
基于FPGA的快速樱桃缺陷检测与识别系统设计
2020-09-18 06:15裴悦琨连明月
食品与机械 2020年8期
裴悦琨 - 谷 宇 连明月 -
(1. 大连大学辽宁省北斗高精度位置服务技术工程实验室,辽宁 大连 116622;2. 大连大学大连市环境感知与智能控制重点实验室,辽宁 大连 116622)
卷积神经网络(convolutional neural networks,CNN)是目前性能较好的深度学习算法之一。通过其网络模型和足够的训练数据集,CNN可以为某些任务生成复杂的功能,胜过传统的人工算法。目前,CNN已成功应用于手写体数字识别及交通标志识别[1-2]等,并且取得了较好的效果。
基于CNN的水果品质检测大多是在软件平台上实现。刘云等[3]基于CNN对苹果进行分块缺陷检测,并且在软件平台上进行训练和测试,检测速度达到5个/s,且正确率高达97.3%;裴悦琨等[4]对樱桃的缺陷进行检测和识别,利用CNN对采集的樱桃图片进行测试,基于CPU的软件平台上识别速度可达25个/s;伍锡如等[5]构建一个多层卷积神经网络,在英特尔i5平台上对水果采摘机器人视觉识别系统进行测试,单张水果图像的识别速度只需0.2 s。这些软件平台都是基于通用的处理器,然而CNN具有很高的并行度,通用处理器主要用来控制指令调度、执行和逻辑判断,并不适合用来大量的并行计算[6]。因此基于软件方式的CNN在实时性和能耗方面都不能适应实际水果检测中场外作业的需求。目前大部分对于CNN的研究主要还是采用GPU,但是对于GPU功耗大的问题一直存在,所以在需要电池供电的嵌入式设备中也是很难得到应用。
现场可编程门阵列(field programmable gate array,FPGA)具有强大的并行处理能力、灵活的可配置特性和超低功耗,使其成为CNN实现平台的理想选择。王巍等[7]充分利用CNN的并行计算特征,进行了CNN算法的FPGA并行结构设计,提高了资源利用率且计算效率也得到大幅提升;Ma等[8]使用RTL编译器完成CNN网络的硬件加速,使用FPGA在100 MHz的工作频率下得到2倍的性能提升,然而上述基于硬件描述语言(HDL)或者逻辑图的设计方法难度较大,周期较长并且在数学运算上存在许多弊端,极大地阻碍了FPGA中进行人工智能的快速开发[9]。Danopoulos等[10]的研究充分地展现了FPGA快速开发的优势,将网络框架移植到FPGA的ARM(基于Zynq-7000)处理器中,在Xilinx的SDSoC开发环境中设计硬件加速器,并利用硬件加速器显著提高神经网络执行速度。
试验拟采用美国Xilinx公司发布的SDSoC开发环境,通过使用C/C++在目标平台上完成完整的硬件/软件系统的编译、实现、调试执行等全过程[11]。利用卷积网络并行结构的特点,采用高级语言映射卷积神经网络模型并进行优化设计,通过处理器系统(Processing System,PS)和可编程逻辑(Programmable Logic,PL)的协同处理实现一个完整的软硬件系统,为樱桃的快速、准确地检测分级提供新的方法和策略。
