
基于YOLO的多尺度并行人脸检测算法
2020-09-29 08:08贺怀清惠康华
计算机工程与设计 2020年9期
贺怀清,王 进,惠康华,陈 琴
(中国民航大学 计算机科学与技术学院,天津 300300)
0 引 言
人脸检测作为相关人脸问题[1-3]的基础,一直以来都是计算机视觉领域热门研究方向。随着深度学习的发展,开始出现许多基于卷积神经网络的人脸检测算法,Li等[4]提出了级联的卷积神经网络算法一定程度上解决了传统方法在开放场景对光照等环境因素敏感的问题。Zhang等[5]提出了多任务级联的检测算法与人脸关键点检测联合训练。通用目标检测算法经常被应用到人脸检测领域,比如Jiang等[6]将通用目标检测算法Faster R-CNN[7]应用到人脸检测中取得很好的检测效果。
上述采用的都是两阶段方法(two-stage),主要分为两个步骤:候选区域提取和候选区域特征判断。这一类方法主要特点是检测准确率高,但是速度方面有所欠缺。后来出现了端到端的单阶段方法(one-stage),比如Najibi等[8]提出根据不同卷积层的感受野大小不同实现多尺度的检测,检测精度虽然较两阶段类方法有所下降,但是检测速度提高了许多。在通用目标检测中比较经典的one-stage方法是Redmon等[9]提出的YOLO。
虽然YOLO具有检测速度快,误检率低和泛化能力强的优势,但直接应用在人脸中存在问题。由于网格划分的尺度单一,对多尺度人脸的检测效果不够理想,召回率不够高;另外,YOLO本质思想是将检测问题转变为回归问题,单一尺度的检测使得人脸的定位不准确;最后,YOLO算法是针对通用目标检测的算法,更多考虑的是类间的分离而忽略了类内的聚合,导致类内距离可能会大于类间距离而降低检测的准确度。
针对以上问题,本文提出基于YOLO的多尺度并行人脸检测算法(multi-scale parallel face detection algorithm based on YOLO, MPYOLO)。首先,MPYOLO具有由密集到稀疏的多尺度的网络结构能够兼顾多种尺寸的人脸,从而提高检测的召回率;多尺度网络使得同一张人脸检测得到的定位框增多,求取平均增加人脸定位的准确度;其次,采用基于生产者消费者模型的并行检测算法,保证了时间开销与YOLO持平;最后,引入中心聚合的思想,将中心损失函数(center loss)[10]与YOLO损失函数联合训练,降低类内的距离,进一步提高网络的分类性能。
1 MPYOLO模型结构
1.1 YOLO通用目标检测问题分析
YOLO主要思想是将输入图片划分成s×s个网格,每个网格负责预测m个边界框,则一幅图的候选区域最多为s×s×m个。如果检测目标的中心落在某个网格中,那么这个网格就负责预测回归这个目标,如图1所示,人脸框efgh的中心o落在了网格abcd中,则网格abcd负责回归预测出人脸。YOLO省去了two-stage方法中耗时的候选区域提取的步骤,提高了检测速度,但由于网格划分的尺度单一性,使得YOLO方法的召回率不够高。另外,YOLO采用回归方式定位人脸位置,速度虽然有所提升,但是定位准确性要比two-stage方法中采用搜索方式定位方法要差些。

图1 YOLO网格划分
1.2 多尺度并行网络结构
YOLO采用单一尺度存在召回率低的问题,召回率计算方法见式(1)
(1)
式中:TP(true positive)指正样本中预测为正的数量,FN(false negative)为正样本中预测为负的数量,YOLO召回率低是因为有些人脸没有检测到,TP值较低。如图2(a)所示,当人脸尺寸较小且距离较近时候,多个人脸的中心点就会落到同一个网格中。如果一个网格只负责预测两个边界框,则最终只能检测到其中两个人脸。如果将网格进一步细分,比如划分成8×8,如图2(b)所示就可以将距离近的小尺寸人脸划分开。人脸中心将落到不同的网格中就能够被检测到,TP值提升,从而提高检测的召回率。

图2 不同网格划分
当检测大尺寸人脸时,如果采用密集的网格划分,如图3所示,人脸中心点落到了候选框ABCD,则需要以候选框ABCD去回归预测真实的边界框EFGH,候选框与真正的边界框差距较大,这样导致YOLO对大尺寸人脸的定位不准确,因此只采用密集的网格划分,难以满足实际的需求。

