
基于电子舌及一维深度CNN-ELM模型的普洱茶贮藏年限快速检测
2020-09-18 06:15杨正伟李庆盛王志强李彩虹袁文浩马云霞
食品与机械 2020年8期
杨正伟 - 张 鑫 李庆盛 - 缪 楠 王志强 - 李彩虹 - 袁文浩 - 马云霞 - 周 智
(1. 山东理工大学计算机科学与技术学院,山东 淄博 255049;2. 淄博市中西医结合医院,山东 淄博 255026)
普洱茶是以云南特有的大叶种晒青毛茶为原料,经过渥堆发酵工艺生产的后发酵类茶[1],具有降血糖、降血脂、抗病毒等功效,深受国内外消费者的喜爱[2]。随着贮藏时间的增加,普洱茶的内部会发生复杂的化学变化,使得其风味和口感得以提升[3]。近年来,受经济利益驱动,市场上常会出现普洱茶产品以新替旧、以次充好等现象,严重损害了消费者的权益和普洱茶市场的声誉。传统普洱茶贮藏年限鉴别方法主要有感官分析法和理化分析法。谌滢等[4]采用感官分析法对不同年限的普洱茶外形、茶汤色泽和口感进行评价并做出区分,但该方法受人为因素影响较大,结果的客观性容易受到干扰;谢直虎等[5]采用傅里叶红外光谱对不同年限普洱茶中的酚类、醇类等物质进行分析,进而对不同普洱茶进行分辨;郑玲等[6]采用表面增强拉曼光谱对不同年限普洱茶中的茶素、茶氨酸等物质进行检测,从而区分不同年限的普洱熟茶。但以上理化分析方法检测仪器成本高、分析过程繁琐、耗时耗力且需要检测人员具备专业技能,不适用于对普洱茶贮藏年限进行快速鉴别。
电子舌是一种利用多传感阵列结合模式识别技术对液态样本的“指纹图谱”进行分析的仿生学仪器,具有操作简单、检测迅速、仪器体积小、成本低、检测结果客观性强等特点。近年来电子舌已被广泛应用于环境监测[7]、食品检测与鉴别[8]和药物分析[9]等多个领域。模式识别技术在电子舌系统中起着至关重要的作用,其适用性直接影响到检测结果的准确性。Bhondekar等[10]使用电子舌结合主成分分析和判别因子分析等模式识别方法对不同生产工艺的印度红茶进行了辨别;Bhattacharyya等[11]采用电子舌结合线性判别分析和反向传播神经网络等模式识别方法对不同种类的红茶进行了区分。一般来说,电子舌系统的模式识别过程主要包括特征提取和分类识别两个阶段。特征提取的主要作用是从原始电子舌信号中提取出最重要的信息,从而减少后续数据分析的复杂性。常见的特征提取方法有特征点法[12]、主成分分析法(PCA)[13]、快速傅里叶变换法(FFT)[14]、离散小波变换法(DWT)等,其中离散小波变换已被证明是一种较为有效的电子舌特征提取方法[15]。然而,以上特征提取方法主要基于人工特征设计,效率较低,并且其效果受设计人员的经验和技术影响较大。分类识别是基于所提取的特征信息对样本进行分类或识别的方法。目前常用的电子舌分类识别算法主要有线性判别分析(LDA)[16]、反向传播神经网络(BPNN)[17]、支持向量机(SVM)[18]等。然而,这些方法主要基于浅层的机器学习算法构造,存在模型精度有限、泛化能力不足等问题。