1 卷积神经网络
相比普通的图像处理算法,卷积神经网络仅需少量的预处理,识别范围广,能容许图像的畸变,对几何变形具有很好的鲁棒性,其经典网络模型包含卷积层、池化层、全连接层等结构。其中卷积层即特征提取,针对图像上存在的特征进行局部感知,紧接着进行多层卷积获取全局信息。
池化层也叫下采样层。主要用作降低特征维度,减小过拟合的发生,同时增强系统的容错性。
全连接层即输出层,主要对数据进行归一化处理,避免数据值大的节点对分类造成影响,最终进行正确的图片分类。
卷积过程如图1所示:输入层的图像首先通过多个卷积层、修正线性单元(rectified linear unit,ReLU)以及最大池化层运算,之后进入全连接层,最后通过输出层得到最终的分类结果。
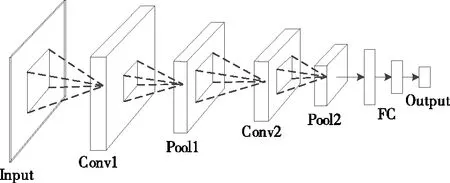
图1 卷积神经网络结构
针对樱桃缺陷的特点,设计CNN模型。该模型包括卷积层、修正线性单元、最大池化层以及全连接层。模型设计如表1所示。
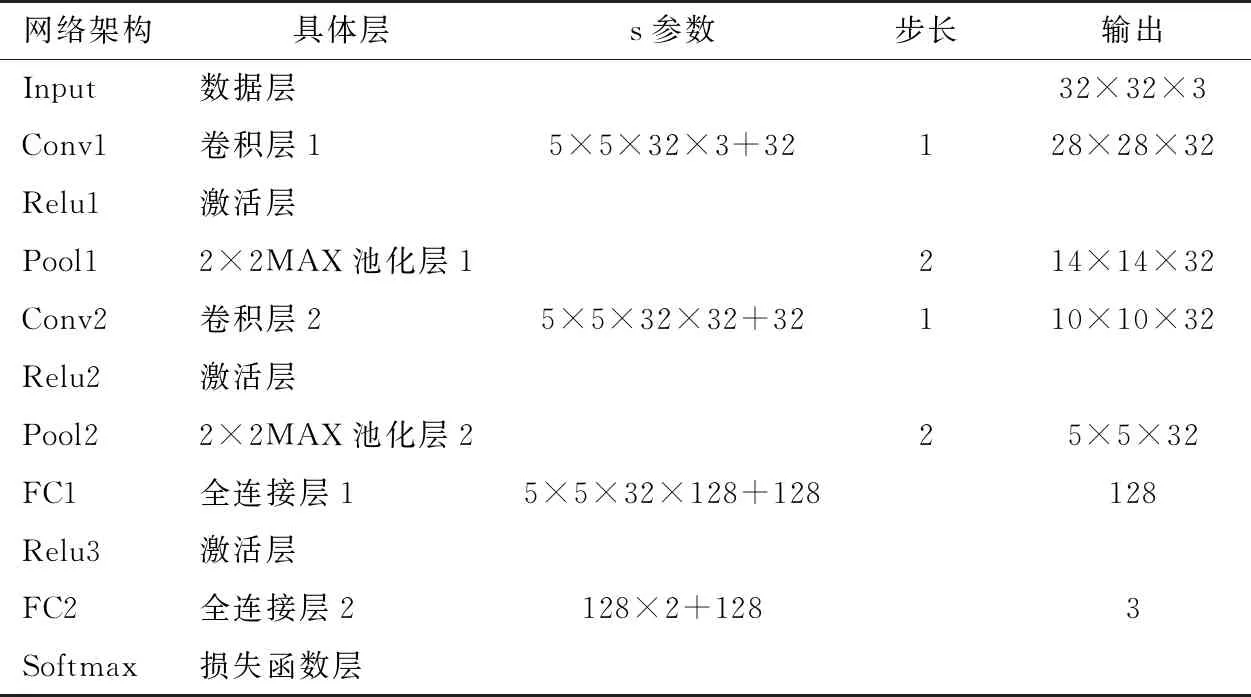
表1 CNN模型设计
2 樱桃缺陷检测与识别系统结构设计
2.1 系统结构
樱桃缺陷检测与识别系统的结构设计如图2所示。主要包括图像采集、HDMI接口、SD卡数据读取、图像预处理、PL端加速和终端显示等模块。其中系统全局控制在ARM处理器完成,主要负责HDMI接口调用、数据传输,对图像进行预处理,并完成加速函数对PL端的写入工作,最终PS端将分类结果显示在终端显示器上。
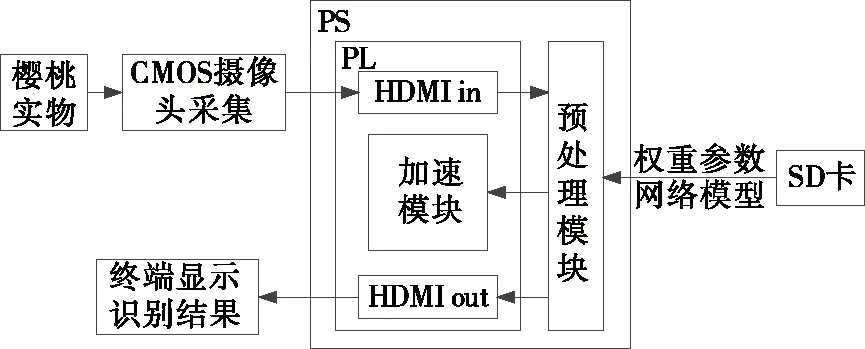
图2 系统结构设计框图
由于卷积模块和硬件接口模块计算密集且模块化较强,因此将其模块放入FPGA的PL端实现。该系统优点是在Xilinx的SDSoC开发环境中采用软硬件结合的形式,复用卷积模块以及使用优化指令对卷积层和数据传输进行优化,节省资源,提高识别效率。
2.2 网络映射
整个网络模型移植到Zynq 7020 SoC以便在ARM内核上运行。为了使网络在Zynq上运行,必须使用SDSoC环境中包含的ARM交叉编译器对整个模型进行交叉编译。SDSoC是Xilinx提供的基于IDE的框架,该框架允许为Zynq平台开发硬件/软件嵌入式系统。该平台提供了定义,集成和验证硬件加速器的能力,该硬件加速器将加速特定功能,稍后将对其进行描述,生成ARM软件和FPGA比特流,同时生成SD映像,以便脱机进行SD卡读取[12]。SDSoC网络映射开发流程如图3所示。
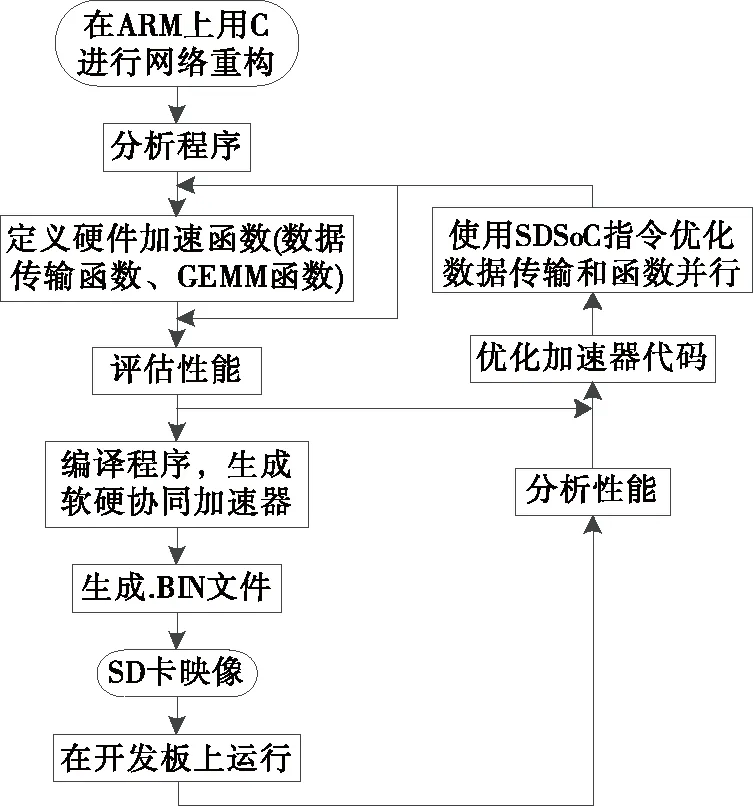
图3 SDSoC网络映射开发流程
2.3 硬件设计
该系统通过HDMI接收、输出图片,采用输入输出级优化、通用矩阵乘法函数复用优化以及卷积操作并行化设计,实现对输入输出级设计和CNN计算密集的卷积层加速。
