
浅析克隆代码领域本体构建研究
2020-09-26 11:50翟晔葛湘薇
内蒙古教育·理论版 2020年6期
翟晔 葛湘薇
摘 要:代码克隆是软件开发中常用的方法。本文针对“克隆代码领域本体构建”这一核心问题,从克隆代码领域本体模型的规划、分析与设计、形式化、本体评估及维护等方面展开具体研究工作。通过克隆检测结果获取克隆代码的克隆关系,通过代码静态分析技术抽取克隆代码之间的耦合关系,基于这两种以克隆代码为中心的数据,设计并实现克隆代码领域本体。该本体对克隆代码的理解、分析、维护与管理有积极作用。
关键词:克隆代码;领域本体;克隆关系;克隆检测
【中图分类号】G【文献标识码】B 【文章编号】1008-1216(2020)06C-0127-02
克隆代码是指,一个软件系统代码库中的两个或多个代码片段彼此完全相同或几乎相似的代码。一组相似的代码片段构成一个克隆类。有关克隆代码的研究工作开始于上世纪九十年代,并在随后的二十多年里受到越来越多国内外研究学者的高度关注,在克隆检测、克隆演化分析等多个方面产生了大量研究成果。
过去的软件克隆研究主要集中于代码克隆的检测和分析,而近年来的研究扩展到了克隆管理的整个领域。克隆代码领域本体的构建可以为克隆代码理解、克隆分析、克隆维护、克隆管理以及克隆重构等研究提供有力的参考与支持。该本体可以为软件开发及维护人员提供克隆代码的更多特征以及更深层次的关系,如分布特征、耦合特征、高层设计特征等。这使得克隆代码更容易被理解,进而使软件开发及维护人员能更高效地维护及管理克隆代码。
一 相关研究
目前,针对以领域本体为基础的相关研究还非常少。现有的基于领域本体的代码理解及分析研究,大多是通过代码本体与业务逻辑本体相关联的方法分析、理解与维护软件系统,这些研究大多关注了代码或克隆代码的基本信息或是业务逻辑信息,但是,克隆代码的维护与管理工作仅凭这些研究成果是远远不够的。通过克隆代码领域本体,可以解决类似“同一克隆群内的克隆代码在高层设计上有什么联系”“哪些克隆代码与其他代码的耦合程度较高”等问题。这类问题可以给出克隆代码更全面的生存环境状况。
二、克隆代码领域本体构建
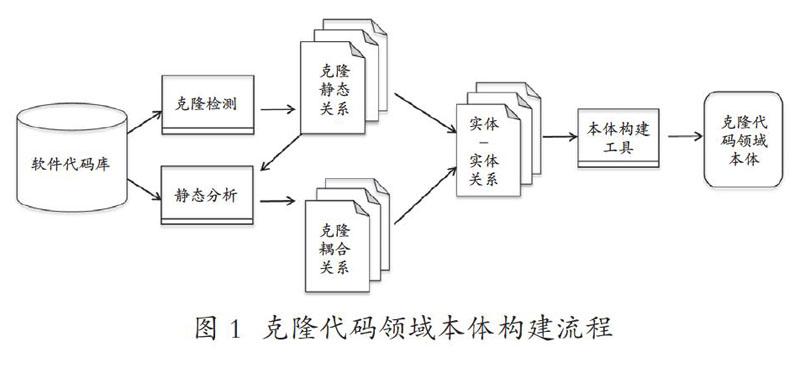
本研究面向开源软件代码资源,笔者制订了详细技术方案,并开展深入研究。本研究实现流程如图 1所示。
(一)克隆静态关系
克隆检测是研究基础,本研究借助领域内较为流行的克隆代码检测工具NiCad来进行克隆代码检测工作。NiCad可以有效检测3种类型的克隆代码,并以XML格式反馈克隆对以及克隆群关系。根据克隆代码检测结果,做进一步分析,获得克隆关系。
1.克隆代码相似度。