深度学习是近年来发展起来的一种新型数据处理和信号分析技术。深度学习对传统的人工神经网络进行扩充,增加了模型的深度(复杂性),并通过使用允许分层级别的数据表示,提高了数据处理和分析的能力。在深度学习算法中,卷积神经网络(Convolutional Neural Network,CNN)是最著名的模型之一。CNN通过引入多个卷积层和池化层(下采样层),实现了一种自动的特征提取机制[19]。目前,CNN已被广泛应用于计算机视觉、语音识别、自然语言处理等多个与人工智能相关的研究领域[20]。然而,当前尚未见文献将CNN应用于电子舌的模式识别处理。由于CNN的全连接层采用反向传播(BP)算法进行训练,容易陷入局部最小或出现过度训练,导致模型训练时间长、泛化性能下降。极限学习机(ELM)是一种基于单隐层前馈神经网络(SLFN)的监督型算法,具有训练参数计算量小、训练时间短、分类效率高等特点,作为分类器可以很好地弥补BP算法的缺点[21]。
研究拟提出一种基于伏安电子舌和一维深度CNN结合ELM模型(1-D CNN-ELM)的普洱茶贮藏年限鉴别方法。利用卷积神经网络自动提取特征的特点对电子舌信号进行特征提取,并通过ELM建立分类模型对提取后的特征向量进行分类,为不同年限普洱茶的快速、准确地鉴别提供新的方法和思路。
1 材料与方法
1.1 试验材料及样本处理
试验材料均采用勐海茶厂出产的普洱熟茶,出厂时间分别为2011年、2013年、2015年、2017年和2019年5个不同年份。准确称取5 g茶叶,放入200 mL沸腾蒸馏水冲泡5 min,茶溶液经滤纸过滤,冷却至室温[(25±2) ℃]后采用伏安电子舌进行数据采集。每个样本采集完成后,用Al2O3粉末对传感器阵列进行打磨,然后放入超声波清洗仪中清洗。采用上述方法共采集到1 595个电子舌信号,其中2011年、2013年、2015年、2017年和2019年的样品数量分别为333,310,314,317,321。
1.2 电子舌系统
伏安电子舌系统由实验室自行开发,结构如图1所示。该系统由4部分组成:① 传感器阵列,包括8个不同的工作电极(铂、金、钛、钯、银、钨、镍和玻碳)、一个铂辅助电极和一个Ag/AgCl参比电极。Winquist等[22]发现不同种类贵金属电极对不同化学成分的敏感性不同,导致其表面的电化学反应产生差异,多个工作电极采集的电流信号经汇总后可形成被测溶液的“指纹图谱”。② 信号调理电路,用于控制三电极系统的恒压电势并完成采集信号的放大与滤波功能。③ 数据采集卡,通过其D/A模块产生电极激励信号并利用A/D模块采集传感器响应信号。④ LabVIEW上位机软件,用于对检测过程进行操控,并对采集到的电极响应信号进行分析。电子舌检测过程中,采用如图2所示的大幅方波脉冲(LAPV)对工作电极进行伏安扫描,其工作电势范围为-1~1 V,扫描频率为10 Hz,阶跃电位为5 mV。在LAPV的激励下,多个工作电极表面发生氧化还原反应,产生不同幅度的微弱电流响应信号。该信号经调理电路放大后,通过数据采集卡采集至LabVIEW软件进行分析。

