翻折、仿射变换;
5) 随机噪声、模糊和扭曲.
通过两步变换操作实现数据增强,首先,将畸变矫正后的图像添加随机的像素点扰动,其次,将原本1 920 px×1 080 px的图像随机裁剪成224 px×224 px大小,随机翻折图像(上下、左右或镜像翻折随机进行),随机组合,形成新的1 920 px×1 080 px的图像.通过监督,随机生成原始数据量19倍的新图像,总数据量扩充为原来的20倍.
至此,数据预处理及数据集的构建完成.由于深度学习模型依赖训练样本的数量,所以仅对常见的裂缝、渗漏水和破损3种病害进行目标检测.排除其他病害,不同病害类别以3∶1随机抽取,构建模型的训练集和验证集.
1.3 MRF-FCN模型的构建
1.3.1 基础模型 对于隧道病害检测而言,从图像级别的分类细化到像素级别的分类,使病害危险程度可以定量计算和评估.若使用目标检测的神经网络模型,仅能够判断病害的位置,无法进一步计算其严重程度(面积、宽度等).在现有的病害检测研究中,薛亚东等[30]改进了GoogLeNet,并用于隧道内渗漏水、裂缝、拼缝、管线图片的分类,相对于一般目标检测模型效果更好.目标检测的方法能够找到病害,判断病害类别,但是在实际应用中,还需要计算病害的严重程度,例如,裂缝的长度、宽度、渗漏水和破损的面积等,所以需要将检测的精度细化到像素级别,从而进行图像语义分割.
在现有的语义分割模型中,FCN应用于诸多领域中,并取得了显著的研究成果.FCN是卷积神经网络中的一种,能够对每个像素点都进行预测,可以实现图像像素点对点的分类[24].因此,选用FCN作为基础模型.全卷积网络架构图,如图3所示.
全卷积神经网络对图像进行语义分割,需要对图像上的各个像素进行分类,上采样过程是将最后输出的热力图上采样到原图.上采样类似卷积,在卷积之前,将输入特征插值到更大的特征图,然后,进行卷积.一般采用双线性插值填充特征图,这一操作丢失部分信息.根据FCN模型结构计算,经过5次卷积和池化,图像的分辨率依次缩小了2,4,8,16和32倍.因此,32倍上采样丢失了大量细节信息.Long等[24]将第4次和第3次卷积分别进行16倍和8倍上采样,可以保留更多细节信息.将底层结果进行2倍上采样,结果与第4层结果相加并进行预测,得到FCN-16s,以此类推,得到更加精细的FCN-8s.
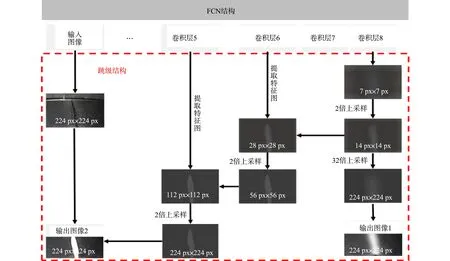
图3 全卷积网络架构图Fig.3 Structure of FCN network
1.3.2 MRF增强空间一致性 FCN模型存在着空间不一致的问题,端对端的计算方式忽视了像素点之间的关联.由于隧道病害和干扰物均具有连通性,其像素点之间可以通过领域相关算法构建关联.将像素点视作节点,引入MRF概念可以更好地反映像素点之间的邻域关系.对于病害检测而言,裂缝、渗漏水和破损3种常见病害均具有连通性,结合MRF的图像分割,对病害区域中的个别错误分类有抑制的作用.
MRF也被称为马尔科夫网络或者无向图模型,在图像处理中,往往使用MRF表示图像像素之间的关联,将图像中的每个像素作为马尔可夫随机场的节点,每个节点之间都存在相互的连接(Edges),而且这种连接是无向的.特别地,对于马尔可夫随机场而言,每个像素的分类结果仅与相邻像素的类别相关,而与图像中的其他像素的分类是条件独立的.MRF通过势函数反映节点之间的关系,也就是研究中需要使用的损失函数,即
(7)
一元势函数仅仅反映了单个像素的分类概率,在实际应用中,病害具有连通性,因此,可以看作是连通区域内的其他像素影响某一像素分类的结果.在势函数中需要添加二元势函数,即
(8)
用来反映该像素点与连通区域内其他像素之间的连接关系.
二元势函数示意图.如图4所示.图4中:K为图像中所有连通区域的集合,且连通区域内所有像素分类均不是背景;μk(i,u,j,v)表示第k个连通区域内,像素i被分为病害类别u,同时,像素j被分为病害类别v的联合概率;d(i,j)表示像素i与j之间的几何距离.二元势函数通过连通区域内像素点的连接关系(分类的联合概率和像素的几何距离),表现像素之间的关联性.
一元势函数和二元势函数组成了MRF方法,而MRF势函数包含了FCN模型的损失函数,作为单个像素的分类结果,另外还增加了二元势函数反映像素之间的关联.所以使用MRF方法和FCN模型结合的方式就是扩展FCN模型的损失函数.增加二元势函数损失LPai作为额外的优化目标,形成联合损失函数Ltotal,即
Ltotal=LFCN+LPai.
(9)
MRF优化流程,如图5所示.
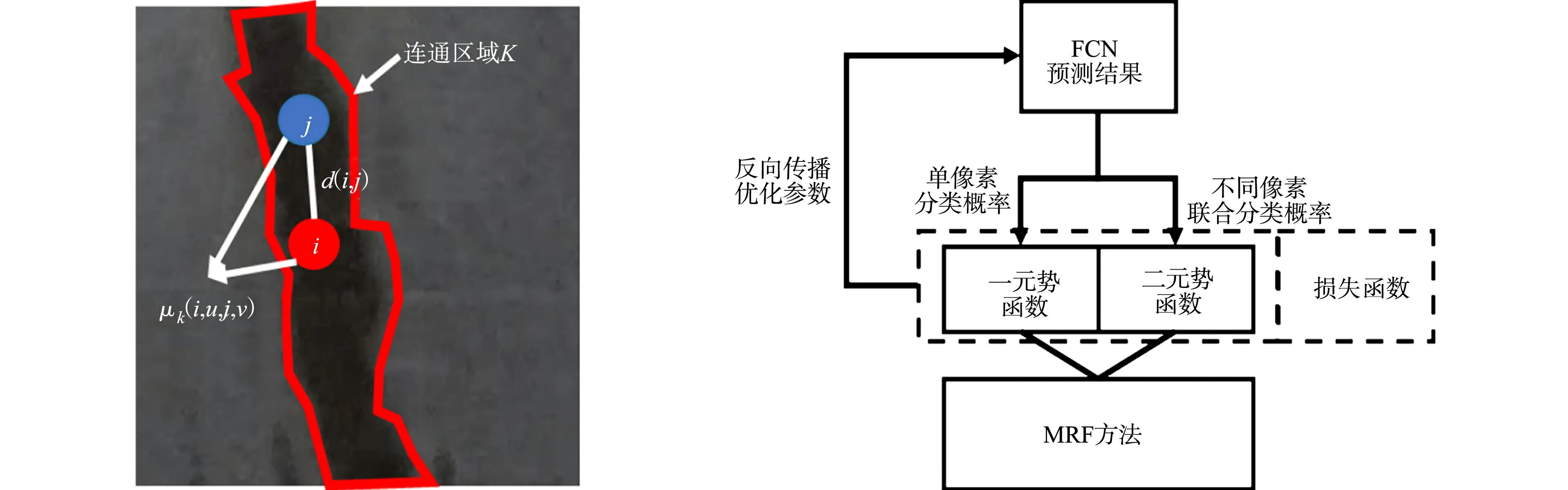
图4 二元势函数示意图 图5 MRF优化流程 Fig.4 Schematic diagram of binary energy function Fig.5 Process of MRF optimization
2 结果与应用
2.1 数据获取与模型训练

