
茶叶嫩芽图像的自动识别与检测研究
2020-09-28 07:05白雪蒋思中
电脑知识与技术 2020年16期
白雪 蒋思中

摘要:针对目前茶叶种植中自动化茶叶采摘面临的难题,提出了一种茶叶嫩芽图像自动识别与检测的算法。该方法通过建立增强的图像样本库,选择超绿指标、饱和度等特征数据,利用神经网络算法进行茶叶嫩芽图像的训练、识别和检测,对桂绿1号进行实验,取得较好的实验效果,表明了该算法的有效性。
关键词:茶叶嫩芽;图像增强;神经网络;识别与检测
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2020)16-0207-02
Abstract: In order to solve the problem of automatic tea picking in tea planting, an algorithm of automatic recognition and detection of tea bud image is proposed. This method uses neural network algorithm to train, recognize and detect the tea bud image by establishing the enhanced image sample database, selecting the super green index, saturation and other characteristic data, and carries out the experiment on Guilv 1. The experiment results show that the algorithm is effective.
Key words: tea shoots; image enhancement; neural network; recognition and detection
1 引言
我国是茶叶生产大国,茶叶产量连年上升[1],茶叶制作过程包含采摘、晾晒、杀青等几道主要工序, 其中最为重要的是采摘,采摘的嫩芽品质可能会对成品茶质量造成很大影响,但茶叶生产中的鲜叶采摘环节一直存在成本高、劳动强度大、工作效率低等问题,影响了茶叶生产量。因此,实现茶叶嫩芽的自动化采摘是个值得研究的课题。
目前,也有些学者对茶叶嫩芽的自动化采摘进行了研究,早在1958年就有简易的机械化采茶机出现[2],后来陆续出现了机动、电动的采摘嫩芽的机器,这些机器虽然能提高采摘效率,代替一些人的劳动,但是采来的茶叶老叶太多,和嫩芽混在一起,后期挑拣需要时间,直接做茶影响茶叶的品质[3]。考虑到后期分拣工作会耗费不少时间,也有人进行了分拣技术的研究,例如唐萌等人[4]研究了名优茶应用采茶机采摘茶叶后续处理技术,茶叶的分级,并且对多种分级方法进行了对比分析;王成军等人[5]设计了一种利用多维震动进行茶叶嫩芽分级的机器,缩短了一些茶叶分级的时间。虽然目前一些采茶机器使采茶的时间成本大大降低,但由于没对茶叶的嫩芽进行识别和检测,采到很多没用的茶叶,挑拣困难,却对茶叶的茶株进行了一定程度的破坏,所以很多茶叶园区不愿意采用这种采茶机器。
随着智能农业发展,大量的智能化技术应用到农业生产中,这为茶叶嫩芽的采摘提供了启示,将智能化技术应用到茶叶嫩芽的采摘中,就可以极大地提高嫩芽采摘的品质、完整度等,减少对茶叶茶株的破坏。其中最关键的技术之一就是茶叶嫩芽图像的识别与检测技术。本文使用了一种茶叶嫩芽图像的识别与检测方法,并针对桂绿1号进行了实验,取得了较好的效果。
2 茶叶嫩芽图像的识别与检测