图2 大幅方波脉冲伏安信号
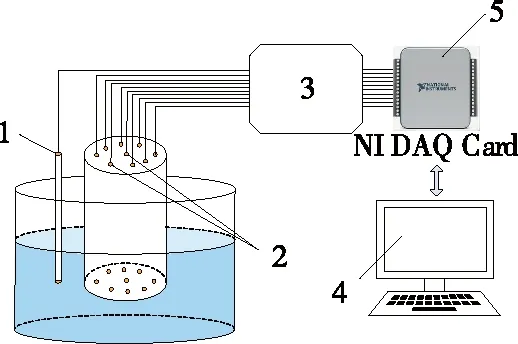
1. 参比电极 2. 工作电极与辅助电极 3. 信号调理电路 4. LabVIEW上位机软件 5. 数据采集卡
1.3 一维卷积神经网络
传统的CNN为二维卷积神经网络,通常用于图像识别领域[23]。由于电子舌信号为一维信号,因此选用一维卷积神经网络(1-D CNN)模型。其结构如图3所示,主要由多个卷积层、池化层(下采样层)和全连接层组成。

图3 一维卷积神经网络模型结构

(1)
式中:
D——输入数据;

*——一维卷积操作;
b——偏置项;
f(·)——激活函数。
卷积层后为池化层(下采样层),其目的是进一步缩小特征图的尺寸,减轻1-D CNN的计算负担。池化层一般只进行降维操作,没有参数,不进行权重更新。文中,选择最大池化操作:
(2)
式中:

n——卷积核的尺寸边长;
max(·)——最大值函数。
全连接层由多个隐含层组成,作用是将所得到的多通道特征图转化为一维向量,其形式为X=[x1,x2,…,xn],其中n为最后一个卷积层的节点个数。模型最后一层输出层采用Softmax激活函数,其公式:
(3)
1.4 极限学习机
极限学习机(ELM)是由Huang等[21]提出的一种改进的单隐层前馈神经网络(SLFN)。ELM可以随机选择输入层和隐含层之间的隐藏节点和连接权值,从而确定网络的输出权值。对N个任意不同的样本(xi,yi), (xi=[xi1,xi2,…,xin]T∈Rn,yi=[yi1,yi2,…,yin]T∈Rn),其具有L个隐含层节点的SLFN为
(4)
式中:
f(·)——激活函数;
βi——隐含层和输出层第i个节点之间的输出权重;
αi——输入层和隐含层第i个节点之间的输入权重;
bi——第i个节点之间的偏置。
用矩阵的形式对式(6)进行重构:
Hβ=T,
(5)
其中,H表示隐含层输出矩阵:
(6)
式中:
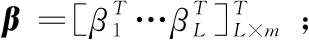

在SLFN中,当激活函数f无限可微,对于随机选择的输入权值和隐含层偏置,只要训练集样本数N大于隐含层神经元个数L,SLFN即可零误差去逼近训练样本。因此,训练ELM的过程相当于求解方程组Hβ=T的最小二乘解:

(7)
可证明该最小二乘解的最小值为:
(8)
式中:
H+——隐含层输出矩阵H的广义雅克比矩阵的逆,可通过正交法计算求得。
1.5 1-D CNN-ELM模型
经典1-D CNN采用BPNN作为分类器,会导致训练时间长、泛化能力差的问题。ELM具有训练速度快、泛化性好、分类精度高等优点。鉴于1-D CNN以及ELM各自的特点,将1-D CNN 和ELM 组合构建CNN-ELM模型。图4为1-D CNN-ELM模型结构图,其中,1-D CNN模型由5个卷积层和4个池化层组成。第1个卷积层使用了16个尺寸为7的卷积核。第2个卷积层使用32个尺寸为5的卷积核。第3~5个卷积层均采用尺寸为3的卷积核,其个数分别为64,128,64。模型的激活函数采用指数线性单元(ELU)。在第1个卷积层到第5层卷积层之间均放置一个Max-Pooling层,池化窗口尺寸和步幅为2。最后一层卷积后采用ELM进行分类识别。
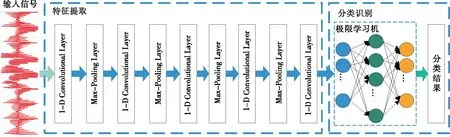
图4 1-D CNN-ELM模型
1-D CNN-ELM模型的训练流程如图5所示,先将伏安电子舌采集的普洱茶信号进行数据预处理操作(数据增强、数据归一化),再将处理好后的数据集中的70%作为训练集样本,其余作为测试集样本。使用训练集样本训练1-D CNN至收敛,然后提取最后一个卷积层的特征训练ELM,可得到1-D CNN-ELM模型,采用测试集样本对模型进行分类效果检验。

图5 1-D CNN-ELM模型训练流程
2 结果与分析
模型训练均是在Keras框架下完成的。硬件环境:Intel i7-8700K@3.70 GHz;24 G内存;Nvidia GeForce GTX 1080Ti,11 G显存。软件环境:CUDA Toolkit 10.0,CUDNN V7.6.1;Python 3.6;Keras 2.2.4;Windows 10 64 bit 操作系统。
2.1 电子舌响应信号
伏安电子舌系统的8个工作电极得到的响应信号如图6所示。由图6可以看出,每个电极区域都表现出一种独特的普洱茶样品“指纹图谱”。普洱茶经检测后,每个样品可采集得到8 000个数据点(1 000×8个电极)。