图6 MRF-FCN模型迭代损失图Fig.6 Loss of MRF-FCN model iterations
用于训练模型的病害图像来自于上海市大连路隧道,使用自主研发的自动巡检设备机器人采集视频数据.研究所使用的计算机配置为:Inter core i7-8750H @2.2 GHz,内存8 GB×2,显卡为GeForce GTX1070 8 GB.由于自动巡检设备分别对环面、顶部和侧墙3个方向同时采集视频数据,且每个方向的信息无重叠、背景不一样,主要干扰物也不同,但病害特征基本一致.因此,所使用的实验数据将分为3个数据集.模型训练的过程中,将从3个数据集等比例随机抽取图像训练,防止模型过拟合.对3个数据集进行模型验证,并且将验证的结果与常见检测算法进行对比.
通过采集共获取3个采集方向等比例的4 200余张图像,通过数据增强使得数据集扩大到20倍.因此,数据集共有约84 000张的图像可用于训练.实验将从增强数据中随机抽取67 200张图像进行训练,抽取16 800张图像用于测试.MRF-FCN模型迭代损失图,如图6所示.图6中:n为迭代次数.由图6可知:经过了3 000次迭代训练,损失函数趋于收敛,结束模型的训练.
2.2 结果分析
为了检验所提出算法的鲁棒性,将处理后的结果与其他算法的结果进行对比.准确率(P)常常作为目标识别算法的评价指标,可以有效直观地反映出检测算法的准确性,即
(10)