克隆代码的相似度是指两段克隆代码片段之间的文本相似度,本研究利用编辑距离相似度计算模型,计算两段克隆代码片段之间的文本相似度。
2.克隆类型。
克隆类型除了能反应克隆代码文本相似程度,还能够反应克隆代码之间存在的差异。本研究利用NiCad对每一种克隆类型进行检测,从而可以直接获取克隆对之间的克隆类型关系。
3.克隆对及克隆群关系。
克隆对被分组,称为克隆群的集合,其中集合中的任何两个片段都可以形成克隆对。由于克隆代码检测工具能以克隆对、克隆群的方式反馈克隆代码,所以通过分析检测结果,可直接获取克隆对与克隆群关系。
4.克隆代码位置。
克隆检测结果中至少要包含表征克隆代码位置信息的三元组:所在文件名、起始行号、终止行号。通过分析克隆代码检测工具的反馈信息,即可获取克隆对与克隆群关系信息。
(二)克隆代码耦合关系分析
构建克隆代码领域本体,除了关注代码的克隆关系外,还需关注克隆代码与其他代码之间存在的耦合关系,这样才能更全面地表征克隆代码的生存环境,更深层次地理解克隆代码。本文中涉及克隆代码的耦合关系包含以下几个方面。
1.继承、实现关系。
由于特定粒度的克隆代码片段位于某一个类或接口中,本研究考虑了克隆代码所在的類是否继承了其他类,从而可反映出部分克隆代码是否在高层设计上存在着联系。
2.声明关系。
声明关系指一个类中声明的属性和方法。通过分析声明关系,可以挖掘出克隆代码所在的类之间是否存在聚合等关系,这些关系可以反应克隆代码所在类之间存在着哪些设计模式。
3.调用关系。
克隆代码与其他代码片段之间存在着耦合关系,例如,某一段克隆代码调用了某些函数,或者该克隆代码片段被其他代码段调用。与克隆代码相关的调用关系,是构成克隆代码生存环境的重要数据。
克隆代码耦合关系提取,是克隆代码本体构建的关键,本研究采用AST技术准确地提取了克隆代码中的耦合关系。
三、克隆代码领域本体的构建
结合克隆代码的实际需要,本项目以七步法本体构建思想为指导,结合软件工程的结构化开发方法,设计克隆代码领域本体的构建流程。主要包括以下步骤。
(一)本体规划
需求分析是本体规划的第一步,主要任务是明确本体构建的基本信息,最后生成需求分析文档。该本体适用的专业领域和范围是软件代码中的克隆代码,构建本体的目的主要是为克隆管理提供方便。该本体的目标用户是开发人员和测试维护人员等,目前不存在可重用的本体。
(二)本体分析
本体分析阶段主要任务是:确定本体的主体架构和知识粒度,明确克隆代码领域本体需要哪些克隆实体来填充和支撑,以及提取克隆代码中的各种信息。克隆代码以克隆代码片段为单位的方式进行组织,本文选用自上而下的构建方法设计本体。
(三)本体设计