图3 密集网格划分
针对以上分析,本文提出由密集到稀疏的多尺度并行网络,结构框架如图4所示。对于一幅含有多个尺寸的人脸照片,采用多尺度的网络来进行检测,稀疏的网格划分网络对大尺寸人脸检测效果良好,密集的网格划分网络对距离较近的小尺寸人脸检测效果良好。
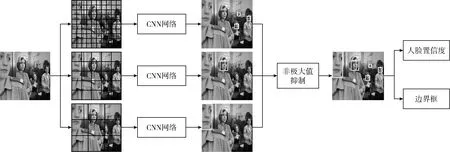
图4 多尺度并行网络结构
图4所示多尺度并行网络结构不仅提高了检测的召回率,在一定程度上也提高了定位的准确性。多尺度网络结构使得输入图片的同一个人脸可能会在不同尺度网络中检测出不同结果,如图5(b)所示,两个较细检测框为两种尺度下的两个不同的检测结果,经过非极大值抑制求取平均合并后得到较粗的检测框为多尺度网络下检测最终结果。在非极大值抑制过程中,对保留框与剔除框分别求取坐标与宽高的加和平均值为最终的输出结果。加和平均的结果由于是多个尺度网络的检测结果,比如图5(a)所示的单尺度YOLO检测定位要准确。

图5 单尺度与多尺度检测结果对比
串行的多尺度网络会使时间开销增大,为了使检测的速度与YOLO保持相同水平,MPYOLO采用基于生产者消费者模型的并行算法,具体算法见表1。多尺度网络由串行变成并行工作,时间开销由多个尺度网络检测的时间加和减少为单个尺度网络检测的时间,保证了YOLO在提高检测性能的同时时间开销不会大幅度增加。

表1 基于生产者消费者模型的并行检测算法
1.3 中心损失函数
YOLO损失函数采用的是平方和误差,这种误差的特点是误差值大的将会变得更大从而增大不同误差值之间的差距。平方和误差损失函数作为神经网络的输出层,有着计算方便的优点,但是将隐藏层输出值转换成结果值时只考虑到了类间的分离,却忽略了类内的聚合问题。这样导致的结果是类内的距离可能比类间的距离还要大,如图6(a)所示,类别1与类别2的类间距离比类内距离还小。因此,引入中心聚合的思想,将类内距离减小,如图6(b)所示,相对的进一步增加了类间的区分度,提升检测的性能。
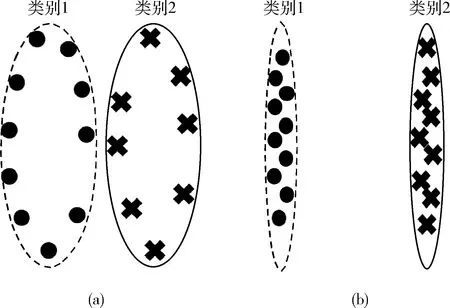
图6 中心聚合
为解决这一问题,本文在YOLO损失函数基础上加入中心损失函数,见式(2)
(2)
N表示所有样本网格分块总数量,xi表示第i(i=1,2,3,…,N) 个分块全连接层之前的特征值,cyi表示第i个分块的第yi个类别的中心。该公式有效地表示了类内的变化,理想情况下,随着深层特征的改变,应该更新cyi, 换句话说,在每次迭代中需要考虑整个训练集并求取每个类的平均特征,实际中由于数据量巨大以及计算资源有限,这样是不切实际的。因此,中心损失不能直接使用。
为解决这个问题,首先,不是基于整个训练集更新中心,而是基于小批量执行更新。在每次迭代中,通过平均相应类的特征来计算中心。其次,为了避免由少量错误标记的样本引起的大扰动,使用标量α来控制中心值的学习率。c与Δc的更新表达式分别见式(3)和式(4)。最终采用标准随机梯度下降进行优化
(3)
式中:t表示迭代次数
(4)
其中

(5)
训练过程中,YOLO损失函数与中心损失函数结合,见式(6)
Lcls=LYOLO+λLc
(6)
标量λ, 称作惩罚系数用于平衡两个损失函数。如果λ设置为0,YOLO损失函数则可以被认为是这种联合损失函数的一个特例。
2 实验结果及分析
本文实验使用的计算机配置为ubuntu 16.04操作系统,Intel Core i5处理器,内存为8 GB,显卡为NVIDIA GeForce GTX 745,开发环境使用的是Pycharm。
2.1 数据集介绍
CelebA[11],它是香港中文大学提供的人脸数据集,包括10 177个名人身份,总共202 599个人脸。这些人脸图像覆盖多姿态,多角度以及复杂的背景。CelebA数据集的特点是大部分图像都只包含一张人脸,这样在训练的时候可以确保一个网格中只能落入一个人脸的中心,使得对人脸的特征学习更加充分。
FDDB[12]是非常具有挑战性的人脸检测数据集,一共包含了2845张图片,人脸总数达到5171个。这些人脸所呈现的状态多样,包括遮挡、罕见姿态、低分辨率以及失焦的情况,该数据集是评价人脸检测算法的权威数据集。
2.2 模型训练
从CelebA数据集中随机选取15 000张作训练集。如图7 所示为7×7网格划分的训练网络结构图,引入中心损失函数后,为了进一步增加网络的分类能力在YOLO网络卷积层最后一层后面增加一层参数为512的全连接层,同时为了防止过拟合,在最后输出层之前增加dropout层。其它尺度的网格划分的训练网络与图7结构类似。图7中 YOLO 卷积层的具体的网络结构参照文献[9]。