对于HDMI接收设计,可调用相关IP进行驱动。因此硬件设计的重点即数据传输优化、通用矩阵乘法函数复用和卷积操作并行化设计和优化。
2.3.1 数据传输优化 数据传输优化主要包括PS和PL接口优化和数据传输方式优化。如图4所示,PortA和PortB接口分别为PS端和PL端接口,Data Mover为PS和PL之间进行数据传输的方式。因此,数据传输优化即对PortA、PortB和Data Mover进行优化设计。

图4 数据传输接口
通常大部分的权重参数和算法模型存在DDR中,PS和PL则通过AXI标准总线接口进行数据的交互,AXI接口包括通用AXI接口(AXI_GP)、加速器一致性接口(AXI_ACP)和高性能接口(AXI_HP)[13]。
鉴于访问DDR延迟会导致读写速度缓慢,在PS端与PL端对数据的传输进行优化。传输接口及传输方式的相关优化指令:
//system port
#pragma SDS datasys_port(input:AXI_HP,output:AXI_HP)
//data mover
#pragma SDS datamem_attribute(input:PHYSICAL_CONTIGUOUS|
NON_CACHEABLE,output: PHYSICAL_CONTIGUOUS|NON_CACHEABLE)
#pragma SDS data copy(input[0:WIDTH*HEIGHT],output[0:WIDTH*HEIGHT])
//accelerator
#pragma SDS dataaccess_pattern(input:SEQUENTIAL,output:SEQUENTIAL)
SDS datasys_port指令用于直接约束PS端总线接口类型,试验选择HP类型。AXI_HP接口具有高性能和高带宽的特性,其内部配置异步FIFO作为高速数据读写的缓冲。相反AXI_GP则是没有配置缓冲的中低速接口,AXI_ACP主要实现PS中cache和PL单元之间的一致性接口,因此都不适合。
SDS data mem_attribute用于约束矩阵数据存放地址的连续性。硬件综合时,SDSoC平台会选择传输连续内存更快的AXI_DMA_Simple,而不是AXI_DMA_SG。
SDS data copy指令约束内存大小,意味着SDSoC会将硬件加速器的接口通过AXI总线直接连接到PS的存储器,对其进行一定内存大小的数据传输。
SDS dataaccess_pattern指令约束访问数据的方式,在CNN中都是按照图像每行像素的顺序进行卷积操作,所以将SEQUENTIAL设置为数据访问的方式,那么综合时自动生成顺序访问的接口协议(例如ap_fifo),而不是生成随机访问的接口,大大提高了数据访问速度。
采用综上4条优化指令,可以在连续的物理空间中按照数据流的方式访问数据,降低数据传输延迟,增大数据吞吐率。试验中,传输图像及权重偏置信息均采用此方式加载。