表1 实验结果Tab.1 Experiment results (%)
由表1可知:文中方法的平均准确率略高于FCN模型,比传统方法(大律分割法和区域增长法)要高出许多,且更为稳定,相比较而言,对于不同背景的数据集传统方法稳定性不佳.
不同病害检测算法的语义分割结果,如表2所示.

表2 不同病害检测算法的语义分割结果Tab.2 Semantic segmentation results of different defect detection algorithms

续表Continue table
由表2可知:FCN模型在未经过MRF的优化时,对于病害的错误分类较多,存在较多离散的病害像素,而MRF-FCN则较好地优化了检测结果,对于同一病害连通区域内的点进行了分类结果的优化,减少了连通区域内的误分类,同时,去除了背景区域中的离散点,MRF-FCN的检测准确度显著提升;大律分割法和分水岭法两种方法对于图像中的反光部分过于敏感,导致算法忽视了病害的信息,其中,大律法能有效获取细微的病害边缘信息,适用于细小病害以及零散病害的检测,但边缘信息粗糙,零散的误诊点也较多.分水岭法对于较大的病害识别更加精细,对于病害边缘预测更加平滑,但会忽视较小的病害信息.
2.3 实际应用
文中方法已经在上海市虹梅南路隧道中进行应用,共执行18次巡检任务.根据实际需求开发隧道运维系统界面,如图7所示.使用文中方法从视频中获取病害信息,并对检测结果进行汇总与分析,判断每个病害的严重程度,以及结构段(50 m)的病害健康状况,以报告的形式为隧道运维和维修提供科学的建议.

图7 隧道运维系统界面Fig.7 Interface of tunnel operation and maintenance system
通过应用文中方法,隧道病害检测的效率和准确率具有明显的提升,日常巡检的耗时从约2 h(2 km)降低至1.5 h(2 km),定期巡检频率也从一个月1次变为一周2次.另外,与人工检测相比,应用文中方法大幅度减少了病害的漏检率,达到0.1% .病害识别的准确度约为92.0%,非常接近人工判断的准确率.另外,在检测中发现了两处尚未修理的严重病害,及时提醒运维公司进行维修,防止进一步恶化.检测结果均通过人工复检的方式加以验证,并用复检结果再次训练检测模型,不断提高检测准确度.经过多次再训练和应用,漏检率为0.05%,错检率为4.50%.
3 结论
在隧道内部环面上采集视频数据,首先,从视频数据中截取信息完全且不重复的环面图像,然后,对每个截取出来的图像去除广角畸变.对每张图像进行随机小幅修改,以实现数据增强.通过处理好的图像进行标记工作,构建了病害图像数据集.使用多种上采样结合推理的跳级策略,引入马尔科夫随机场弥补了FCN模型空间一致性的缺失,构建了MRF-FCN病害识别模型.使用预先准备好的数据集训练改进的MRF-FCN模型,并取得部分数据测试模型的性能,模型的平均准确率为92.8%.
文中方法在上海市虹梅南路隧道中进行了应用,结果通过隧道运维公司的复检进行验证,开展了维修工作并给予反馈,最后,反向更新数据集,形成了完整的闭环管理.
但是基于机器学习的隧道病害检测还处于实验阶段,鲜有能够适用于实际应用.主要困难在于:1) 可供用于训练的病害图像数量较少且类别不均衡;2) 训练出的模型有特殊性,难以应用于结构有差异的隧道;3) 干扰物数目较多且会与病害交叠共存.针对以上问题还需要进一步研究,才能使基于机器学习的方法在实际隧道运维中真正进行应用.
猜你喜欢
西南交通大学学报(2022年5期)2022-11-03
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
现代计算机(2022年4期)2022-04-24
金属热处理(2022年3期)2022-04-09
建材发展导向(2021年23期)2021-03-08
微型电脑应用(2020年12期)2020-12-25
东南大学学报(自然科学版)(2020年1期)2020-01-16
扬州大学学报(自然科学版)(2019年2期)2019-08-12
软件导刊(2018年4期)2018-05-15