图6 电子舌响应信号
2.2 数据预处理与数据增强
由于电子舌信号噪声大且数值变化幅度较大,因此需要采用式(9)对电子舌信号进行归一化处理:
(9)
式中:
xi——信号中第i个采样值;
xmax——信号中最大值;
xmin——信号中最小值。
为了进一步提高1-D CNN模型的鲁棒性,采用数据增强技术增加电子舌信号的训练样本数量。文中采用信号加噪扩容的信号增强方法,步骤是:首先将均值为0,标准差为0.05的随机高斯噪声信号嵌入到原始的电子舌信号中,形成加噪数据集。然后将加噪数据集与原数据集组合,共可得到3 190个电子舌信号训练样本。
2.3 CNN-ELM模型
2.3.1 CNN结构优化 不同的卷积层和池化层组合会影响1-D CNN对电子舌信号特征的提取效果。较多的卷积层(Conv-i)和池化层(Pooling-i)会导致模型提取过多不必要的特征,易产生过拟合问题;而较少的卷积层和池化层则会使得样本特征得不到充分提取,易产生欠拟合问题。为了达到最佳的特征提取效果,采用(Conv-6, Pooling-5)、(Conv-5, Pooling-4)、(Conv-4, Pooling-3)和(Conv-3, Pooling-2) 4种不同数目的卷积层和池化层组合对CNN模型进行优化。从图7可以看出,随着卷积层从3增加到6、池化层从2增加到5,1-D CNN模型在训练集上的收敛速度和分类准确率增加。从图8可以看出,测试集上,最佳组合为(Conv-5, Pooling-4),而组合(Conv-6, Pooling-5)出现性能下降的原因可能是卷积层和池化层数量过多,导致电子舌特征被过度提取从而产生过拟合问题。

图8 不同卷积层和池化层组合的模型在训练集和测试集上的平均分类精度
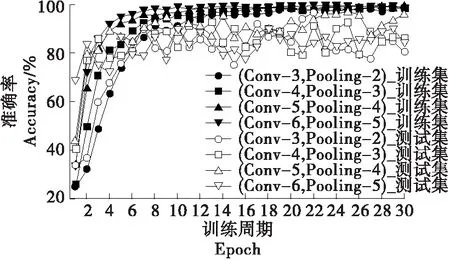
图7 不同模型组合在训练集和测试集的分类精度
1-D CNN的超参数如学习率、训练周期epoch和mini-batch size也会对模型的训练速度和泛化性能产生较大影响。因此,采用单一因素法对1-D CNN的超参数进行选择优化,具体步骤见文献[24],其结果如图9所示。通过比较不同超参数在测试集上的分类性能,得到最佳分类效果的模型的学习率为0.000 5、训练周期epoch为30、mini-batch size的参数为42。

图9 不同超参数在CNN测试集上的准确率
2.3.2 ELM分类器优化 1-D CNN-ELM模型的ELM分类器在训练中能够随机产生输入层和隐含层间的连接权值和阈值,因此,仅需要对ELM隐含层节点数进行优化即可。分别将隐含层的节点数为2~200的不同ELM与1-D CNN结合,其不同结构的模型分类准确性结果如图10所示。由图10可以看出,当隐含层节点数为146时,1-D CNN-ELM的性能最佳,其准确率为98.32%。