2.3.2 通用矩阵乘法函数复用 CNN中最为密集的计算是卷积,每个卷积层都要进行线性矩阵乘法和加法运算即通用矩阵乘法(GEMM)函数,利用FPGA来实现可以有效地提高卷积计算效率,并降低功耗,区别在于特征图的尺寸不同。对于这一结构上的差异,应将其同构化达到复用的目的。
在不造成卷积运算误差的前提下,对所要进行卷积操作的特征图进行补零。如图5所示,除了输入特征图,之后的卷积操作的特征图的宽和高均小于输入特征图尺寸,因此对其进行填补零值,使其尺寸与输入特征图尺寸相同。因此,与权重的矩阵乘法操作使每一层的卷积运算具有了同构性。在SDSoC中可以专门定义通用矩阵乘法(GEMM)函数并且每一次卷积都可以调用该函数,卷积运算可以复用相同的控制电路,从而节省硬件资源的开销。
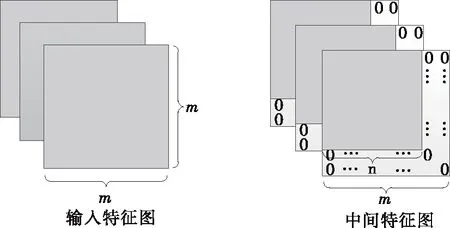
图5 特征图同构化
2.3.3 卷积操作并行化
(1) 矩阵分块优化:对于卷积层中较大的数组拆分为多个较小的数组,用于增加数据访问的并行性。通过使用ARRAY _PARTITION指令对数组进行分块。在文中优化卷积操作使用下述代码结构。对二维数组进行降维,将二维数组分解为若干个小寄存器,提高并行度。相关指令:
#pragma HLSarray_partition variable=in_Bcomplete dim=2
(2) 流水线优化:流水线优化能够将一个延时较大的操作切割成多个小操作并行执行,这样就大大增加了总体的运行速度。采用PIPELINING约束指令来使结构执行流水线操作。为了不消耗太多的硬件资源并且不浪费太多的数据延迟,综合考虑选择在第2层循环内添加优化命令,可以使得工作频率提高将近1倍。流水线优化使用PIPELINING指令:
for(index_a = 0; index_a< A_NROWS; index_a++){
for(index_b = 0; index_b< A_NCOLS; index_b++){
#pragma HLS PIPELINE
//next operations
}}
(3) 循环展开优化:默认情况下,卷积的所有嵌套循环都是按顺序执行的。循环展开优化可以提高循环迭代之间的并行性,增加FPGA计算资源的利用率。如图6所示,将特征图和权重通过移位寄存器分别展开,并且进行并行乘加运算。

图6 循环展开优化
在卷积过程中,通过使用UNROLL优化指令对for循环进行展开。展开最内层for循环,每一层权重的乘积作为一个独立的处理单元(PE),使得PE核最小化。将第3层for循环展开作为PE的并行数量,用来一次获得多个输出层的部分和,部分代码:
//multiply accumulate broken into individual operators
#pragma HLS UNROLL
for(index_d = 0; index_d< B_NCOLS; index_d++){
