
一种边缘环境下基于EfficientDet的施工人员安全帽检测方法
2020-10-09 09:09:30梅国新姚庆华
数字通信世界 2020年9期
梅国新,姚庆华,陈 瑶,刘 华
(1.云南省交通投资建设集团有限公司,云南 昆明 650228;2.云南省交通科学研究院有限公司,云南 昆明 650011)
目前,检测方法由于监控摄像机的位置距离监控场景较远,视频内工作人员图像像素尺寸小(一般30像素左右),同时背景较为复杂,这对于检测安全帽佩戴构成了重大挑战.针对以上问题,本项目提出了一种边缘环境下面向大监控视频背景的安全帽检测方法。针对边缘环境下面向复杂背景远距离监控视频中安全帽检测问题,本文讨论了jetson tx2环境下基于EfficientDet的检测方法的性能。
1 基于EfficientDet的安全帽检测
EfficientDet包含两部分:特征提取网络EfficientNet和面向多目标检测的加权双向特征金字塔网络。该架构解决了深度网络的深度、宽度和分辨率之间的平衡问题,可以提高生成模型的泛化能力。如图1所示,单一提高某个参数,模型对图像的分类准确率很快会达到上限。
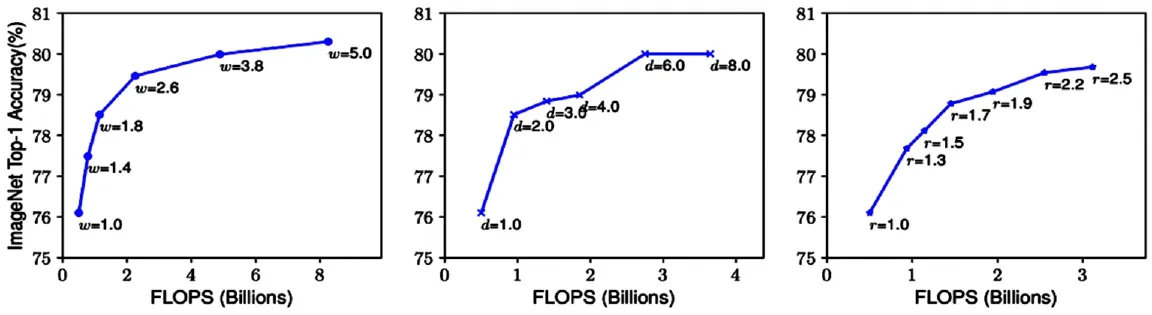
图1 单独提升模型宽度、深度、以及图像分辨率的效果
为了有效调整深度、宽度和分辨率参数,EfficientNet使用了“复合系数”来动态调整这3个参数。(α,β,γ)分别代表网络的深度、宽度和输入分辨率。根据前期研究可知网络宽度和分辨率每增加一倍,计算代价会多四倍,因此EfficientNet对目标函数的约束相进行了调整,分别考虑了网络深度、网络宽度和分辨率三个维度:网络深度约束网络深度约束分辨率约束其中图2给出了达到同样检测准确率,使用增加网络宽度、网络深度、分辨率的策略和使用EfficientNet策略的不同结果。
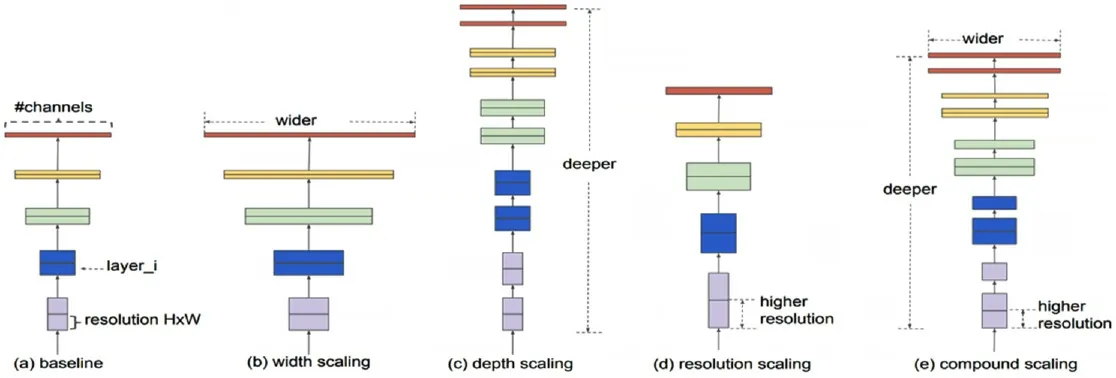
图2 (a)baseline model,(b)-(d)单一提参数策略,(e)EfficientNet策略
同时,谷歌大脑团队对EfficientNet网络进行了优化,使之适应多种目标检测,提出加权双向特征金字塔网络,从而快速地实现多尺度特征融合,对小目标的检测起到了显著的作用。其次采用了EfficientNet作为特征提取网络,大大减少了参数量,为我们将模型部署到移动边缘计算设备上提供了可能性。
2 实验
2.1 实验数据
实验数据集来自于(https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset),该数据集总共有7581张图像,包含9044个佩戴安全帽图像(正类图像),以及111514个未佩戴安全帽的图像(负类图像),所有的图像都标注出了目标区域及类别。
2.2 算法评价指标