图10 不同隐含层节点数的ELM在测试集上的准确率
2.4 传统机器学习模型
为了验证文中方法的有效性,采用离散小波变换(DWT)作为特征提取方法,分别使用SVM和ELM作为分类器,组成DWT-SVM和DWT-ELM两种对比模型,对普洱茶电子舌信号进行模式识别操作。
在DWT特征提取过程中,为了达到最佳效果,对小波基函数和分解阶数进行优化。电子舌信号分别选择4种不同的小波基函数(Coiflets、Daubechies、Haar、Symlets)进行4~7阶的分解。为了评价分解效果,选择相关系数R2作为评价指标。其试验结果如图11所示。结果表明,当采用Sym6母小波进行7层分解时,相似系数达到最大值0.974 9,此时压缩效果最好。电子舌信号经DWT特征提取后,8 000个数据点被压缩至73个。
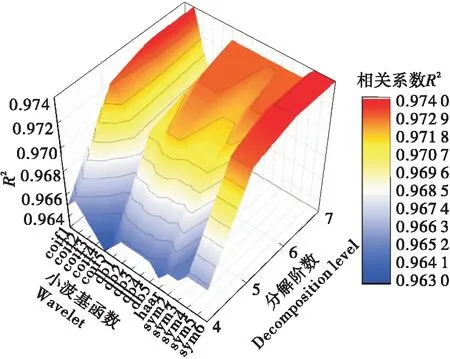
图11 DWT特征提取中不同母小波和分解层数对R2的影响
采用SVM作为模型分类器,其分类性能主要受到惩罚系数C和核函数参数λ影响。采用网格寻优算法对SVM进行优化,其中的C和γ的取值范围均为[2-5,2-4,…,24,25],其结果如图12所示,试验表明,当C=2-5,γ=25时,DWT-SVM模型的分类效果达到最优,其准确率为91.36%。采用与3.3.2节相同的方法对DWT-ELM模型中的ELM隐含层节点进行优化,结果表明,当节点数为96时,DWT-ELM模型的性能最佳,其准确率为93.63%。

图12 SVM中不同的C和γ对测试集准确率的影响
2.5 模型性能对比分析
分别建立1-D CNN-ELM、传统CNN、DWT-SVM和DWT-ELM模型的分类混淆矩阵。如图13所示,可发现传统CNN对普洱茶年限鉴别的正确分类的样本个数要大于DWT-ELM和DWT-SVM,而1-D CNN-ELM的正确分类的样本数多于传统CNN。

图13 4种模型的分类混淆矩阵
进一步对4种模型的精确率、召回率和F1-Score参数进行对比分析,其公式:
(10)
(11)
(12)
式中:
Precison——精确率,%;
Recall——召回率,%;
F1-Score——F1-Score参数;
TP——真实的正样本数量;
FP——真实的负样本数量;
FN——虚假的负样本数量。
从表1可以看出,DWT-ELM模型的精确率、召回率和F1-Score分别为94.0%,94.0%,0.94,较DWT-SVM模型的性能提高了约3%。这可能是由ELM模型比SVM模型具有更好的泛化能力和鲁棒性造成的。传统1-D CNN模型性能又较DWT-ELM模型提高了约2%,表明1-D CNN在其分类器(BPNN)性能劣于ELM的情况下,仍能取得较好的分类效果,证明了深度学习方法比传统机器学习方法具有更好的特征提取性能。而1-D CNN-ELM模型与1-D CNN模型相比性能更好,说明ELM分类器的引入有效地提高了传统CNN模型的分类准确率和模型泛化性能。

表1 不同模式识别模型的性能对比
3 结论
研究提出了一种基于1-D CNN-ELM模式识别模型结合伏安电子舌对普洱茶年限进行鉴别的方法。采用一维卷积神经网络对电子舌信号进行自动特征提取,然后利用ELM算法进行分类识别。该方法克服了传统CNN泛化能力差、训练耗时长的缺点,同时避免了传统机器学习模型需要人工特征设计,导致特征提取不完善、费时费力等问题。试验结果表明,与传统电子舌信号模式识别模型相比,1-D CNN-ELM模型对不同贮藏年限的普洱茶电子舌信号的分类准确率有较大提升。研究仅对5种不同年限的普洱茶进行鉴别且采用单一因素法优化1-D CNN模型超参数,后续将采用更加高效的模型优化方法,并将其应用于电子舌的其他检测领域,以进一步验证其适用性。
猜你喜欢
科技创新与应用(2021年23期)2021-08-30
无线互联科技(2020年15期)2020-11-10
天津农林科技(2020年3期)2020-08-13
科技传播(2020年6期)2020-05-25
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
云南画报(2019年11期)2019-03-08
电子制作(2018年19期)2018-11-14
雷达科学与技术(2018年3期)2018-07-18