图7 训练网络结构
卷积层预训练参数使用YOLO网络全连接层的前24层网络参数,这些参数在CoCo[13]数据集上取得了63.4%的平均准确率。中心损失函数学习率设置为0.1,惩罚系数设置为0.1,将输入图片调整成448×448大小分别训练不同网格划分的网络。
本文在网格划分为 {n×n|n=2,3,…,14} 做测试,其中7×7,10×10,14×14这3种网格划分有较好的检测结果。以7×7网格划分的训练结果为例,如图8所示。准确率是评价分类器性能比较直观的评价指标,本文每迭代5000次在训练集上进行测试。如图8(a)所示,随着迭代次数的增加,中心损失不断优化下降,最终趋于平稳状态,此时在测试集上平均准确度(average precision,AP)也不断上升最终趋于饱和状态,趋近于1,表明训练的网络已经具备很强的分类能力。整体损失值同样也随着迭代次数的增加不断优化下降最终趋于平稳状态,同样AP值也不断上升最终趋于饱和状态,趋近于1,如图8(b)所示。

图8 中心损失与整体损失的训练优化
2.3 对比算法实验结果及分析
2.3.1 多尺度与单尺度方法对比
从CelebA数据集中随机选取5000张图片组成测试集。采用7×7,10×10,14×14这3种尺度的并行网络结构与单尺度7×7的YOLO方法进行测试,得到受试者工作特征曲线(receiver operating characteristic curve,ROC)对比如图9所示。ROC曲线越靠近点(0,1),分类器检测性能就越好;绘制ROC曲线时阈值不固定,也体现了分类器的泛化性能,越靠近点(0,1)分类器泛化性能越好。图9所示多尺度网络结构的曲线要比YOLO单尺度的曲线更靠近点(0,1),这是因为多尺度网络相对于单尺度的YOLO方法对数据集中不同尺寸的人脸有更强的检测能力。稀疏的单尺度网络对小尺寸人脸检测性能不理想,但在多尺度中不仅保留有稀疏的网络,还存在密集的网络可以提高对小尺寸的人脸检测效果,因此多尺度的网络结构检测性能和泛化性能都要优于单尺度的YOLO。如图9所示,采用本文多尺度结构的YOLO在横坐标相同的情况下,纵坐标要比单尺度YOLO的曲线高,也就是召回率高。

图9 单尺度与多尺度YOLO的ROC对比

图10 单尺度YOLO有无中心损失ROC对比
2.3.2 无中心损失对比
图10所示为在7×7网格划分下迭代55 000次YOLO算法有无引入中心损失后的ROC曲线,可以看到,引入中心损失后,ROC曲线要高于YOLO方法的曲线,也就是说在FP(false positive)相同的情况下,引入中心损失后的召回率要比YOLO方法要高,要更靠近左上角,分类性能有所提高。引入中心损失函数后,训练过程中人脸的特征被不断聚合,不同人脸之间的差距不断地减小,不同的人脸不断地向着中心聚集,如此一来,最终人脸之间的联系会变得更加紧密,相对的人脸与背景的差异就会变得明显,因此网络的分类性能会有所提高。
在ROC图中当两条曲线交叉的时候无法直接看出哪一条曲线性能更佳,引入AUC(area under curve)值,它可以根据曲线右下方面积占比计算得出,AUC值越大,对应的分类器性能越好。从第1次迭代到55 000次迭代每隔5000次在测试集上测试,绘制出单尺度YOLO有无引入中心损失AUC对比,如图11所示。从图中可以看出,开始的时候加入中心损失的AUC值要比原方法要低,这是因为训练开始阶段,训练不够充分,一定程度上破坏了类内特征之间的联系,特征的聚合还不足以去弥补。随着迭代次数的增加达到两条曲线交点30 000次迭代左右时,类内距离开始小于类间距离,这时中心损失开始起作用,类内距离不断减小,分类性能不断提高。从图中两条曲线的走势可以看出,YOLO方法AUC值基本保持平稳状态,加入了中心损失后AUC值呈现上升的趋势,这也正是特征不断中心聚合的过程,类内聚合越紧密,相对的类间的距离越大,分类器分类效果越好。
为了更加直观展示中心聚合后的效果,迭代55 000次后用5000个样本的卷积层最后一层的特征的平均数与中位数画出散点图。图12(a)和图12(b)分别为未引入中心损失与引入中心损失的对比图。可以看到,加入中心损失后,散点图更加集中,特征聚合程度要明显高于未加入的YOLO算法。加入中心损失后类内的距离减小了,使得类内特征更加紧密,相对的类间的距离增大,这样提高了网络的分类性能。