本文采用mAP(Mean Average Precision)作为算法的性能评价指标,平均精度均值(mAP)是预测目标位置以及类别的这一类算法的性能度量标准。mAP指标能较好地评估目标定位模型、目标检测模型以及实例分割模型性能。
mAP指标定义如下,其中C为检测类别数目,AP为每一个检测类的平均检测精度。
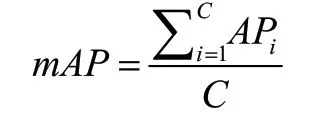
AP值刻画了检测准确率和召回率(precision-recall)曲线面积
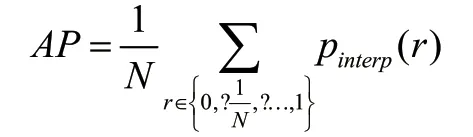
准确率和召回率计算公式如下:

式 中,TP表 示 真 正 例(True Positives);TF表示 假 正 例(False Positives);TN表 示 真 负 例(True Negatives);FN表示假负例(False Negatives)。
2.3 实验结果
本文将CascadeRCNN、YOLO V3作为基线算法,对比了不同参数设置的EfficientDet(即EfficientDet-D0、EfficientDet-D3,EfficientDet-D4)在jetson tx2边缘环境下的性能。其与基线方法模型大小及性能对比情况分别如图3、图4所示:
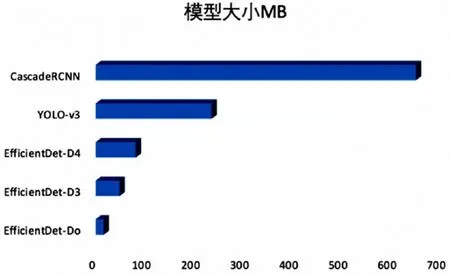
图3 模型大小对比
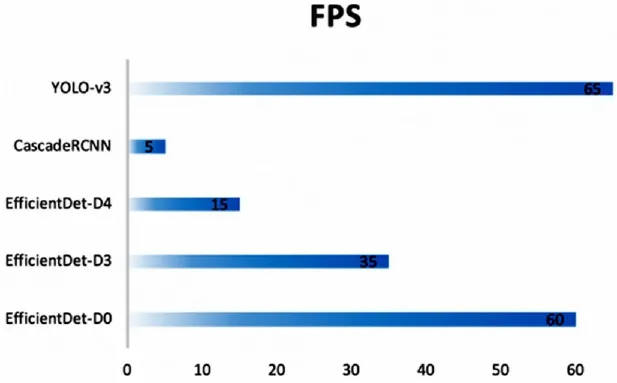
图4 模型性能对比
如下表1所示,EfficientDet在同等精度的前提下,模型只使用了52M参数,仅为主流模型的十几分之一,计算量为326B FLOPS的EfficientDet-D7在COCO数据集上实现了当前最优的51.0 mAP,准确率超越之前最优检测器(+0.3% mAP),其规模仅为之前最优检测器的1/4,而后者的计算量FLOPS更是EfficientDet-D7的9.3倍。从实际检测效果来看,EfficientDet模型克服了检测目标间存在着明显遮挡、重叠率高、图像分辨率低等问题,取得了比较好的效果,达到了推理速度更快,模型占用空间较小的要求,也为部署在边缘计算环境上提供了可能。
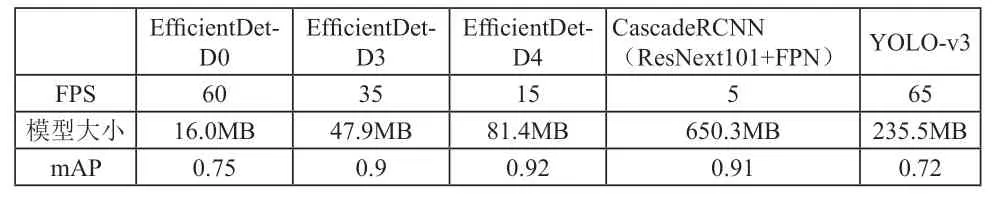
表1 同等精度下EfficientDet差数对比表
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
自动化学报(2017年5期)2017-05-14 06:20:52
少儿科学周刊·少年版(2017年1期)2017-03-29 17:50:36
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
医学研究杂志(2015年5期)2015-06-10 06:43:26
人生十六七(2015年5期)2015-02-28 13:08:24
华东理工大学学报(自然科学版)(2014年3期)2014-02-27 13:49:03