floatresult + = weights[index_c][index_d]*input_fm[index_c+i][index_d+j];
}
output_fm[i* A_NROWS +j]=result;
(4) 函数内联优化:此外,试验还使用了函数内联优化指令INLINE,去除子函数层次结构,通过减少函数调用开销来改善延迟。指令:
#pragma HLS INLINE self
3 实现
3.1 硬件实现
在硬件设备上,基于Xilinx Zynq7020开发板实现网络的加速,开发板为异构芯片,该芯片有2个ARM A9处理器作为处理系统(PS),还有一个可编程逻辑(PL)XC7Z020用于硬件加速,开发板如图7所示;此外,开发板通过SONY IMX222 CMOS相机对采集的樱桃图片进行测试,试验还配有一台显示器用于测试结果的终端显示,如图8所示。

1. SONY IMX222 CMOS相机 2. 圆顶光源 3. 樱桃样本 4. Xilinx Zynq7020开发板 5. 终端显示器
图7 Xilinx Zynq7020开发板结构图
在硬件模块化设计上,试验基于Xilinx Vivado 2016.4软件,将数据传输模块,通用矩阵乘法模块以及接口模块分别生成各个硬件IP,完成硬件模块化设计。数据的内部传输采用AXI Interconnect模块,即AXI互联矩阵,能够实现将主设备和从设备的互联;外部数据传输采用 HDMI模块实现图像数据传输,并利用异步FIFO模块作为帧缓冲区,缓存数据。内部PS模块包含一个Zynq处理器硬核,实现各IP初始化与配置。定义的Mmult模块实现卷积操作,其内部通用矩阵乘法IP在卷积层进行复用。
分别在PC机、纯ARM软件和试验加速器3种平台进行试验,结果如表2所示。

表2 PC机、纯ARM和试验加速器3种平台比较
3.2 制作并训练数据集
在制作数据集的过程中,在实验室的环境下对采摘来的樱桃进行图像采集。为了能覆盖每个樱桃的完整表面,试验使用Basler acA2000-50gc工业相机对樱桃的6个不同角度进行采集;利用Matlab对图像进行裁剪、旋转、缩放等操作来扩大样本数据;最后将所有的待训练图像统一成32×32规格大小。部分样本示例如图9所示。
训练在Caffe平台下进行,操作系统为Ubuntu16.04,使用Python搭建CNN模型,采用监督式学习的方法对樱桃样本进行训练。最后的全连接层的输出通道即分类数,将樱桃分为3类,分别为:裂口、完好和畸形。用于训练的樱桃图片18 000张,采用人工标记的方法对训练样本进行标记。
4 结果与分析
4.1 数据集测试
试验选取600张樱桃原图进行测试,每个分类各200张,将裂口和畸形的樱桃归为缺陷樱桃。试验先在PC机上利用Python进行测试,再将测试图片放入FPGA进行测试,如表3所示,可以发现在FPGA上,准确率几乎没有下降。
4.2 实际图片测试