图11 单尺度YOLO有无中心损失AUC对比

图12 特征聚合对比
2.3.3 人脸定位对比
为了比较两种方法定位的准确性,本文计算检测到人脸的边界框与真实人脸边界框的平均交并比(intersection over union,IoU),平均交并比越大表明检测结果与真实人脸边界框重叠区域越大,定位也就越准确。对比结果见表2。从表中可以看出,本文的方法平均IoU要比YOLO方法大。这是因为不同尺度的网络都有可能准确地检测到人脸的一部分,对最终的检测结果都有所贡献,如果采用YOLO单纯地剔除重叠框的策略就会忽略不同尺度网络对检测结果所做出的贡献,在一定程度会导致定位的不够准确,而本文采用的策略是将不同尺度网络检测结果非极大值抑制的同时加和求取平均,这样考虑到了不同尺度网络的检测结果,因此正如表2结果所示,加入了多尺度网络后定位的准确性要高于YOLO方法。

表2 平均IoU对比结果
2.3.4 整体结果对比
为了进一步验证本文方法的有效性,在FDDB数据集上与YOLO进行对比。不失一般性地选取FP为1106,从准确率、召回率以及检测速度3个方面与YOLO进行对比,结果见表3。从表中可以看出,本文方法在FDDB上的准确率和召回率要优于YOLO方法。本文方法采用多尺度的网络结构,对于差异大的多尺寸人脸图片要比YOLO敏感,因此能够在FDDB数据集上发挥多尺度的优势,检测出更多尺寸的人脸。

表3 FDDB数据集对比结果
图13为几张在FDDB上随机选取的实际检测结果对比图,白色边框为YOLO方法检测的得到的最终结果,黑色边框为本文检测结果。可以看到针对多角度多姿态的人脸,本文方法的检测结果相比于YOLO与实际的大小和位置更加吻合。

图13 FDDB数据集检测效果对比
为了进一步验证本文方法的优势所在,本文选取目前主流的Face R-CNN[14]和最新的DSFD[15]从准确率、召回率以及平均检测速度3种具体数值指标进行比较,结果见表4。从结果可以看到,本文方法的准确率和召回率相比于YOLO都有所提高。由于本文采用了生产者消费者模型的并行检测方式,检测速度基本与YOLO持平。从实验结果,可以看出虽然MPYOLO在检测效果上与Face R-CNN和DSFD稍微有所差距,但是检测速度有着明显的优势。另外,MPYOLO的模型相比于Face R-CNN和DSFD要简单,易于实现并且应用。

表4 CelebA测试集对比结果
3 结束语
本文基于YOLO方法进行改进,提出了多尺度并行的检测网络,多尺度网络结构能够充分学习到不同尺度的人脸特征,提高多尺寸人脸的检测效果。在减小时间开销上,采用了基于生产者消费者模型的并行检测算法,将多个尺度网络检测时间缩短为单尺度网络的检测时间。此外,引入中心损失函数,能够减小类内距离,使人脸特征联系更加紧密,进一步提高网络的分类性能。实验结果表明,MPYOLO的召回率有所提高,准确率也有所提高,人脸定位的准确性也有所提高,同时速度仍然保持与YOLO的相同水平。本文在对人脸图片或者视频处理方面有着良好的应用价值。在今后的研究中会从其它方面进一步优化MPYOLO模型,争取能够更快更准地检测并定位人脸。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学小灵通·3-4年级(2021年5期)2021-07-16
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
今日农业(2019年15期)2019-01-03
动漫星空(2018年9期)2018-10-26
太空探索(2016年5期)2016-07-12
共产党员(辽宁)(2015年2期)2015-12-06
读者·校园版(2015年19期)2015-05-14
时代英语·高三(2014年5期)2014-08-26