对本体分析阶段收集到的概念进行分析归纳,建立本体类,然后依据概念的唯一性和同级概念间不存在交集的要求,形成以继承关系为主关系结构的树状模型、声明及调用关系。类是本体的核心与基础,定义本体的类应该能够突显类本身的特性,所以,一个新的类应包含其父类所没有的新属性。例如,对于“克隆群”类,它具备的属性有克隆群尺寸、克隆群号等,而对于该类下的子类“克隆代码”则新增了代码相似度、克隆类型、文件距离等属性。
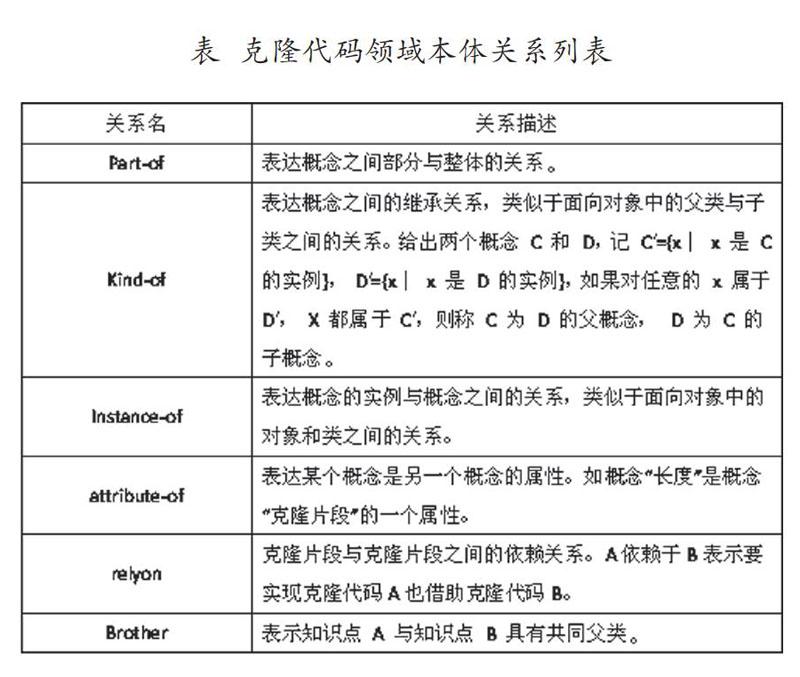
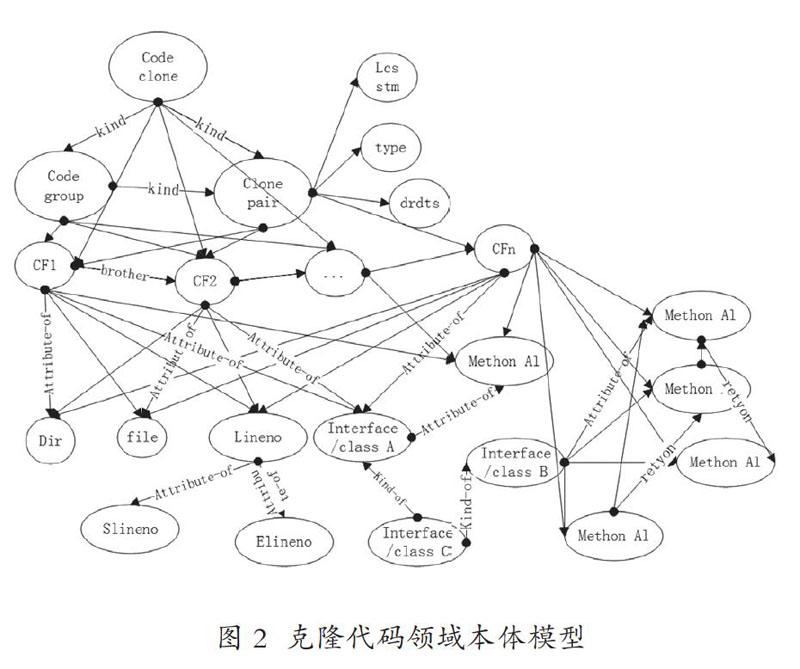
克隆代码领域不同实体间存在的关系很多,如对一个具体克隆片段来说,它需同属于一个克隆对。本项目设计的关系如右表。同时,图2呈现了克隆代码领域本体中部分实体以及对应关系。
(四)本体形式化
1.本体的形式化主要采用形式语言来构建。
本研究中采用OWL 描述语言,用 Protégé保存为基于 RDF/XML格式的 OWL 文件,文件命名为Code Clone.owl。
2.命名空间声明。
一组 XML 格式的命名空间的声明,本体标识符的表示可以提供无歧义的解释方式,使本体的表示更具可读性。
3.实体定义。
为了避免本体表示过程中对冗长的 URL 的书写,文档类型声明部分提供了对一些实体的定义,利用实体名来代替冗长的URL。
(五)克隆代码本体的存储与维护
对于克隆代码领域本体的持久化,本文采用 Jena 技术实现,并将本体持久化到 MySQL 数据库中存储。
本体的维护是指本体的迭代进化。本体的建模目标非一个周期或者一次循环就能够完全实现的。由于软件复杂度的增加或新技术的迭代更新,后期需要对现有本体进行调整。
四、总结与展望
本研究是将克隆代码与领域本体相结合,构建出克隆代码的领域本体。研究过程中,通过对克隆代码中耦合关系的提取,深入地研究了克隆代码中的函数调用、变量之间的关系,该本体能帮助开发和维护人员有效地理解克隆代码的生存环境,为克隆代码的后期演化和重构提供依据。
參考文献:
[1]史庆庆,孟繁军,张丽萍,等.克隆代码技术研究综述[J].计算机应用研究,2013,(6).
[2]张瑞霞,张丽萍,王春晖,等.基于主题建模技术的克隆群映射方法[J]. 计算机工程与设计,2015,(6).
[3]涂颖,张丽萍,王春晖,等.基于软件多版本演化提取克隆谱系[J].计算机应用,2015,(4).
[4]苏小红,张凡龙.面向管理的克隆代码研究综述[J].计算机学报,2018,(3).
[5]郭颖,陈峰宏,周明辉.大规模代码克隆的检测方法[J].计算机科学与探索,2014,(4).
[6]史庆庆,孟繁军,张丽萍,刘东升.克隆代码技术研究综述[J].计算机应用研究,2013,(6).