在茶叶嫩芽采摘中,根据茶株和制茶的不同需要,在实際的采茶中有时一芽两叶,有时一芽一叶,有时却只能采摘嫩芽,其他的叶片都要放弃,因此,要综合考虑建立样本库。
首先,需要检测嫩芽样本库,为了深度学习训练的有效性,选取广职茶园桂绿1号茶园中拍摄的200余幅茶叶图片,建立茶叶样本库,对于多种姿态和光照嫩芽进行拍摄,并对拍摄图像进行分割。考虑到嫩芽采摘判定的复杂,对数据样本进行一些旋转、缩放、更改背景等操作,增加样本数量。
然后,对茶叶嫩芽的特征进行提取和建模,在茶园中茶叶的老枝、枯叶、土壤等在颜色上与茶叶嫩芽有明显的差异,通过对茶叶图像进行RGB通道分离研究发现,茶叶嫩芽的G分量明显高于老枝、枯叶、土壤的部分,因此,鉴于这种颜色特殊性,进行茶叶图像的图片预处理,根据2G-R-B超绿指标,加强G分量使嫩芽与背景的区别更加明显,从茶叶图像中选取合适的嫩芽与背景像素点,从中提取特征数据组成训练特征数据集,为后续的训练做准备。而有些老叶与嫩芽的区别主要在绿色深浅上,像素值的界限并不明显,因此加入饱和度特征数据和部分纹理参数作为参考,饱和度越大,颜色越鲜艳,反之颜色越浅。
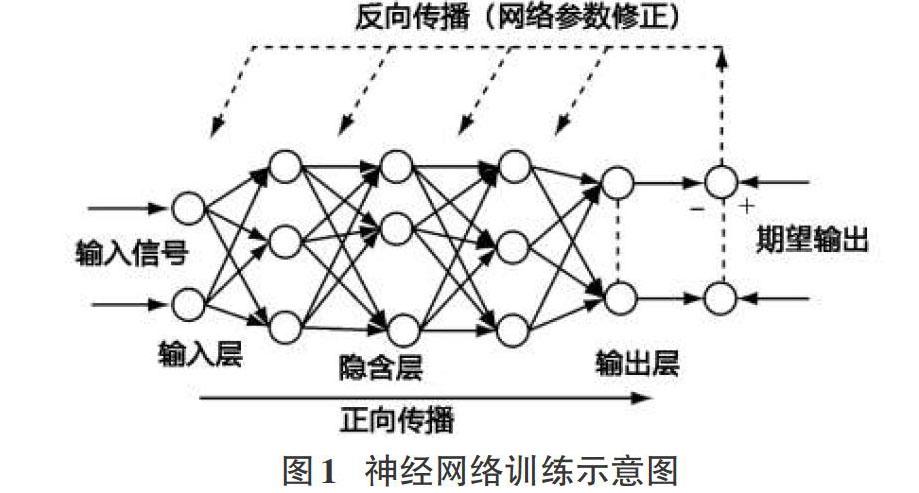
最后,利用BP神经网络对特征数据进行训练,根据训练的结果,对茶叶图像进行匹配识别和标记,BP神经网络是一种根据误差调整网络参数进行自适应训练的多层神经网络算法,包括信号的前向传播和误差的反向传播两个过程,应用十分的广泛。
经过反复学习训练,当实际输出与期望输出误差满足约束条件时,训练终止。
在有噪声的情况下,识别结果有些杂乱,需要采用闭运算进行去噪。闭运算是先对图像进行膨胀处理,再进行腐蚀处理。它可以把区域内的微小缺口填充好,将短的断口修补上。通过闭运算,大量噪声被去除,图像整体比较平滑,经闭运算处理后的图像色调更加均匀,对后续采摘点的确定更有利。
3 总结
为了解决项目实践中茶叶嫩芽识别与检测的难题,本文提出了一种茶叶嫩芽识别与检测的方法,通过利用神经网络的特性对特征数据进行训练的方法进行茶叶嫩芽的识别与检测,通过对桂绿1号茶叶图像的实验,取得较好的实验效果,但是后期还需要进一步提升识别与检测的精度和抗干扰能力。由于光照的影响会使嫩芽出现遮挡呈现暗色调或者老叶透光后呈现翠绿色,有些茶叶嫩芽的舒展度不高,叶片的脉络不清晰且较密集,反之老叶的舒展度较高,这些种情况都使嫩芽图像识别和检测出现了问题,后续将继续进行抗干扰的研究。
参考文献:
[1] 国家统计局.中华人民共和国2018年国民经济和社会发展统计公报[EB/OL].(2019-02-28).
[2] 高凤.名优茶并联采摘机器人结构设计与仿真[D].南京:南京林业大学,2013.
[3] 唐小林.机械化采茶的利弊分析及发展前景[J].中国茶叶工,2008(4):10-12.
[4] 张兰兰,董迹芬,唐萌,等.名优茶机采鲜叶分级技术研究[J].浙江大学学报(农业与生命科学版), 2012,30(5):593-598.
[5] 谢俊,张晓庆,王成军,等.三平移并联茶叶筛分机构设计及运动仿真[J].工程设计学报,2012,19(3):208-212.
【通联编辑:朱宝贵】
猜你喜欢
航天返回与遥感(2022年2期)2022-05-12
燃气涡轮试验与研究(2021年6期)2021-08-01
海洋信息技术与应用(2020年4期)2021-01-18
电子制作(2019年19期)2019-11-23
中国生物医学工程学报(2019年5期)2019-07-16
北京航空航天大学学报(2017年3期)2017-11-23
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
警察技术(2015年1期)2015-02-27
海军航空大学学报(2015年4期)2015-02-27