工程编译完成之后,.BIN文件会自动在release目录下的sd_card文件夹下生成。将.BIN文件拷贝到SD卡中,设置开发板为SD卡启动模式。连接好终端显示器,显示器左上角为识别出樱桃结果的黄色标签,试验运行结果部分展示如图10所示。

图10 试验运行结果部分展示
Zynq XC7Z020资源包括:18 K大小的Block RAM 140个,查找表(LUT) 53 200个,触发器(FF)106 400个和数字信号处理器(DSP)220个,文中2个硬件加速函数在硬件中的资源占用使用情况和运行时长如表4所示。

表4 硬件加速函数资源占用和运行时长
输入同样尺寸大小的图片在不同平台下分别进行测试,如表5所示。结果表明在纯ARM软件中对单张樱桃图片检测处理需要57.89 ms,而在硬件平台上需26.42 ms,其检测处理速度是纯ARM软件的2.19 倍。

表5 纯ARM软件与试验加速器对樱桃图片处理时长比较
裴悦琨等[4]选用CPU型号为intel(R)Core(TM) i5-6500 CPU @ 3.20GHzHP LV2011的PC机对樱桃进行检测,测试实际图片时在网络中将输入图片的尺寸缩放为64×64,因此将FPGA中网络的缩放尺寸改为64×64,并与文献[4]的处理时间进行比较,如表6所示。

表6 CPU平台与试验加速器对樱桃图片处理时长比较
由表6可以看出,当输入图像尺寸扩大一倍时,一幅图片的处理时长为42.59 ms,对比原来图像尺寸延长了16.17 ms,与文献[4]的CPU平台处理时长相当,但是试验系统所使用的时钟频率与CPU平台相差甚远,若使用性能更好的FPGA,速度应超过CPU平台。而且试验系统具有小型化、手持化的特点,与CPU平台相比具有很强的实际应用价值。
5 结论
试验利用SDSoC快速开发平台,协同处理PS端与PL端,实现一个快速樱桃检测的软硬件系统。通过对系统硬件设计及优化,大大提高了系统的计算性能,与纯ARM软件和CPU实现的算法相比,使用软硬件协同处理对算法的加速效果明显,满足实时性与低成本的要求。试验系统可以不使用PC机,便携性大大提高,同时可拓展性好,具有很大的市场空间。
试验系统还有进一步优化的空间,比如增加学习样本种类、建立合理的分类分级逻辑和改进神经网络模型结构等。同时笔者正在尝试其他水果数据应用于此系统,以使其能检测更多水果缺陷,最终形成一个实用的快速自动水果缺陷检测与识别系统。
猜你喜欢
金桥(2022年2期)2022-03-02
北京航空航天大学学报(2021年9期)2021-11-02
数码世界(2020年12期)2021-01-20
学校教育研究(2020年11期)2020-06-08
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
人大建设(2018年5期)2018-08-16
北京航空航天大学学报(2018年1期)2018-04-20
喜剧世界(2017年13期)2017-07-24
科技传播(2015年20期)2015-03-25
